强化学习中经典算法 —— reinforce算法 —— (进一步理解, 理论推导出的计算模型和实际应用中的计算模型的区别)
在奖励折扣率为1的情况下,既没有折扣的情况下,reinforce算法理论上可以写为:

但是在有折扣的情况下,reinforce算法理论上可以写为:

以上均为理论模型。
====================================================
根据上面的理论上的算法模型,或者说是伪代码,你是难以使用这个算法的。这个reinforce算法也是十分古怪和气人的,之所以这样说是因为完全根据reinforce的算法描述(伪代码)实际上基本无法写出可以正常运行的代码(能有效的代码,算法结果是不收敛的或者在使用神经网络做拟合函数会出现衰退的问题)。而且另一个古怪和气人的地方是reinforce的算法描述(伪代码)和reinforce算法的理论分析模型也是不同的,reinforce的理论分析一般都是假定有同一个执行策略(动作策略)下生成的大量episodes的数据来对评估网络(评估策略)进行更新的,而在算法描述中往往是一个episode下的每一个step的数据就对策略网络进行一次更新,或者说算法描述中我们是一个策略网络生成一个episode的数据,然后我们把这个episode下每一step的数据都用来更新一次策略网络。
总的说来,就是reinforce的标准算法描述是不可用的,往往在实际中我们使用的reinforce算法的模型,或者说实际上的算法描述(伪代码)是不同的。
===============================================
实际上的 reinforce算法,真正使用的reinforce算法是这样的:伪代码(算法描述):

但是,如果我们严格按照reinforce算法的理论推导,写出的算法模型,伪代码该是如下形式:

根据上面的两个不同具体形式的伪代码,我们可以看出严格按照理论推导得到的reinforce算法模型是需要使用折扣概率下的折扣奖励来做计算的,而实际应用中我们往往直接使用折扣奖励进行规整后的数值来进行计算。也就是说实际应用reinforce算法时我们不仅没有对奖励值取折扣概率下的值,并且还对折扣奖励进行了规整(高斯化)。
那么我们可以不可以对折扣奖励取折扣概率后再进行规整化呢,于是有了下面的算法模型,伪代码:

