【解决】ValueError: Memory growth cannot differ between GPU devices
在ubuntu系统下双显卡运行TensorFlow代码报错:
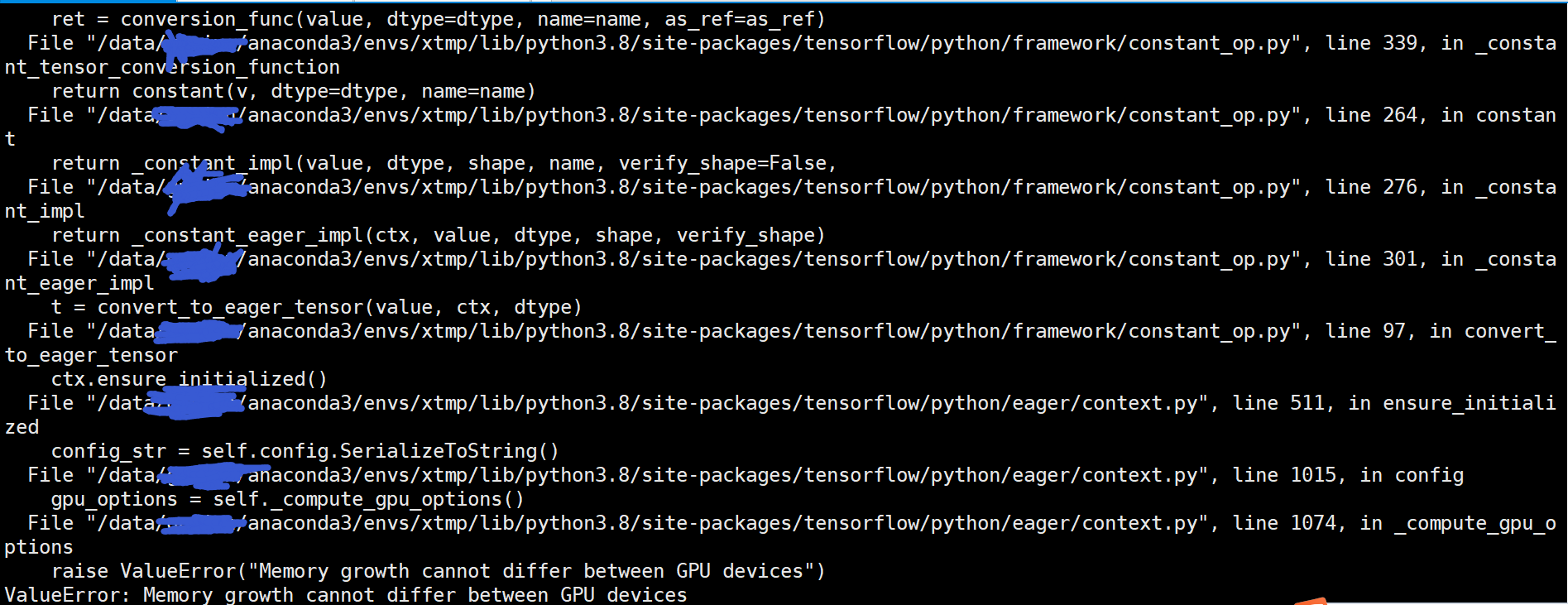
ValueError: Memory growth cannot differ between GPU devices
报错的代码位置为: tf.config.experimental.set_memory_growth(physical_devices[0], True)
全部代码:
import os import tensorflow as tf from tensorflow.keras.applications import resnet50 physical_devices = tf.config.list_physical_devices('GPU') print(physical_devices) tf.config.experimental.set_memory_growth(physical_devices[0], True) #加载预训练模型 model = resnet50.ResNet50(weights='imagenet') #save_model方式保存模型 tf.saved_model.save(model, "resnet/1/")
报错:

