linux工具grep的使用心得笔记
grep作为linux管理中常用的三大工具之一(grep、awk、sed),其功能十分强大,因此难以对其进行全面的使用介绍,因此本文只作为个人学习的笔记之用。
grep的用处:
在文本中匹配要查询的字符串,该字符串支持通配符和正则表达式,并且在文本中进行查找的时候是以行为单位的。给一个简单的用法:查询/etc/passwd文件中root字符串。

现有待查询的文本:

例子1:
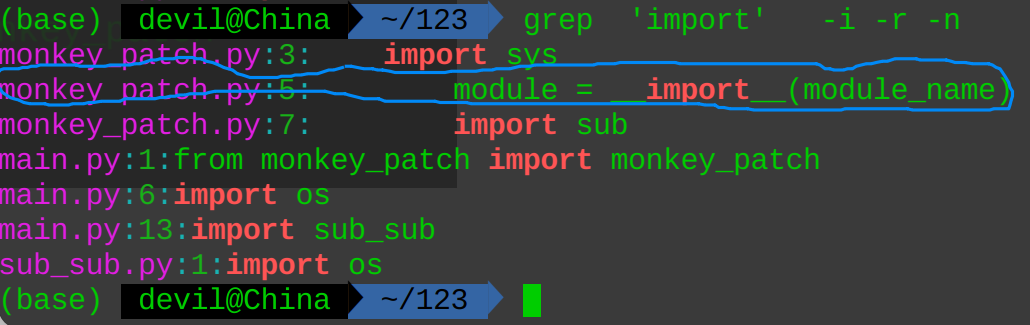
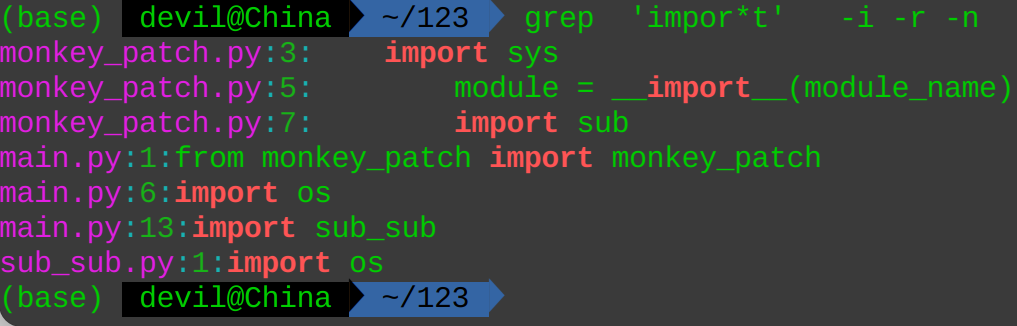
grep 'from' -i -r -n
'from' 为需要查询的字符串;
-i 为在查询匹配时不区分字符串的大小写;
-r 为在查询时对指定的目录进行迭代查询(就是说会遍历目录下面的所有子目录中的文件),这里我们默认目录为当前路径‘.’ ;
-n 为返回查询结果时标注出匹配的字符串所在行的行号;

例子2:
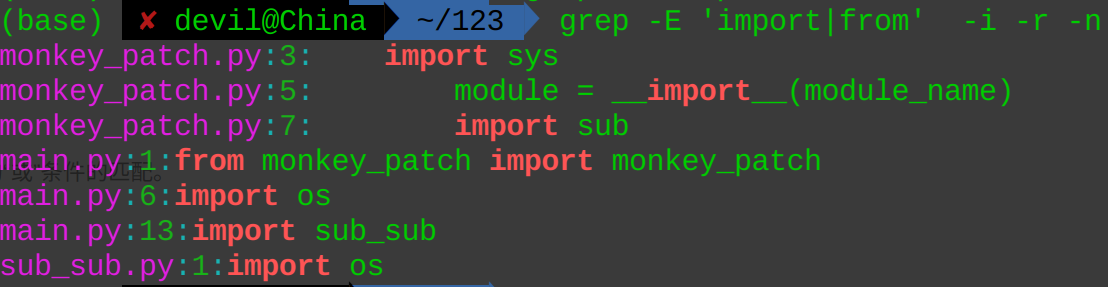
grep -E 'import|from' -i -r -n
这里匹配的是‘import’或‘from’,一行中字符串只要匹配这两个中的一个即可。