===========================
根据上面的分析,实际使用reinforce算法时根据对奖励值的处理可以分为以下4种:
1. 更新网络参数时使用的奖励值为 折扣奖励,也就是最原始的奖励值,不加其他处理的形式。
2. 更新网络参数时使用的奖励值为 折扣概率下的折扣奖励。
3. 更新网络参数时使用的奖励值为 将折扣奖励进行规整化后的奖励值 。
4. 更新网络参数时使用的奖励值为 将折扣概率下的折扣奖励进行规整化后的奖励值。
--------------------------
通过gym环境下的实验发现,第一种和第二种形式的reinforce算法直接导致神经网络衰退,也就是说完全随机策略进行交互我们可以得到的episode的长度在29左右,而第一种和第二种形式的reinforce算法所训练得到的策略直接会衰退到对一个episode内的所有step下的状态给出相同的action。
第二种形式下的部分运行结果:(第二种形式下,此时更新一次网络的episodes数为10)
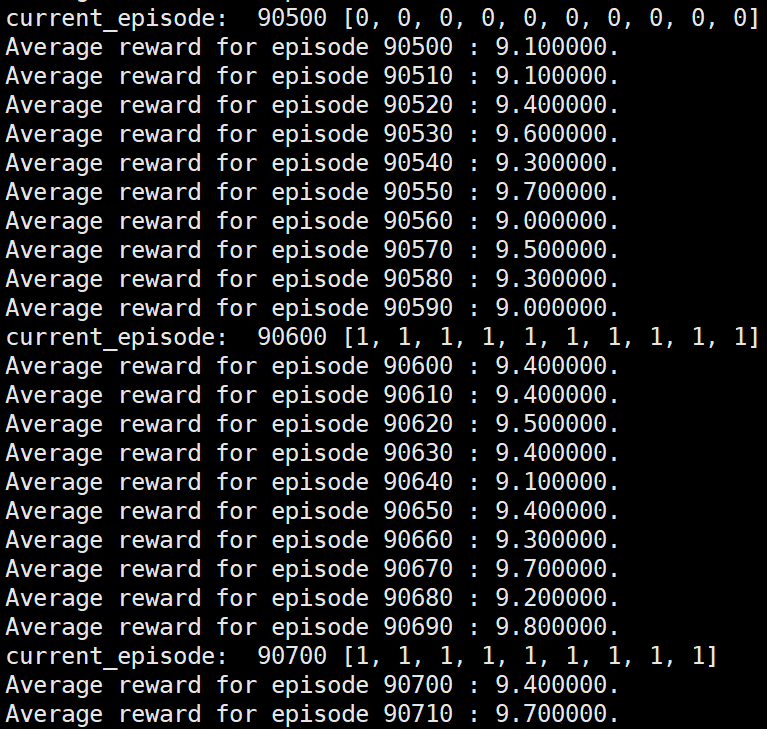
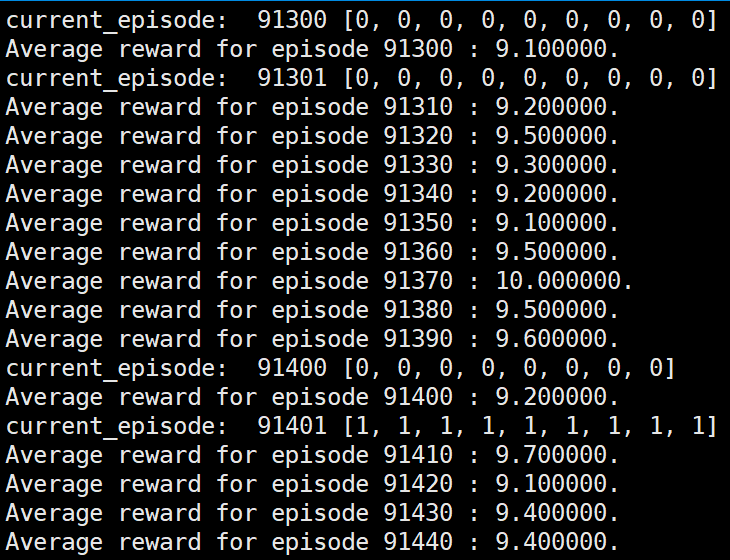
可以看到使用第二种形式的reinforce算法,在运行一段时间后运行效果直接从完全随机的策略衰退为对一个episode下的所有状态给出相同action的表现。
而在以前的博客(https://www.cnblogs.com/devilmaycry812839668/p/14097322.html)中也讨论过即使使用实际应用中最常见的第3种形式的reinforce也会有一定的概率出现衰退问题,不过那时的衰退往往是运行效果优化到了一定程度后才进行衰退的,而第二种形式的reinforce算法是直接在开始的阶段就直接从随机策略衰退到完全无效的策略(对一个episode内的所有state给出完全相同的action)。
第一种形式的reinforce和第二种形式的reinforce相似,都是从随机策略开始后快速的衰退到对一个episode内的所有state给出完全相同的action,从而变成了无效的策略。