===============================================
查了网上的各种说法,有的说是TensorFlow的版本问题,有的说是TensorFlow的bug问题,有的说的gpu的版本问题(只有rtx2070和rtx2080的双显卡才会报错)
于是我就换了在服务器上运行,服务器为4卡泰坦,运行结果与上面的相同。
通过这样的对比实验我们可以得出结论,那就是这个并不是TensorFlow版本问题或是显卡版本问题,而是对于多显卡的运行模式下上面的写法并不是很正确,这本身就是TensorFlow的预先设定。
=====================================================
如果代码修改下就可以不报错,也就是添加内容:os.environ['CUDA_VISIBLE_DEVICES']='0'
import os import tensorflow as tf from tensorflow.keras.applications import resnet50 os.environ['CUDA_VISIBLE_DEVICES']='0' physical_devices = tf.config.list_physical_devices('GPU') print(physical_devices) tf.config.experimental.set_memory_growth(physical_devices[0], True) #加载预训练模型 model = resnet50.ResNet50(weights='imagenet') #save_model方式保存模型 tf.saved_model.save(model, "resnet/1/")
运行正常不报错:

如果修改成下面这样,依然报同样的错误。
import os import tensorflow as tf from tensorflow.keras.applications import resnet50 #os.environ['CUDA_VISIBLE_DEVICES']='0' physical_devices = tf.config.list_physical_devices('GPU') print(physical_devices) #os.environ['CUDA_VISIBLE_DEVICES']='0' tf.config.experimental.set_memory_growth(physical_devices[0], True) #加载预训练模型 model = resnet50.ResNet50(weights='imagenet') #save_model方式保存模型 tf.saved_model.save(model, "resnet/1/")
回过头我们再仔细研究下报错的信息:

其实之所以报错就是因为主机有多块显卡,我们默认进行计算的时候是使用所有的显卡的,但是我们设置set_memory_growth时只为了部分显卡做设定,这样就造成了所要调用的显卡中部分显卡为set_memory_growth模式而部分不是,这样就造成了显卡与显卡之间的模式不已配的问题,因此也就报错了:
ValueError: Memory growth cannot differ between GPU devices
解决这个问题也是简单只要我们把所有用到的显卡模式设置为统一,如果设置set_memory_growth模式就为所有显卡都进行设定,也或者我们指定只使用部分显卡然后对这部分指定的显卡设置set_memory_growth模式。而设定只使用部分显卡的写法为:
os.environ['CUDA_VISIBLE_DEVICES']='0'
os.environ['CUDA_VISIBLE_DEVICES']='0,1'
而且需要知道一点,那就是os.environ['CUDA_VISIBLE_DEVICES']='0'这样的设置必须在调用TensorFlow框架之前声明否则不生效,这样同样会报错,就像上面的对比实验一样。
如下面:
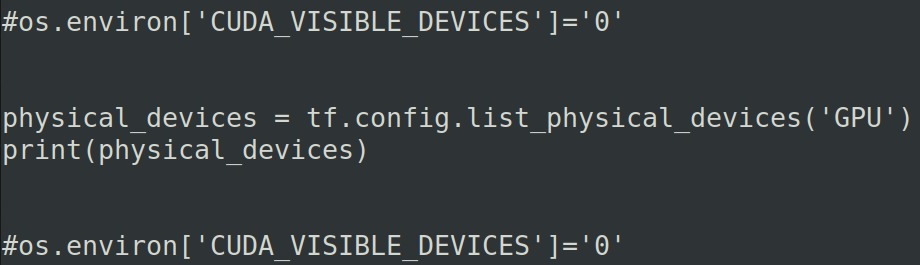
为了方便我们可以直接把os.environ['CUDA_VISIBLE_DEVICES']='0'写在文件的最前面。
===============================================
如果我们想使用多块显卡进行计算,并且想使用set_memory_growth设置,那么我们就需要对这些显卡都进行set_memory_growth模式设置,具体如下代码:
import os import tensorflow as tf from tensorflow.keras.applications import resnet50 os.environ['CUDA_VISIBLE_DEVICES']='0,1' physical_devices = tf.config.list_physical_devices('GPU') print(physical_devices) tf.config.experimental.set_memory_growth(physical_devices[0], True) tf.config.experimental.set_memory_growth(physical_devices[1], True) #加载预训练模型 model = resnet50.ResNet50(weights='imagenet') #save_model方式保存模型 tf.saved_model.save(model, "resnet/1/")
关键的设置为:
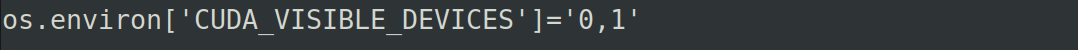

==================================================
posted on 2022-05-22 09:59 Angry_Panda 阅读(1144) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号