例子3: (和第二个例子很相似)
grep -e 'import' -e 'from' -i -r -n
这里匹配的是‘import’或‘from’,一行中字符串只要匹配这两个中的一个即可。

例子4:

第4个例子可以和第3个、第二个例子比较来看,可以看到,每个文本中只匹配了一行。
例子5:
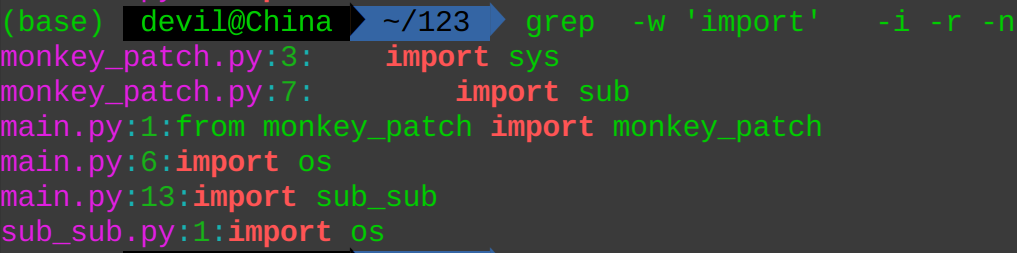
如果不加-w,则是:
例子6:
- 1 . 表示 任意一个字符
- 2 * 表示 零个或多个前面的字符
- 3 .* 表示0个或1个或多个任意字符,空行也包含在内
- 4 ? 表示0个或者1个前面的字符,使用的时候要\ 转义一下
- 5 + 表示一个或者多个+前面的字符
- 6 | 在正则表达式里面表示或者,能够写多个,是特殊符号,要使用转义 或者-E 或者 egrep
- 7 () 括号表示一个总体,{1,3}大括号表示一个范围,“ ? +(){} | ” 都是特殊符号,要使用必须转义或者-E 或者egrep,“. 和 *”不需要转义。[ ]也不需要转义。
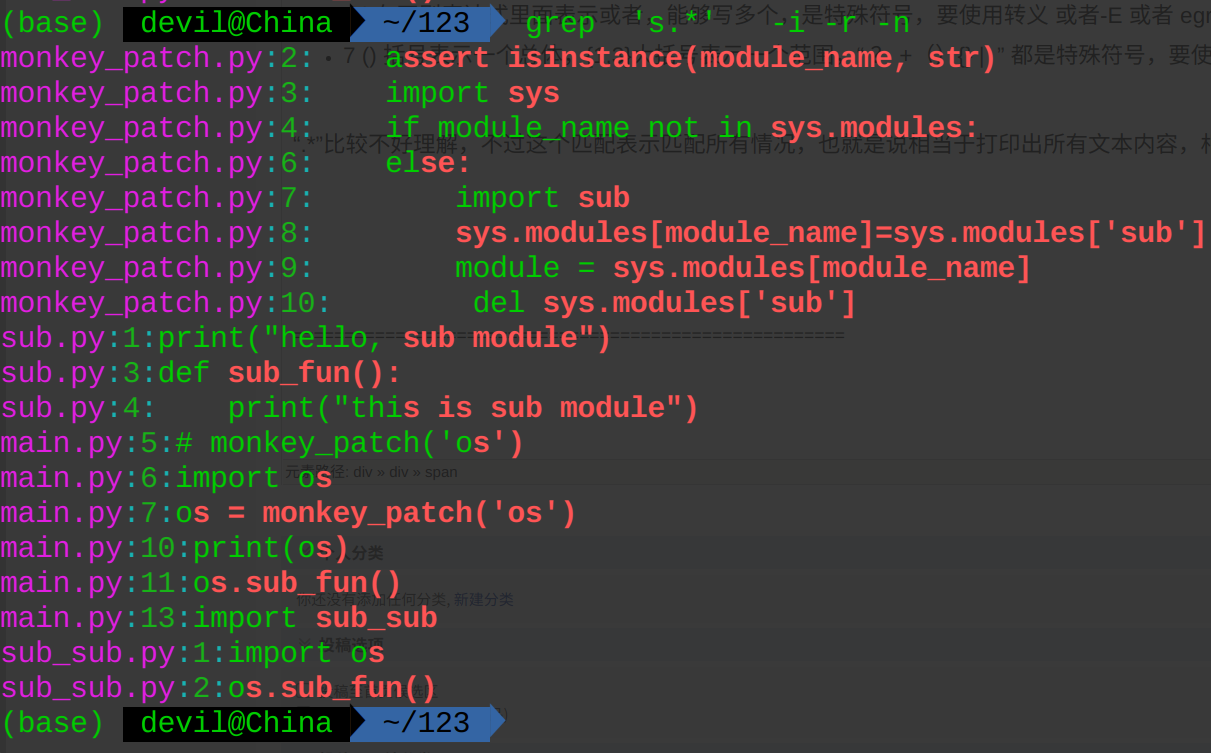