第一种,第二种形式的reinforce直接进入衰退,而第三种,第四中形式的reinforce就可以正常运行到要求的效果,这中间的区别就是最后训练时所采用的奖励值的具体形式。
=======================================
个人的小尝试:
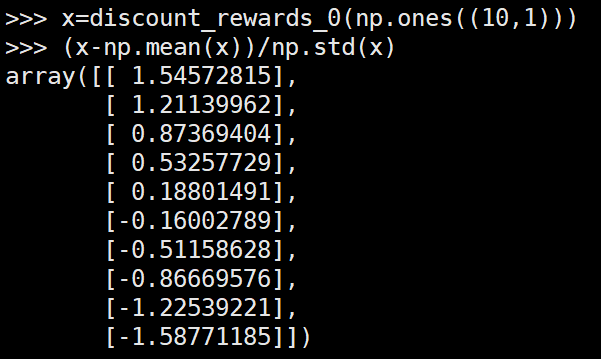
第三种形式的reinforce中最后更新网络的奖励值的例子:
(action全部都是1的情况)
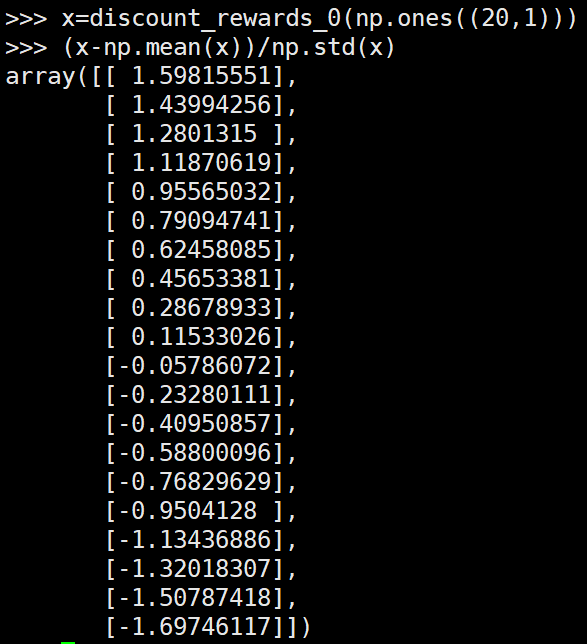
第二种形式的reinforce算法奖励值的例子:
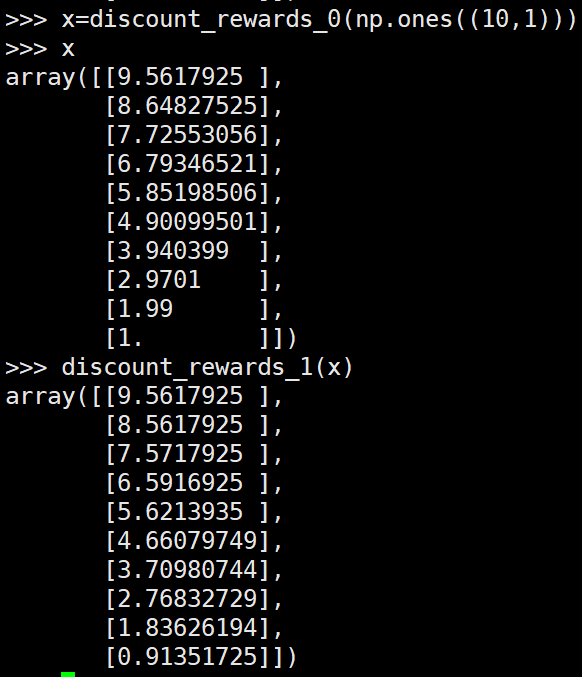
可以看到第一种形式的reinforce和第二种的reinforce最后进行网络更新时的奖励值都是大小在T到0之间,其中T为该episode的长度。而第三种形式的reinforce算法均值为0,方差为1。
观察第二种形式的reinforce和第三种reinforce的区别,更新网络时奖励值的区别,我们将第二种形式的reinforce奖励值的形式进行修改:
此时运行reinforce算法:
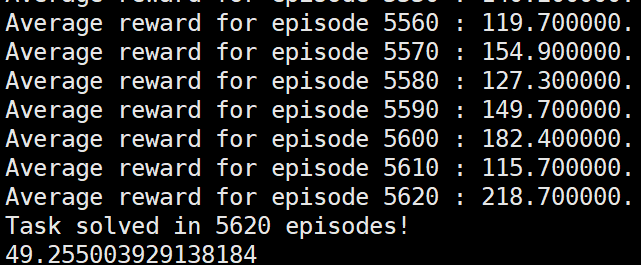
修改后的reinforce算法成功达到要求。
而第三种形式的reinforce运行结果:
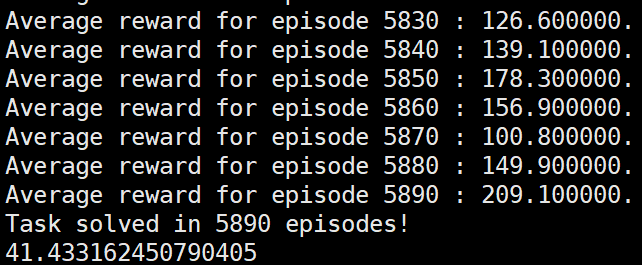
可以看到采用新的奖励值后的reinforce算法可以和第三种形式的reinforce算法性能相当,或者说并没有明显差于第三种形式的reinforce。
再一次修改第二种形式的reinforce的奖励值形式:
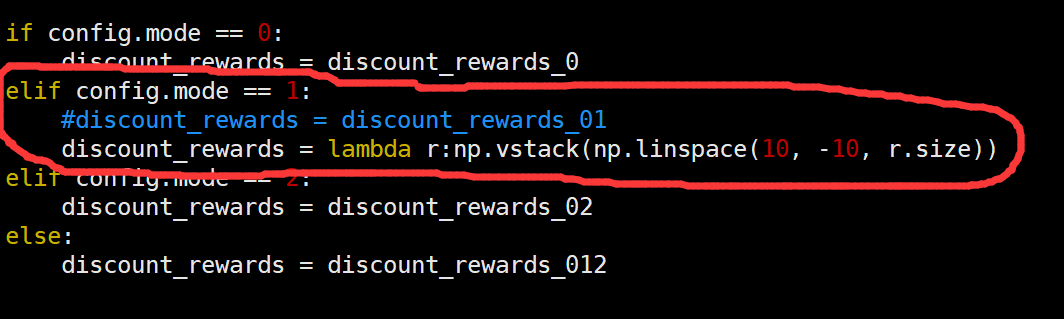
发现也是可以达到要求:
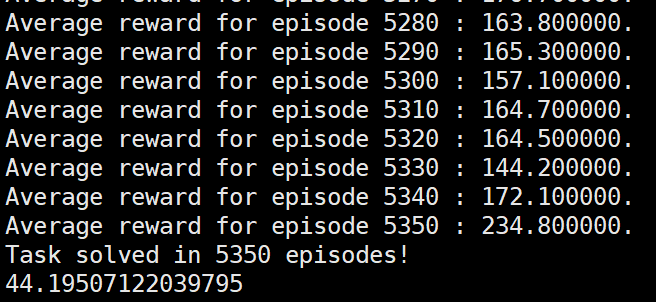
然而当奖励值形式为:

