

Bert的原理及实现
Bert实际上就是通过叠加多层transformer的encoder(transformer的介绍可以看我的这篇文章)通过两个任务进行训练的得到的。本文参考自BERT 的 PyTorch 实现,BERT 详解.主要结合自己对代码的一些理解融合成一篇以供学习。同时DaNing大佬的博客写的比我好的多,大家可以直接点此查看。代码可以看这里。
关于Bert的一些知识
在开始之前,首先介绍一下Bert的代码实现涉及的知识以及关于Bert的相关问题解读,便于读者理解
准备
头文件
'''
simple bert in pytorch
code by xyzhrrr
2012/12/27
'''
import re #正则表达式操作
import math
import torch
import numpy as np
from random import*
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
数据集准备
与transformer相同,数据集是手动输入了两个人的对话,主要是为了降低代码阅读难度,我希望读者能更关注模型实现的部分
'''
准备数据,为降低阅读难度,手动输入两人对话作为数据
'''
text = (
'Hello, how are you? I am Romeo.\n' # R
'Hello, Romeo My name is Juliet. Nice to meet you.\n' # J
'Nice meet you too. How are you today?\n' # R
'Great. My baseball team won the competition.\n' # J
'Oh Congratulations, Juliet\n' # R
'Thank you Romeo\n' # J
'Where are you going today?\n' # R
'I am going shopping. What about you?\n' # J
'I am going to visit my grandmother. she is not very well' # R
)
sentences = re.sub("[.,!?\\-]", '', text.lower()).split('\n') # 将 '.' ',' '?' '!'以及‘-’全部替换为‘’,即将这些过滤掉
word_list=list(set(" ".join(sentences).split()))
## ['hello', 'how', 'are', 'you',...]获取单词list,set集合将自动将重复单词去掉
word2idx={'[PAD]':0,'[CLS]':1,'[SEP]':2,'[MASK]':3}
#自左到右分别代表:填充、判断符、分隔符、掩码mask
for i,w in enumerate(word_list):
word2idx[w]=i+4#生成最终的词字典,+4是从4开始作为单词的idx
idx2word={i:w for i,w in enumerate(word2idx)}#idx转回word的list
vocab_size=len(word2idx)
token_list=list()#存储将原始数据转后的值,里面每一行代表一句话
for sentence in sentences:
arr=[word2idx[s] for s in sentence.split()]
token_list.append(arr)
模型参数
- maxlen 表示同一个 batch 中的所有句子都由 30 个 token 组成,不够的补 PAD(这里我实现的方式比较粗暴,直接固定所有 * batch 中的所有句子都为 30)
- max_pred 表示最多需要预测多少个单词,即 BERT 中的完形填空任务最多MASK或替换多少单词
- n_layers 表示 Encoder Layer 的数量
- d_model 表示 Token Embeddings、Segment Embeddings、Position Embeddings 的维度
- d_ff 表示 Encoder Layer 中全连接层的维度
- n_segments 表示 Decoder input 由几句话组成
maxlen=30
batch_size=6
max_pred=5
n_layers=6
n_heads=12
d_model=768
d_ff=768*4
d_k = d_v = 64 # dimension of K(=Q), V
n_segments=2
数据预处理
需要根据概率随机 make 或者替换(以下统称 mask)一句话中 15% 的 token,还需要拼接任意两句话这些 token 有 80% 的几率被替换成 [MASK],有 10% 的几率被替换成任意一个其它的 token,有 10% 的几率原封不动.
