batch normalization的multi-GPU版本该怎么实现? 【Tensorflow 分布式PS/Worker模式下异步更新的情况】
最近由于实验室有了个AI计算平台,于是研究了些分布式和单机多GPU的深度学习代码,于是遇到了下面的讨论:
https://www.zhihu.com/question/59321480/answer/198077371
那么batch normalization的multi-GPU版本该怎么实现呢?由于个人只使用过Tensorflow 分布式PS/Worker模式下异步更新的情况,所以也就在这里说说自己对这个情况下如何实现。
batch nrmalization中的mean,variance是不可训练的局部参数,alpha,beta是可训练的全局参数,由于beta,gama是可训练参数所以和网络中的其他参数一样所以这里不特殊考虑,而需要特殊考虑的就是这里的mean,variance这两个不可训练的局部参数。
个人判断:
单机多GPU的网络参数的更新(包括 batch nrmalization中的mean,variance是不可训练的局部参数,beta,gama是可训练的全局参数),就是在使用loss对网络参数进行梯度更新前对batch_norlization中的mean,variance进行更新,代码如下:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(update_ops): #保证train_op在update_ops执行之后再执行。 train_op = optimizer.minimize(loss)
多GPU或分布式环境下的PS/Worker异步更新模式下,batch normalization这个操作会怎么表示呢,个人观点如下:
分布式环境下的PS/Worker异步更新模式下:
batch normalization这个操作:

说的就是在train_op之前对网络中的batch_normalization操作中的全局mean和variance进行动量更新:
global_mean=(1- m)*global_mean+m*batch_mean
global_var=(1- m)*global_var+m*batch_var
而在PS/Worker异步更新模式下, 我们一般这么设置变量的所在设备:

而这也意味着 局部变量的mean,variance也是存在于 PS 端的,那么在 PS/Worker异步更新模式下 我们是没有必要对mean,variance这两个局部变量做什么特殊处理的,因为这两个局部变量和全局变量一样自然会进行异步的更新。
给出一个PS异步更新模式下打印分配设备的图:

从上图可以看到,mean,variance 与 beta,gama 一样都是分配在PS 端的。
所以,PS异步更新模式下 无需对 batch_normalization再做其他的改动便可以实现异步更新了。
单机多GPU情况下:
1. 计算各全局可训练variable的梯度
# Calculate the gradients for the batch of data on this CIFAR tower.
grads = opt.compute_gradients(loss)
2. 计算多个GPU中对variable的的梯度的平均
average_gradients
3. 将得到的各GPU种对variable的梯度的平均更新回variable中
# Apply the gradients to adjust the shared variables.
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
以上1,2,3步骤是对可训练的variable的操作,这里我们如果有batch_normalization操作时对于不可训练的batch_normalization中的mean,var局部变量也需要更新。
第一种做法: 如果将操作
tf.GraphKeys.UPDATE_OPS
不加入到计算图的依赖中的话,我们可以这么做:
需要手动改动的地方则在1中,需要将各GPU中的batch_mean,batch_var如可训variable那样进行收集;
在2步骤中,需要单独将不可训练的各GPU中的batch_mean,batch_var如可训variable那样进行手动取均值(其实,这里我们是不是可以获得所有gpu上batch数据的均值,然后再获得所有GPU上数据的方差呢);
在3步骤中,手动将计算的平均后的batch_mean,batch_var更新到global_mean,global_var中。
该种做法对 mean,var两个不可训练参数同其他可训练参数一样进行了同步更新。
第二种做法: 如果将操作
tf.GraphKeys.UPDATE_OPS
加入到计算图的依赖中的话,我们可以这么做:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops): #保证train_op在update_ops执行之后再执行。
train_op = opt.compute_gradients(loss)
这样的话不需要对batch_normalization中的mean,var进行额外操作,该种做法对 mean,var两个不可训练参数进行异步更新,而对同其他可训练参数进行同步更新。
第二种方法比第一种要方便简单些,同时对全局mean,var的更新不会有太大的影响。
---------------------------------
对于 PS模式下同步更新的情况:
个人观点该情况下和单机多GPU中的第二种方法相同,就是将
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
加入到图的依赖中。
因为在PS下的同步更新中只对可训练的variable进行梯度平均后更新,因此此种情况下和单机多GPU中的第二种方法相同对全局mean,var进行异步更新也是OK的,而且不太会有太大性能上的影响。
--------------------------------------------------------------------------------
其实对于多GPU, 或者分布式的环境下讨论batch_normalization中的全局mean和var如果更新获得(异步方式,同步方式)意义并不大,个人感觉这问题甚至有些伪命题的感觉。(只为个人观点)
batch_normalizaiton中的batch的mean,var是指通过batch中的少量数据估计某层输出tensor的均值,方差,并用其动量的更新全局mean,var。如果一个GPU运行100steps,就是更新100次全局mean,var; 如果4个GPU就是每个进行25steps, 每个step是把各gpu上batch内的数据求均值,方差,然后再求4个GPU的平均的 均值,方差,然后再更新全局均值,方差 (也或许将4个GPU上的batch数据全部拼在一起求均值,方差);这两种方法本身都是种估计,两者之间会有很大差距吗,个人很是怀疑。
由于水平问题,不能实现上面说的各种方法以探讨不同方式对全局mean,var的影响,但是给出下面模拟一个分布的数据集,已知其全局均值,方差,通过单个batch数据更新全局mean,var或使用几个batch的数据各自的mean,var 的均值更新,或是使用几个batch的数据拼在一起的mean,var 来进行更新,试着模拟一下网络训练中的过程,看看这几种方法的最终结果的差距:
第一种,逐个batch的更新全局mean,var
import numpy as np m = 3.9 v = 12.4 alpha=0.1 false_mean = 0 false_var = 0 for i in range(10000): sub_data_0 = np.random.normal(m, v, 100) _false_mean = np.mean(sub_data_0) _false_var = np.var(sub_data_0)**0.5 false_mean = (1-alpha)*false_mean + alpha*_false_mean false_var = (1-alpha)*false_var + alpha*_false_var print("time", i) print("true mean", m) print("true var", v) print("false mean", false_mean) print("false var", false_var)
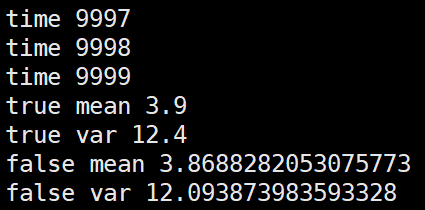
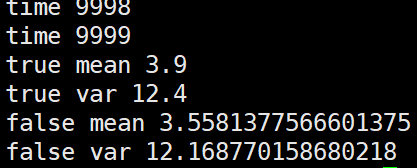

