
self-attention 详解
参考自李宏毅老师的self-atention的课程
pd下载:self-atention、Transformer
理论说明
在NLP中,常用的计算两个向量之间相关性的方法有以下两种:

self-attention中用的就是左侧的类型,将两个向量乘以一个可训练权重,然后将结构进行对应相乘,得到最终的相关性\({\alpha}\)。
基于此,以计算b1(即所有向量对第一个向量的重要信息的抽取结果,b1并不代表最先计算,都是同时进行的)为例进行说明:

-
当输入一长串输入时(a1、a2...,可以为input也有可能是上一步隐藏层输出)时,要求b1首先要求出其余所有向量对a1的相互关系,也就是用到了刚开始介绍的方法。其中要求的a1对应的q1就是Q,其余对应的即为K

其中\({\alpha}_{1,2}\)就是代表着query是1提供的,key是2提供的,即计算的a2对a1的相关性。 -
需要说明的是,q1还需与自己k1计算相关性即\({\alpha}_{1,2}\),然后将所有的相关性通过一个softmax层,得到所有向量对a1的对应相关性大小比例(都映射到了0~1直接,且和为1)。

-
根据上面softmax输出结果,我们就获知了哪些相对对于a1比较重要,就可以抽取相应的重要信息{v1,v2....},然后将v与对应的softmax(q*v)相乘在求和(即加权求和)即可求得b1

矩阵计算
下面用矩阵形式对自注意力的公式进行解读:
-
首先是Q、K、V的产生:

-
相关性的计算,以及通过softmax候的结果(标准化了):

-
求出O(注意力的结果):

-
总览:

与下面的公式相比只是没有除以根号维度而已。

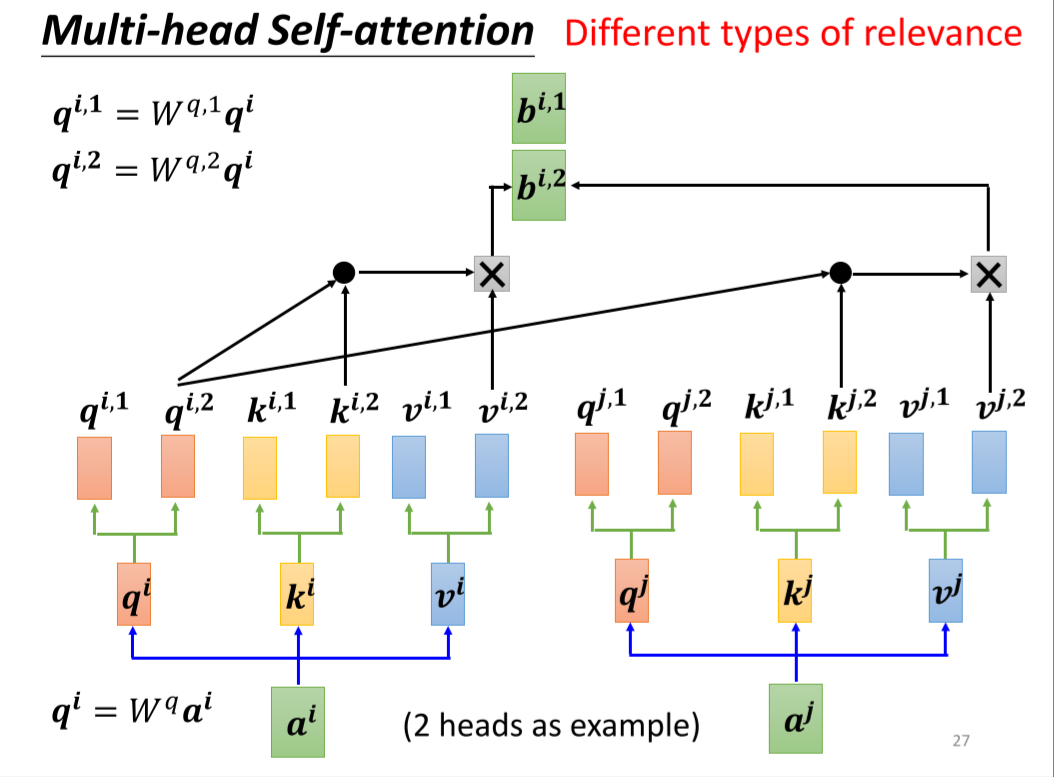
多头的自注意力


本文来自博客园,作者:xingye_z,转载请注明原文链接:https://www.cnblogs.com/xyzhrrr/p/15584848.html

