深度强化学习中探索《蒙特祖马的复仇》与《陷阱》的突破:Go-Explore 算法
原地址:
https://www.uber.com/blog/go-explore/
在深度强化学习(RL)领域,攻克 Atari 游戏《蒙特苏马的复仇》和《陷阱》一直是一项重大挑战。这些游戏代表了一大类具有挑战性的现实问题,被称为“难以探索的问题”,在这些问题中,智能体必须在极其稀疏或具有欺骗性的反馈下学习复杂任务。
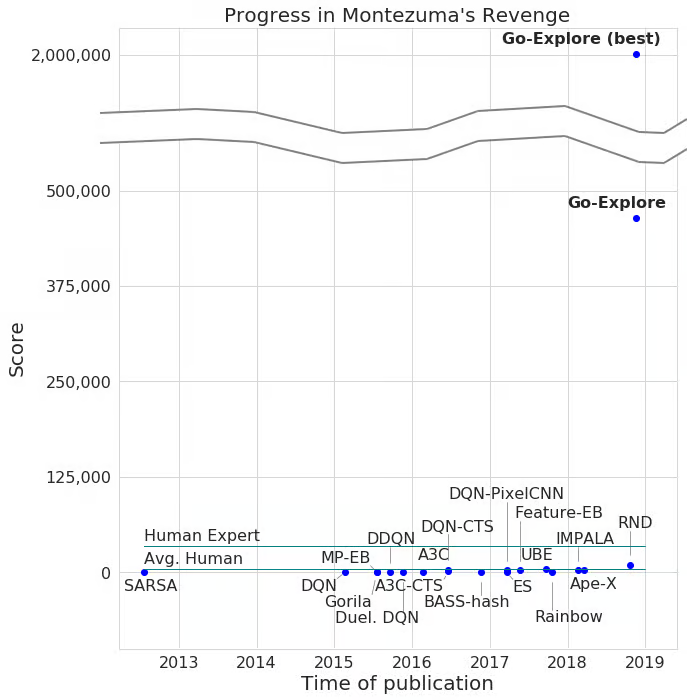
目前最先进的算法在《蒙特苏马的复仇》中能获得平均得分 11,347 分,最高得分达到 17,500 分,并且在十次尝试中有一次成功通过了第一关。令人惊讶的是,尽管投入了大量研究工作,到目前为止还没有任何算法能在《陷阱》中取得超过 0 分的成绩。
今天,我们推出了 Go-Explore——一类全新算法,其在《蒙特苏马的复仇》中能获得超过 200 万分的成绩,平均得分超过 40 万分!Go-Explore 能够稳定地解决整个游戏,也就是说,能够通过所有三个独特的关卡,并且能推广到后续几乎完全相同的关卡(这些关卡仅在事件时机和屏幕得分上存在差异)。我们甚至观察到它达到了第 159 关!
在《陷阱》游戏中,Go-Explore 的平均得分超过 21,000 分,远远超越了人类的平均表现,并且首次使任何学习算法在该游戏中得分突破 0。为此,它遍历了 40 个房间,这需要它在水面上用绳子荡过、跳过鳄鱼、陷阱门以及移动的桶、攀爬梯子,并应对其他各种危险。
总而言之,Go-Explore 在《蒙特苏马的复仇》和《陷阱》上的表现分别比现有最先进技术提高了两个数量级和 21,000 分。它不依赖人类示范,却能超越那些依赖人类示范来提供解法的模仿学习算法在《蒙特苏马的复仇》上的最先进表现。
Go-Explore 能够利用人类领域知识(而无需人类亲自解决整个任务来提供示范),以上结果便采用了这一点。所需的领域知识非常有限,而且可以直接从像素中轻松获取,这凸显了 Go-Explore 在利用最小先验知识方面的强大能力。然而,即使在没有任何领域知识的情况下,Go-Explore 在《蒙特苏马的复仇》中也能获得超过 35,000 分的成绩,比现有最先进方法高出三倍以上。
Go-Explore 与其他深度强化学习算法有着根本性的不同。我们认为,它能够在各种重要且具有挑战性的问题上实现快速突破,特别是在机器人领域。因此,我们期待它能帮助 Uber 以及其他团队越来越好地利用人工智能的优势。
更新: 我们鼓励您阅读下文标题为 “关于随机性问题的更新” 的新部分,以了解我们的结果与基准测试其他变体之间的关系。
更新 2: 我们现已发布了一篇关于 Go-Explore 的论文以及相应的源代码。
探索的挑战
奖励稀少的问题非常困难,因为随机行为不太可能产生奖励,从而使得学习变得不可能。《蒙特苏马的复仇》正是这样一个“稀疏奖励问题”。更棘手的是奖励具有欺骗性,这意味着追求短期奖励的最大化会让智能体学到错误的策略,从而无法实现整体上更高的得分。《陷阱》在这方面尤为具有欺骗性,因为许多动作会带来微小的负奖励(例如击中敌人),以致大多数算法学会根本不移动,从而永远无法学会收集难以获得的宝藏。许多具有挑战性的现实问题既稀疏又具有欺骗性。
普通的强化学习算法通常无法走出《蒙特苏马的复仇》的第一个房间(得分通常在 400 分或更低),而在《陷阱》中得分则为 0 或更低。为了解决这些挑战,研究人员为智能体增加了探索奖励,通常称为内在动机(IM),以奖励它们到达新的状态(即新的情境或位置)。尽管内在动机算法专门设计来应对稀疏奖励问题,但它们在《蒙特苏马的复仇》和《陷阱》上依然表现不佳。即便是最优秀的算法也很少能解决《蒙特苏马的复仇》的第一关,而在《陷阱》上更是完全失败,得分为零。
我们假设,当前内在动机算法的一个主要弱点在于“脱节”问题——算法会忘记它们曾经访问过的有前景区域,因而不会回到这些区域来验证是否能发现新的状态。举例来说,设想一个智能体处于两个迷宫入口之间。它可能偶然开始探索西侧迷宫,内在动机会促使它学会穿越大约 50% 的区域。但由于当前算法会通过在动作或参数上引入随机性来尝试新的行为,以期获得明确或内在奖励,智能体可能会在某一时刻开始探索东侧迷宫,并在那里同样获得大量内在奖励。完全探索完东侧迷宫后,它对在西侧迷宫中曾经放弃的有前景的探索前沿没有任何明确记忆。由于众所周知的人工智能中的灾难性遗忘问题,它可能也不会有隐性的记忆。更糟糕的是,通向西侧迷宫前沿的路径已经被探索过,因此几乎没有内在动机去重新发现它。我们因此认为,该算法已经与提供内在动机的状态前沿脱节。结果,当智能体当前所在区域附近的区域已经被探索完毕时,探索便可能陷入停滞。如果智能体能够返回之前发现的有前景区域继续探索,这一问题就能得到解决。

