
深度学习需要float64精度吗 —— 为什么各大深度学习框架均不支持float64的深度学习运算呢 —— 商用NVIDIA显卡的float64性能是否多余呢
首先要知道这么几个事实,也是交代一下本文要讨论的问题的背景:
- 各大深度学习框架均支持float64类型的简单运算,但是均不支持float64的深度学习的运算操作;
- 作为深度学习运行的加速设备,各种GPU、TPU、NPU的各种XPU均以其卓越的float64精度计算能力作为宣传,如NVIDIA公司的显卡,其商用版本显卡与家用版本最大的两个不同的性能参数,一个是显存带宽,另一个则是float64计算能力;
在知道了上面的几个事实后,我们这里要问的问题就是既然各大深度学习的设备厂商都以float64性能作为主打宣传,但是为啥各大深度学习框架不支持float64的深度学习运算操作呢?
答案:
-
深度学习的各种操作其实用不到float64精度。
经过研究发现float32精度就完全够用,而且计算结果和float64精度基本保持一致,甚至有大量研究发现float16精度可以取得和float32精度下相近的最终结果,更为甚者有研究使用int16或int8的精度来进行深度学习计算,也能获得和float32精度下相差程度可以接受的结果。 -
在进行加速计算时浮点型精度越高计算速度越慢,占用的显存也越大,如float16的运算速度则是float32的2倍,而显存占用则是50%,而使用int8这种精度更小的整数类型进行计算则更能大幅度加速计算并减少显存占用(当然这时产生的最终结果要比float32下的有一定差距,但通过一些技术可以控制在一定的可接受范围内)。
-
各种xPU的始祖,NVIDIA的GPU,其通用计算能力最初是为HPC做异构计算加速的,那个时候还没深度学习什么事情呢。HPC,就是传输中的高性能运行,一般使用C/C++语言配合MPI消息传递框架进行编程,主要运行在各个超级计算机集群上,如我国的天河超算,银河超算等等,最初的应用场景就是做仿真计算,如为飞机制造做设计,算空气动力学,算化学方程式,算药物学方程式,算核物理方程式,算卫星火箭导弹的各种方程式,算天气预报的各种方程式,算地震预测的各种方程式,等等吧,总之这些类型的计算又可以统称为线性代数计算(对,这个就是大学里面学的那个矩阵计算的那个数学)。