tensorflow的官方强化学习库agents的相关内容及一些注意事项
源代码地址:
https://github.com/tensorflow/agents
TensorFlow给出的官方文档说明:
https://tensorflow.google.cn/agents
相关视频:
https://www.youtube.com/watch?v=U7g7-Jzj9qo
https://www.youtube.com/watch?v=tAOApRQAgpc
https://www.youtube.com/watch?v=52DTXidSVWc&list=PLQY2H8rRoyvxWE6bWx8XiMvyZFgg_25Q_&index=2
-----------------------------------------------------------
框架实现的算法:
论文1:
论文3:
论文4:
论文5:
论文6:
论文7:
论文8:
论文9:
论文10:
====================================
1. gym的环境版本有要求,给出具体安装及Atari的安装:
pip install gym[atari]==0.23.0
pip install gym[accept-rom-license]
=====================================
2. 代码的逻辑bug
tf_agents/specs/array_spec.py 代码bug:
def sample_bounded_spec(spec, rng): """Samples the given bounded spec. Args: spec: A BoundedSpec to sample. rng: A numpy RandomState to use for the sampling. Returns: An np.array sample of the requested spec. """ tf_dtype = tf.as_dtype(spec.dtype) low = spec.minimum high = spec.maximum if tf_dtype.is_floating: if spec.dtype == np.float64 and np.any(np.isinf(high - low)): # The min-max interval cannot be represented by the np.float64. This is a # problem only for np.float64, np.float32 works as expected. # Spec bounds are set to read only so we can't use argumented assignment. low = low / 2 high = high / 2 return rng.uniform( low, high, size=spec.shape, ).astype(spec.dtype) else: if spec.dtype == np.int64 and np.any(high - low < 0): # The min-max interval cannot be represented by the tf_dtype. This is a # problem only for int64. low = low / 2 high = high / 2 if np.any(high < tf_dtype.max): high = np.where(high < tf_dtype.max, high + 1, high) elif spec.dtype != np.int64 or spec.dtype != np.uint64: # We can still +1 the high if we cast it to the larger dtype. high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1: return rng.randint( low, high, size=spec.shape, dtype=spec.dtype, ) else: return np.reshape( np.array([ rng.randint(low, high, size=1, dtype=spec.dtype) for low, high in zip(low.flatten(), high.flatten()) ]), spec.shape)
这个代码的意思就是在给定区间能进行均匀抽样,但是由于区间可能过大因此导致无法使用库函数抽样,因此需要对区间进行压缩。
当抽样的数据类型为np.float64时,由代码:
np.array(np.zeros(10), dtype=np.float64)+np.finfo(np.float64).max-np.finfo(np.float64).min

np.random.uniform(size=10, low=np.finfo(np.float64).min, high=np.finfo(np.float64).max)

可以知道,当类型为np.float64时,如果抽样区间过大会(超出数值表示范围)导致无法抽样,因此进行压缩区间:
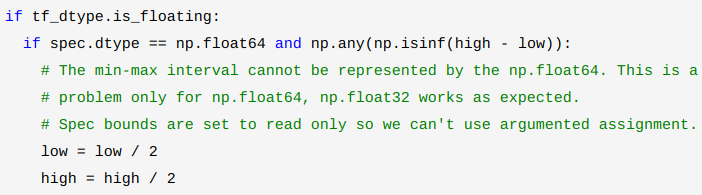
当数据类型为np.float32时,虽然也会存在超出表示范围的问题:
np.array(np.zeros(10), dtype=np.float32)+np.finfo(np.float32).max-np.finfo(np.float32).min

但是由于函数 np.random.uniform 的计算中会把np.float32转为np.float64,因此不会出现报错,如下:
np.random.uniform(size=10, low=np.finfo(np.float32).min, high=np.finfo(np.float32).max)

---------------------------------------------------
当数值类型为int时,区间访问过大的检测代码为:
np.any(high - low < 0)
原因在意np.float类型数值超出表示范围会表示为infi变量,但是int类型则会以溢出形式表现,如:

