如何编程求解俄罗斯方块游戏问题
相关资料:
对于特定的游戏问题使用启发式算法可以取得比AI算法更好的表现
https://www.askforgametask.com/tutorial/machine-learning/ai-plays-tetris-with-cnn/
Using A.I. to DOMINATE NERDS in TETRIS
Machine Learning: AI Learns To Play Tetris with Convolutional Neural Network
AI learns to play Tetris using Machine Learning and Convolutional Neural Network
I Created An A.I. to DESTROY Tetris
Building an AI to MASTER Tetris
前文(对于特定的游戏问题使用启发式算法可以取得比AI算法更好的表现)中讨论了解决俄罗斯方块的几种方法,不过由于只是介绍了大致的路线并没有给出足够的细节,因此也是很难进行真正的solution开发的,本文就是接着前文给出俄罗斯方块游戏的具体解决方法的细节。
就像前文所说的,对于俄罗斯方块游戏如果恰当的使用启发式算法往往可以获得比AI方法更好的解决效果,这就像之前分享的几篇如何解决 《2048》游戏的方法一样,可以说这里的《俄罗斯方块》和之前分享的《2048》游戏一样都属于较难解决的游戏问题,而且这两款游戏也同样属于难以直接使用通用的AI算法求解的游戏环境(不同于gym的atari游戏等等,解决方法需要定制化),也正是因为《俄罗斯方块》和《2048》游戏的具体解法需要定制化,因此分享一下这两款游戏的具体解法细节,关于《2048》游戏的解法和代码之前已经分享过了,本文则接续分享《俄罗斯方块》游戏的解法。
给出解法介绍之下定义一下《俄罗斯方块》游戏中的action空间,即可以操作的游戏动作有那些,这里为了下面介绍中出现歧义因此统一一下这部分概念;这里规定action有left,right,down,up四个按键动作,其中left和right代表控制当前的方块向左或向右移动,按键执行一次则当前方块移动一次;up按键代表方块的变形旋转,每个当前的积木块均有0度、90度、180度、270度这四种旋转角度,每按动一次up键当前下落的积木块都会顺时针旋转90度,即0度旋转为90度,90度旋转为180度,以此类推;由于每个时间步时当前积木都会自动下降一行,而按键down则意味在每个时间步时增加当前积木块的下降行,即在某个时间步按下down键后下落积木块会下降两个行,从而实现下落积木块的加速下落;为了描述简单这里再增加另一个动作就是all down,这个动作的本质就是down动作,不过这个all down意味着一直按down键直到当前下落积木块完成下落。
总结来说,left/right键代表着移动,up键代表着旋转90度,down键意味着加速下降(下降速度加倍)。
根据本文开头分享的几个相关资料可以知道现在的计算机解决《俄罗斯方块》游戏都有一个共同点,那就是计算机生成的执行动作序列大致为如下样式:
up, up, up, left, left, left, all down;
up, left, left, all down;
right, right, right, all down;
up, right, right, all down;
up, up, left, left, all down;
left, left, left, left, left, all down;
right, right, all down;
up, right, all down;
left, all down;
right all down;
而人类操作当前积木块下落的实际操作动作的序列情况可能是:
right, right, left, up, down, left, right, right
left, up, all down
right, right, right, right, left, up, up, left, up
up, left, left, right, right, left, up
left, left, up, right, right, up, left