或:

reinforce算法都是无法达到要求的,直接衰退:
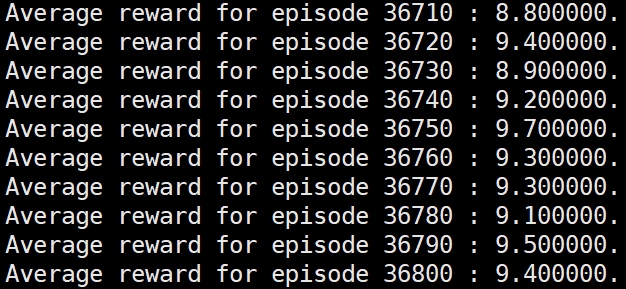
于是有了一个大胆的猜测,只要更新网络时的一个episode内的各个step的奖励值均值为0,那么必然可以运行到要求的水平,于是奖励值设置下面的形式:

发现依然成功到达要求:
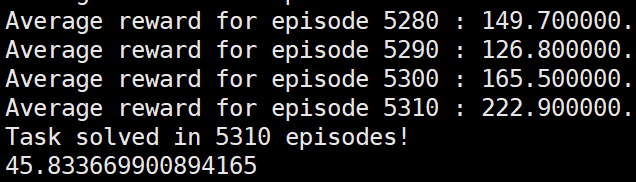
根据上面的实际应用中的reinforce的实际形式(形式3)和理论推导中的(形式2)之间运行效果的不同,我们大胆设想每一次更新网络时reinforce算法要求各奖励值的均值为0才可以成功运行。
==========================================
个人的一点小总结:
有时候理论上各种推导,各种公式,各种理论,然后各种名词堆到一起搞出一个算法,貌似应该可行,而在实际上就并不是很可行,个人感觉这说明理论是有指导作用但是没有绝定性的作用,而且至于靠谱不靠谱,完善不完善最终还是需要实际应用中去看,可能这也是那种 实践是检验真理的唯一途径。可能有时候由于理论的限制等等原因,有些改进的东西无法用完善的理论来解释但是确实可行,而有的时候有些理论感觉很完善其实却还差一些,这时候就需要一些在实践中的改进了。
单纯的从算法角度来看,那就是 reward shap 不仅会提高算法的运算效率,甚至对算法的最终性能(优化结果)也是具有很大的影响的,就像本文中的不同形式的reinforce,如果reward设置的不好往往算法不work。就像实际中的reinforce算法虽然和理论推导的形式有一些不同,但是却能work,而我们最终采用的形式就是那种可以work就用哪种。
文中代码地址:
https://gitee.com/devilmaycry812839668/cart-pole_-policy-network_-reinforce
====================================================
重要说明:
本文代码中出现错误,后已经修复,因此上面的实验结果均为错误。
经过修改后发现mode=0 , mode=1, mode=2, mode=3 均可以收敛取得最终结果。 因此原文中所得到的结论mode=0, mode=1 不能收敛是错误的。
特此更正。
----------------------------------------------
posted on 2020-12-24 22:35 Angry_Panda 阅读(3673) 评论(1) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号