

第五课第四周笔记4:Transformer Network变压器网络
Transformer Network变压器网络
你已经了解了 self attention,你已经了解了 multi headed attention。在这个视频中,让我们把它们放在一起来构建一个变压器网络。您将看到如何将之前视频中看到的注意力机制配对来构建转换器架构。再次从句子 Jane Visite the feet on September 及其相应的嵌入开始。让我们来看看如何将句子从法语翻译成英语。我还在此处添加了句首和句尾标记。到目前为止,为了简单起见,我只讨论了句子中单词的嵌入。但是在许多序列的序列翻译任务中,在句子的开头或 SOS(开始符) 和句子的结尾或我在此示例中拥有的 EOS(结束符) 令牌也将很有用。
-
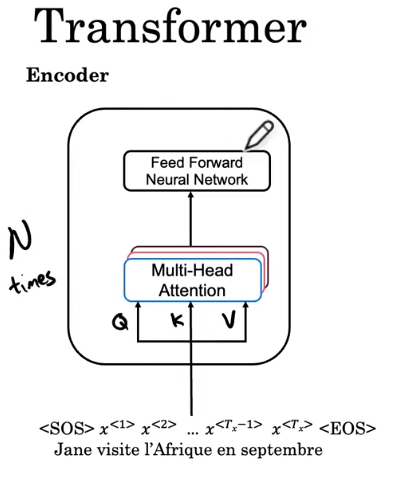
Transformer 的第一步是将这些嵌入输入到一个编码器块中,该编码器块在那里具有多头注意力。所以这正是你在上一张幻灯片中看到的,你输入了从嵌入和权重矩阵 W 计算出的值 Q K 和 V。然后这一层产生一个矩阵,可以传递到一个前馈神经网络。这有助于确定句子中有哪些有趣的特征。在 Transformer 论文中,这个块,这个编码块重复 N 次,N 的典型值为 6。
-
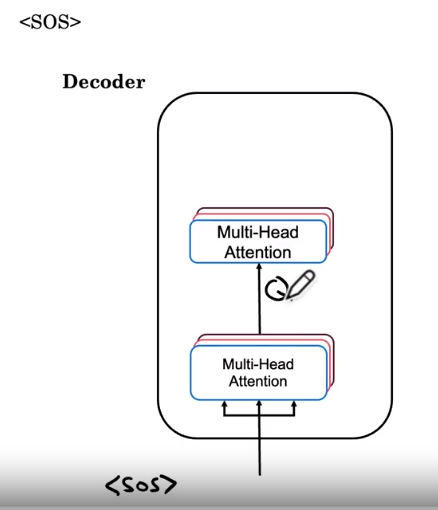
所以在通过这个块大约六次之后,我们将把编码器的笨拙输入到解码器块中。 让我们开始构建解码器块。 而解码器块的工作是输出英文翻译。 所以第一个输出将是句子标记的开始,我已经在这里写下了。 在每一步,解码器块都会输入我们已经生成的翻译的前几个词。 当我们刚刚开始时,我们唯一知道的是翻译将以句子标记开头。 因此,开始一个句子标记被输入到这个多头注意力块中。 而就这一个标记,SOS 标记看到的句子用于计算这个多头注意力块的 Q K 和 V。
-
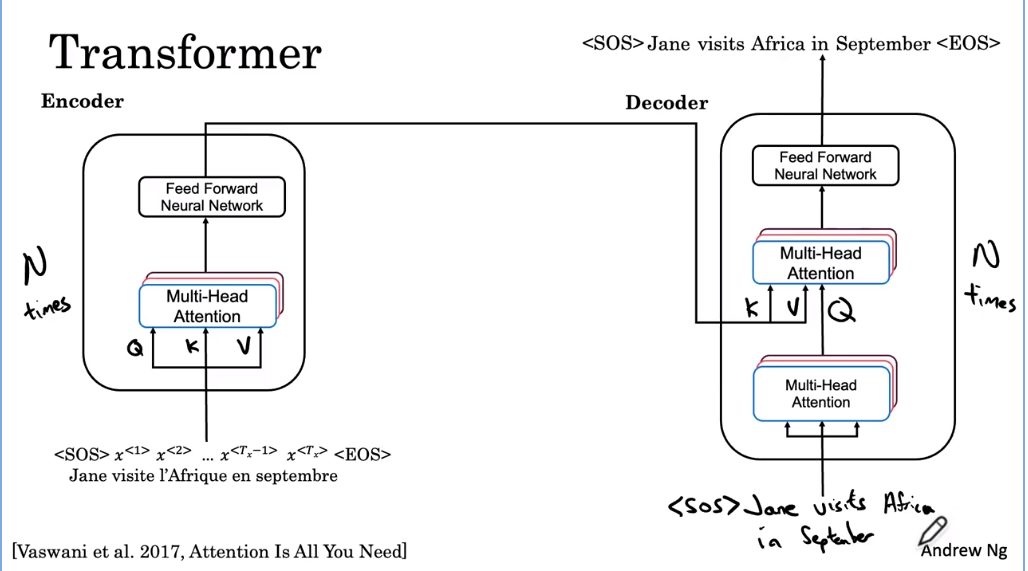
第一个块,输出用于为下一个多头注意块生成 Q 矩阵。编码器的输出用于生成 K 和 V。所以这里是第二个多头滞留块,输入 Q、K 和 V 和以前一样。为什么是这样的结构?也许这是一种直觉,希望这里的输入是您迄今为止对句子的任何翻译。所以这也将询问句子的开头是什么,然后它会从 K 和 V 中提取上下文,这是从句子的法语版本翻译过来的。然后尝试决定要生成的序列中的下一个单词是什么。为了完成解码器块的描述,多头延迟块输出馈送神经网络的值。这个解码器块也将重复 N 次,可能是六次,在你获取输出的地方,将它反馈给输入,然后让它经历六次。
-