可以看到,人类的操作东西的序列和计算机生成的操作动作序列有着明显的不同。人类的操作动作序列可以看做是一种不断的尝试的动作,在控制一个积木块下落的过程中时而向左移动,时而向右移动,时而旋转变换,时而再接着移动,而且人类控制过程中并不一定以all down动作结束,甚至人类可以在积木块与其他积木块贴合的同时控制积木块移动(这个动作估计玩过俄罗斯方块的都会懂),给出下面的两个示意图:
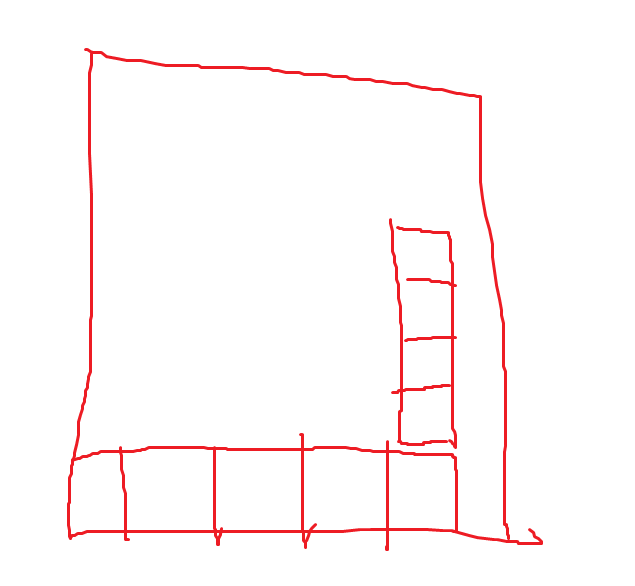
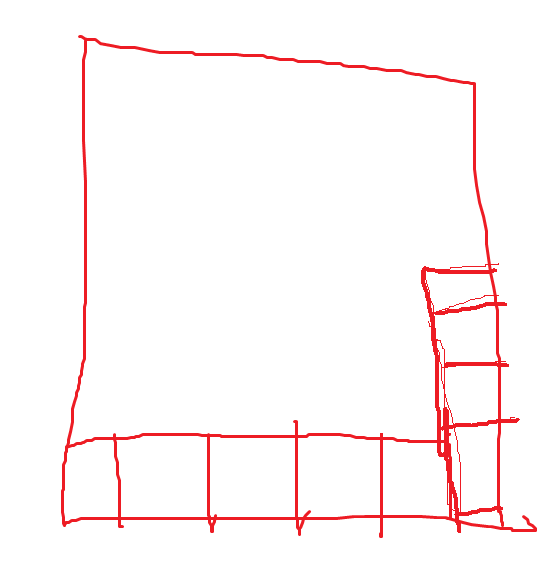
通过上面的两个示意图可以看到,人类控制积木块时可以在积木块和其他积木块贴合时依旧可以至少移动一次当前积木块(如果移动合法的话,比如向右移动式右侧不是紧靠墙),而这说明人类控制积木块的方式可以实现更加复杂的动作,以应对一下更加复杂的情景,比如在下面的场景下:
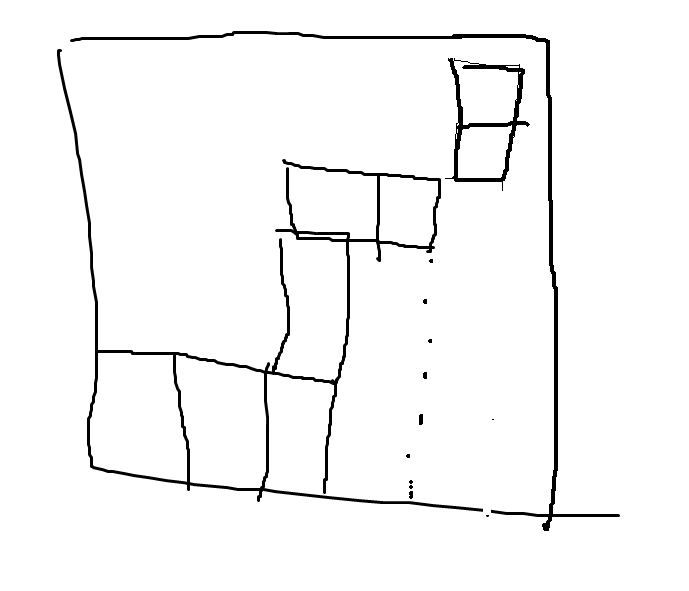
计算机程序生成的执行动作只能得到以下结果:
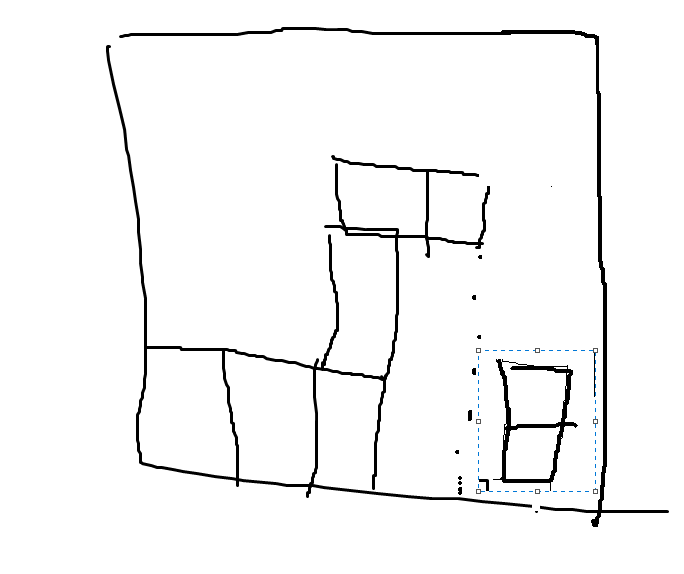
而人类的操作可以得到以下结果:
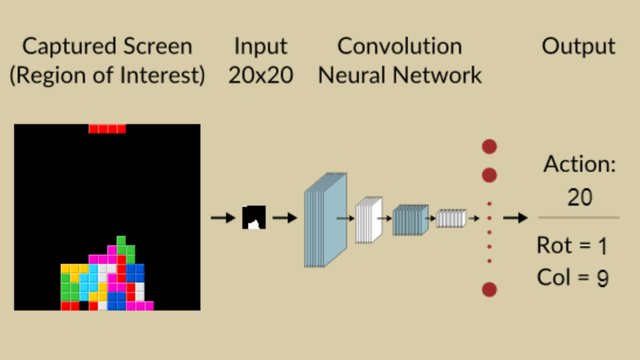
之所以人类操作和计算机生成的动作有这个区别的原因是现有的计算机程序解决俄罗斯方块都是根据当前的下降积木块和当前的已有积木块布局得到这个新积木块应该落在那个行上并且旋转角该是多少而不是直接获得具体的操作动作,也正因为计算机程序都是为当前下降积木块生成应该落地的列号和旋转角度这两个数值,然后再根据这两个数值生成具体的执行动作,因此才会有上面给出的如此不同的执行动作序列,也是因此所以计算机生成的执行动作都是先执行若干次旋转(包括0次),然后再只向左移动若干次或者只向右移动若干次,然后当下落积木块满足生成的下落列和旋转角后再最后执行all down动作以来加速完成积木块的下落。关于计算机程序解决俄罗斯方块问题时生成下落目标列和旋转角度的具体介绍可以参考https://www.askforgametask.com/tutorial/machine-learning/ai-plays-tetris-with-cnn/。
之所以计算机程序设计生产下落目标列和旋转角度这两个数值而不是为每一时间步事实生成一个动作,其原因是如果为每个时间步生成一个动作难度极大,因为当前的已落地的积木块的情况和正在下落的积木块所组成的当前状态在相近的时间步中是极为相似的,而这会导致计算机程序难以编码来区分不同timestep下的具体状态,并且如果是使用AI程序的话如果为每个timestep生成一个action,那么这个问题就成了一个稀疏reward问题,而根据已有的相关研究(学术论文及俄罗斯方块解法的学术资料)可以知道如果是按照如此建模的话构建成稀疏reward后是更不利于算法训练和算法性能提高的。因此,计算机程序对俄罗斯方块问题的建模和解决都是计算当前下落积木块的目标落地列和旋转角度的,这部分的示意图如下:
虽然几十年前的解决《俄罗斯方块》游戏的程序都是生成具体动作,而现在设计的计算机程序都是生成目标落地的列和旋转角度,虽然看似是简化问题甚至是有些偷工减料,但是根据相关的资料可以看到这种简化操作成功的避免了把该游戏的解法建模成一个稀疏reward的问题,极大的提高了算法的求解性能,当然由于现在的对于该游戏的计算机解法的这种生成目标落地的列和旋转角度会导致计算机程序无法实现人类操作的这种灵活性(无法在下降到某个行后旋转或再移动等复杂动作,并且如果某个空缺位置的正上方存在遮挡的情况也是直接将遮挡部分与空缺部分之间的部分考虑成不可填充的),但是这种设计(生成目标落地的列和旋转角度)会极大提高算法性能提高最终的算法得分,而对于中间空缺部分并且可以填补的情况毕竟在游戏中出现的比较小概率,而这时把该部分当做已填满部分也不会对算法性能有太多影响。
给出一个有空缺但是上方被遮挡的情况:

在这种情况下计算机程序生成的解决方法并不会通过最右侧的三个空缺格进入下方后进行填补,如:
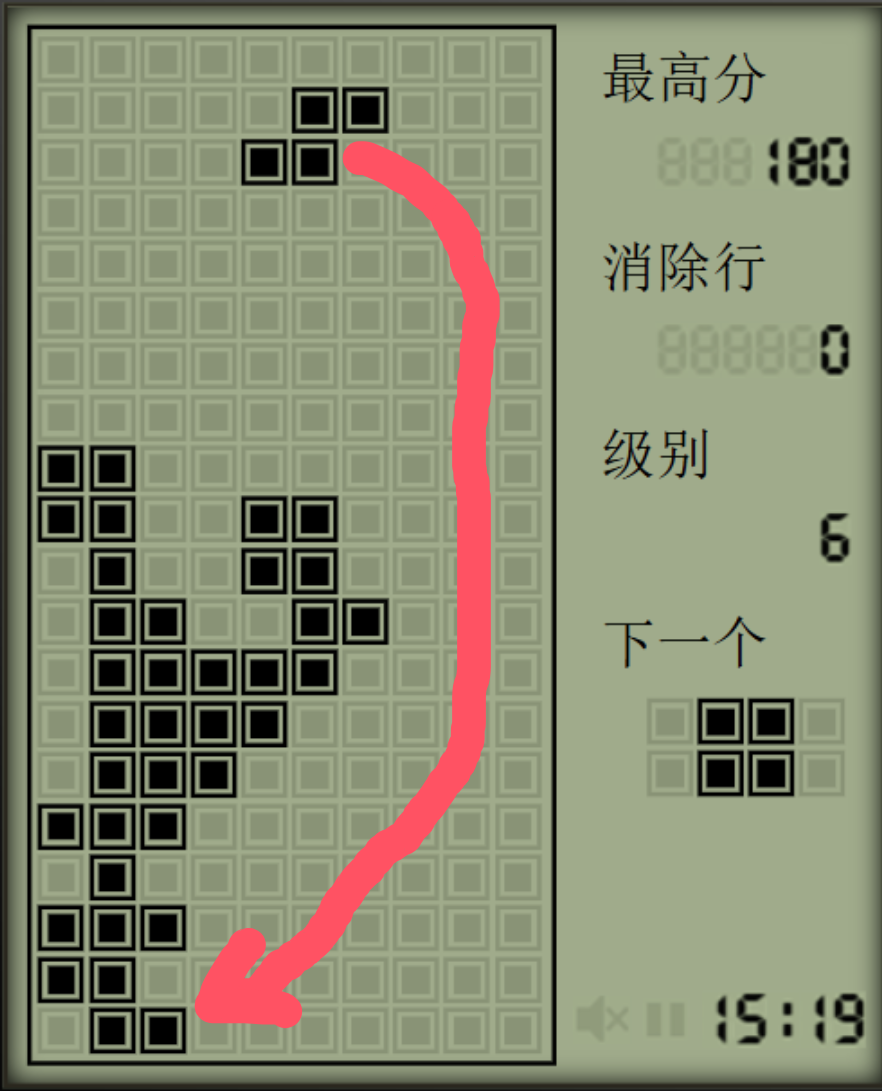
在计算机程序中这种情况等价于:

而计算机生成的最后操作的空间也是上图红框中最右侧的三列,可以说垂直有遮挡的空格在计算机程序中都被视为已填满的部分。
由于中间有空洞,上方被遮挡,甚至周围都被遮挡的情况下其实很多时候也无法利用当前下落积木对其进行操作的,如:

其中的中间空格也都是无法被直接操作的,因此这些空格可以当做已填满考虑,这样也不会对算法性能有什么影响,如下图中的红色圈中的部分,这些部分都是可以在计算机程序中当做已填满的。