BERT预训练
我们首先介绍一下BERT预训练的具体任务:

一共是两个任务:
- 漏字填空(完型填空),学术点的说法是 Masked Language Model
- 判断第 2 个句子在原始本文中是否跟第 1 个句子相接(Next Sentence Prediction)
设计细节
BERT 语言模型任务一:Masked Language Model
在 BERT 中,Masked LM(Masked Language Model)构建了语言模型,简单来说,就是随机遮盖或替换一句话里面的任意字或词,然后让模型通过上下文预测那一个被遮盖或替换的部分,之后做 Loss 的时候也只计算被遮盖部分的 Loss,这其实是一个很容易理解的任务,实际操作如下:
- 随机把一句话中 15% 的 token(字或词)替换成以下内容:
- 这些 token 有 80% 的几率被替换成 [MASK],例如 my dog is hairy→my dog is [MASK]
- 有 10% 的几率被替换成任意一个其它的 token,例如 my dog is hairy→my dog is apple
- 有 10% 的几率原封不动,例如 my dog is hairy→my dog is hairy
- 之后让模型预测和还原被遮盖掉或替换掉的部分,计算损失的时候,只计算在第 1 步里被随机遮盖或替换的部分,其余部分不做损失,其余部分无论输出什么东西,都无所谓
这样做的好处是,BERT 并不知道 [MASK] 替换的是哪一个词,而且任何一个词都有可能是被替换掉的,比如它看到的 apple 可能是被替换的词。这样强迫模型在编码当前时刻词的时候不能太依赖当前的词,而要考虑它的上下文,甚至根据上下文进行 "纠错"。比如上面的例子中,模型在编码 apple 时,根据上下文 my dog is,应该把 apple 编码成 hairy 的语义而不是 apple 的语义
BERT 语言模型任务二:Next Sentence Prediction
我们首先拿到属于上下文的一对句子,也就是两个句子,之后我们要在这两个句子中加一些特殊的 token:[CLS]上一句话[SEP]下一句话[SEP]。也就是在句子开头加一个 [CLS],在两句话之间和句末加 [SEP],具体地如下图所示

-
可以看到,上图中的两句话明显是连续的。如果现在有这么一句话 [CLS]我的狗很可爱[SEP]企鹅不擅长飞行[SEP],可见这两句话就不是连续的。在实际训练中,我们会让这两种情况出现的数量为 1:1
-
Token Embedding就是正常的词向量,即 PyTorch 中的 nn.Embedding()
Segment Embedding 的作用是用 embedding 的信息让模型分开上下句,我们给上句的 token 全 0,下句的 token 全 1,让模型得以判断上下句的起止位置,例如
[CLS]我的狗很可爱[SEP]企鹅不擅长飞行[SEP]
0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
- position Embedding 和 Transformer 中的不一样,不是三角函数,而是学习出来的.
代码
- 代码中,positive 变量代表两句话是连续的个数,negative 代表两句话不是连续的个数,我们需要做到在一个 batch 中,这两个样本的比例为 1:1。随机选取的两句话是否连续,只要通过判断 tokens_a_index + 1 == tokens_b_index 即可.
-
然后是随机 mask 一些 token,n_pred 变量代表的是即将 mask 的 token 数量,cand_maked_pos 代表的是有哪些位置是候选的、可以 mask 的(因为像 [SEP],[CLS] 这些不能做 mask,没有意义),最后 shuffle() 一下,然后根据 random() 的值选择是替换为 [MASK] 还是替换为其它的 token
-
接下来会做两个 Zero Padding,第一个是为了补齐句子的长度,使得一个 batch 中的句子都是相同长度。第二个是为了补齐 mask 的数量,因为不同句子长度,会导致不同数量的单词进行 mask,我们需要保证同一个 batch 中,mask 的数量(必须)是相同的,所以也需要在后面补一些没有意义的东西,比方说 [0]
这就是整个数据预处理的部分
def make_data():#可以看到所有数据都是随机采样的,因此很可能有的数据没有用到
batch=[]#存储一个batch内的输入
positive=negative=0
while positive !=batch_size/2 or negative!=batch_size/2:
#判断条件是两个句子连续与不连续的比例应为1:1
tokens_a_index,tokens_b_index=randrange(len(sentences)),randrange(len(sentences))
# sample random index in sentences,randrange随机抽取一个数
tokens_a,tokens_b=token_list[tokens_a_index],token_list[tokens_b_index]
input_ids=[word2idx['[CLS]']]+tokens_a+[word2idx['[SEP]']]+tokens_b+[word2idx['[SEP]']]
#上面几步随机抽取几个句子然后按照规范合成一个bert输入,最后形成一个数字list数组
segment_ids=[0]*(1+len(tokens_a)+1)+[1]*(len(tokens_b)+1)
#这是生成段嵌入,将上下句分开,上一句以及[CLS]和第一个[SEP]都为0
#第二个句子以及最后一个[SEP]用1表示,最后生成一个[0,0,0,0...1,1,1]
n_pred=min(max_pred,max(1,int(len(input_ids)*0.15)))#随机选15%的用作预测
#15 % of tokens in one sentence,n_pred 变量代表的是即将 mask 的 token 数量
cand_masked_pos=[i for i,token in enumerate(input_ids)