这个新网络的工作是预测句子中的下一个单词。所以希望它会决定英文翻译中的第一个单词是 Jane,然后我们所做的就是将 Jane 输入到输入中。现在下一个查询来自 SOS 和 Jane,它说,鉴于 Jane,最合适的昵称是什么。让我们找到正确的键和正确的值,让我们生成最合适的下一个单词,希望这会生成 Visite。然后再次运行这个神经网络生成Africa,然后我们将Africa反馈到输入中。希望它随后在 septembe和此输入中生成,希望它生成句尾标记,然后我们就完成了。
这些编码器和解码器块以及它们如何组合以执行序列和序列翻译任务是转换架构背后的主要思想。在本例中,您看到了如何将输入的句子翻译成另一种语言的句子,以获得关于如何将注意力和网络结合起来以允许同时计算的一些直觉。但是除了这些主要思想之外,还有一些额外的花里胡哨可以改变它。让我通过这些额外的花里胡哨来简要介绍这些步骤,使变压器网络工作得更好。
-
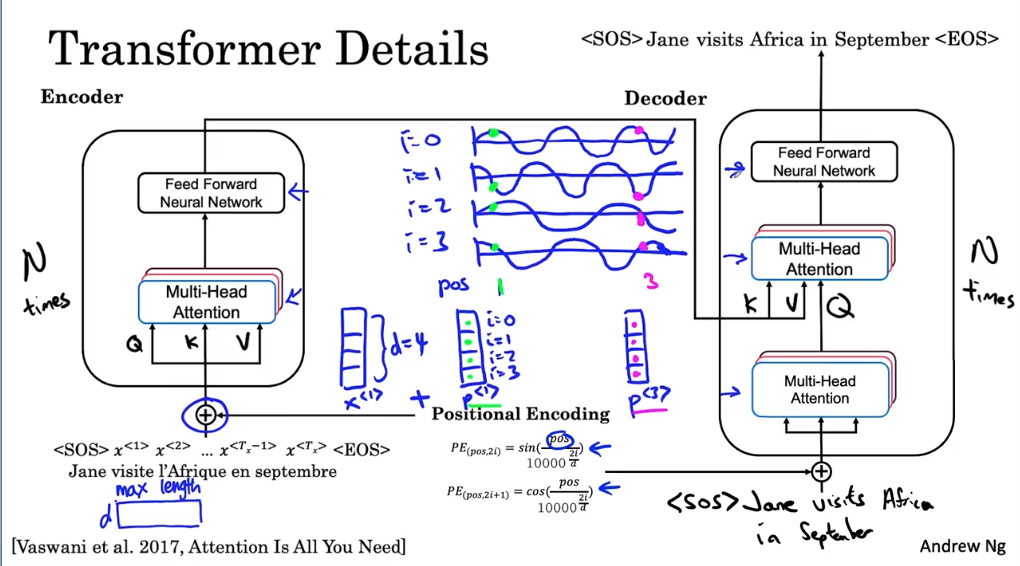
第一个是输入的位置编码。如果你回忆一下自我注意方程,就没有任何东西可以表明一个词的位置。这个词,在句子中的第一个词,在句子中的最后一个词的中间。但是句子中的位置对于翻译来说可能非常重要。因此,您对输入中元素的位置进行编码的方式是使用这些正弦和余弦方程的组合。
-
例如,假设您的词嵌入是一个具有四个值的向量。在这种情况下,词嵌入的维度 D 是 4。所以 X1、X2、X3 假设它们是四维向量。在这个例子中,我们将创建一个嵌入在相同维度向量中的位置。也是四维的,我将把这个位置嵌入称为 P1。假设第一个单词 Jane 的位置嵌入。

-
在的这个等式中,pos position 表示单词的数字位置。所以对于Jane这个词,pos等于1,我这里指的是编码的不同维度。所以第一个元素响应 I 等于 0。这个元素 i 等于 1,i 等于 2,i 等于 3。所以这些是变量 pos 和 i 进入下面这些方程,其中 pos 是单词的位置。 i 从 0 到 3,d 等于 4 作为该因子的维度。位置编码对正弦和余弦的作用是创建一个唯一的位置编码向量。这些向量之一对于每个单词都是唯一的。所以编码freak(法语输入) 位置的向量 P3,第三个词将是一组四个值。它们会有所不同,然后使用的四个值对 Jane 的第一个单词的位置进行编码。这就是正弦和余弦曲线的样子。是的,i = 0,i = 1,i = 2,我等于 3。因为你有这些项和分母,你最终得到 i = 0。我们会有一些像这样的正弦或曲线,i = 1 会是匹配余弦。
-
所以在表面 9°。 i cos 2 我们最终会得到像这样的较低频率的正弦曲线,i cos 3 为您提供匹配的余弦曲线。