正事因为这种不考虑被遮挡部分的空间的这种假设,最后算法生成的只有目标列和旋转角度,由此避免了难以训练的并且复杂的稀疏奖励建模问题,而得到了一个易于建模并且容易计算的问题建模。
在解决了问题建模后我们可以进行具体的算法设计部分了(下面的所有种类的计算机解法都是基于该问题的建模方式)。
在以上的建模方式下给出具体的解法:
- 规划法
- 遗传算法+规划法(遗传算法辅助规划法)
- 监督学习法
- 强化学习法(TD算法)
在进行具体的算法细节之下需要明确的是《俄罗斯方块》游戏中下落积木块和已落地积木块的游戏状态表示(这部分示意图图片来自:https://www.askforgametask.com/tutorial/machine-learning/ai-plays-tetris-with-cnn/),关于下落的积木块表示如下:
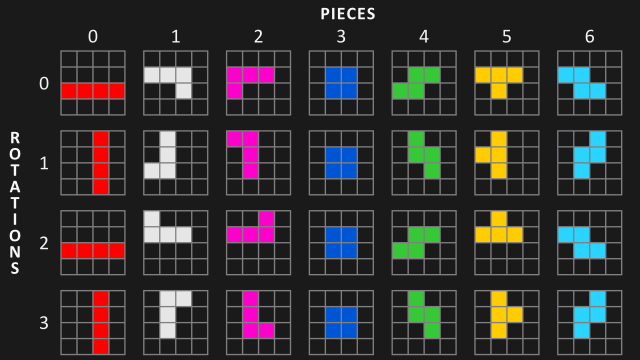
可以看到该游戏中共有七种积木块,每一种积木块均有4个旋转角度,因此在计算机算法控制积木块all down下落时共有4*7=28种形态的积木块。
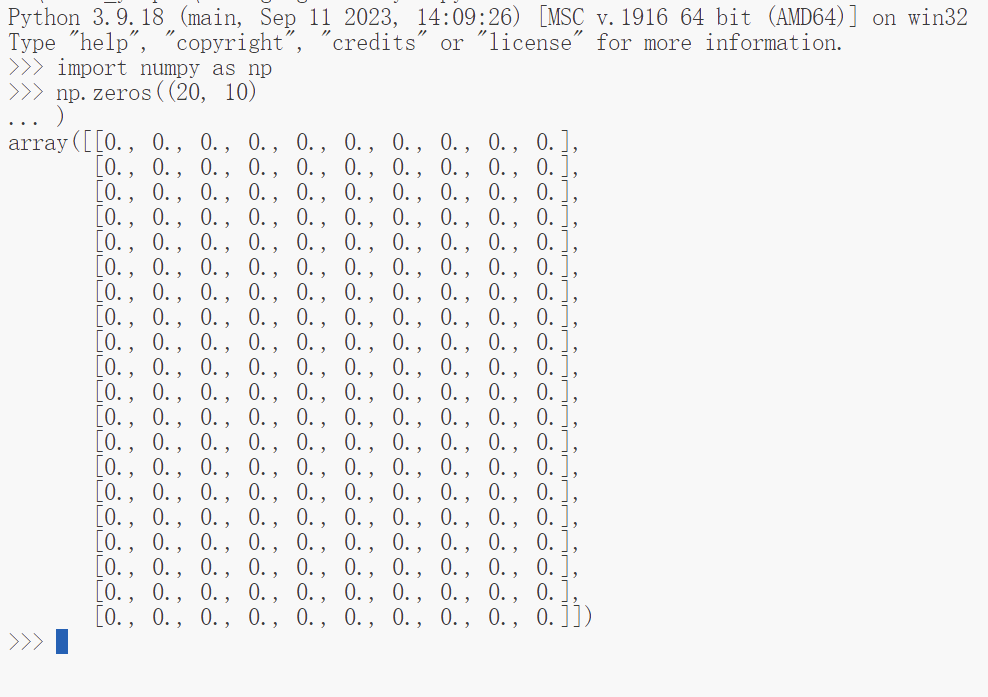
关于棋牌我们需要知道在《俄罗斯方块》游戏中整个游戏盘面的布局是固定的,及高20,宽10的一个布局,使用np.array来表示可以为:
board=np.zeros((20, 10))
在知道了棋牌的棋面布局的状态表示和下落积木块的表示形式后需要知道这里所有的计算机求解程序其实都是一种有模型的求解方式,即所有解法都可以根据现有的棋面布局和下落积木块的形态来向前推演出执行某个动作后的棋面状态(或者说是当前下落积木块在确定落点所在列和旋转角度后下落停止后的棋面状态),这一点和AlphaGo下围棋时可以预先向前推演出未来下多少步棋后的棋面状态是一样的。
就个人的观点来看,将计算程序求解《俄罗斯方块》问题的输出从每一步的up,down,left,right改为输出下落目标列和旋转角度后最难的两个技术点就是下落积木块的状态表示和确定下落目标列和旋转角度后执行落子后棋牌的棋面布局的推演,在完成了这几样事情后我们就可以使用规划算法、遗传算法、强化学习算法来对其进行求解了。
使用“规划算法”求解
规划算法求解其实就是利用效用理论来评估最佳移动方式。它通过一系列启发式方法来衡量当前配置的一些特性,例如方块堆叠的高度或存在的空隙数量,这也看做是一种启发式算法。
这些启发式方法通过加权平均进行组合,在确定各个因素的权重系数后我们就可以获得不同棋牌状态的评估,这里给出的棋牌的评估为cost,也就是说值越大则状态评估越差,假设评估的因素为方块堆叠的高度\(x\)或存在的空隙数量\(y\),cost函数为:
\(cost=w_1*x+w_2*y\)
注意,这里只是为说明之用,关于应该更全面的考虑的因素可以参考:对于特定的游戏问题使用启发式算法可以取得比AI算法更好的表现
在一些公开资料中考虑的因素量为5个以上,包括棋牌布局的凹凸度,最高堆叠高度,最低的堆叠高度,等等,这里不过多讨论和分析规划法中的cost函数的因素个数。
在确定cost函数中的各因素权重系数后(这个系数可以看做是人为头脑风暴预设的,或者是人为手动调整的),那么在某个状态棋牌布局和当前下落积木块已知的情况下我们可以向前推演在指定的落点列和旋转角度后积木块落定后的棋盘布局及该状态下的棋牌布局的cost值,根据不同的下落积木块我们可以知道一共有多少可能,比如方形积木块,由于其长宽为2,旋转后依旧为方块,因此方块的下落可能共有10-2+1=9,因为棋牌宽为10,方形积木块长宽为2,因此才有9种可能的下落所在列,由此可以知道,在棋牌状态cost函数确定,并且可以推演出未来的几种棋牌状态及对应的cost后,我们就可以计算出哪个下落落点列及旋转角度所对应的cost函数越小,那么我们就执行对应的下落点所在列和旋转角度即可;这里依旧是假设方块,方块初始时所在的列为4号和5号列(棋牌宽为10, 10个列编号分别为09),那么下落的可能列分布为08(这里以下落块的最右侧列作为下落列的计算列),假设计算出最优的下落列为0,那么可以转换为具体的执行动作为left,left,left,left,all down;如果计算出最终的下落列为8,那么转换后的具体执行动作为right,right,right,right,all down。