最初美国搞出HPC这一套东西的时候都是用CPU计算的,后来NVIDIA公司提出这种矩阵计算其实使用GPU是速度更快的,因为GPU本身就是为计算机图形显示做矩阵计算的,也因此就有了GPU的通用计算的这个功能,而这个功能也就自然而然的用到了HPC上,这也就是最早的异构计算。但是政府和军方的订单总是有限的,为了进一步扩大营收,NVIDIA公司就把这个GPU的通用计算功能扩展到了家用级别的显卡上,也就是后来的GTX和RTX这些类型的显卡,这些家用显卡由于具备和军用、政府用的商用级别显卡具备近乎相同的计算能力(除显存带宽和float64精度计算能力不同),其它方面的性能都是几乎一致的。显存带宽会控制整体计算能力的最大吞吐量,也就是控制了GPU设备的最高计算性能,但是要注意,由于GPU的计算核心是不被限制的,因此即使被控制最大吞吐量,但是对于绝大部分科研用处的使用都是足够的,而且要知道往往集群GPU的计算才比较受显存带宽的影响,而绝大部分非军用、非政府用的单机或小集群(三五台主机的情况)其实GPU的带宽对整体性能影响不大。而float64的计算往往是用于军用和政府用处的对精度要求高的仿真计算上,如对桥梁设计时的受力仿真分析,对核物理的反应方程式的计算等等,而民营的场合和科研单位的场合往往是小集群的(受显存带宽影响较小),并且对计算精度要求并不高(比如算某个聚类算法的baseline,如k-means),基本float32就够用,即使有用到float64精度的时候,科研单位或者民用的场合对于这个计算性能要求也没那么高,毕竟家用GPU的float64计算能力只是商用的30%到50%性能,也不是不能用,只是慢些,这种科研单位和民用场合是完全可以接受的。
-
深度学习的任务类型属于线性代数计算,也就是说深度学习计算也是HPC计算下的任务的一种,因此GPU也可以用来给深度学习计算来加速(这也是为啥现在GPU这么火的原因)。
-