if token!=word2idx['[CLS]'] and token!= word2idx['[SEP]']] #candidate masked position
#选出候选的被替换或mask的位置,标记位不参与
shuffle(cand_masked_pos)#将候选位置打乱
masked_tokens,masked_pos=[],[]
for pos in cand_masked_pos[:n_pred]:
masked_pos.append(pos)#选定的要处理的token的位置。
masked_tokens.append(input_ids[pos])#存储选定的token的数字表示
if random() <0.8: #80%被替换成 [MASK]
input_ids[pos]=word2idx['[MASK]']
elif random()>0.9: #有 10% 的几率被替换成任意一个其它的 token,
index=randint(0,vocab_size-1)#随机生成一个在词表范围内的id
while index<4: #不涉及'CLS', 'SEP', 'PAD'
index=randint(0,vocab_size-1)#重新生成
input_ids[pos]=index #替换
#剩下的10%不处理。
n_pad=maxlen-len(input_ids)
input_ids.extend([0]*n_pad)
segment_ids.extend([0]*n_pad)
#第一个是为了补齐句子的长度,使得一个 batch 中的句子都是相同长度。
if max_pred>n_pred: # Zero Padding (100% - 15%) tokens
'''
第二个是为了补齐 mask 的数量,因为不同句子长度,
会导致不同数量的单词进行 mask,
我们需要保证同一个 batch 中,mask 的数量(必须)是相同的,
所以也需要在后面补一些没有意义的东西,比方说 [0]
'''
n_pad=max_pred-n_pred
masked_tokens.extend([0]*n_pad)
masked_pos.extend([0]*n_pad)
#所以上面两个的大小为[batch, max_pred]
'''
positive 变量代表两句话是连续的个数,negative 代表两句话不是连续的个数,
在一个 batch 中,这两个样本的比例为 1:1。
两句话是否连续,只要通过判断 tokens_a_index + 1 == tokens_b_index 即可
'''
if tokens_a_index+1 == tokens_b_index and positive<batch_size/2:
batch.append([input_ids,segment_ids,masked_tokens,masked_pos,True])
positive+=1 # IsNext
elif tokens_a_index+1 != tokens_b_index and negative<batch_size/2:
batch.append([input_ids,segment_ids,masked_tokens,masked_pos,False])
negative+=1 # NotNext
return batch
#获取一个batch内的所有输入,并转换为tensor
#zip将batch按列解压。所以例如input_ids会存储那一列说有的batch中的inputs_ids,
# 即每一个是一个矩阵,每一行代表一个输入的对应元素(也是一个list),一共batch_size行
'''
数据加载器
'''
class MyDataSet(Data.Dataset):
def __init__(self,input_ids,segment_ids,masked_tokens,masked_pos,isNext):
self.input_ids=input_ids
self.segment_ids = segment_ids
self.masked_tokens = masked_tokens
self.masked_pos = masked_pos
self.isNext = isNext
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):#最好就用idx而不要用item否则可能会有一些问题
return self.input_ids[idx], self.segment_ids[idx], self.masked_tokens[idx], self.masked_pos[idx], self.isNext[idx]
模型构建
同时参考了DaNing
模型结构主要采用了 Transformer 的 Encoder,所以这里我不再多赘述,可以直接看这篇文章 Transformer 的 PyTorch 实现,以及B 站视频讲解.
Mask
'''
针对句子不够长,加了 pad,因此需要对 pad 进行 mask
具体参考transformer实现的部分。
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
'''
def get_attn_pad_mask(seq_q,seq_k):
batch_size,seq_len=seq_q.size() # eq(zero) is PAD token
'''
是返回一个大小和 seq_k 一样的 tensor,只不过里面的值只有 True 和 False。
如果 seq_q 某个位置的值等于 0,那么对应位置就是 True,否则即为 False。
'''
pad_attn_mask=seq_q.data.eq(0).unsqueeze(1)# [batch_size, 1, seq_len]
# unsqueeze(1)在1那个位置增加一个维度
return pad_attn_mask.expand(batch_size,seq_len,seq_len)
# [batch_size, seq_len, seq_len],
# #维度是这样的,因为掩码用在softmax之前,那他的维度就是Q*k.T的维度,而实际上len_q=len_k
Gelu