使用规划算法时我们也可以很好的解决在知道当前下落块及下一个下落块(有些《俄罗斯方块》游戏中是可以看到下一个未来的下落块的形态的)的情况下进行计算,示意如下:
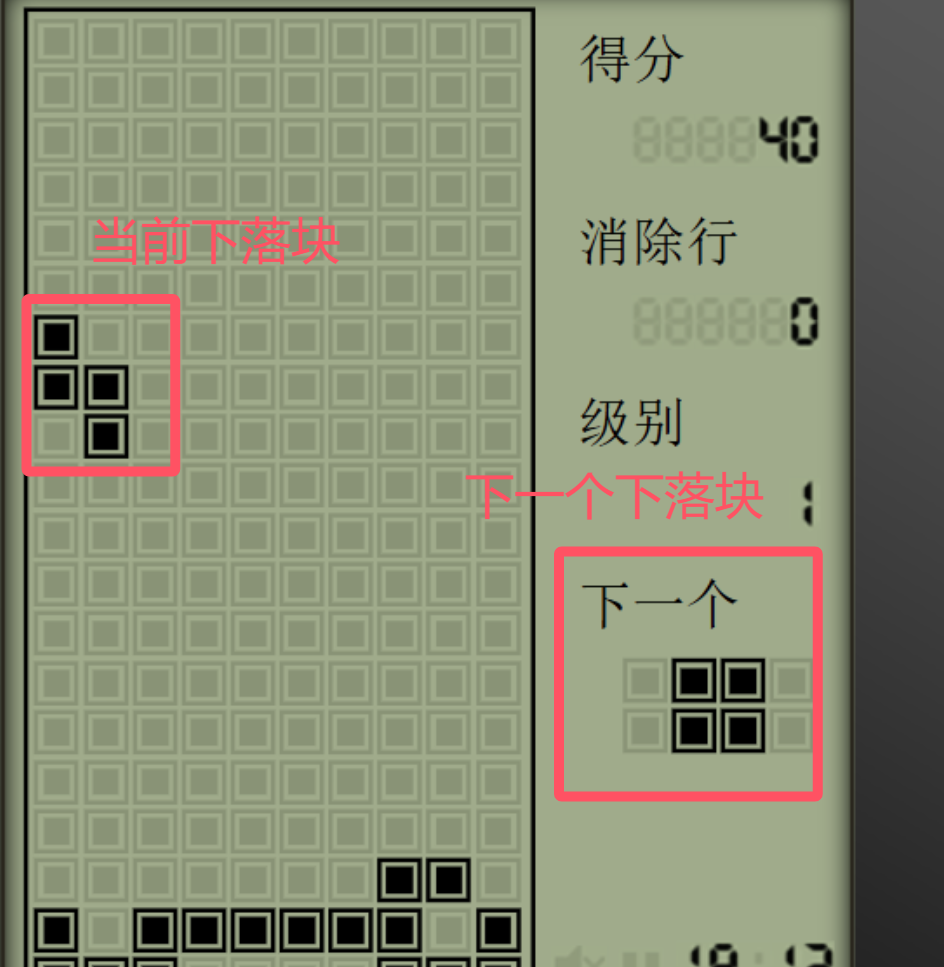
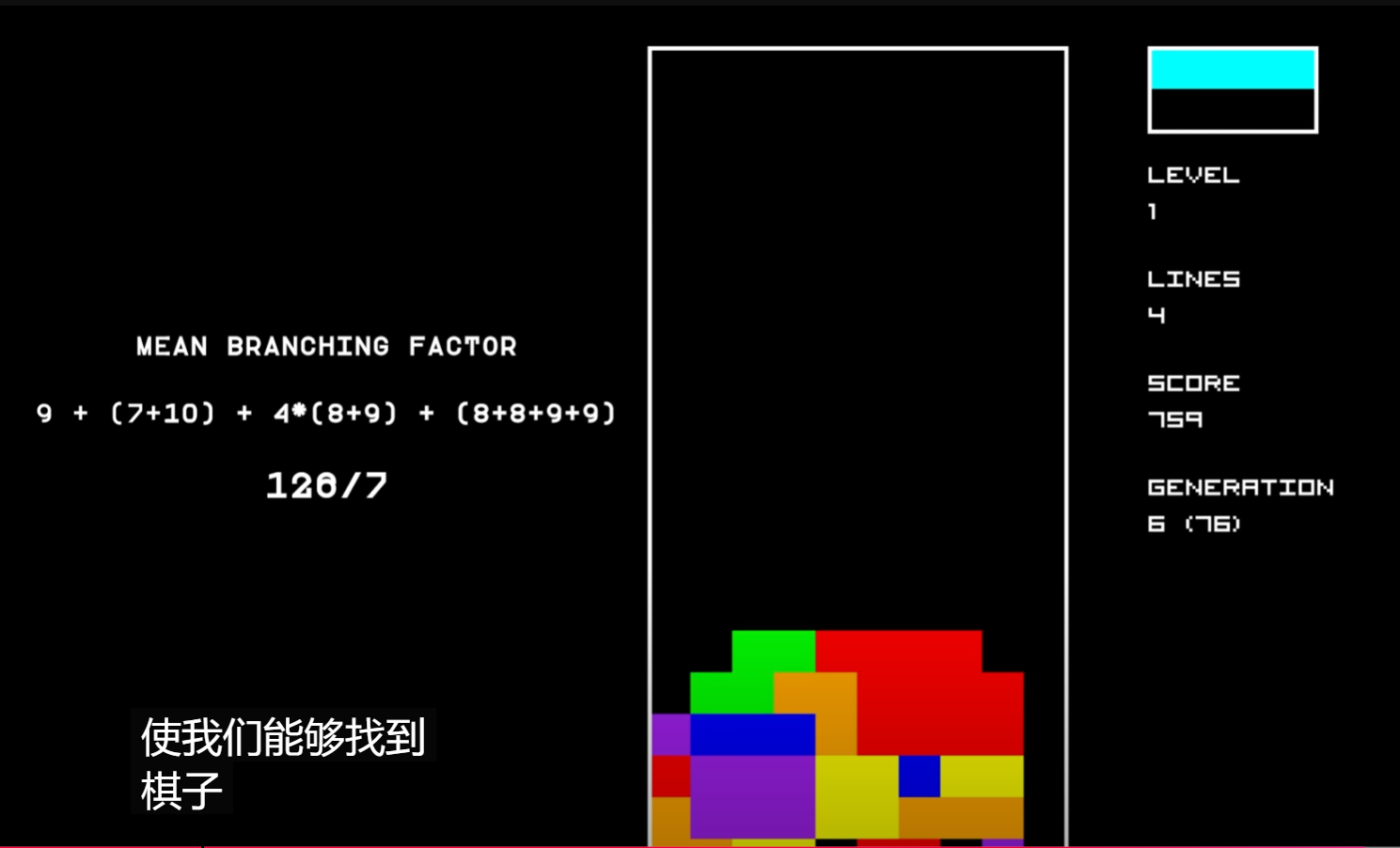
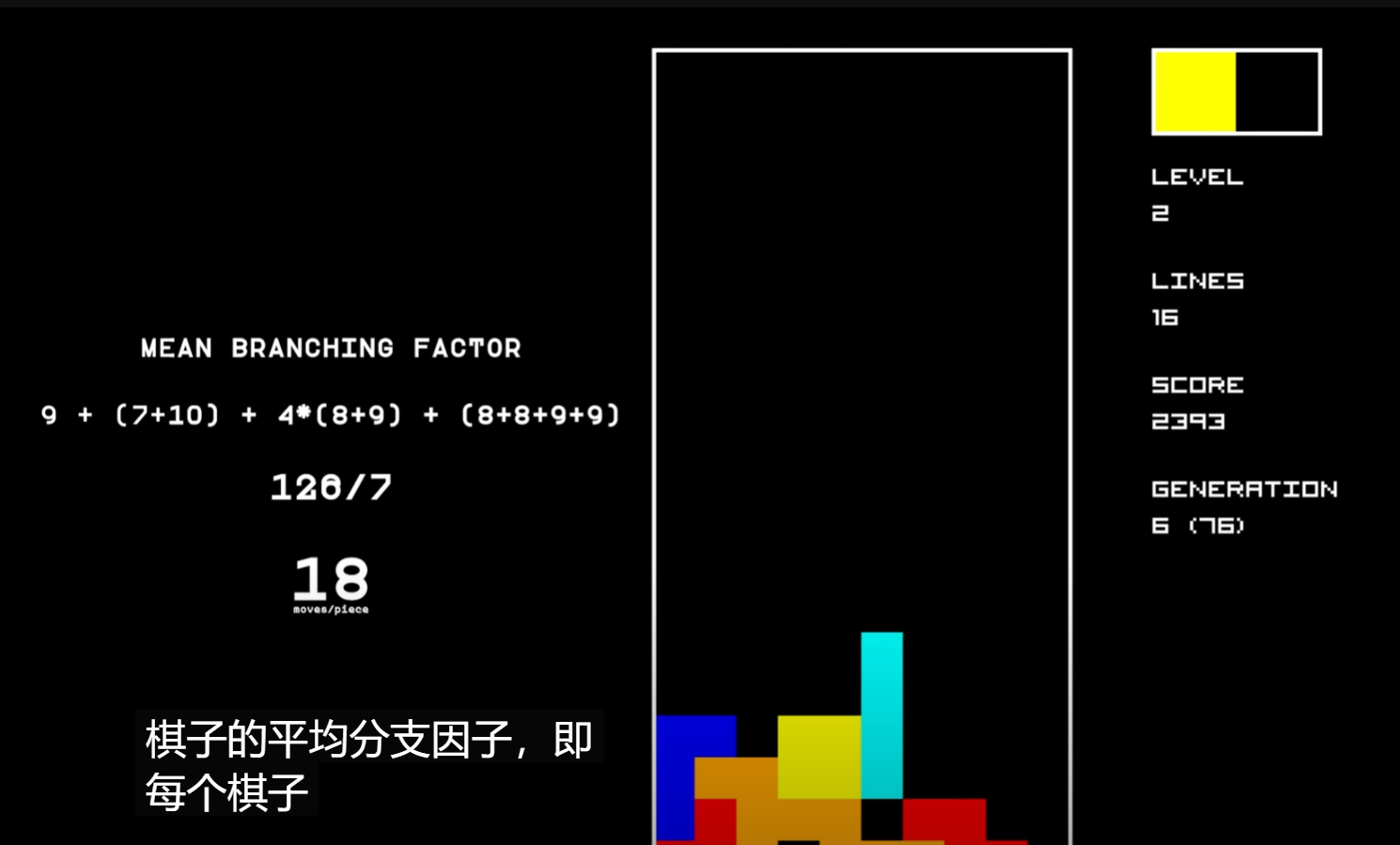
根据https://www.youtube.com/watch?v=LGNiWRhuIoA可以知道I型积木块横着的姿态下可以有7种下落的列,也就是有7种可能的落点(10-4+1=7, I型积木块长度为4),I型积木块竖着的姿态下有10种下落的落点(10-1+1=10, 竖着的情况下I型积木块宽为1),同理我们可以计算出7种积木块在4种旋转角度下共有多少种落点,具体如下:(方块积木块4种旋转角度下形状相同,因此落点只有一个姿态下的情况,同理I型的有两种)

经过计算我们可以知道这7种积木块一共可以有126个落点,平均为126/7=18。
根据以上的不同积木块的落点数,我们可以大致的计算出不同情况下规划算法需要计算cost的状态数。假设我们在使用规划算法时需要根据当前积木块和下个积木块落地的cost值来计算当前的积木块的下落点和旋转角度,那么当我们知道当前积木块和下个积木块的情况时我们大约平均存在\(18*18=324\)种可能的下一个状态,也就是需要规划算法计算大约324种下落后的棋牌状态;当我们知道只当前积木块的情况而不知道下一个积木块的情况时我们需要计算\(18*1246=2268\)种。当然这里的规划都是推演到连续两个积木块后的状态,并以此计算当前的积木块的最优下落选择的,我们同样也可以只计算推演一次积木块落地后的状态的,这就如同AlphaGo下围棋时需要前向推演几步一样,一般来说推演的步数越长其算法效果越好但也越消耗计算时长,这里建议的就是只计算一次积木块下落或两次积木块下落,否则对计算下落列和旋转角度的时间花费会难以接受的,而且由于这里的启发式算法所预先设定的cost函数的质量并不一定保证(因素种类和权重都是没有经过调优的),因此过长的推演step对算法提升不明显也没有太大意义。
遗传算法+规划法(遗传算法辅助规划法)
遗传算法+规划法(遗传算法辅助规划法)求解《俄罗斯方块》游戏其实和规划算法基本一致,唯一的不同是规划算法中cost函数中不同考虑因素的权重是人为凭借专家经验设定的(注意,这里使用的是学术术语,如果用白话解释的话就是人工手动试验出的权重值,就和做菜时放盐一样,多少全凭手感),但是由于人工设定权重往往需要花费大量的试验时间并且也难以保证会得到一个较为可靠的权重值,因此网上最为常见的解决方法则是在规划算法的基础之上使用遗传算法来优化这里的cost函数中的各因素权重。具体的操作步骤,将cost函数的各因素权重值编码为遗传算法中的基因型,而遗传算法中某个DNA个体的fitness则为该DNA表现(也就是某个cost函数下的各因素的权重)下形成的cost函数在规划算法下完成一整个游戏(玩到失败结束)的步数(或者叫做episode长度),由此来利用遗传算法来优化规划算法中的cost函数中的各因素的权重值,由此实现规划算法中的各因素权重从人为凭经验设定到使用遗传算法自动计算出的转变。注意,这里因为是使用遗传算法优化cost函数中各因素的权重,因此在遗传算法中种群个体的用来编码的cost函数中的各个因素的权重都是随机初始化的,并且使用遗传算法来寻找和优化规划算法中cost函数的各因素权重是极为耗费时间的,因为每次评估一个cost函数下权重值的好坏都是需要该cost函数下完整玩完一次游戏才可以进行,而当所有遗传算法中的种群个体都分别完成这样的一次评估才可以完成一次遗传算法的优化计算,根据网上的一些资料可以知道这个过程可能需要几天甚至几周的时间才能完成,这个时间可以和deep learning训练一个中型网络的时间匹敌了。
关于使用遗传算法优化规划算法来求解《俄罗斯方块》游戏的探索中一位外国网友给出了一些经验:
这些启发式方法通过加权平均进行组合,并选择得分最高的配置作为下一步行动的依据。初始的权重是完全随机的,随后经过几代的进化算法不断优化。表现最佳的AI(即最佳的权重组合)被选为下一代的基础,并进行微小的突变调整。
你可以看到,最开始的AI几乎是随机操作的,但经过几代后,其表现迅速提升。
这里展示的是50代的试错过程。实际上,我已经运行了好几天,但目前遇到瓶颈,因为AI已经足够优秀,每场游戏都能持续数百万次操作,这需要数小时才能完成一场游戏!