grep '\(_\)\{2\}' -i -r -n
egrep '(_){2}' -i -r -n
需要注意的是()是需要转义的,而[ ]是不需要转义的。
grep 'impor\+t' -i -r -n
grep 'impo[a-zA-Z0-9]t' -i -r -n
[ ]是不需要转义的,()是需要转义的。
[ ]表示的是单一字符的匹配范围,()表示的是1个或多个字符的匹配范围。
a-z 表示所有小写英文字母;
A-Z 表示所有大写英文字母;
0-9 表示所有数字。

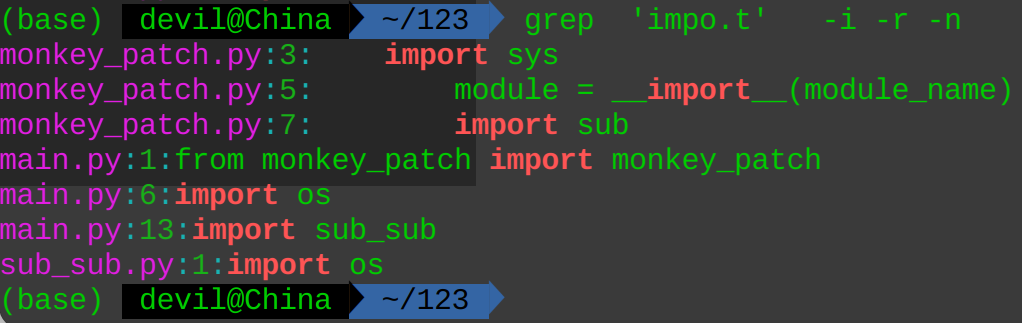
匹配字符中^代表行首,$代表行尾,"^s"代表位于行首的为"s"的字符,"s$"代表位于行尾的为"s"的字符,例子:grep '^i' -i -r -n
grep 'b$' -i -r -n
grep '^i.*s$' -i -r -n
其中,“.*”表示任意长度的任意字符串。
grep 's\{2\}' -i -r -n 
等价于:
grep '\(ss\)\{1\}' -i -r -n
等价于:
grep 'ss' -i -r -n
{ } 中可以指定多个重复的数值:
grep 's\{1,2\}' -i -r -n 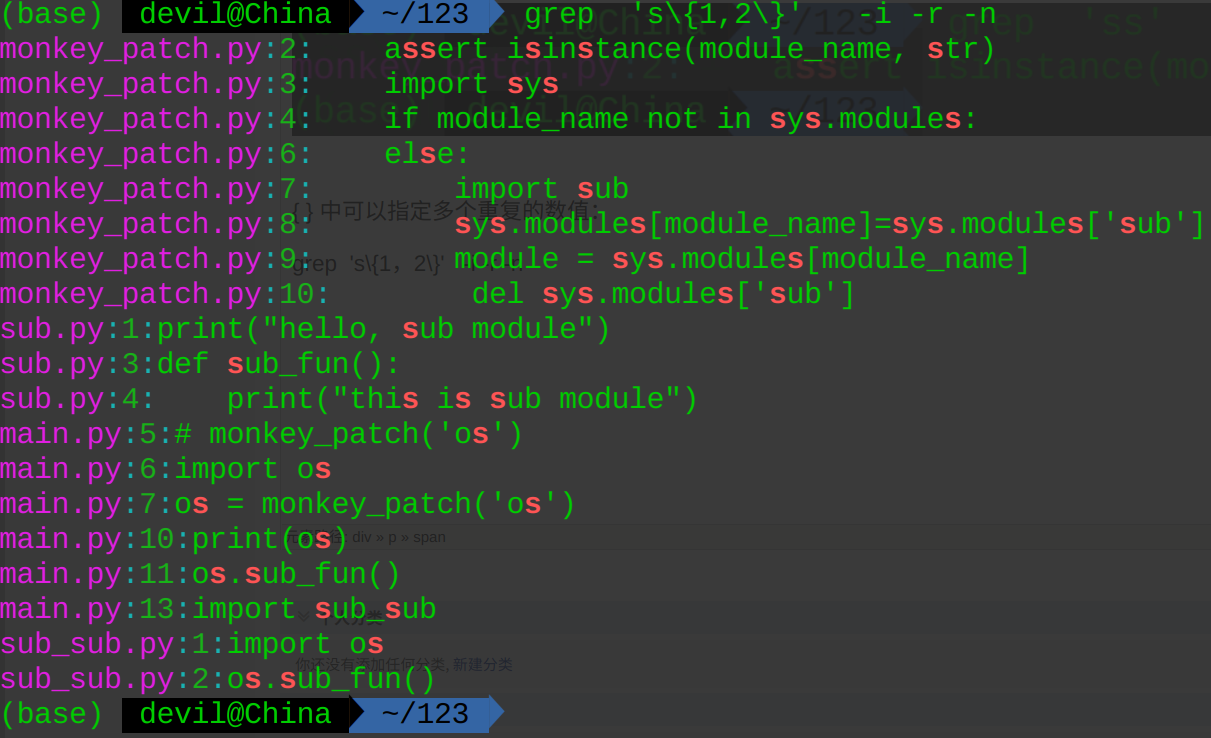