在BERT中采用GELU作为激活函数, 它与ReLU相比具有一些概率上的性质,具体的可以看开头的一些参考:
'''
gelu 激活函数,具体看笔记
'''
def gelu(x):
'''
erf(x)就是对e^(-t^2)作0到x的积分。
'''
return x*0.5*(1.0+ torch.erf(x/math.sqrt(2.0)))
Embedding
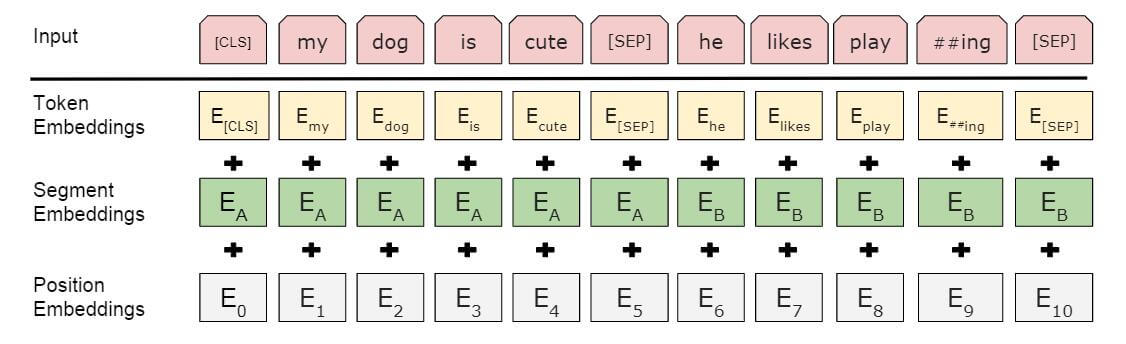
BERT中含有三种编码, Word Embedding, Position Embedding, Segment Embedding:
'''
构建embedding
可以看到这里的位置嵌入是通过学习得到的,具体输入的是什么还是要看一下后续的代码
对于具体的内容可以看一下bert的间隔及博客:
https://wmathor.com/index.php/archives/1456/
'''
class Embedding(nn.Module):
def __init__(self):
super(Embedding,self).__init__()
self.tok_embed=nn.Embedding(vocab_size,d_model)
# token embedding,定义一个具有vocab_size个单词的维度为d_model的查询矩阵
self.pos_embed=nn.Embedding(maxlen,d_model)# position embedding
self.seg_embed=nn.Embedding(n_segments,d_model) # segment(token type) embedding
self.norm=nn.LayerNorm(d_model)#定义一个归一化层
def forward(self,x,seg):
seq_len=x.size(1)
pos=torch.arange(seq_len,dtype=torch.long)
pos=pos.unsqueeze(0).expand_as(x) # [seq_len] -> [batch_size, seq_len]
embedding=self.tok_embed(x)+self.pos_embed(pos)+self.seg_embed(seg)
return self.norm(embedding)
Attention
这里的点积缩放注意力和多头注意力完全和Transformer一致, 不再细说, 直接照搬过来就行.
Scaled DotProduct Attention:
'''
计算上下文向量
这里要做的是,通过 Q 和 K 计算出 scores,
然后将 scores 和 V 相乘,得到每个单词的 context vector
'''
class ScaleDotProductAttention(nn.Module):
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
def forward(self,Q,K,V,attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores=torch.matmul(Q,K.transpose(-1,-2))/np.sqrt(d_k)
# scores : [batch_size, n_heads, seq_len, seq_len]
scores.masked_fill_(attn_mask,-1e9)
# masked_fill_()函数可以将attn_mask中为1(True,也就是填充0的部分)的位置填充为-1e9
# 相当于对填0的地方加上一个极小值以消除在计算attention时softmax时的影响。
attn=nn.Softmax(dim=-1)(scores)
# 对行进行softmax,每一行其实就是求一个字对应的注意力权重,可以看博客
context=torch.matmul(attn,V)
# [batch_size, n_heads, len_q, d_v]
return context
Multi - Head Attention
'''
多头注意力机制
完整transformer代码中一定会有三处地方调用 MultiHeadAttention(),Encoder Layer 调用一次,
传入的 input_Q、input_K、input_V 全部都是 encoder_inputs;
Decoder Layer 中两次调用,第一次传入的全是 decoder_inputs,
第二次传入的分别是 decoder_outputs,encoder_outputs,encoder_outputs
'''
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q=nn.Linear(d_model,d_k*n_heads)
#输入维度为embedding维度,输出维度为Q(=K的维度)的维度*头数,
# bias为False就是不要学习偏差,只更新权重即可(计算的就是权重)
self.W_K=nn.Linear(d_model,d_k*n_heads)
self.W_V=nn.Linear(d_model,d_v*n_heads)
self.fc=nn.Linear(n_heads*d_v,d_model)
#通过一个全连接层将维度转为embedding维度好判断预测结果
def forward(self,input_Q,input_K,input_V,attn_mask):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual,batch_size=input_Q,input_Q.size(0)
#residual,剩余的,用于后续残差计算,这里的input的一样,这里没有position嵌入
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q=self.W_Q(input_Q).view(batch_size,-1,n_heads,d_k).transpose(1,2)