【图例说明】内在动机(IM)算法中脱节的示例。绿色区域表示内在奖励,白色区域表示没有内在奖励的区域,而紫色区域表示算法当前正在探索的区域。
Go-Explore

【图例说明】Go-Explore 算法的高级概述。
Go-Explore 将学习过程分为两个步骤:探索与稳健化。
第一阶段:探索直到问题解决
Go-Explore 构建了一个存档,记录了各种有趣且不同的游戏状态(我们称之为“单元”)以及通向这些状态的轨迹,具体步骤如下:
重复以下过程,直到问题解决:
- 从存档中以概率方式选择一个单元(可选地优先选择那些更有前景的单元,例如较新的单元)
- 返回到该单元
- 从该单元开始探索(例如,随机探索 n 步)
- 对于所有访问到的单元(包括新发现的单元),如果新的轨迹更优(例如得分更高),则将其替换为到达该单元的轨迹
通过在存档中显式存储多种探索的垫脚石,Go-Explore 能够记住并返回到有前景的区域进行探索(这与使用内在动机训练策略时通常会发生的情况不同)。此外,通过先返回到单元再从该处开始探索(优先选择那些遥远且难以到达的单元),Go-Explore 避免了对容易到达状态(例如起始点附近)的过度探索,而是专注于扩展其知识范围。最后,由于 Go-Explore 尝试访问所有可到达的状态,它对欺骗性奖励函数的敏感性也大大降低。对于熟悉质量多样性算法(QD)的读者来说,这些理念会很熟悉,我们下文将讨论 Go-Explore 如何代表了一种新型的质量多样性算法。
第二阶段:稳健化(如有必要)
如果找到的解决方案对于噪声不具备稳健性(正如我们在 Atari 游戏中的轨迹那样),则使用模仿学习算法将这些脆弱的轨迹稳健化为一个深度神经网络。
单元表示
为了在如 Atari 这样高维的状态空间中实现可行性,Go-Explore 需要一种低维的单元表示来构建存档。因此,单元表示应将那些足够相似、不值得单独探索的状态合并在一起(同时又不能将具有实质差异的状态混为一谈)。重要的是,我们证明了构造这种表示并不需要特定于游戏的领域知识。我们发现,也许最简单的单元表示方法——仅仅对当前游戏画面进行下采样——效果就非常不错。

【图例说明】下采样单元表示的示例。完整的可观察状态(彩色图像)被下采样为 11×8 的灰度图像,包含 8 种像素强度。
返回到单元
在开始探索前,返回到某个单元可以通过三种方式实现,具体取决于环境的约束条件,按效率排序如下:
在可重置的环境中,可以直接将环境状态重置为该单元的状态
在确定性环境中,可以通过重放轨迹返回到该单元
在随机环境中,可以训练一个目标条件策略,使其学会可靠地返回到某个单元
尽管大多数有趣的问题都具有随机性,但 Go-Explore 的一个关键见解是,我们可以先解决问题,再处理如何使解决方案更稳健(如果必要的话)。具体而言,与通常认为确定性是产生稳健且高性能智能体的障碍不同,我们可以利用这样一个事实:大多数模拟器都可以通过保存和恢复状态被设置为既确定性又可重置,之后还可以通过引入随机性(包括添加领域随机化)来生成更稳健的策略。这一观察对于机器人任务尤其相关,因为这些任务通常先在模拟中训练策略,再将其转移到现实世界中。
Atari 游戏是可重置的,因此出于效率考虑,我们通过加载游戏状态来返回到之前访问过的单元。在《蒙特苏马的复仇》中,这种优化使我们比单纯重放轨迹快了 45 倍地解决了第一关。但实际上,Go-Explore 的运作并不依赖于能够访问模拟器,这只是加快了运行速度。
在本工作中,当智能体返回到某个单元后,它仅通过采取随机动作(且有较大概率重复前一个动作)来进行探索。请注意,这种探索方式不需要神经网络或其他控制器,后续所有实验中的探索均未使用神经网络(尽管神经网络会用于稳健化阶段)。这种完全随机的探索方法能取得如此显著的效果,正凸显了仅仅返回到有趣单元这一做法的强大威力。
(后续 省略)
见原文:
https://www.uber.com/blog/go-explore/
posted on 2025-03-01 19:39 Angry_Panda 阅读(131) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号