
机器学习中验证两个算法之间是否存在显著差距的t-test检验
同一主题的简单分析版本,建议查看:
机器学习领域中假设检验的使用
本文内容为在上文基础上进一步分析版本。
相关:
t检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n < 30),总体标准差σ未知的正态分布。 t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
t检验是一种常用的统计方法,主要用于比较两组数据的平均值是否存在显著差异。
t-test的使用场景非常广泛,只要涉及到需要比较两组数据平均值差异的情况,都可以考虑使用t-test进行分析。
在机器学习实践中,我们可能会尝试不同的算法或模型来解决同一个问题。t检验可以帮助我们比较这些算法或模型在性能上的差异,从而选择出最优的模型。
总之,t检验在机器学习领域是一种有用的统计工具,它可以帮助我们更好地理解数据,优化模型,并做出更明智的决策。
为什么使用t-test检验,或者说为什么使用t分布统计量,也或者说高斯分布/正太分布之间的关系,等等,这些统计学的问题,包括相关统计假设的数学定理及其推导,说实话,自己也不会,大学学的就是标准的人教版教材,告诉的也就是用这个东西来作统计就是,至于具体原因以及背后的深刻数学原理这里也无法讨论,但是说一个自己的一个简单理解的小例子:
投掷一枚硬币,正反面出现的概率均为0.5,那么连续投掷10000次,最后出现正面次数为0、1、2、3,......97、98、99、100的概率其实就是服从一个正太分布的,关于二项式分布与正太分布之间的数学推导这里也就不介绍了,这里举这个例子要说明的是在日常的发生事件的统计模型建立时使用状态分布的有效性及其背后有相关数学理论支撑。
如果在统计建模时我们的样本量较小(样本量小于30时),那么该模型更趋向于t分布而不是正太分布,因此在日常统计建模检验时我们常使用t分布而不是正太分布。大致可以这么理解,一个分布是正太分布,但是对这个分布抽样较少的样本,那么由于样本量较少,因此抽取的样本更符合t分布而不是正太分布。
t检验可分为单总体检验和双总体检验,以及配对样本检验。
t检验用于比较两个均值是否存在显著差异。具体来说:
- 单样本t检验:用于检测一个样本的均值是否与某个已知的总体均值有显著差异。
- 独立样本t检验:用于比较两个独立样本之间的均值差异。
- 配对样本t检验:用于比较同一对象在不同条件下的均值差异(如治疗前后)。
在使用t检验时都是将两个分布的差异不显著设置为
在使用t检验判断两个总体分布均值差异是否显著时需要假设两样本总体方差相同,因为t检验要求两总体分布方差相同,当然这里也只是假设二者相同。
在使用t检验对样本抽样均值和总体均值差异显著判断时要求总体方差未知,否则就可以利用 Z 检验(也叫U检验,就是正态检验)
要知道统计学理论和计算机领域的机器学习一样都是建立在假设之上的,也就是说在预先设置假设后才在这些假设之上构建的后面的理论。这里使用t检验时对两总体分布均值差异显著性判断时就是假设两总体方差相同的。
声明:下面的公式来源一文详解t检验。
- 抽样样本与目标总体分布之间均值差异性判断构建的统计量:
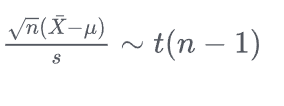
- 两个抽样样本均值差异性判断,

- 配对样本均值检验,来自某总体分布的抽样样本X在某因素影响下对应改变为另一种样本抽样Y,如:同一受试对象的自身前后对照(如检验癌症患者术前、术后的某种指标的差异)
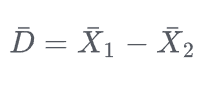

t检验在机器学习领域中的应用
在机器学习领域,我们针对某个问题可以构建几个不同的算法或模型,往往为了判断哪两个算法更优我们会使用t检验。我们假设由两个算法A、B,每个算法均进行24次重复实验,即24次trial,我们可以根据重复实验的结果计算出A、B算法的实验结果的均值,从而我们可以构建t统计量:

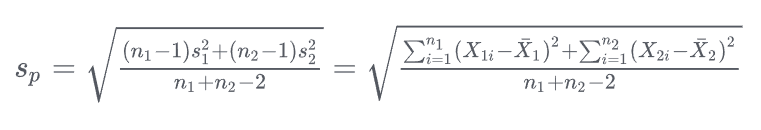
这个例子中
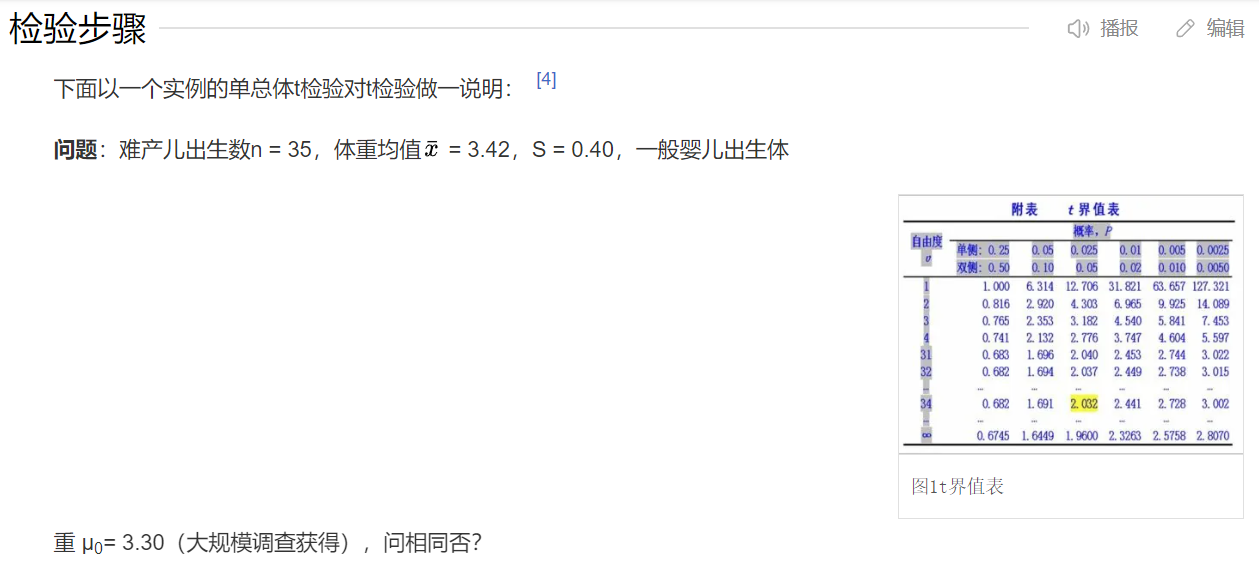
问题示例:(一个实例的单总体t检验对t检验)
判断一个抽样样本(下例子中样本数为35)是否与某总体分布具有统计学意义?
零假设,由于统计量中主要计算部分为
由于
当,

个人github博客地址:
https://devilmaycry812839668.github.io/


posted on 2024-10-24 17:09 Angry_Panda 阅读(339) 评论(0) 编辑 收藏 举报










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2023-10-24 在论文写作时是否可以使用第一人称???
2023-10-24 vscode远程连接远程主机上的docker —— 设置命令 —— -p 5001:5001
2021-10-24 如何在python同一应用下的多模块中共享变量