但是在使用numpy.random.randint 函数时,即使范围为最大范围也没有报错:
np.random.randint(size=10000, low=tf.as_dtype(np.int64).min, high=tf.as_dtype(np.int64).max)

np.random.randint(size=10000, low=np.iinfo(np.int64).min, high=np.iinfo(np.int64).max)

而且即使由于high值是取开区间的,我们对high值加1以后也没有报错:
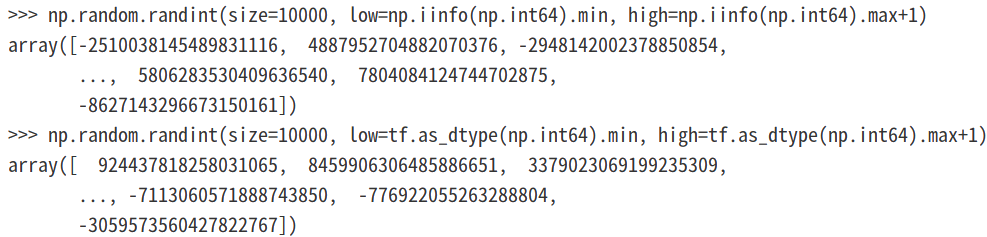
但是需要注意,此时传给np.random.randint函数中的low和high数值都为python数据类型int而不是numpy中的np.int64,下面我们看下numpy.float64类型是否会溢出:
当以数组形式传递最高high值并使其保持np.float64类型,发现使用high+1就会溢出:
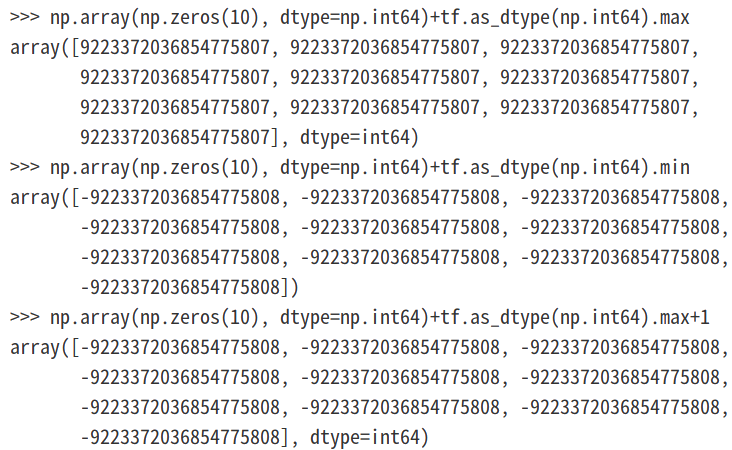
可以看到使用最大范围+1作为high值会导致报错:
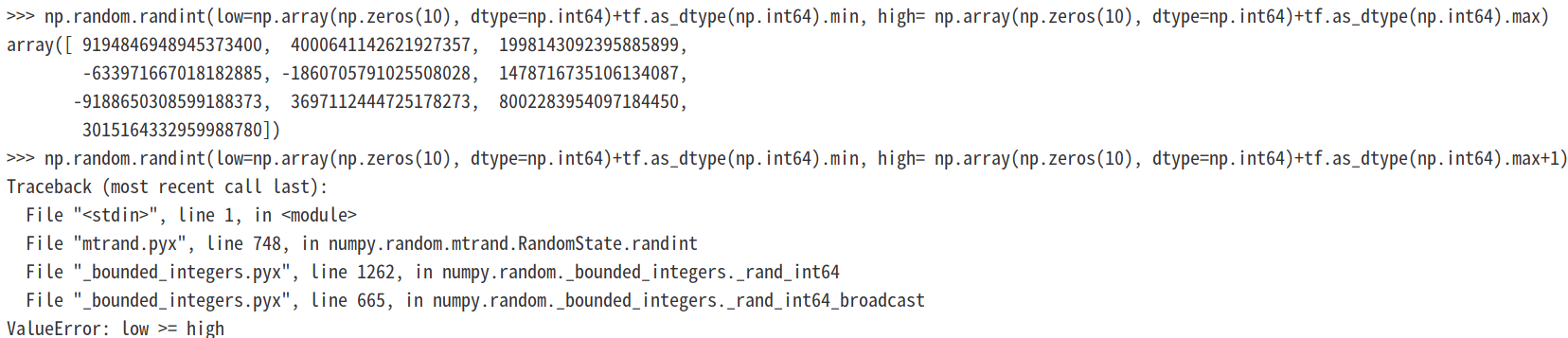
可以看到在使用numpy.random.randint时对上下限还是要注意的,虽然numpy.random.randint对上限是开区间,但是+1操作是很可能引起溢出错误的。
这也就是为什么 high+1操作之前要做判断了,如下:

