元强化学习算法:MAML —— 实验环境的分析 —— half_cheetah —— gym和gymnasium
元强化学习算法,在几年前曾经火热过一小段时间,然后就几乎是销声匿迹了,虽然现在也偶尔有这个方向的research paper发表,不过也都是那最早的那几篇基础上改动不大,几乎就是个缝合怪,自己当年也是入了这个坑,搞了这个研究方向,也就一直搞到了如今。
元强化学习算法最为有代表的就是MAML算法,其实这个称呼不准确,全称应该是MAML-TRPO算法,而之后的元强化学习算法也都会借鉴这个算法并且也大多会使用这个算法所使用的实验环境和配置,但是由于过去了好多年,虽然这个方向也还有人在搞,但是也属于小众冷门方向了,这个元强化学习算法的实验环境也一直没有人在维护,现在网上的公开环境还是最早的MAML的那个版本,但是gym都升级了好多版本,甚至gym都被弃用,然后出现了整合升级版的gymnasium,这时候如果还想接着使用最早的MAML的元强化学习的实验环境就只能用最早的配置环境,比如python3.7或者python3.8,然后gym和mujoco都是使用最早的那些版本,而这又导致最终配置出的环境和最新的很多软件不兼容,这种问题一直也没有人解决,为此,也为一劳永逸,于是决定将MAML的元强化学习的实验环境升级到最新的python版本,本文即为对此的记录。
目前元强化学习的python环境如下:
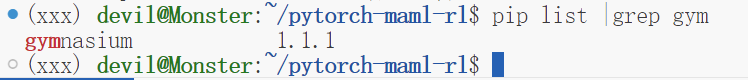

我们需要作的事情就是把元强化学习的实验环境环境的代码进行修改和升级,以使其可以兼容上面的运行环境版本。
给出 half_cheetah 环境的老版本的代码,下面的代码已经进行了初步的修改,该代码已经可以与最新版本的gym和mujoco进行兼容。
import numpy as np
from gymnasium.envs.mujoco.half_cheetah_v5 import HalfCheetahEnv as HalfCheetahEnv_
class HalfCheetahEnv(HalfCheetahEnv_):
def _get_obs(self):
return np.concatenate([
self.data.qpos.flat[1:],
self.data.qvel.flat,
self.get_body_com("torso").flat,
]).astype(np.float32).flatten()
def viewer_setup(self):
camera_id = self.model.camera_name2id('track')
self.viewer.cam.type = 2
self.viewer.cam.fixedcamid = camera_id
self.viewer.cam.distance = self.model.stat.extent * 0.35
# Hide the overlay
self.viewer._hide_overlay = True
def render(self, mode='human'):
if mode == 'rgb_array':
self._get_viewer().render()
# window size used for old mujoco-py:
width, height = 500, 500
data = self._get_viewer().read_pixels(width, height, depth=False)
return data
elif mode == 'human':
self._get_viewer().render()
class HalfCheetahVelEnv(HalfCheetahEnv):
"""Half-cheetah environment with target velocity, as described in [1]. The
code is adapted from
https://github.com/cbfinn/maml_rl/blob/9c8e2ebd741cb0c7b8bf2d040c4caeeb8e06cc95/rllab/envs/mujoco/half_cheetah_env_rand.py
The half-cheetah follows the dynamics from MuJoCo [2], and receives at each
time step a reward composed of a control cost and a penalty equal to the
difference between its current velocity and the target velocity. The tasks
are generated by sampling the target velocities from the uniform
distribution on [0, 2].