因此,对于 P1,对于位置 1,您可以读取用于填充这四个值的值。 而对于不同位置的不同单词,现在可能是横轴上的 3。 您读取一组不同的值并注意到前两个值可能非常相似,因为它们的高度大致相同。 但是通过使用这些多个正弦和余弦,然后查看所有四个值,P3 将是一个与 P1 不同的向量。 所以将编码P1的位置直接加到X1上就这样输入了。 因此,每个词向量也受到词在句子中出现的位置的影响或颜色。
编码块的输出包含上下文语义嵌入和位置编码信息。 然后嵌入层的输出是 d,在这种情况下是 4 乘以您母亲可以采用的最大序列长度。 所有这些层的输出也是这种形状。
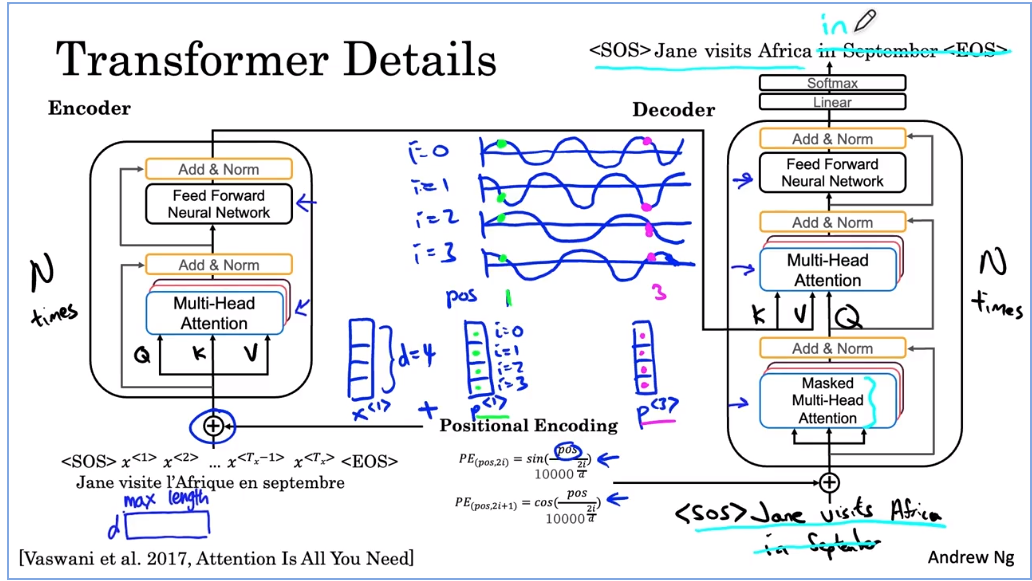
除了将这些位置编码添加到嵌入中之外,您还可以将它们通过具有残差连接的网络传递。这些残留连接类似于您之前在树脂中看到的连接。在这种情况下,它们的目的是在整个架构中传递位置信息。除了位置编码之外,transformer 网络还使用了一个非常类似于 bash 规范的层。在这种情况下,它们的目的是传递位置信息,即位置编码。转换器还使用了一个称为腺组(adenome)的层。这与您已经熟悉的national layer非常相似。
就本视频而言,请不要担心差异。将其视为与 bash 规范非常相似的角色,只是有助于加快学习速度。而这个 bash 规范层只是添加规范层在整个架构中重复。最后,对于解码器块的输出,实际上还有一个线性层,然后是一个 softmax 层,一次一个单词地预测下一个单词。
如果您阅读有关变压器网络的文献,您可能还会听到称为掩码多头注意(mask multi -head attention)的东西。我们应该只把它画在这里。掩码多头注意力仅在训练过程中很重要,在该过程中您使用正确的法语到英语翻译的数据集来训练您的变压器。所以之前我们逐步介绍了 Transformer 如何执行预测,一次一个词,但它是如何训练的?假设您的数据集具有正确的法语到英语翻译,Jane Visite freak on September 和 Jane visits Africa in September。在训练时,您可以访问完整的正确英文翻译、正确的输出和正确的输入。并且因为您拥有完全正确的输出,所以您实际上不必在训练期间一次生成一个单词。相反,掩码的作用是屏蔽句子的最后一部分,以模仿网络在测试时或预测期间需要做的事情。换句话说,掩码多头注意力所做的一切只是反复假装网络已经完美翻译。说出前几个单词并隐藏其余单词,看看是否给出了完美的第一部分翻译,神经网络是否可以准确预测序列中的下一个单词。以上是对转换架构的总结。
由于论文注意力就是你所需要的,所以这个模型还有很多其他的迭代。
本文来自博客园,作者:xingye_z,转载请注明原文链接:https://www.cnblogs.com/xyzhrrr/p/15306270.html

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步