强化学习训练过程中的过度拟合(overfitting)
相关:
A.I. Learns to Drive From Scratch in Trackmania
本文讨论的是强化学习中的过度拟合问题,要知道强化学习中的过拟合和其他的监督、无监督学习的过拟合不太一样,主要是因为强化学习中的过拟合情况复杂、场景多样,难以用简单语言描述,而监督、无监督学习中的过拟合情况单一容易描述,所以在强化学习中对于过拟合的问题都是极少的,或者是要针对特定情况给出举例的,而本文就依照这个赛车游戏问题给出一种情况的强化学习过拟合问题。
在这个游戏中(A.I. Learns to Drive From Scratch in Trackmania)是使用DQN进行训练的,由于这个这个游戏环境比较复杂,因此DQN训练的agent的episode的长度增长十分的缓慢,由于episode长度增长缓慢反之导致agent对新场景见的频率极低,而这反过来加剧了agent的episodes的长度的训练困难性,于是陷入到循环困难中导致DQN难以有很好的效果和算法性能,可以看到这种问题的出现就是因为游戏难度大导致agent长期陷入到较短episodes环境中从而出现了对较短路径的过拟合于是更难以探索更长episode了。
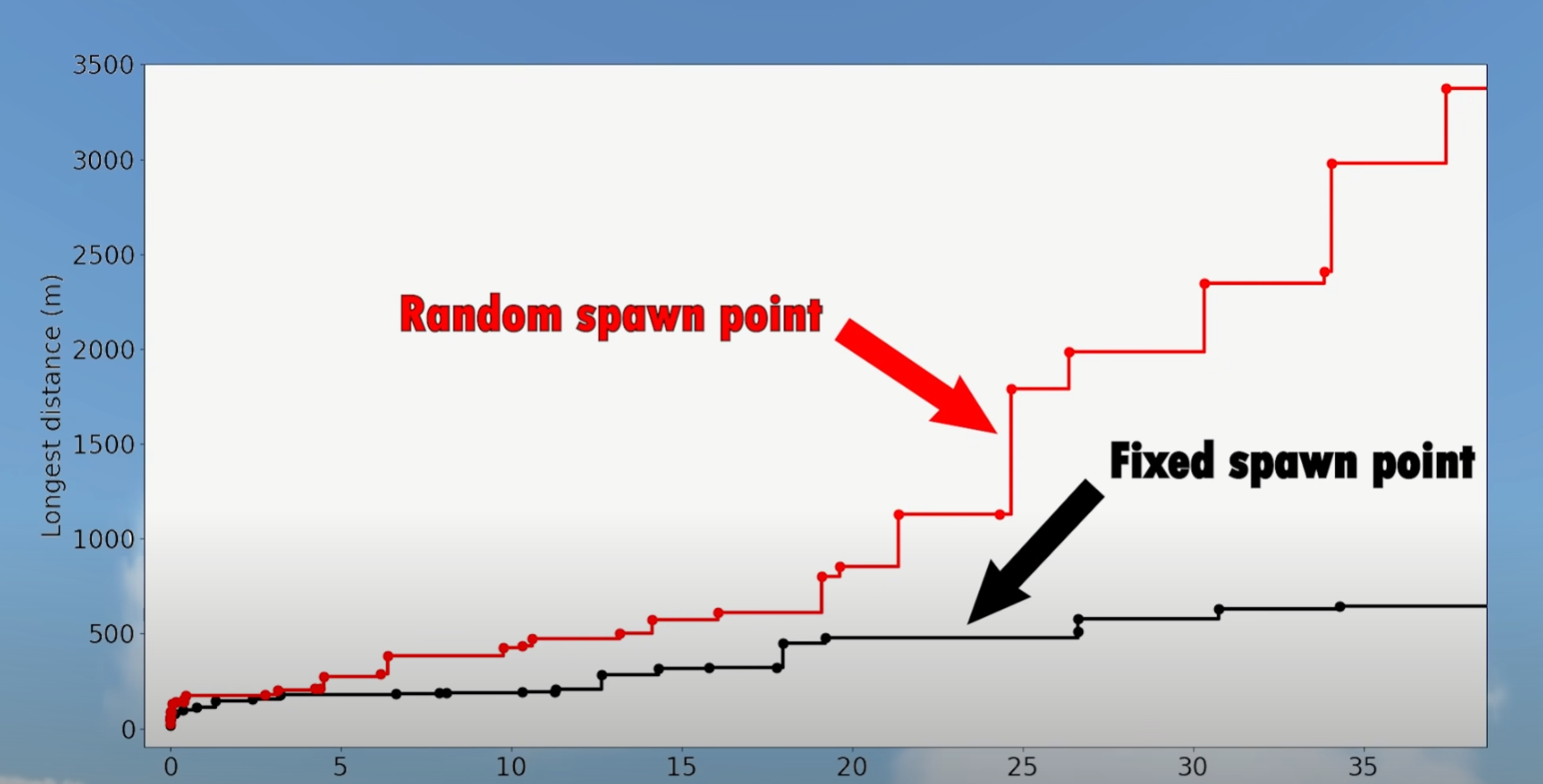
为了解决这里的过拟合问题,原作者使用随机生成赛车出发点的方式进行训练,结果发现很好的克服了过拟合问题,使agent的性能在训练过程中有了明显提升。在这里使用随机生成出发点的方法和随机生成不同的小地图进行训练时同样的作用的,都是克服agent的过拟合的。
这时候可能有人会问,为什么在DQN运行在atari游戏环境下没有出现过拟合,而在这个赛车游戏中出现了过拟合了呢?其实答案很简单,那就是因为这里的这个赛车游戏难度明显高于大部分的atari游戏,导致agent的episode长度很短,并且难以增长,所以导致大部分的训练数据(采集到的数据)都停滞在较短的episodes的背景下,由此产生了大量的相似训练数据,于是导致出现了这里的过拟合问题;而atari游戏相对简单些,DQN在atari游戏中可以保持一个比较好的episode长度的增长速率,这样随着agent在atari游戏中episode的长度增加自然就避免了agent陷入过拟合问题中。可以认为这里的赛车游戏出现的过拟合就是因为agent陷入了较差的局部最优解中,导致大量的低质量的探索数据,从而产生了过拟合,反过来导致agent在局部最优中更加难以跳出,如此陷入反复恶化的情景中。





强化学习算法library库:(集成库)
https://github.com/Denys88/rl_games
https://github.com/Domattee/gymTouch
个人github博客地址:
https://devilmaycry812839668.github.io/
posted on 2024-11-05 14:21 Angry_Panda 阅读(294) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号