[1] Chelsea Finn, Pieter Abbeel, Sergey Levine, "Model-Agnostic
Meta-Learning for Fast Adaptation of Deep Networks", 2017
(https://arxiv.org/abs/1703.03400)
[2] Emanuel Todorov, Tom Erez, Yuval Tassa, "MuJoCo: A physics engine for
model-based control", 2012
(https://homes.cs.washington.edu/~todorov/papers/TodorovIROS12.pdf)
"""
def __init__(self, task={}, low=0.0, high=2.0):
self._task = task
self.low = low
self.high = high
self._goal_vel = task.get('velocity', 0.0)
super(HalfCheetahVelEnv, self).__init__()
def step(self, action):
xposbefore = self.data.qpos[0]
self.do_simulation(action, self.frame_skip)
xposafter = self.data.qpos[0]
forward_vel = (xposafter - xposbefore) / self.dt
forward_reward = -1.0 * abs(forward_vel - self._goal_vel)
ctrl_cost = 0.5 * 1e-1 * np.sum(np.square(action))
observation = self._get_obs()
reward = forward_reward - ctrl_cost
done = False
infos = dict(reward_forward=forward_reward,
reward_ctrl=-ctrl_cost,
task=self._task)
return (observation, reward, done, "", infos)
def sample_tasks(self, num_tasks):
velocities = self.np_random.uniform(self.low, self.high, size=(num_tasks,))
tasks = [{'velocity': velocity} for velocity in velocities]
return tasks
def reset_task(self, task):
self._task = task
self._goal_vel = task['velocity']
class HalfCheetahDirEnv(HalfCheetahEnv):
"""Half-cheetah environment with target direction, as described in [1]. The
code is adapted from
https://github.com/cbfinn/maml_rl/blob/9c8e2ebd741cb0c7b8bf2d040c4caeeb8e06cc95/rllab/envs/mujoco/half_cheetah_env_rand_direc.py
The half-cheetah follows the dynamics from MuJoCo [2], and receives at each
time step a reward composed of a control cost and a reward equal to its
velocity in the target direction. The tasks are generated by sampling the
target directions from a Bernoulli distribution on {-1, 1} with parameter
0.5 (-1: backward, +1: forward).
[1] Chelsea Finn, Pieter Abbeel, Sergey Levine, "Model-Agnostic
Meta-Learning for Fast Adaptation of Deep Networks", 2017
(https://arxiv.org/abs/1703.03400)
[2] Emanuel Todorov, Tom Erez, Yuval Tassa, "MuJoCo: A physics engine for
model-based control", 2012
(https://homes.cs.washington.edu/~todorov/papers/TodorovIROS12.pdf)
"""
def __init__(self, task={}):
self._task = task
self._goal_dir = task.get('direction', 1)
super(HalfCheetahDirEnv, self).__init__()
def step(self, action):
xposbefore = self.data.qpos[0]
self.do_simulation(action, self.frame_skip)
xposafter = self.data.qpos[0]
forward_vel = (xposafter - xposbefore) / self.dt
forward_reward = self._goal_dir * forward_vel
ctrl_cost = 0.5 * 1e-1 * np.sum(np.square(action))
observation = self._get_obs()
reward = forward_reward - ctrl_cost
done = False
infos = dict(reward_forward=forward_reward,
reward_ctrl=-ctrl_cost,
task=self._task)
return (observation, reward, done, infos)
def sample_tasks(self, num_tasks):
directions = 2 * self.np_random.binomial(1, p=0.5, size=(num_tasks,)) - 1
tasks = [{'direction': direction} for direction in directions]
return tasks
def reset_task(self, task):
self._task = task
self._goal_dir = task['direction']
其实,改动不大:
第一个地方:
from gymnasium.envs.mujoco.half_cheetah_v5 import HalfCheetahEnv as HalfCheetahEnv_
第二个地方:
return (observation, reward, done, "", infos)

并给出最新gymnasium下的v5版本实现的代码:
点击查看代码
__credits__ = ["Kallinteris-Andreas", "Rushiv Arora"]
from typing import Dict, Union
import numpy as np
from gymnasium import utils
from gymnasium.envs.mujoco import MujocoEnv
from gymnasium.spaces import Box
DEFAULT_CAMERA_CONFIG = {
"distance": 4.0,
}
class HalfCheetahEnv(MujocoEnv, utils.EzPickle):
r"""
## Description
This environment is based on the work of P. Wawrzyński in ["A Cat-Like Robot Real-Time Learning to Run"](http://staff.elka.pw.edu.pl/~pwawrzyn/pub-s/0812_LSCLRR.pdf).
