机器学习领域中假设检验的使用
机器学习领域中置信区间的使用
本文讨论假设检验的相关问题。
基本概念:
样本(一般指样本集合):一次从总体抽样中获得的样本集合。
样本量/样本个数:一次从总体抽样中获得的样本集合的样本数目。
===============================
对于假设检验是什么就不作介绍了,本文主要是介绍在机器学习领域一般对假设检验的使用,这里主要参考:
作为非统计专业的同学,关于置信区间,你需要了解什么?

就像前文机器学习领域中置信区间的使用中给出的例子,我们可以通过对总体的抽样计算出总体的某个置信度下的置信区间,而该种形式是对总体期望的评估,使用局限性很大,而在机器学习领域中我们使用更多的是对两个总体的差异评估,比如:某个原始算法试验m次后获得抽样数据,其样本均值为X_bar,方差为S1;该原始算法的改进算法试验n次后获得抽样数据,其均值为Y_bar,方差为S2;那么我们就可以使用T检验来判断改进后的算法性能是否得到了提升。
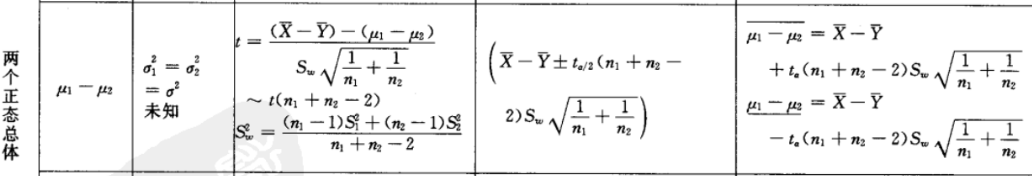
μ1为原算法的总体期望,μ2为改进算法的总体期望。
这里假设H0:μ1=μ2;H1:μ1≠μ2 .根据95%的置信度计算出置信区间的上下限,由于这里假设H0成立,也就是说假设μ1-μ2=0,
可以得到 X_BAR - Y_BAR 的上限:
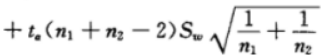
可以得到 X_BAR - Y_BAR 的下限:
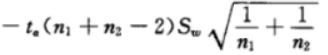
如果实际抽样中的X_BAR - Y_BAR在该区间内,则接受H0假设,如果不在该区间则拒绝H0假设。如果接受H0则说明改进后算法没有提升。
可以看到上面的假设检验只能估计两个总体期望是否相当,也可以假设H0:μ1≤μ2;H1:μ1>μ2 .
注意此时使用的不是上面例子的双侧检验而是单侧检验,α为0.05,在双侧检测时,t值为tα/2,而在单侧检验时t值为tα;
假设H0成立,也就是μ1-μ2≤0,可以得到 X_BAR - Y_BAR 的上限小于等于:
可以得到 X_BAR - Y_BAR 的下限小于等于:
也就是说只有当X_BAR - Y_BAR的真实计算值大于上面的上限值才可以拒绝H0假设,否则为接受。
通过这个方法来估计新算法是否比原始算法在统计意义上有性能提升。
========================================
参考:
posted on 2022-12-06 15:46 Angry_Panda 阅读(232) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号