读《Simple statistical gradient-following algorithms for connectionist reinforcement learning》论文 提出Reinforce算法的论文
《Simple statistical gradient-following algorithms for connectionist reinforcement learning》发表于1992年,是一个比较久远的论文,因为前几天写了博文:
论文《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》的阅读——强化学习中的策略梯度算法基本形式与部分证明
所以也就顺路看看先关的论文,尤其是这篇提出Reinforce的算法,准确的来说正是这篇论文提出了基于策略搜索的强化学习方法,所以说这是个始祖型的论文。
给出部分论文内容:




--------------------------------------------------------------------------------
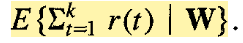
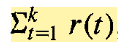

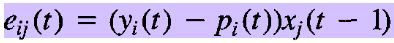
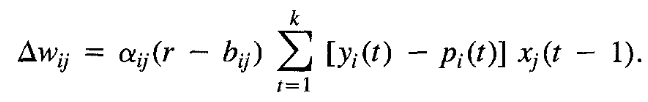
associative reinforcement problem:

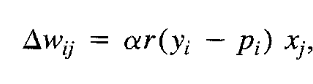
根据上面的论文中给出的公式,可以得到现在的Reinforce算法的 标准 formulation。
---------------------------------------------------------------------------------

---------------------------------------------------------------
还有一点Reinforce的名称来源是缩写:

这是原先没有想到的。
---------------------------------------------------------------
现在一般给出的reinforce算法的推导如下:

一般对于reinforce算法最终给出的形式就是上面最后的表达式。
不过上面的reinforce表达形式还可以继续推导:
因为t=0,1,2,3,4,5,......,H
假设动作集中的动作个数为A,也就是说St 状态时可以选择的动作数为A,而选择各个动作的概率和为1。而R(τ)可以写为St之前的状态行为所获得的奖励和与之后所获得的奖励和,即r(0),r(1),r(2),r(3),...,r(t-1) 折扣和 和 r(t), r(t+1), ......,r(H)折扣和。
因为当前的动作与过去的回报实际上是没有关系的,于是可以得到化简后的reinforce算法的表达式:

所以可得:


所以,化简reinforce的表现形式,可以得到:

根据上面的推导可以看出重点是在于这句话: 当前的动作与过去的回报实际上是没有关系的
对于如此关键的一句话,正是因为这句话才推导出reinforce算法的简化形式,那么这句话又是如何来进行理解呢?



![]()
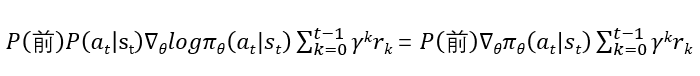
因为A1集合中的at均为a1,A2集合中的均为a2, 以此类推直至AN集合,所以其他子集合也可得上述表达式,只不过at不同而已。
因为不同集合中的该部分表达式只有at不同,即π(at|st)不同,而对不同集合中所得的上面该部分再求和,因为∑π(at|st)=1,为常数,因此求和后该部分为0。
也就是说集合A中该部分求和为0,以此类推至所有轨迹中的所有状态中的该部分,皆为0,由此对应了前面的那句话:
当前的动作与过去的回报实际上是没有关系的
其实上面的推导过程有个隐含的假设,那就是s,a返回的奖励r是确定的,而如果状态,动作对返回的奖励reward是一个分布的话上面的推导过程则隐含假设每一个状态,动作对(s,a)获得的reward都是期望值,即R使s,a所得的期望值。
----------------------------------------------------------------------
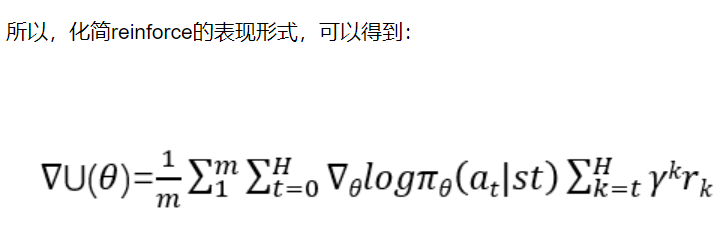
或者为:
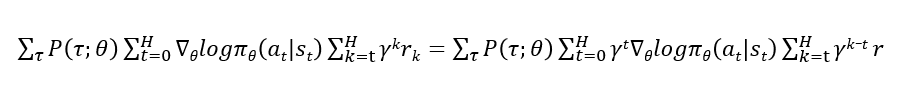
根据上面化简后得到的形式,容易得到Sutton的Reinforcement introduction中的一般形式及算法伪代码,如下:

根据上面简化形式的推导过程,容易理解sutton给出的伪代码中的:
![]()

-------------------------------------------------------------------------------------
在论文 《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》中指出策略梯度定理为reinforce算法的更一般的表现形式,下面给出策略梯度算法中episode形式下的推导:

不论是上面我们对reinforce算法的推导形式,还是策略梯度定理中给出的推导,都是等价的,都可以将episodic情景下计算表达式写为如下:
策略梯度定理中:
![]()
或策略梯度定理中:

或reinforce算法中在一个个episode中序惯采样的形式:

在reinforce算法中,我们是在一个episode中序惯的采样,因此γk是乘在我们的计算项中的。这里的计算项为:
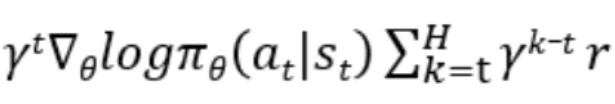
而在策略梯度定理中我们假设采样到的计算项,即
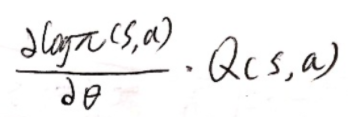
策略梯度定理中计算项的表达式之所以和reinforce算法中的有所不同在于其采样的设定,在reinforce算法中是按照一条条轨迹那样来采样的,在采样的过程中就已经把计算项前面的概率使用采样的方式来表达了,所以需要把折扣率算在计算项中。而在策略梯度定理中,并没有设定为采样,而是直接假设系统中(s,a)的γk折扣概率,我们是计算在所有轨迹中(或是系统中)第k步出现(s,a)的γk折扣概率,因此已经把折扣率算在了概率的过程中。
策略定理中没有设定为采样,但是我们为了便于理解也可以把整个系统想象成一个超大的采样,把所有会出现的轨迹都采样出来了,并且每个轨迹在系统中出现的概率和我们这里采样的频率相等,这时我们想要得到某对(s,a)则直接在这个大的采样中来获得,此时获得某对(s,a)的概率就等于所有轨迹中(或是系统中)第k步出现(s,a)的γk折扣概率,因此这样也可以理解为折扣率算在了采样的过程中。
------------------------------------------------------
posted on 2020-11-05 09:08 Angry_Panda 阅读(3249) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号