不过如果数据类型不为np.int64,并且也不为np.uint64,那么我们依然可以把high值转为np.int64后在+1 ,但是上面的逻辑判断是有一定问题的,这些修正后如下:

总的修改后的代码为:
def sample_bounded_spec(spec, rng): """Samples the given bounded spec. Args: spec: A BoundedSpec to sample. rng: A numpy RandomState to use for the sampling. Returns: An np.array sample of the requested spec. """ tf_dtype = tf.as_dtype(spec.dtype) low = spec.minimum high = spec.maximum if tf_dtype.is_floating: if spec.dtype == np.float64 and np.any(np.isinf(high - low)): # The min-max interval cannot be represented by the np.float64. This is a # problem only for np.float64, np.float32 works as expected. # Spec bounds are set to read only so we can't use argumented assignment. low = low / 2 high = high / 2 return rng.uniform( low, high, size=spec.shape, ).astype(spec.dtype) else: if spec.dtype == np.int64 and np.any(high - low < 0): # The min-max interval cannot be represented by the tf_dtype. This is a # problem only for int64. low = low / 2 high = high / 2 if np.any(high < tf_dtype.max): high = np.where(high < tf_dtype.max, high + 1, high) elif spec.dtype != np.int64 and spec.dtype != np.uint64: # We can still +1 the high if we cast it to the larger dtype. high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1: return rng.randint( low, high, size=spec.shape, dtype=spec.dtype, ) else: return np.reshape( np.array([ rng.randint(low, high, size=1, dtype=spec.dtype) for low, high in zip(low.flatten(), high.flatten()) ]), spec.shape)
加入对np.uint64类型的判断:
def sample_bounded_spec(spec, rng): """Samples the given bounded spec. Args: spec: A BoundedSpec to sample. rng: A numpy RandomState to use for the sampling. Returns: An np.array sample of the requested spec. """ tf_dtype = tf.as_dtype(spec.dtype) low = spec.minimum high = spec.maximum if tf_dtype.is_floating: if spec.dtype == np.float64 and np.any(np.isinf(high - low)): # The min-max interval cannot be represented by the np.float64. This is a # problem only for np.float64, np.float32 works as expected. # Spec bounds are set to read only so we can't use argumented assignment. low = low / 2 high = high / 2 return rng.uniform( low, high, size=spec.shape, ).astype(spec.dtype) else: if spec.dtype == np.int64 and np.any(high - low < 0): # The min-max interval cannot be represented by the tf_dtype. This is a # problem only for int64. low = low / 2 high = high / 2 if spec.dtype == np.uint64 and np.any(high >= np.iinfo(np.int64).max): low = low / 2 high = high / 2 if np.any(high < tf_dtype.max): high = np.where(high < tf_dtype.max, high + 1, high) elif spec.dtype != np.int64 and spec.dtype != np.uint64: # We can still +1 the high if we cast it to the larger dtype. high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1: return rng.randint( low, high, size=spec.shape, dtype=spec.dtype, ) else: return np.reshape( np.array([ rng.randint(low, high, size=1, dtype=spec.dtype) for low, high in zip(low.flatten(), high.flatten()) ]), spec.shape)
===========================================
tf-agents框架的交互逻辑代码:
===========================================
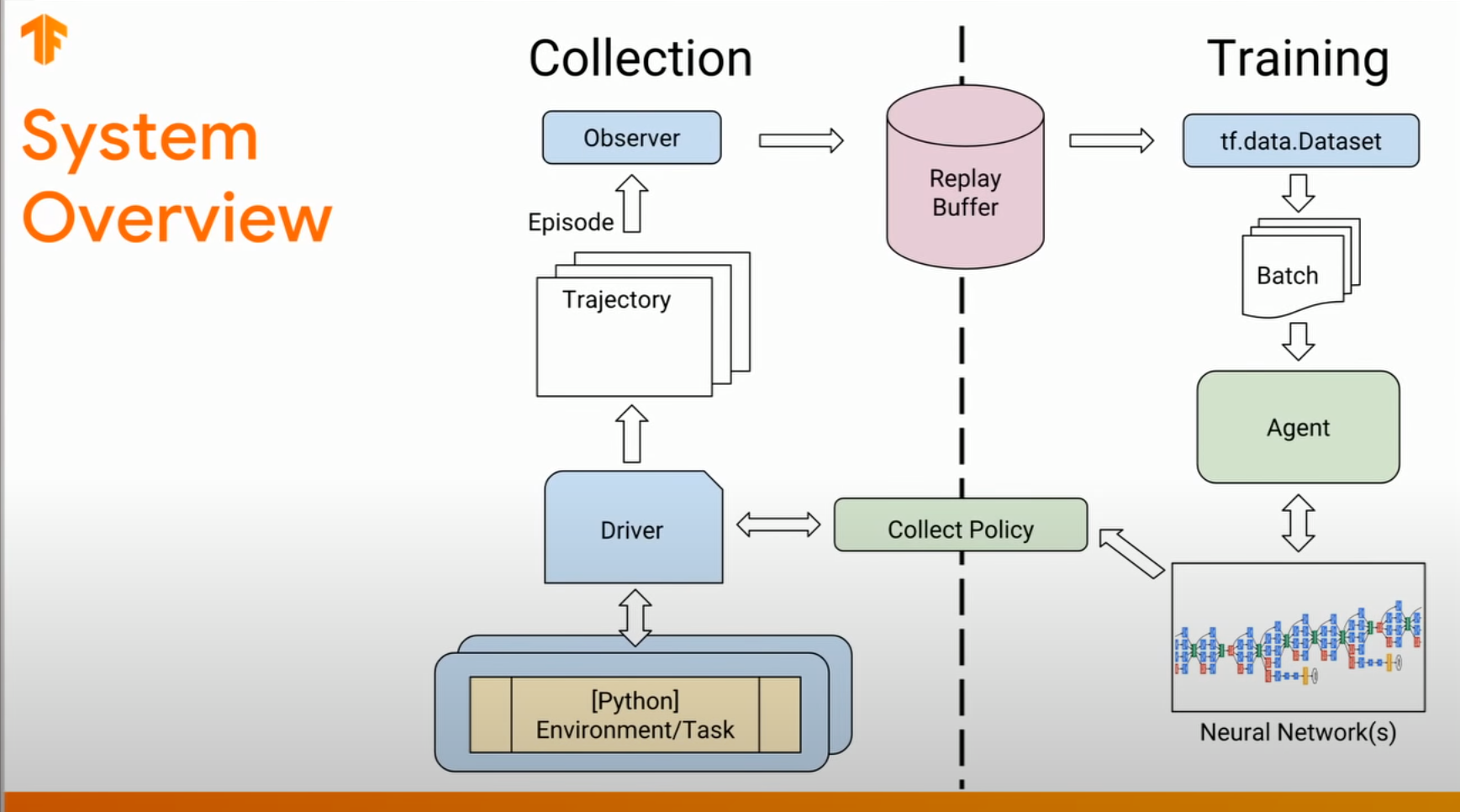