# Q: [batch_size, n_heads, len_q, d_k],-1就是在求长度
#其实self.W_Q就是一个线性层,输入的时input_Q,然后对输出进行变形,
# 这也是linear的特点,即只需要最后一个满足维度就可以即[batch_size,size]中的size
K=self.W_K(input_K).view(batch_size,-1,n_heads,d_k).transpose(1,2)
# K: [batch_size, n_heads, len_k, d_k]
V=self.W_V(input_V).view(batch_size,-1,n_heads,d_v).transpose(1,2)
# V: [batch_size, n_heads, len_v(=len_k), d_v]
'''
我们知道为了能够计算上下文context我们需要len_v==len_k,这就要求d_v=d_k
所以实际上Q、K、V的维度都是相同的
我猜测这里仅将Q、K一起表示是为了便于管理参与加权计算的和不参与的。
'''
attn_mask=attn_mask.unsqueeze(1).repeat(1,n_heads,1,1)
# attn_mask : [batch_size, n_heads, seq_len, seq_len]
#根据生成attn_mask的函数生成的大小应该为# [batch_size, len_q, len_k]
#所以显示增加了一个1个列的维度变为[batch_size, 1,len_q, len_k]在通过repeat变为上面结果
context=ScaleDotProductAttention()(Q,K,V,attn_mask)
#这种输入形式是为了将参数传送到forward,若在括号里则传给init了。
context=context.transpose(1,2).reshape(batch_size,-1,n_heads*d_v)
# [batch_size, n_heads, len_q, d_v]->[batch_size, len_q, n_heads * d_v],为了最后一个维度符合全连接层的输入
output=self.fc(context)# [batch_size, len_q, d_model]
return nn.LayerNorm(d_model)(output+residual)#可以看linear的实现就明白了
#最后进行残差运算以及通过LayerNorm把神经网络中隐藏层归一为标准正态分布,也就是独立同分布以起到加快训练速度,加速收敛的作用
#残差连接实际上是为了防止防止梯度消失,帮助深层网络训练
Feed Forward Neural Network
BERT中的FFN实现将激活函数换为了GELU:
'''
前馈连接层
就是做两次线性变换,与transformer不同,本处使用了bert提出的gelu()激活函数
需要注意,每个 Encoder Block 中的 FeedForward 层权重都是共享的
'''
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc1=nn.Linear(d_model,d_ff) #d_ff全连接层维度
self.fc2= nn.Linear(d_ff,d_model)
#先映射到高维在回到低维以学习更多的信息
def forward(self,x):
'''
x: [batch_size, seq_len, d_model]
'''
residual=x
output=self.fc2(gelu(self.fc1(x)))
# [batch_size, seq_len, d_model]
return nn.LayerNorm(d_model)(output+residual)
#这里与参考博客给的不一样,我自己加上了残差和layernorm,要了解二者的作用
#可以参考transformer中layernorm的作用,https://blog.csdn.net/weixin_42399993/article/details/121585747
#但是如果实际用也可以加上试试
Encoder
'''
encoder layer
就是将上述组件拼起来
'''
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn=MultiHeadAttention()#多头注意力层
self.pos_ffn=PoswiseFeedForwardNet()#前馈层,注意残差以及归一化已经在各自层内实现
def forward(self,enc_inouts,enc_self_attn_mask):
'''
enc_inputs: [batch_size, src_len, d_model]
nc_self_attn_mask: [batch_size, src_len, src_len]
'''
enc_outputs=self.enc_self_attn(enc_inouts,enc_inouts,enc_inouts,enc_self_attn_mask)
#三个inputs对应了input_Q\K\V.attn其实就是softmax后没有乘以V之前的值。
enc_outputs=self.pos_ffn(enc_outputs)# enc_outputs: [batch_size, src_len, d_model]
return enc_outputs
Bert
-
首先介绍一下池化层pooler:Pooler是
Hugging Face实现BERT时加上的额外组件. NSP任务需要提取[CLS]处的特征, Hugging Face的做法是将[CLS]处的输出接上一个FC, 并用tanh激活, 最后再接上二分类输出层. 他们将这一过程称为”Pool“.因为额外添加了一个FC层, 所以能增强表达能力, 同样提升了训练难度. -
现在大框架中的Embedding, EncoderLayer, Pooler已经定义好了, 只需要额外定义输出时需要的其他组件. 在NSP任务输出时需要额外定义一个二分类输出层
next_cls, 还有MLM任务输出所需的word_classifier, 以及前向传递forward.