The HalfCheetah is a 2-dimensional robot consisting of 9 body parts and 8 joints connecting them (including two paws).
The goal is to apply torque to the joints to make the cheetah run forward (right) as fast as possible, with a positive reward based on the distance moved forward and a negative reward for moving backward.
The cheetah's torso and head are fixed, and torque can only be applied to the other 6 joints over the front and back thighs (which connect to the torso), the shins (which connect to the thighs), and the feet (which connect to the shins).
## Action Space
```{figure} action_space_figures/half_cheetah.png
:name: half_cheetah
```
The action space is a `Box(-1, 1, (6,), float32)`. An action represents the torques applied at the hinge joints.
| Num | Action | Control Min | Control Max | Name (in corresponding XML file) | Joint | Type (Unit) |
| --- | --------------------------------------- | ----------- | ----------- | -------------------------------- | ----- | ------------ |
| 0 | Torque applied on the back thigh rotor | -1 | 1 | bthigh | hinge | torque (N m) |
| 1 | Torque applied on the back shin rotor | -1 | 1 | bshin | hinge | torque (N m) |
| 2 | Torque applied on the back foot rotor | -1 | 1 | bfoot | hinge | torque (N m) |
| 3 | Torque applied on the front thigh rotor | -1 | 1 | fthigh | hinge | torque (N m) |
| 4 | Torque applied on the front shin rotor | -1 | 1 | fshin | hinge | torque (N m) |
| 5 | Torque applied on the front foot rotor | -1 | 1 | ffoot | hinge | torque (N m) |
## Observation Space
The observation space consists of the following parts (in order):
- *qpos (8 elements by default):* Position values of the robot's body parts.
- *qvel (9 elements):* The velocities of these individual body parts (their derivatives).
By default, the observation does not include the robot's x-coordinate (`rootx`).
This can be included by passing `exclude_current_positions_from_observation=False` during construction.
In this case, the observation space will be a `Box(-Inf, Inf, (18,), float64)`, where the first observation element is the x-coordinate of the robot.
Regardless of whether `exclude_current_positions_from_observation` is set to `True` or `False`, the x- and y-coordinates are returned in `info` with the keys `"x_position"` and `"y_position"`, respectively.
By default, however, the observation space is a `Box(-Inf, Inf, (17,), float64)` where the elements are as follows:
| Num | Observation | Min | Max | Name (in corresponding XML file) | Joint | Type (Unit) |
| --- | ------------------------------------------- | ---- | --- | -------------------------------- | ----- | ------------------------ |
| 0 | z-coordinate of the front tip | -Inf | Inf | rootz | slide | position (m) |
| 1 | angle of the front tip | -Inf | Inf | rooty | hinge | angle (rad) |
| 2 | angle of the back thigh | -Inf | Inf | bthigh | hinge | angle (rad) |
| 3 | angle of the back shin | -Inf | Inf | bshin | hinge | angle (rad) |
| 4 | angle of the back foot | -Inf | Inf | bfoot | hinge | angle (rad) |
| 5 | angle of the front thigh | -Inf | Inf | fthigh | hinge | angle (rad) |
| 6 | angle of the front shin | -Inf | Inf | fshin | hinge | angle (rad) |
| 7 | angle of the front foot | -Inf | Inf | ffoot | hinge | angle (rad) |
| 8 | velocity of the x-coordinate of front tip | -Inf | Inf | rootx | slide | velocity (m/s) |
| 9 | velocity of the z-coordinate of front tip | -Inf | Inf | rootz | slide | velocity (m/s) |
| 10 | angular velocity of the front tip | -Inf | Inf | rooty | hinge | angular velocity (rad/s) |
| 11 | angular velocity of the back thigh | -Inf | Inf | bthigh | hinge | angular velocity (rad/s) |
| 12 | angular velocity of the back shin | -Inf | Inf | bshin | hinge | angular velocity (rad/s) |
| 13 | angular velocity of the back foot | -Inf | Inf | bfoot | hinge | angular velocity (rad/s) |
| 14 | angular velocity of the front thigh | -Inf | Inf | fthigh | hinge | angular velocity (rad/s) |
| 15 | angular velocity of the front shin | -Inf | Inf | fshin | hinge | angular velocity (rad/s) |
| 16 | angular velocity of the front foot | -Inf | Inf | ffoot | hinge | angular velocity (rad/s) |
| excluded | x-coordinate of the front tip | -Inf | Inf | rootx | slide | position (m) |
## Rewards
The total reward is: ***reward*** *=* *forward_reward - ctrl_cost*.