深度学习框架在设计的时候同时也包括了非深度学习之外的其他线性代数的计算用处的设计,比如pytorch、TensorFlow、jax和mindspore,也就是说这些深度学习框架不仅可以用来做深度学习计算,也可以用来做其他的线性代数的计算之用,如上面见过的各种仿真计算和方程式求解等等。虽然深度学习计算用不到float64精度,但是其他类型的计算却会用到float64精度,如各种化学分子的仿真、药物仿真、天体运行仿真等等,而这些其他场景的线性代数的运算也是深度学习框架设计支持的(虽然这部分的使用率占比很小)。
总结来说,各种xPU虽然是用来给深度学习框架加速的,但是也可以用来给其他的线性代数的计算框架加速的,而很多非深度学习计算的任务是需要使用到float64精度的,因此这些xPU是需要具有float64精度的计算能力的。由于民用场合下对float64的计算场景不多,但是军用等场合是需要的,这也是为什么美国的NVIDIA公司会单纯的以float64计算能力作为民用和军用的分割点(当然还有大集群下的显存带宽也是分割点),因此float64是xPU需要支持的,民用的要比军用的xPU在float64精度上运算慢。虽然深度学习用不到float64精度,但是深度学习框架被设计用来支持的其他线性代数运算(其他科学计算任务,非自动微分的任务)却是需要使用float64精度的,这也就是为啥深度学习框架不支持float64精度的深度学习运算,但是支持float64精度的非深度学习运算(不需要自动微分的场景,不是神经网络的场景,不需要反传的场景,如机器学习算法中的k-means,很多传统的机器学习算法是不需要自动微分和求反传的)。
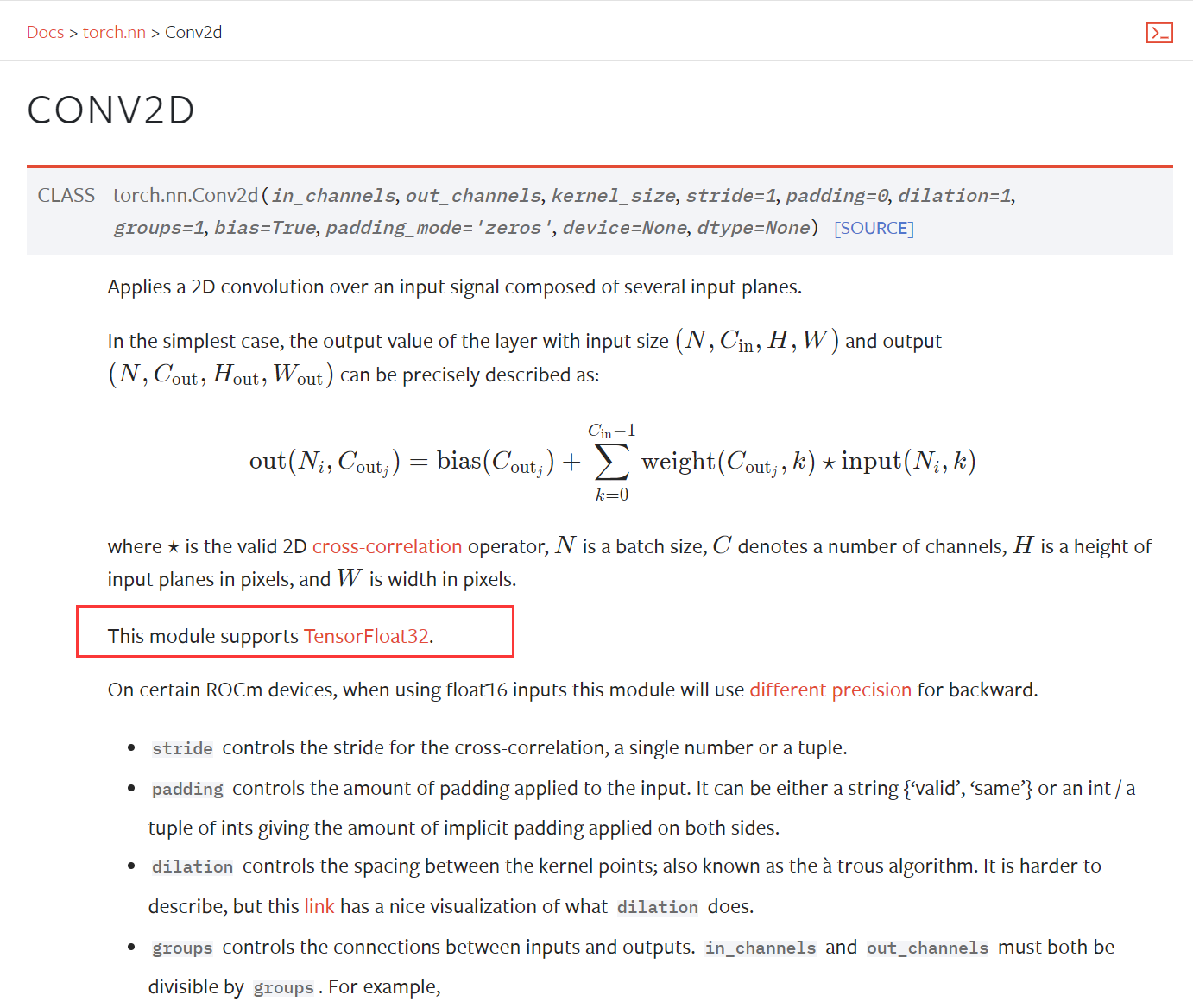
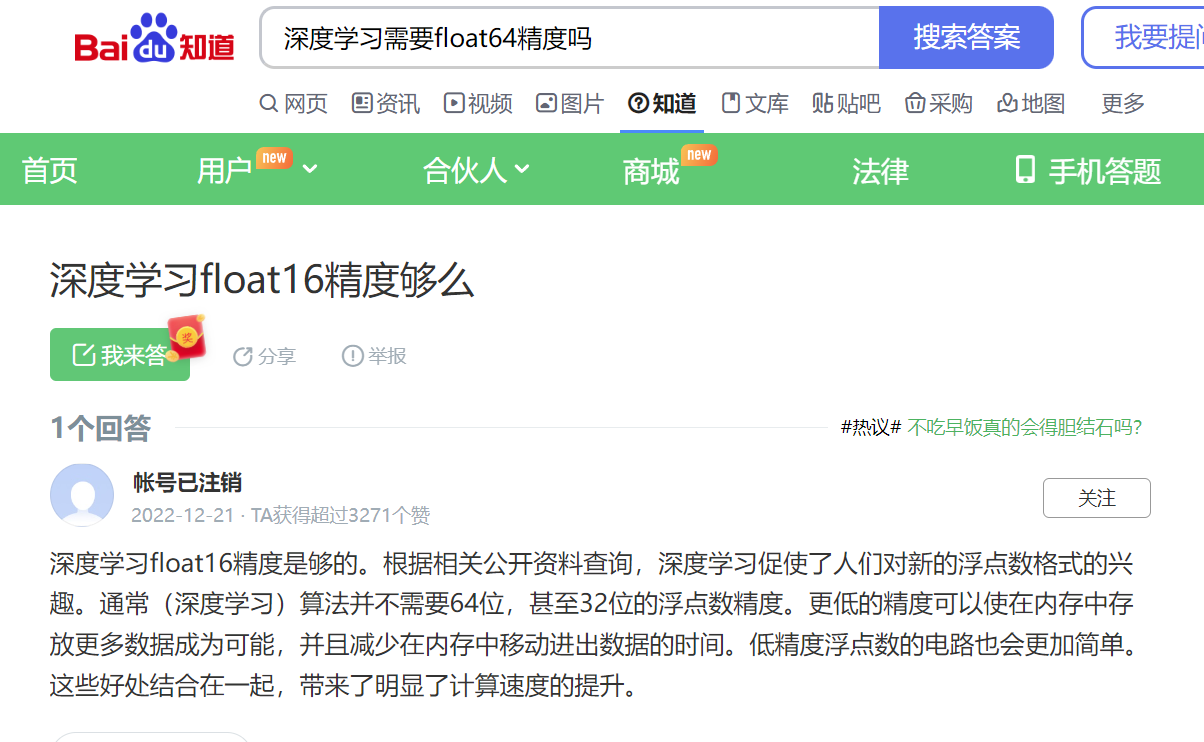
为什么深度学习框架的深度学习操作不支持float64的说明材料:
下面引自的相关链接:
地址:https://zhidao.baidu.com/question/928691981765151259.html


posted on 2024-01-14 09:25 Angry_Panda 阅读(239) 评论(0) 编辑 收藏 举报










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2023-01-14 linux工具grep的使用心得笔记