
强化学习算法中的log_det_jacobian —— 概率分布的仿射变换(Bijector)(续)
前文:
强化学习算法中的log_det_jacobian —— 概率分布的仿射变换(Bijector)
前文说到概率分布的仿射变换(Bijector)在贝叶斯、变分推断等领域有很重要的作用,但是在强化学习中呢,其实在强化学习中也会用到,但是最为普遍的应用场景其实只是做简单的tanh变换。
在强化学习中一般用高斯分布来表示连续动作的策略,但是在很多应用环境中,如:人形机器人领域,连续动作的空间不是[-Inf, Inf],而是[-1, +1],这时则需要进行tanh变换,具体为:
X ~ Normal(loc, scale)
Y = tanh(X)
action = Y
可以看到,这是一种比较简单的概率分布的仿射变换(Bijector),如果按照前文给出的概率变换公式,我们可以得到action,即y的概率:
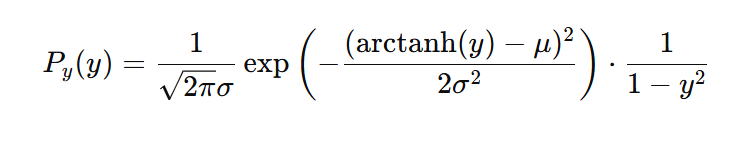
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2024-12-21 18:19 Angry_Panda 阅读(1) 评论(0) 编辑 收藏 举报