class Bert(nn.Module):
def __init__(self):
super(Bert, self).__init__()
self.embedding=Embedding()#返回的是三个嵌入的合,看函数实现即可
self.layers=nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
self.fc=nn.Sequential(
nn.Linear(d_model,d_model),
nn.Dropout(0.5),
nn.Tanh(),
)
'''
用作池化pooler,详见 https://adaning.github.io/posts/52648.html
这里的作用我猜测:全连接层用来获取更多特征,dropout防止过拟合,tanh激活函数引入非线性因素
'''
self.classifier=nn.Linear(d_model,2)#这是用作判断是否是相邻句子的一个二分类
self.linear=nn.Linear(d_model,d_model)
self.gelu=gelu #这里没有括号是将activ2初始化为这个函数,加上括号就是引用了,返回的是函数的结果
# 下面三行实现对Word Embedding和word_classifier的权重共享
embed_weight=self.embedding.tok_embed.weight
self.fc2=nn.Linear(d_model,vocab_size,bias=False)#判断填空的词为什么的分类器
self.fc2.weight=embed_weight
def forward(self,input_ids,segment_ids,masked_pos):
output=self.embedding(input_ids,segment_ids)#返回 embedding
# [bach_size, seq_len, d_model]
enc_self_attn_mask=get_attn_pad_mask(input_ids,input_ids)#获得mask
# [batch_size, maxlen, maxlen]
for layer in self.layers:
# output: [batch_size, max_len, d_model]
output=layer(output,enc_self_attn_mask)
h_pooled=self.fc(output[:,0])# [batch_size, d_model]
logits_clsf=self.classifier(h_pooled)
# [batch_size, 2] predict isNext
# 上两行即是池化过程(两句是否相邻任务),将[CLS]作为输入,通过接上一个FC, 并用tanh激活,
# 最后再接上二分类输出层,因为额外添加了一个FC层, 所以能增强表达能力, 同样提升了训练难度.
'''
# Masked Language Model Task
# masked_pos: [batch, max_pred] -> [batch, max_pred, d_model]
'''
masked_pos=masked_pos.unsqueeze(-1).expand(-1, -1, d_model)
# [batch_size, max_pred, d_model]
h_masked=torch.gather(output,1,masked_pos) # masking position [batch_size, max_pred, d_model]
'''
torch.gather能收集特定维度的指定位置的数值,它的作用是将查找被处理的token的位置,
并按照token的处理顺寻的位置重新排序embedding,总大小[batch, max_pred, d_model].
因为masked_pos大小为[batch, max_pred, d_model],所以embedding应该被裁剪了。
简单来说是为了检索output中 seq_len维度上被Mask的位置上的表示,
我们只选择被处理的位置的内容是因为bert计算这里的损失的时候,只计算在第 1 步里被随机遮盖或替换的部分
这是可以的,因为是由上下文句子的,只是判断单词而已,所以其余的没有什么作用,或者说作用比较小。
'''
h_masked=self.gelu(self.linear(h_masked))#与plooer的原理相同
# [batch_size, max_pred, d_model]
logits_lm=self.fc2(h_masked) # [batch_size, max_pred, vocab_size],预测的单词
return logits_lm,logits_clsf
8 为了减少模型训练上的负担, 这里对pooler的fc和MLM输出时使用的fc做了权重共享, 也对Word Embedding和word_classifier的权重做了共享.
-
torch.gather能收集特定维度的指定位置的数值.h_masked使用的gather是为了检索output中max_len维度上被Mask的位置上的表示, 总大小[batch, max_pred, d_model]. 因为masked_pos大小为[batch, max_pred, d_model]. 可能我表述不太清楚, 请参照Pytorch之张量进阶操作中的例子理解. -
没在模型中使用
Softmax和Simgoid的原因是nn.CrossEntropyLoss自带将Logits转为概率的效果
训练
下面是训练代码, 没有什么值得注意的地方.