grep 'imp\(or\|ro\)t' -i -r -n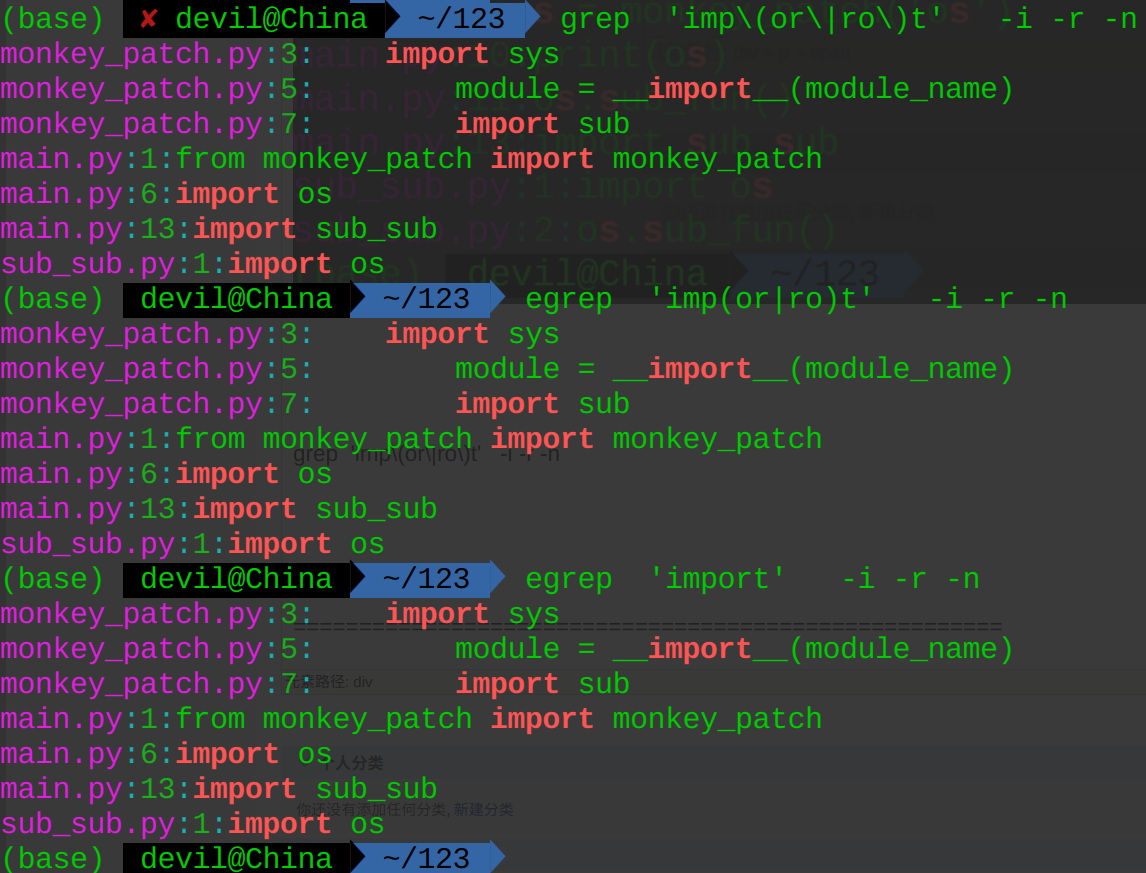
可以在特殊字符“( )”的中间嵌套其他特殊字符。

grep -E 等价于egrep,相当于对需要转义的字符提前做了转义。
- 1 . 表示 任意一个字符
- 2 * 表示 零个或多个前面的字符
- 3 .* 表示0个或1个或多个任意字符,空行也包含在内
- 4 ? 表示0个或者1个前面的字符,使用的时候要\ 转义一下
- 5 + 表示一个或者多个+前面的字符
- 6 | 在正则表达式里面表示或者,能够写多个,是特殊符号,要使用转义 或者-E 或者 egrep
- 7 () 括号表示一个总体,{1,3}大括号表示一个范围,“ ? +(){} | ” 都是特殊符号,要使用必须转义或者-E 或者egrep,“. 和 *”不需要转义。[ ]也不需要转义。
- grep -n 显示符号要求的行,并显示行号
- grep -c 打印符合要求的行数
- grep -v 打印不符合要求的行,取反的意思
- grep -r 会把目录下的全部文件所有遍历;-r针对的是目录,若是不加-r只能针对文件