当然使用遗传算法优化好cost函数的各因素权重值后最终进行游戏求解的其实依旧是规划算法,而且当我们获得一个表现十分好的cost函数权重值后使用规划算法是可以取得比强化学习算法还要好的求解效果的。
使用监督学习法求解游戏
这个方法的一个不错的探索:https://www.askforgametask.com/tutorial/machine-learning/ai-plays-tetris-with-cnn/
这里关于监督学习的机器学习算法以及之后的强化学习算法解法都是属于人工智能方法,并且都是需要使用神经网络结构的,比如使用cnn或mlp,之前的使用遗传算法的解法其实也是人工智能算法中的一种,不过并不需要使用神经网络。
这部分关于使用监督学习方法解决《俄罗斯方块》游戏的方法源自于:https://www.askforgametask.com/tutorial/machine-learning/ai-plays-tetris-with-cnn/
在该方法中使用CNN网络作为分类器,就和之前讲解中的一样因为程序的计算输出是下落列和旋转角,因此对其棋面布局中上方有遮挡和有孔洞的棋面布局都等同于有填补的情况,在监督学习方法中也直接使用该种方式来填补布局,示意图如下:
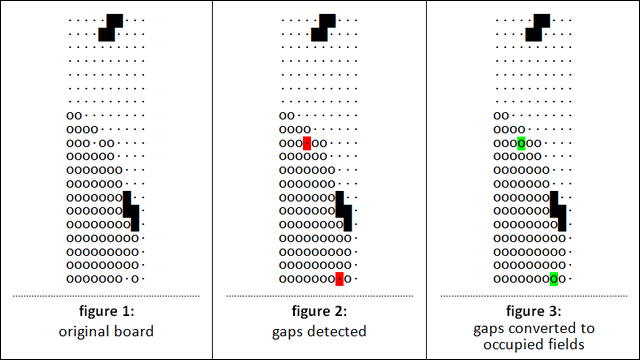
可以看到,上面的这张示意图中将空洞的位置(figure 2中的红色方块)进行填补(结果为figure 3中的绿色块)。需要注意的是在训练时我们采用这种对空洞数据填补的方式来构建神经网络的输入数据,因此我们在训练完成后的测试阶段依旧需要对输入神经网络的输入数据(棋面布局)进行空洞数据的填补,否则会影响算法测试阶段的性能。
由于监督学习法需要有监督信息,即标签数据(不同于强化学习算法,在强化学习中可以通过设置reward函数的方式快速给出每个action后获得新状态的评价而不需要像监督学习这种为每个棋牌状态给出明确的action选择,即标签数据),在这里标签数据为每个棋牌状态所对应的应该选择的action(下落列和旋转角度)。由于监督信息需要人为提供,因此这种手动给数据打标签的操作和模仿学习是很像的,直白的来说就是使用程序记录下当前棋牌状态和下落的积木块形态,然后再记录下人类打游戏时给出的action,从而构建监督学习的数据库。由于人工打标签的操作其实是很耗费时间的,因此在该方法中使用的是数据增强技术(data augmentation),由于已经分析了在输出为下落列和旋转角度的设定下神经网络的输出数据(action)主要是取决于棋牌中堆叠方块的上表面,因此这里采用的数据增强方法是在下方堆叠的方块的底部添加行或减少行,具体的数据增强的示意图如下:

该种数据增强方法是因为对动作选择的影响,也就是监督信息的影响直接取决于棋牌中堆叠方块的上表面,也就是下图中的情况:
其堆叠积木块的上表面为:(红线表示的为堆叠的上表面)

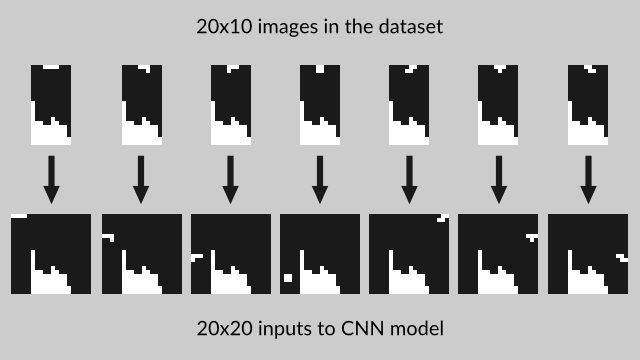
使用该种数据增强的方法将人工采集的50,000 个数据扩展为1,000,000个数据。其实这里的数据扩增的方法除了在堆叠积木块下方增加和减少积木行以外还可以通过整体移动棋牌布局数据的方法来实现,这是因为由于要输入到CNN网络,而CNN网络的输入数据需要时一个长宽维度相等的正方形数据,因此可以有更多的扩增数据。
输入数据,棋盘数据的原始形态为20高,10宽,我们需要对其左右各填补宽度5,实现输入数据为20高,20宽的方形数据形态,示意图如下:
由于使用CNN网络,因此输入数据更多的需要实现的是状态识别或是图形识别的作用,而我们只需要保证下落积木块的旋转角度和堆叠积木块的布局和朝向以外对二者之间的几何距离关系并不作区分,因为我们的目标是需要识别出下落的是哪个积木块及哪个旋转角度,还有已堆叠的积木块的布局,给出一个示意图:

也就是说上面这个图中所有的红色T都可以分别作为一种扩展数据,因此上面的这个图中的T可以在计算时作为8个输入数据(7个红色T,一个白色的T),而这扩增后的8个输入数据的输入(监督信息)都是相同的,都是人为给定的下落列和旋转角度。
注意:这里的数据收集可以是在自己编写的《俄罗斯方块》游戏中进行收集,这样可以方便定制化以实现多样的数据收集,比如在棋牌堆叠情况固定的情况下给出多种的随机生成的下落积木块的情况,然后分别给出人为的动作选择(下落列和旋转角),这样就可以收集到一种棋牌状态分别对应多种不同积木块下的监督信号。
在介绍了监督学习法下的输入数据及数据采集和数据增强的方式后我们需要了解的事输出数据的格式,虽然我们之前已经分析并交代了本blog中所有的解法都是建立到输出数据为下落列和旋转角度的基础上的,以此来实现避免对稀疏reward的问题的建模,但是在下落列的定义上还需要给出一定的解释。这里需要清楚的是对下落列的具体列号的定义或者说是对下落列的顺序号的编码,而具体的列号的编码需要根据具体的下落方块的定义来的,下面给出一个例子:
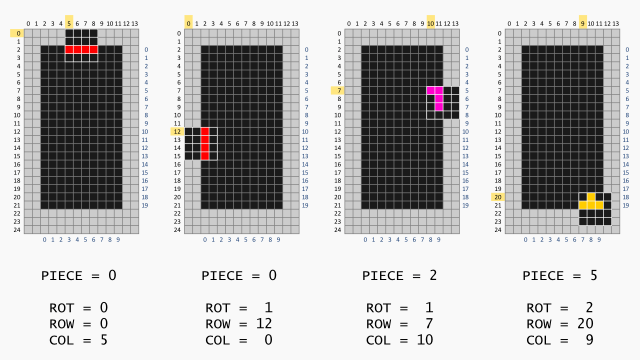
下落积木块的定义:
可以看到下面的定义方法是根据下落积木块的下落时的中心定义的,因为游戏的高20,宽10,因此每次下落积木块都是在宽的中心下落的,因此按照上面对下落块的定义(长4,宽4的方块),那么游戏每次下落积木块时初始时上面方块最左侧列都是在3号列,最右侧都是在6号列,给出示意图:
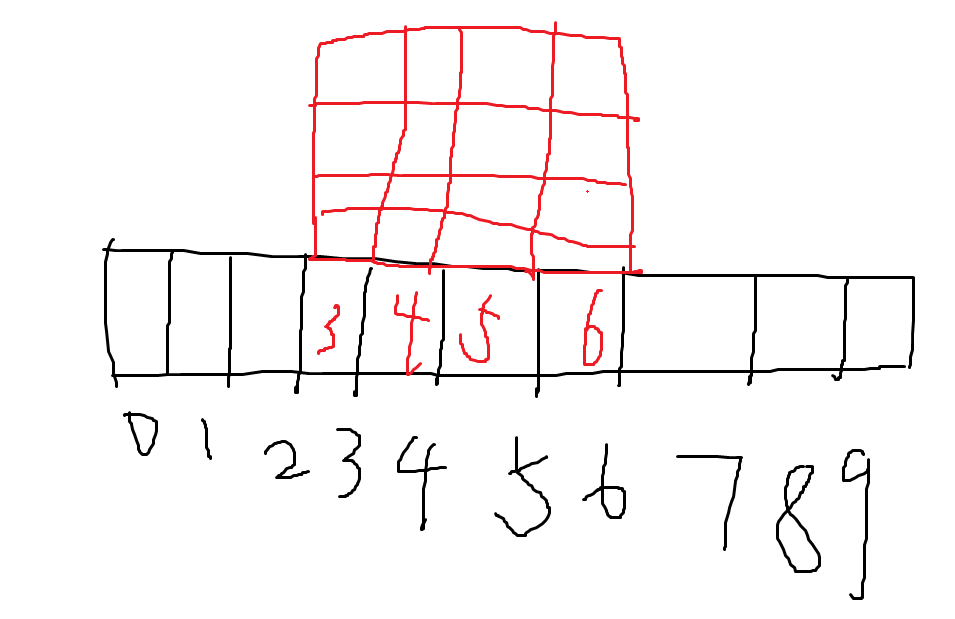
通过上面的这种方式定义下落块可以方便的统一定义出下落块的初始位置,但是这却会导致下落列的编码上的一定困难,比如:

这个方块由于左侧有两列空的地方,因此如果将棋牌的下落列编码为0~9(棋牌宽为10)的话是无法使上面的这个积木块移动到棋牌最左侧的,同理也不能移动到最右侧(有一列空格),为此这里给出的方法是增加棋牌落点列的编码宽度,这里是左右各扩两个列得到宽14的编码列,具体如下:
这时棋牌的落点列的编码为14,这种情况下可以认为下落块的可以落点列从编码0到13,不过需要注意的是这种编码下会存在某些下落块会出现非法下落列,比如上面的这个示例的下落块,由于其左侧有一个空列,因此这个下落块的最左侧列的最大下落列的编码只能是9,如果在CNN网络输入下落列时我们需要根据这个输入数据中的下落块来排除掉10,11,12,13编码的下落列的输出值,而从0~9号编码的下落列中找到最大输出值代表的下落列作为输出。
除了上面的举例的这种下落列编码外我个人也喜欢使用将所有的下落块最左侧所在列下落到棋牌最左侧列作为0号下落列的编码,依旧以I型下落块举例,我们这时的下落块的编码形式为:

这种编码方式就是忽略掉其下落初始化时在棋牌上的所在列,而且这个初始时所在列也不会影响后续计算,因为不会被用到,这两种编码其实区别就是个人偏好,之所以本人喜欢后者的编码方式是因为该种编码会保证下落列的编码在09区间,而不是向上个编码例子中下落列编码序号在013区间,不过即使后者的编码方式也会出现某些情况下的下落列不在合法空间,比如上面的这个I型积木块的在为横的情况下下落列的最大列号为6,因此同理,在CNN输出下落列和旋转角度的数据时我们要先排除掉不合法的输出数据然后再在合法的输出数据中找到最大的值作为输出。
