MindSpore 数据加载及处理
参考地址:
https://www.mindspore.cn/tutorial/zh-CN/r1.2/dataset.html
========================================================
数据集下载:
mkdir -p ./datasets/MNIST_Data/train ./datasets/MNIST_Data/test wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-labels-idx1-ubyte wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-images-idx3-ubyte wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-labels-idx1-ubyte wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-images-idx3-ubyte tree ./datasets/MNIST_Data
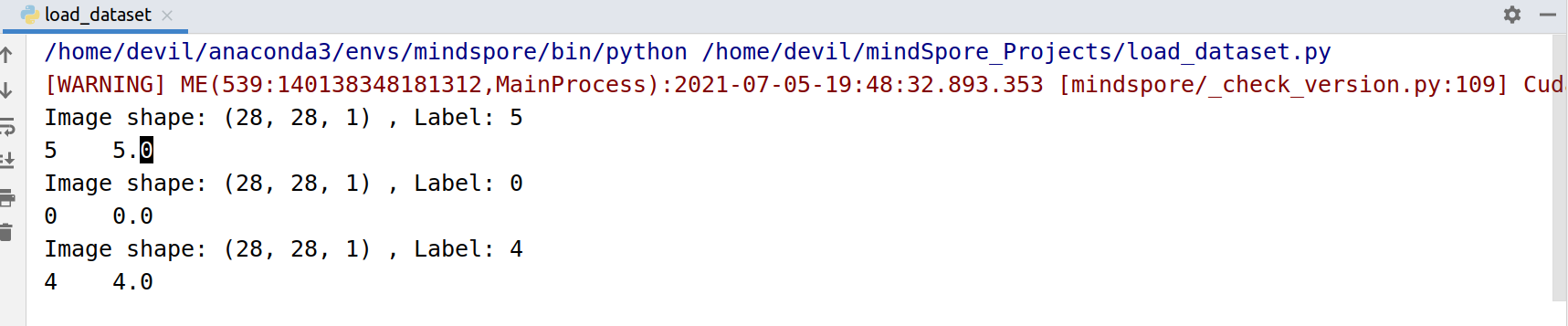
顺序读取N个样本:
import mindspore.dataset as ds from mindspore import dtype as mstype DATA_DIR = "./datasets/MNIST_Data/train" sampler = ds.SequentialSampler(num_samples=3) dataset = ds.MnistDataset(DATA_DIR, sampler=sampler) for data in dataset.create_dict_iterator(): print("Image shape: {}".format(data['image'].shape), ", Label: {}".format(data['label'])) print(data['label'], "\t", data['label'].astype(mstype.float32))
自定义数据集
import mindspore.dataset as ds import numpy as np np.random.seed(58) class DatasetGenerator: def __init__(self): self.data = np.random.sample((5, 2)) self.label = np.random.sample((5, 1)) def __getitem__(self, index): return self.data[index], self.label[index] def __len__(self): return len(self.data) dataset_generator = DatasetGenerator() dataset = ds.GeneratorDataset(dataset_generator, ["data", "label"], shuffle=False) for i, data in enumerate(dataset.create_dict_iterator()): print("第 %d 个样本"%i) print('{}'.format(data["data"]), '{}'.format(data["label"]))

对自定义数据集进行一定预处理:
import mindspore.dataset as ds import numpy as np np.random.seed(58) class DatasetGenerator: def __init__(self): self.data = np.random.sample((5, 2)) self.label = np.random.sample((5, 1)) def __getitem__(self, index): return self.data[index], self.label[index] def __len__(self): return len(self.data) dataset_generator = DatasetGenerator() dataset = ds.GeneratorDataset(dataset_generator, ["data", "label"], shuffle=False) # 随机打乱数据顺序 dataset = dataset.shuffle(buffer_size=10) # 对数据集进行分批 dataset = dataset.batch(batch_size=2) for i, data in enumerate(dataset.create_dict_iterator()): print("第 %d 次选取样本"%i) print("data: \n{}".format(data["data"])) print("label: \n{}".format(data["label"]))

数据处理及增强
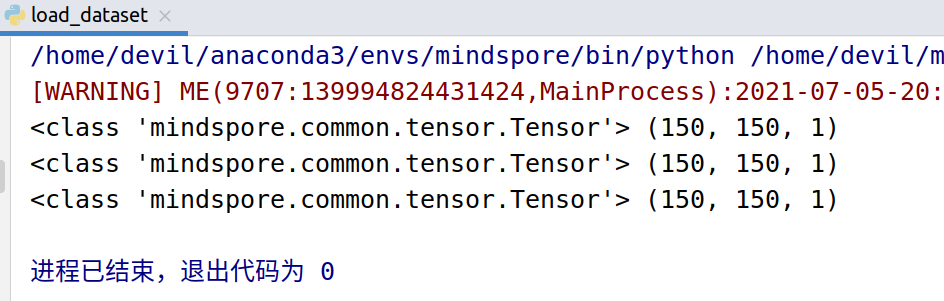
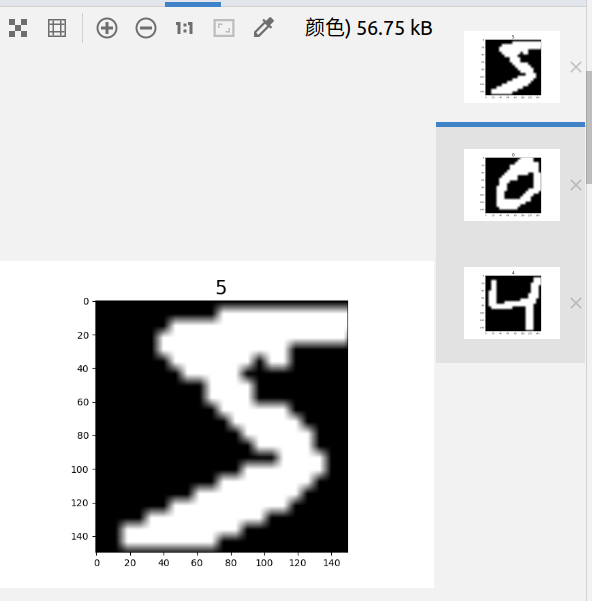
import matplotlib.pyplot as plt import mindspore.dataset as ds from mindspore.dataset.vision import Inter import mindspore.dataset.vision.c_transforms as c_vision DATA_DIR = './datasets/MNIST_Data/train' _number_samples = 3 mnist_dataset = ds.MnistDataset(DATA_DIR, num_samples=_number_samples, shuffle=False) resize_op = c_vision.Resize(size=(200,200), interpolation=Inter.LINEAR) crop_op = c_vision.RandomCrop(150) # 随机将图像裁剪成150尺寸 transforms_list = [resize_op, crop_op] mnist_dataset = mnist_dataset.map(operations=transforms_list, input_columns=["image"]) # 查看数据原图 mnist_it = mnist_dataset.create_dict_iterator() for _ in range(_number_samples): data = next(mnist_it) print(type(data['image']), data['image'].shape) plt.imshow(data['image'].asnumpy().squeeze(), cmap=plt.cm.gray) plt.title(data['label'].asnumpy(), fontsize=20) plt.show()
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2021-07-05 19:51 Angry_Panda 阅读(813) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号