model=Bert()
criterion=nn.CrossEntropyLoss()
optimizer=optim.Adadelta(model.parameters(),lr=0.001)
batch=make_data()
input_ids, segment_ids, masked_tokens, masked_pos, isNext = zip(*batch)#将batch内的各元素解压
input_ids2, segment_ids2, masked_tokens2, masked_pos2, isNext2 = \
torch.LongTensor(input_ids), torch.LongTensor(segment_ids), torch.LongTensor(masked_tokens),\
torch.LongTensor(masked_pos), torch.LongTensor(isNext)
'''
batch_tensor = [torch.LongTensor(ele) for ele in zip(*batch)]
'''
loader=Data.DataLoader(MyDataSet(input_ids2, segment_ids2, masked_tokens2, masked_pos2, isNext2), batch_size,True)
'''
训练代码
'''
for epoch in range(180):
for input_ids, segment_ids, masked_tokens, masked_pos, isNext in loader:
# =[ele for ele in one_batch]
logits_lm,logits_clsf=model(input_ids,segment_ids,masked_pos)
# for masked LM
loss_lm=criterion(logits_lm.view(-1,vocab_size),masked_tokens.view(-1))#计算损失函数
loss_lm=(loss_lm.float()).mean()
# for sentence classification
loss_clsf=criterion(logits_clsf,isNext)
loss=loss_clsf+loss_lm
if (epoch+1)%10==0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
测试
这里只采用了单个样本模拟Evaluation的过程.
'''
测试代码
'''
# Predict mask tokens ans isNext
input_ids,segment_ids,masked_tokens,masked_pos,isNext=batch[0]
print(text)
print([idx2word[w] for w in input_ids if idx2word[w] != '[PAD]'])
logits_lm,logits_clsf=model(torch.LongTensor([input_ids]),
torch.LongTensor([segment_ids]),
torch.LongTensor([masked_pos]))
logits_lm=logits_lm.data.max(2)[1][0].data.numpy()
print('masked tokens list : ',[pos for pos in masked_tokens if pos != 0])
print('predict masked tokens list : ',[pos for pos in logits_lm if pos != 0])
logits_clsf = logits_clsf.data.max(1)[1].data.numpy()[0]
print('isNext : ', True if isNext else False)
print('predict isNext : ',True if logits_clsf else False)
Fine-Tuning
参考自wmathor
-
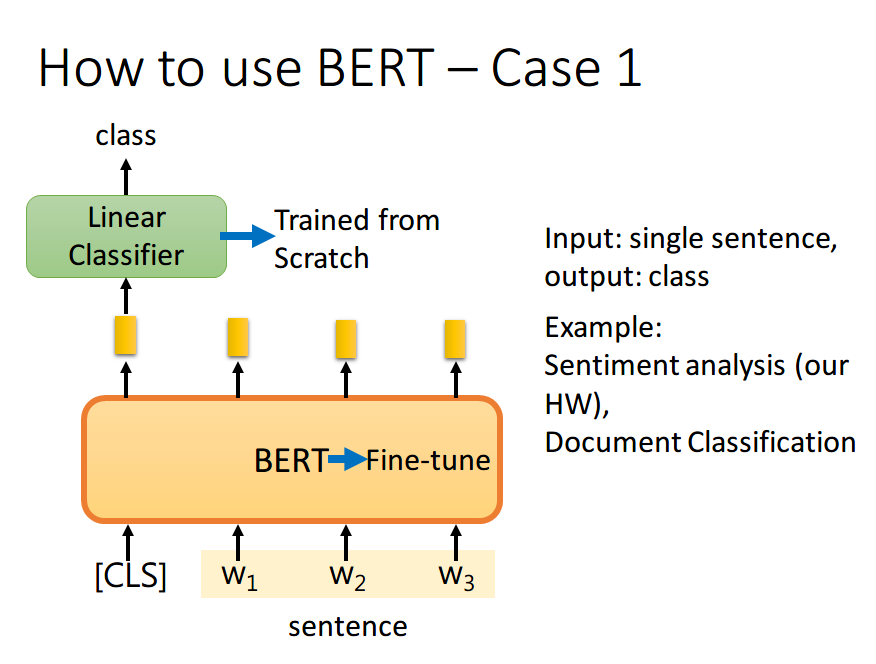
BERT 的 Fine-Tuning 共分为 4 中类型,以下内容、图片均来自台大李宏毅老师 Machine Learning 课程(以下内容 图在上,解释在下)
-
如果现在的任务是 classification,首先在输入句子的开头加一个代表分类的符号 [CLS],然后将该位置的 output,丢给 Linear Classifier,让其 predict 一个 class 即可。整个过程中 Linear Classifier 的参数是需要从头开始学习的,而 BERT 中的参数微调就可以了
这里李宏毅老师有一点没讲到,就是为什么要用第一个位置,即 [CLS] 位置的 output。这里我看了网上的一些博客,结合自己的理解解释一下。因为 BERT 内部是 Transformer,而 Transformer 内部又是 Self-Attention,所以 [CLS] 的 output 里面肯定含有整句话的完整信息,这是毋庸置疑的。但是 Self-Attention 向量中,自己和自己的值其实是占大头的,现在假设使用 的 output 做分类,那么这个 output 中实际上会更加看重 ,而 又是一个有实际意义的字或词,这样难免会影响到最终的结果。但是 [CLS] 是没有任何实际意义的,只是一个占位符而已,所以就算 [CLS] 的 output 中自己的值占大头也无所谓。当然你也可以将所有词的 output 进行 concat,作为最终的 output.