根据不同下落列的编码下获得的输出值中的下落列,我们可以根据编码情况计算出具体的执行动作,比如对于I型积木块的横的情况下的移动,如果得到的目标下落列为2号(棋牌高20,宽10情况下的最左侧列),输出的旋转角度为0而该下落块的旋转角度也为0,那么转换后的动作为left,left,left,all down,如果此时的输出旋转角度为90,那么转换后的动作为up,left,left,left,all down,可以看到这个生成的动作序列的开头有几个up是根据输出的旋转角度和实际下落块的旋转角度差几个90度决定的,而有几个left或right是根据下落块编码的左侧列在棋盘上的列编号和输出下落列编号之间的差值,这里的例子是下落列为2,而下落块的最左侧编码在棋盘中所在的列为5,由此可以得到左移5-2=3个left。
对于具体的输出格式,我们这里以下落列编码为0~13的情况下举例,因为一共有4个旋转形态,那么一共可以有44个输出,也就是说神经网络的底部是CNN,顶部是MLP,最后的output层是节点44的输出,其中输出层不使用激活函数,因此输出层的数值范围为无穷大到无穷小的实数,在这个44个输出中我们排除掉不合法的输出然后再在其中找到最大的输出,假设某次计算后合法的输出中最大的为第20个输出,那么根据下面的计算公式可以得到输出的具体的下落列和旋转角度:
rotation = (output / 11) = {0, 1, 2, 3}
column = (output % 11) = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
即:20/11=1,20%11=9,因此得到下落的落点编码为9,旋转角度为1,如果下落的时一个正方块(方块的初始时最左侧编码为5号编码),那么这个初始翻译为具体执行动作为right,right,right,right,all down,因为9-5=4,因此是移动四次,由于9>5,因此移动动作为right,由于旋转角度为1,因此应该是up,right,right,right,right,all down,但是由于是方块,因此不需要旋转,于是得到最终的执行动作序列:right,right,right,right,all down。
整个监督学习方法解《俄罗斯方块》的神经网络架构如下:
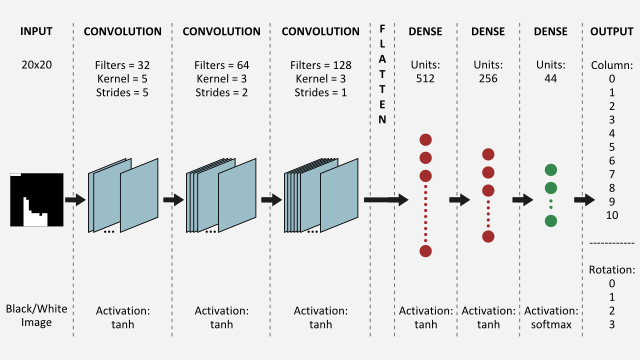
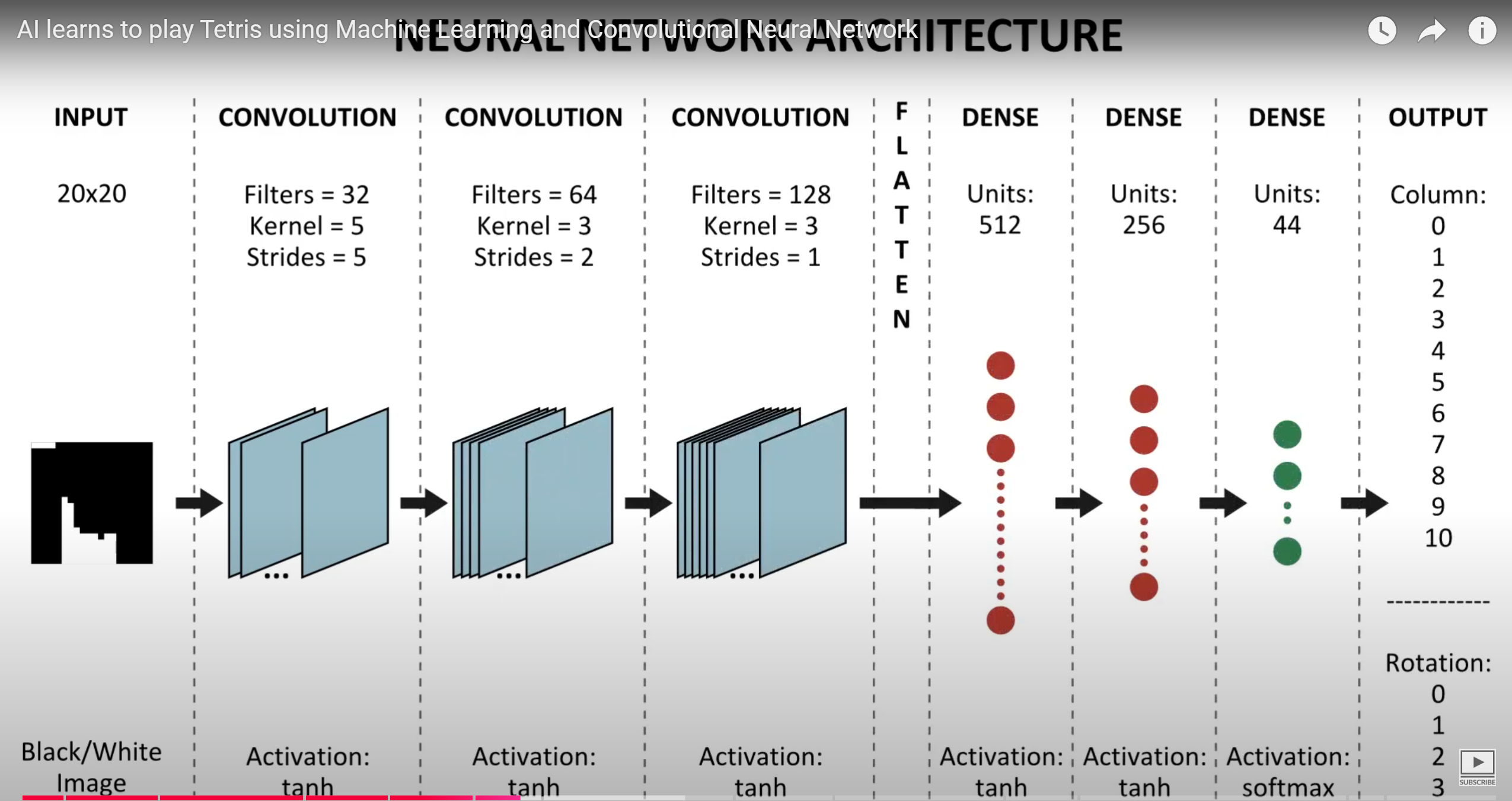
相关资料源自:https://www.askforgametask.com/tutorial/machine-learning/ai-plays-tetris-with-cnn/
强化学习法(TD算法)
在介绍了前面的使用规划算法和监督学习算法求解《俄罗斯方块》问题后,使用强化学习算法也就比较直观了,因为强化学习算法也是使用神经网络结构的,因此我们可以直接采用上面的监督学习算法中的神经网络结构进行求解,由于输入输出的数据格式以及如何根据神经网络输出的动作(下落列和旋转角度)来转换成具体的执行的up,down,right,left动作后就可以直接根据这些信息调用强化学习library来进行求解了。
https://github.com/nuno-faria/tetris-ai
