
第五课第四周笔记1:Transformer Network Intuition 变压器网络直觉
Transformer Network Intuition 变压器网络直觉
深度学习中最令人兴奋的发展之一是 Transformer Network,有时也称为 Transformers。这是一种完全席卷 NLP 世界的架构。当今许多最有效的 NLP 专辑都是基于 Transformer 架构的。它是一个相对复杂的神经网络架构,但在这个和接下来的三个视频中将逐个介绍。因此,在接下来的四个视频结束时,您将对 Transformer Network 的工作原理有一个很好的了解,我们将能够应用零问题。随着序列任务的复杂性增加,模型的复杂性也会增加。
我们从 RNN 开始这门课程,发现它在梯度消失方面存在一些问题,这使得很难捕获长距离依赖关系和序列。然后,我们将 GRU 和 LSTM 模型视为解决许多可能使用门来控制信息流的问题的方法。
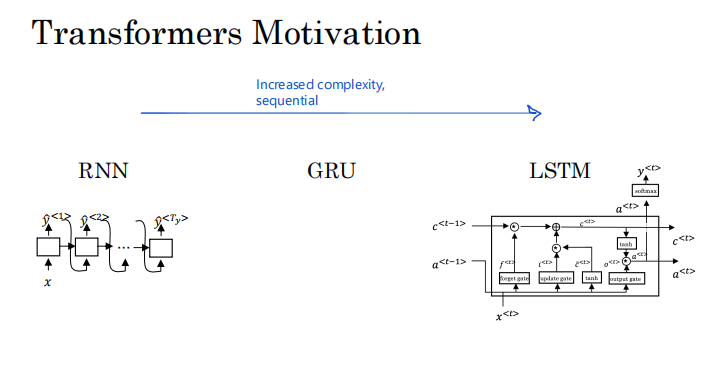
所以这些单元中的每一个都有更多的计算。虽然这些版本改进了对信息流的控制,但也增加了复杂性。因此,随着我们从 RNN 到 GRU 再到 LSTM,模型变得更加复杂(见上图)。所有这些模型仍然是顺序模型,因为它们摄取了输入,可能是当时输入的句子一个词或一个标记。因此,就好像每个单元都像是信息流的瓶颈。因为例如,要计算这个最终单元的输出,您首先必须计算之前出现的所有单元的输出。
在本视频中,您了解了 Transformer 架构,它允许您为整个序列并行运行更多此类计算。因此,您可以同时摄取整个句子,而不是一次从左到右处理一个单词。 Transformer Network 发表在 Vaswani、Norm Shakespeare、Nikki Palmer、Jacob 很棒、行 James、Gomez、Lucas Kaiser 和更早的波兰人的开创性论文中。 Transformer 网络的发明者之一 Lucas Kaiser 也是 NLP 专业与深度学习 dot AI 的联合讲师。
所以当你完成这个深度学习专业化后,你也可以检查一下。 Transformer 架构的主要创新是结合使用基于注意力的表示和 CNN 卷积神经网络处理方式。因此,RNN 可能一次处理一个输出,因此可能 y(0) 向它们馈送您计算 y(1) 的信息,然后将其用于计算 y(2)。
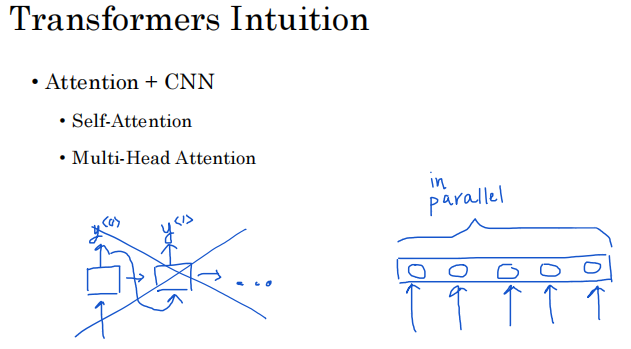
这是处理标记的非常顺序的方式,您可能会将其与 CNN 进行对比,或者有信心可以输入大量像素。是的,或者可能有很多单词,并且可以并行计算它们的表示。所以你在注意力网络中看到的是一种计算非常丰富、非常有用的单词表示的方法。但是有一些更类似于这种 CNN 风格的并行处理。为了理解注意力网络,接下来的几个视频中将涉及两个关键思想。首先是自我关注。 self attention 的目标是,如果你有一个包含五个单词的句子,最终会计算这五个单词的五个表示,将写成 A1、A2、A3、A4 和 A5。这将是一种基于注意力的并行计算句子中所有单词表示的方式。
然后多头注意力(Multi—Head Attention)是自我注意过程的基本 循环。所以你最终会得到这些表示的多个版本。事实证明,这些表示将是非常丰富的表示,可用于机器翻译或其他 NLP 折腾以创造有效性。
所以在下一个视频中,让我们开始学习自我注意,计算这些丰富的表示。之后的视频,我们将讨论多头注意力。然后关于转换网络的最终视频会将所有这些放在一起,以便您了解整个转换器架构是如何工作的。让我们进入下一个视频。
本文来自博客园,作者:xingye_z,转载请注明原文链接:https://www.cnblogs.com/xyzhrrr/p/15303267.html

