

强化学习:基于课程学习的强化学习算法 —— 《Combining Reward Shaping and Curriculum Learning for Training Agents with High Dimensional Continuous Action Spaces》
地址:
https://www.tesble.com/10.1109/ICTC.2018.8539438

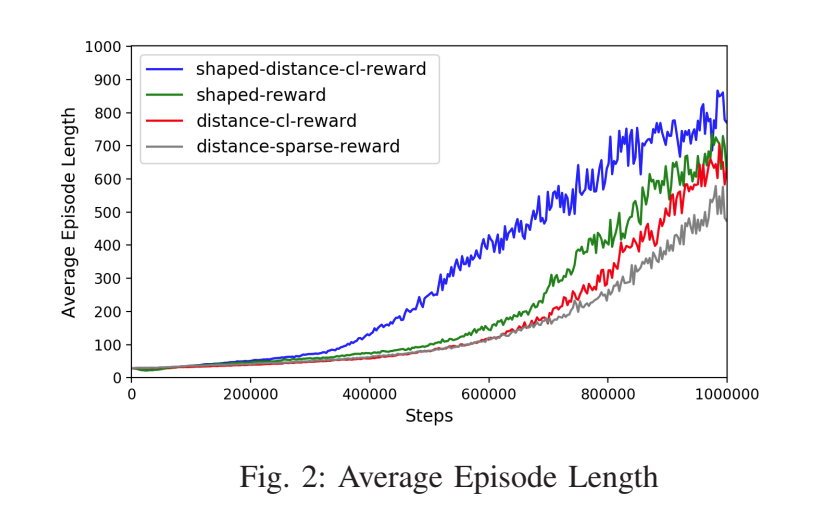
我们在四种不同的奖励函数和终止条件下对行走者进行了训练,以评估结合奖励塑形和课程学习的效果。具体如下。
1)距离稀疏奖励:行走者到达目标时给予1个奖励,否则为0。
2)距离课程奖励:给予行走者的奖励与行走者距离稀疏奖励情况相同,但随着行走者成功到达目标,目标的距离变得更远,即课程学习。
3)塑形奖励:根据行走者的身体部位,每一步都会给予奖励。具体来说,考虑了与目标方向的速度和对齐、头部高度和头部运动。这是Unity ML-Agent的默认设置。
4)塑形距离课程奖励:它是行走者默认奖励和行走者距离课程奖励的结合。
We have trained the walkers in four scenarios with varying
reward functions and termination conditions for evaluation
of the effect of combining reward shaping and curriculum
learning. They are as follows.
- distance-sparse-reward : 1 reward is given when the
walker reaches the target, otherwise, 0. - distance-cl-reward : the reward given to the walker is the
same as walker-distance-sparse-reward case but the distance
of the target gets farther as the walker succeeded to reach the
target, i.e., curriculum learning. - shaped-reward : reward is given for every step according
to the body parts of the walker. Specifically, velocity and
rotation alignments with the target direction, head height and
head movement are considered. This is the default setting of
Unity ML-Agent. - shaped-distance-cl-reward : it is the combination of the
walker-default-reward and walker-distance-cl-reward.
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2024-12-09 14:38 Angry_Panda 阅读(17) 评论(0) 编辑 收藏 举报