-
TD
该项目实际使用的并不是DQN,而TD(0)
-
MLP
该项目并没有使用CNN,而是使用的MLP,并且在特征输入时选择的使自定义的特征
-
确定下落列和旋转角度后不转换为具体动作与环境交互,而是直接生成环境的下一个状态(因为这个环境有些toy,因此程序可以直接修改游戏状态)
本文中解法的最关键点就在于对问题的输出建模为输出下落列和旋转角度,这样不仅避免了AI解法中的稀疏reward问题,同时也避免了规划算法中搜索空间过大的问题,否则如果算法的直接输出为up,right,left,down这四中action的一种,假设一个积木块下落共有10个timestep,那么不使用该种方式建立问题模型的话那么在启发式算法中对一个timestep(一个积木块从初始化到完成落地)的推演规划就需要有\(4^{10}\)种搜索状态,而这个计算量也是一种难以接受的搜索空间,如果不使用这种问题建模方式那么在规划算法中的一个积木块的规划中的状态空间的穷举是一个天文数字,这样也难以最终在计算机程序中实现的。
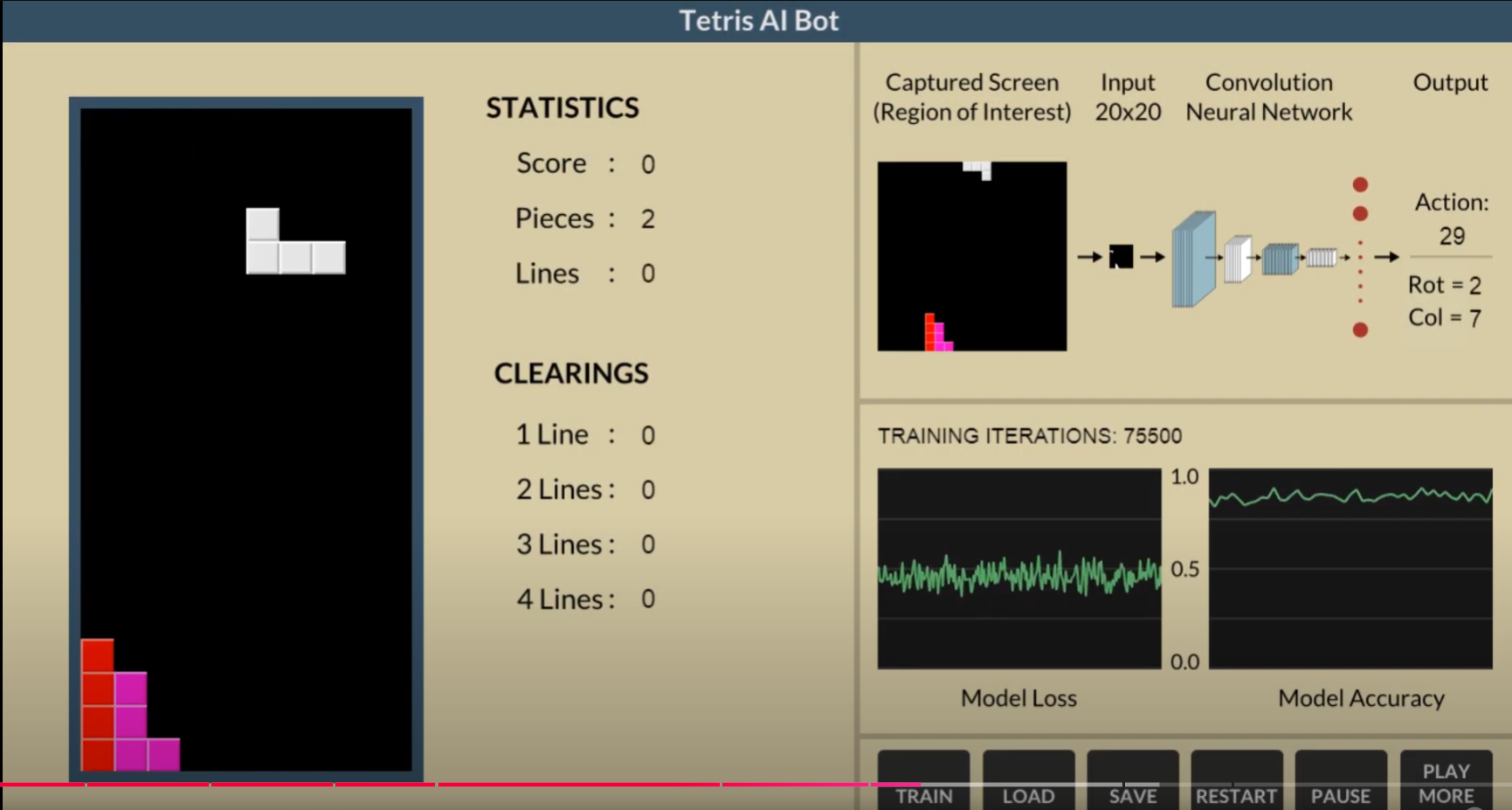
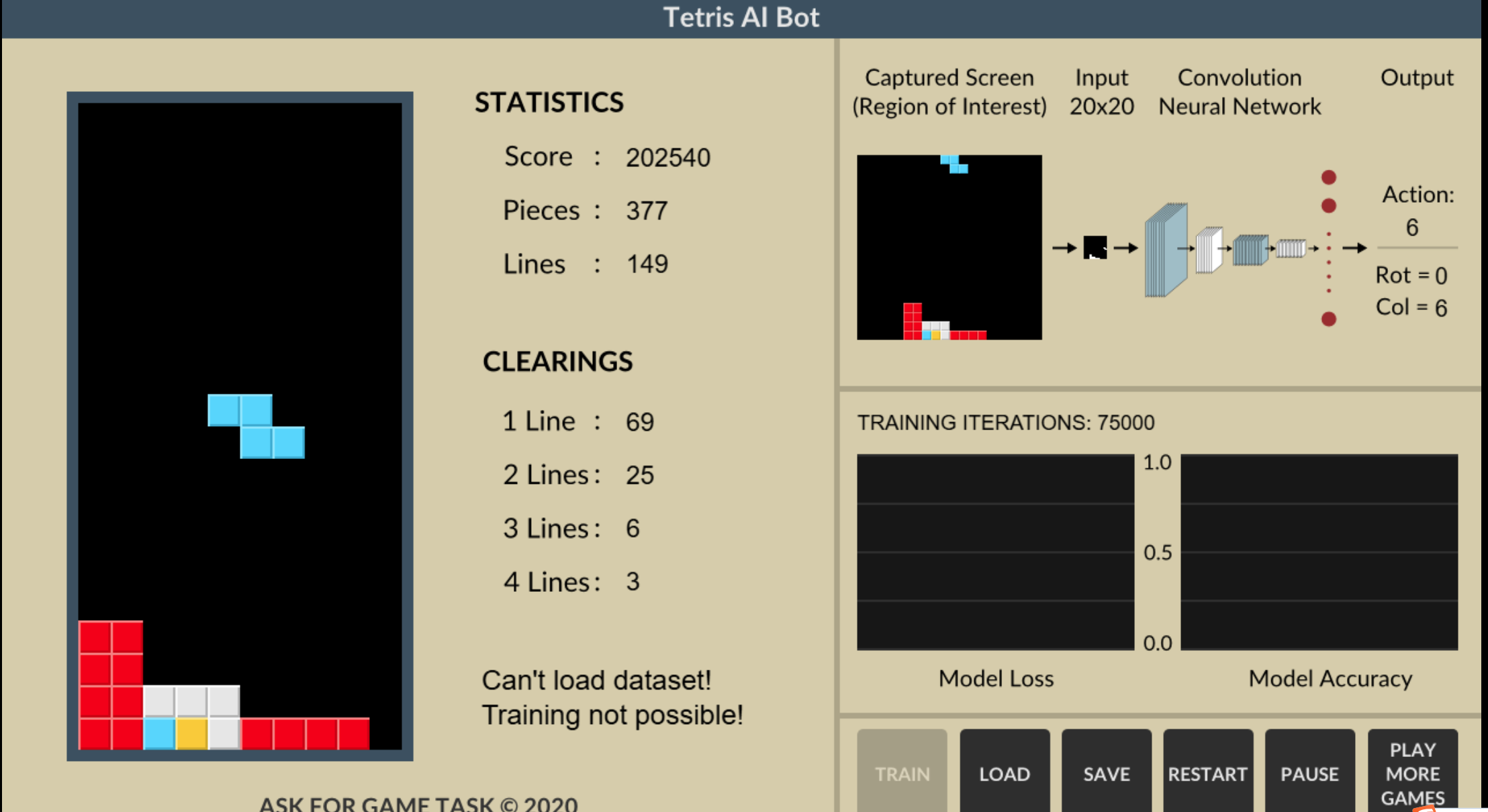
俄罗斯方块游戏的一个演示地址:
https://www.askforgametask.com/html5/tutorials/tetris_ai_bot/source/
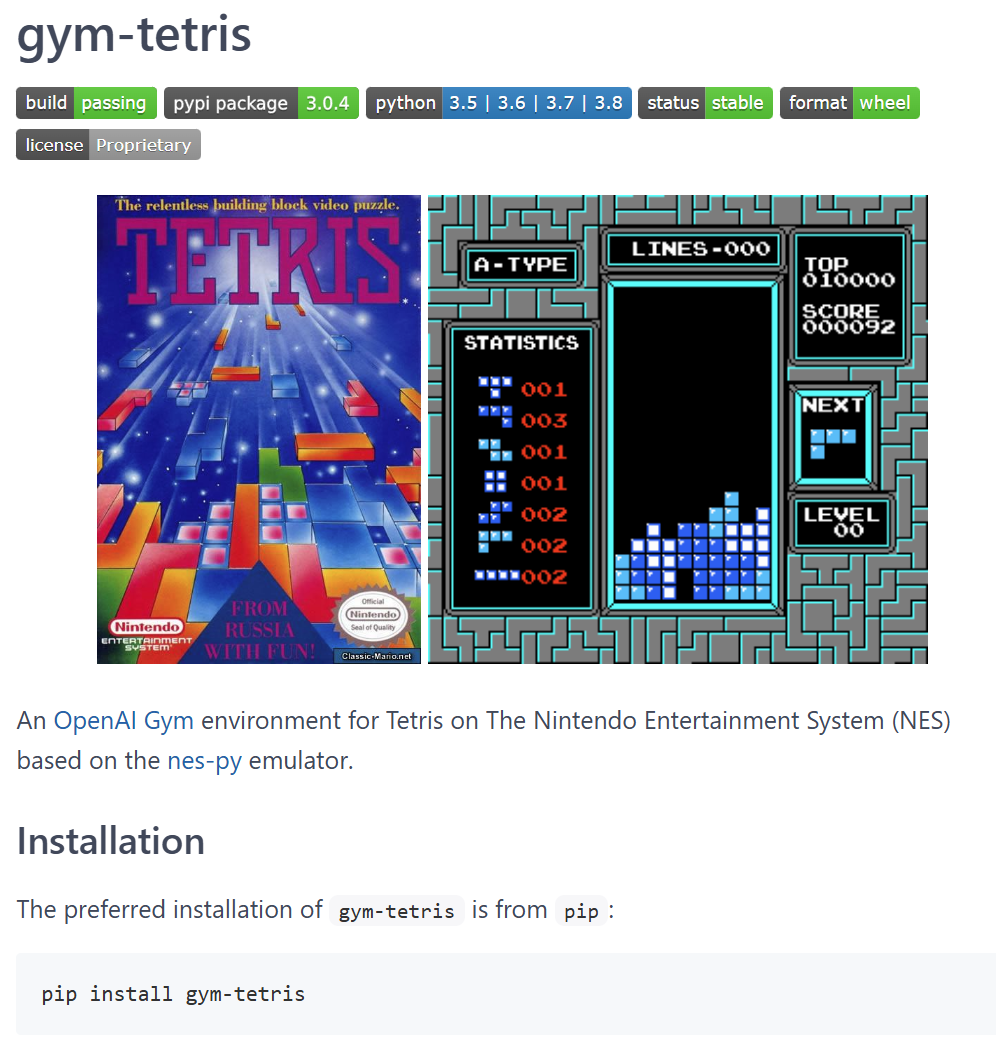
给出一个任天堂的《俄罗斯方块》游戏的仿真模拟器:
https://openi.pcl.ac.cn/devilmaycry812839668/gym-tetris
这个模拟器最大的问题就是其返回的状态是shape为(240, 265, 3)的numpy.array,也就是说这个游戏仿真器返回的是整个游戏的画面,而不是我们想要的shape为(20, 10)的棋牌布局,完整的游戏画面如下:
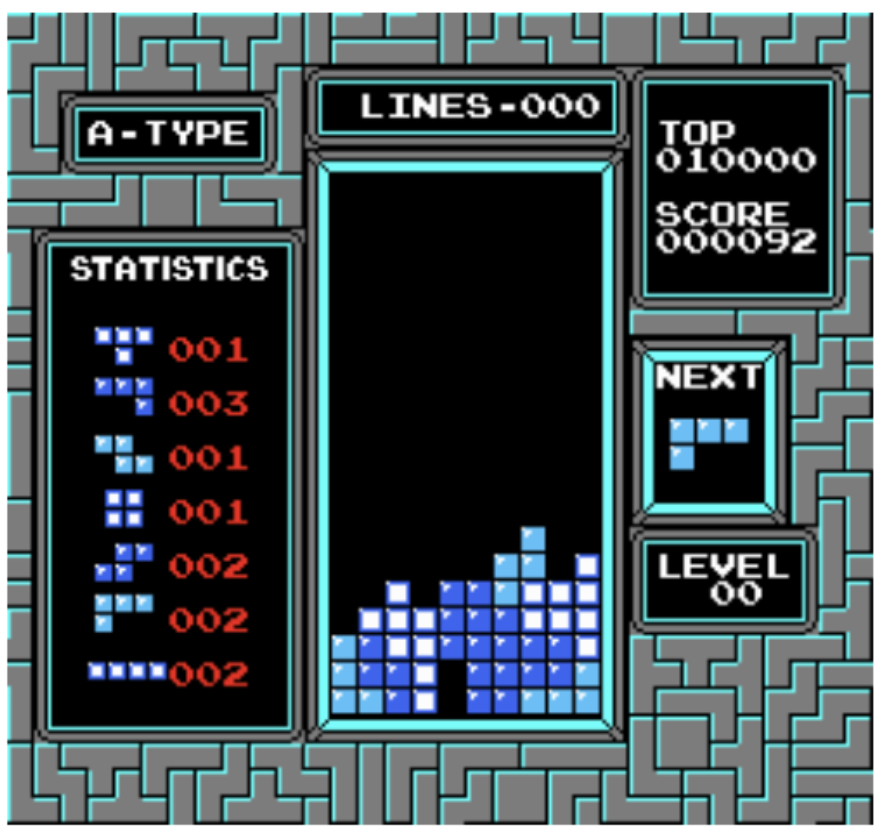
因此如果使用这个仿真器进行算法训练的话第一步就是要确定这个返回的状态矩阵中的哪一部分才是我们进行计算时所需要的棋牌牌面。直接使用这个仿真器进行算法训练时不现实的,因为这个仿真器在状态和动作方面的定义都太原始(raw)了。
关于这个仿真器的一些参考和使用资料如下:
- Tetris (NES): RAM Map. Data Crystal ROM Hacking.
- Tetris: Memory Addresses. NES Hacker.
- Applying Artificial Intelligence to Nintendo Tetris. MeatFighter.
《俄罗斯方块》游戏试玩在线地址:
http://123.geiwosou.net/game/tetris/
强化学习算法library库:(集成库)
https://github.com/Denys88/rl_games
https://github.com/Domattee/gymTouch
个人github博客地址:
https://devilmaycry812839668.github.io/
posted on 2024-11-07 19:14 Angry_Panda 阅读(401) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号