- *forward_reward*:
A reward for moving forward,
this reward would be positive if the Half Cheetah moves forward (in the positive $x$ direction / in the right direction).
$w_{forward} \times \frac{dx}{dt}$, where
$dx$ is the displacement of the "tip" ($x_{after-action} - x_{before-action}$),
$dt$ is the time between actions, which depends on the `frame_skip` parameter (default is $5$),
and `frametime` which is $0.01$ - so the default is $dt = 5 \times 0.01 = 0.05$,
$w_{forward}$ is the `forward_reward_weight` (default is $1$).
- *ctrl_cost*:
A negative reward to penalize the Half Cheetah for taking actions that are too large.
$w_{control} \times \|action\|_2^2$,
where $w_{control}$ is `ctrl_cost_weight` (default is $0.1$).
`info` contains the individual reward terms.
## Starting State
The initial position state is $\mathcal{U}_{[-reset\_noise\_scale \times I_{9}, reset\_noise\_scale \times I_{9}]}$.
The initial velocity state is $\mathcal{N}(0_{9}, reset\_noise\_scale^2 \times I_{9})$.
where $\mathcal{N}$ is the multivariate normal distribution and $\mathcal{U}$ is the multivariate uniform continuous distribution.
## Episode End
### Termination
The Half Cheetah never terminates.
### Truncation
The default duration of an episode is 1000 timesteps.
## Arguments
HalfCheetah provides a range of parameters to modify the observation space, reward function, initial state, and termination condition.
These parameters can be applied during `gymnasium.make` in the following way:
```python
import gymnasium as gym
env = gym.make('HalfCheetah-v5', ctrl_cost_weight=0.1, ....)
```
| Parameter | Type | Default | Description |
| -------------------------------------------- | --------- | -------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `xml_file` | **str** | `"half_cheetah.xml"` | Path to a MuJoCo model |
| `forward_reward_weight` | **float** | `1` | Weight for _forward_reward_ term (see `Rewards` section) |
| `ctrl_cost_weight` | **float** | `0.1` | Weight for _ctrl_cost_ weight (see `Rewards` section) |
| `reset_noise_scale` | **float** | `0.1` | Scale of random perturbations of initial position and velocity (see `Starting State` section) |
| `exclude_current_positions_from_observation` | **bool** | `True` | Whether or not to omit the x-coordinate from observations. Excluding the position can serve as an inductive bias to induce position-agnostic behavior in policies (see `Observation State` section) |
## Version History
* v5:
- Minimum `mujoco` version is now 2.3.3.
- Added support for fully custom/third party `mujoco` models using the `xml_file` argument (previously only a few changes could be made to the existing models).
- Added `default_camera_config` argument, a dictionary for setting the `mj_camera` properties, mainly useful for custom environments.
- Added `env.observation_structure`, a dictionary for specifying the observation space compose (e.g. `qpos`, `qvel`), useful for building tooling and wrappers for the MuJoCo environments.
- Return a non-empty `info` with `reset()`, previously an empty dictionary was returned, the new keys are the same state information as `step()`.
- Added `frame_skip` argument, used to configure the `dt` (duration of `step()`), default varies by environment check environment documentation pages.
- Restored the `xml_file` argument (was removed in `v4`).
- Renamed `info["reward_run"]` to `info["reward_forward"]` to be consistent with the other environments.
* v4: All MuJoCo environments now use the MuJoCo bindings in mujoco >= 2.1.3.