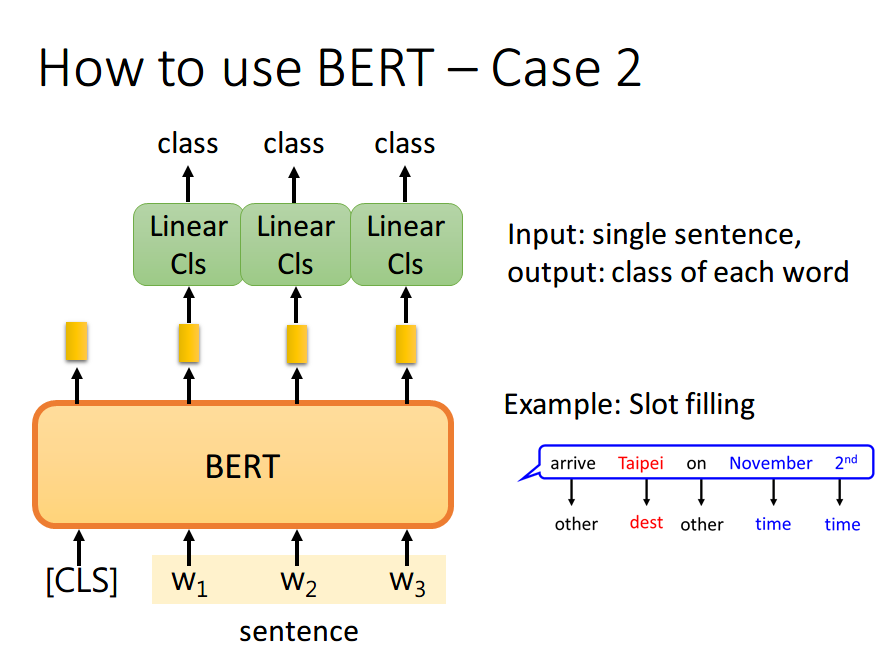
- 如果现在的任务是 Slot Filling,将句子中各个字对应位置的 output 分别送入不同的 Linear,预测出该字的标签。其实这本质上还是个分类问题,只不过是对每个字都要预测一个类别

- 如果现在的任务是 NLI(自然语言推理)。即给定一个前提,然后给出一个假设,模型要判断出这个假设是 正确、错误还是不知道。这本质上是一个三分类的问题,和 Case 1 差不多,对 [CLS] 的 output 进行预测即可

- 如果现在的任务是 QA(问答),举例来说,如上图,将一篇文章,和一个问题(这里的例子比较简单,答案一定会出现在文章中)送入模型中,模型会输出两个数 s,e,这两个数表示,这个问题的答案,落在文章的第 s 个词到第 e 个词。具体流程我们可以看下面这幅图

- 首先将问题和文章通过 [SEP] 分隔,送入 BERT 之后,得到上图中黄色的输出。此时我们还要训练两个 vector,即上图中橙色和黄色的向量。首先将橙色和所有的黄色向量进行 dot product,然后通过 softmax,看哪一个输出的值最大,例如上图中 对应的输出概率最大,那我们就认为 s=2

- 同样地,我们用蓝色的向量和所有黄色向量进行 dot product,最终预测得 的概率最大,因此 e=3。最终,答案就是 s=2,e=3
你可能会觉得这里面有个问题,假设最终的输出 s>e 怎么办,那不就矛盾了吗?其实在某些训练集里,有的问题就是没有答案的,因此此时的预测搞不好是对的,就是没有答案
本文来自博客园,作者:xingye_z,转载请注明原文链接:https://www.cnblogs.com/xyzhrrr/p/15862893.html