- grep -i 忽略大小写
- grep -A2 打印符合要求的行以及下面两行
- grep -B2 打印符合要求的行以及上面两行
- grep -C2 打印符合要求的行以及上下两行
- grep -w 匹配一个完整的单词
- grep -E 特殊符号脱意==egrep
- centos7中自带 --color显示颜色 ;
- grep 跟特殊符号的话,要用单引号
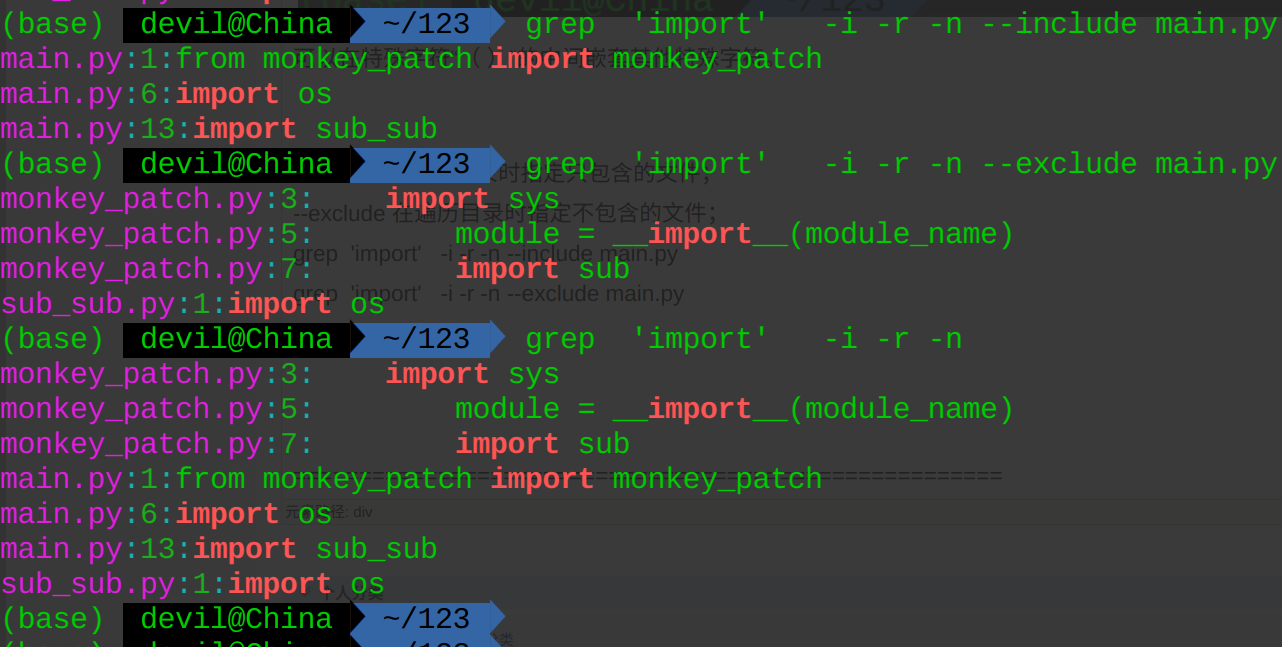
- grep --include 包含
- grep -l 只打印出含有匹配字符串的文件名,不输出具体匹配行的数据
参考:
http://www.noobyard.com/article/p-khsjayud-o.html
http://t.zoukankan.com/seaBiscuit0922-p-7744558.html
https://www.cnblogs.com/niguding/p/16573285.html
posted on 2023-01-14 18:30 Angry_Panda 阅读(221) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号