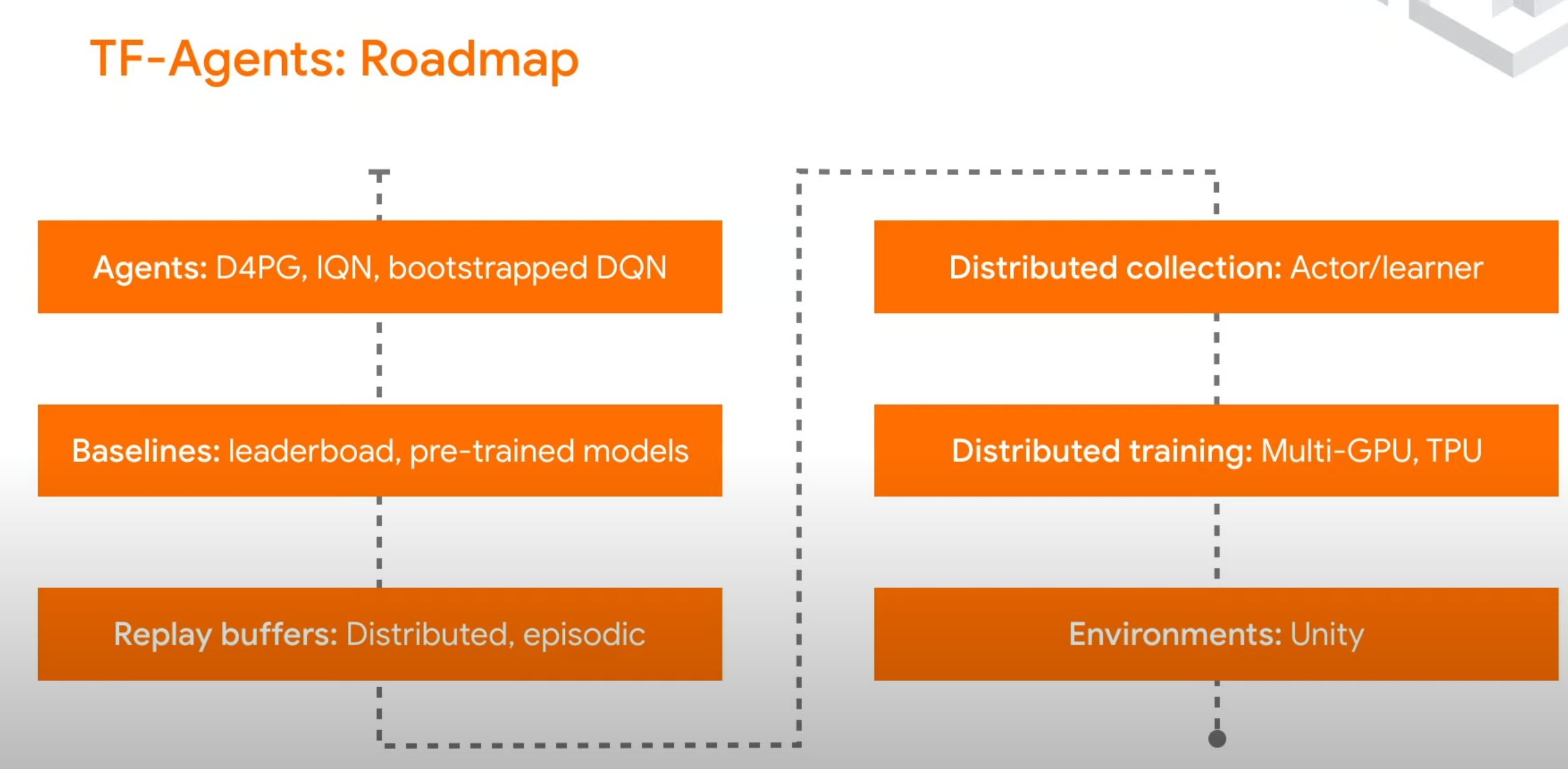

posted on 2023-01-01 13:12 Angry_Panda 阅读(442) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号