* v3: Support for `gymnasium.make` kwargs such as `xml_file`, `ctrl_cost_weight`, `reset_noise_scale`, etc. rgb rendering comes from tracking camera (so agent does not run away from screen).
* v2: All continuous control environments now use mujoco-py >= 1.50.
* v1: max_time_steps raised to 1000 for robot based tasks. Added reward_threshold to environments.
* v0: Initial versions release.
"""
metadata = {
"render_modes": [
"human",
"rgb_array",
"depth_array",
"rgbd_tuple",
],
}
def __init__(
self,
xml_file: str = "half_cheetah.xml",
frame_skip: int = 5,
default_camera_config: Dict[str, Union[float, int]] = DEFAULT_CAMERA_CONFIG,
forward_reward_weight: float = 1.0,
ctrl_cost_weight: float = 0.1,
reset_noise_scale: float = 0.1,
exclude_current_positions_from_observation: bool = True,
**kwargs,
):
utils.EzPickle.__init__(
self,
xml_file,
frame_skip,
default_camera_config,
forward_reward_weight,
ctrl_cost_weight,
reset_noise_scale,
exclude_current_positions_from_observation,
**kwargs,
)
self._forward_reward_weight = forward_reward_weight
self._ctrl_cost_weight = ctrl_cost_weight
self._reset_noise_scale = reset_noise_scale
self._exclude_current_positions_from_observation = (
exclude_current_positions_from_observation
)
MujocoEnv.__init__(
self,
xml_file,
frame_skip,
observation_space=None,
default_camera_config=default_camera_config,
**kwargs,
)
self.metadata = {
"render_modes": [
"human",
"rgb_array",
"depth_array",
"rgbd_tuple",
],
"render_fps": int(np.round(1.0 / self.dt)),
}
obs_size = (
self.data.qpos.size
+ self.data.qvel.size
- exclude_current_positions_from_observation
)
self.observation_space = Box(
low=-np.inf, high=np.inf, shape=(obs_size,), dtype=np.float64
)
self.observation_structure = {
"skipped_qpos": 1 * exclude_current_positions_from_observation,
"qpos": self.data.qpos.size
- 1 * exclude_current_positions_from_observation,
"qvel": self.data.qvel.size,
}
def control_cost(self, action):
control_cost = self._ctrl_cost_weight * np.sum(np.square(action))
return control_cost
def step(self, action):
x_position_before = self.data.qpos[0]
self.do_simulation(action, self.frame_skip)
x_position_after = self.data.qpos[0]
x_velocity = (x_position_after - x_position_before) / self.dt
observation = self._get_obs()
reward, reward_info = self._get_rew(x_velocity, action)
info = {"x_position": x_position_after, "x_velocity": x_velocity, **reward_info}
if self.render_mode == "human":
self.render()
# truncation=False as the time limit is handled by the `TimeLimit` wrapper added during `make`
return observation, reward, False, False, info
def _get_rew(self, x_velocity: float, action):
forward_reward = self._forward_reward_weight * x_velocity
ctrl_cost = self.control_cost(action)
reward = forward_reward - ctrl_cost
reward_info = {
"reward_forward": forward_reward,
"reward_ctrl": -ctrl_cost,
}
return reward, reward_info
def _get_obs(self):
position = self.data.qpos.flatten()
velocity = self.data.qvel.flatten()
if self._exclude_current_positions_from_observation:
position = position[1:]
observation = np.concatenate((position, velocity)).ravel()
return observation
def reset_model(self):
noise_low = -self._reset_noise_scale
noise_high = self._reset_noise_scale
qpos = self.init_qpos + self.np_random.uniform(
low=noise_low, high=noise_high, size=self.model.nq
)
qvel = (
self.init_qvel
+ self._reset_noise_scale * self.np_random.standard_normal(self.model.nv)
)
self.set_state(qpos, qvel)
observation = self._get_obs()
return observation
def _get_reset_info(self):
return {
"x_position": self.data.qpos[0],
}
posted on 2025-03-25 13:33 Angry_Panda 阅读(235) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号