第二种,根据几个batch的mean,var求均值后再更新全局mean,var
import numpy as np m = 3.9 v = 12.4 alpha=0.1 false_mean = 0 false_var = 0 for i in range(10000//4): sub_data_0 = np.random.normal(m, v, 100) _false_mean_0 = np.mean(sub_data_0) _false_var_0 = np.var(sub_data_0)**0.5 sub_data_1 = np.random.normal(m, v, 100) _false_mean_1 = np.mean(sub_data_0) _false_var_1 = np.var(sub_data_0)**0.5 sub_data_2 = np.random.normal(m, v, 100) _false_mean_2 = np.mean(sub_data_0) _false_var_2 = np.var(sub_data_0)**0.5 sub_data_3 = np.random.normal(m, v, 100) _false_mean_3 = np.mean(sub_data_0) _false_var_3 = np.var(sub_data_0)**0.5 _false_mean = np.mean([_false_mean_0,_false_mean_1,_false_mean_2,_false_mean_3]) _false_var = np.mean([_false_var_0,_false_var_1,_false_var_2,_false_var_3]) false_mean = (1-alpha)*false_mean + alpha*_false_mean false_var = (1-alpha)*false_var + alpha*_false_var print("time", i) print("true mean", m) print("true var", v) print("false mean", false_mean) print("false var", false_var)
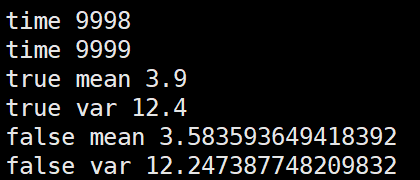
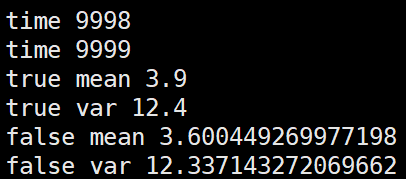
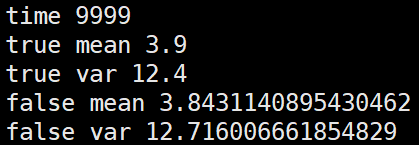
第三种,将几个batch的数据拼在一起求mean,var后再更新全局mean,var
import numpy as np m = 3.9 v = 12.4 alpha=0.1 false_mean = 0 false_var = 0 for i in range(10000//4): sub_data_0 = np.random.normal(m, v, 100) sub_data_1 = np.random.normal(m, v, 100) sub_data_2 = np.random.normal(m, v, 100) sub_data_3 = np.random.normal(m, v, 100) _false_mean = np.mean([sub_data_0, sub_data_1, sub_data_2, sub_data_3]) _false_var = np.var([sub_data_0, sub_data_1, sub_data_2, sub_data_3])**0.5 false_mean = (1-alpha)*false_mean + alpha*_false_mean false_var = (1-alpha)*false_var + alpha*_false_var print("time", i) print("true mean", m) print("true var", v) print("false mean", false_mean) print("false var", false_var)
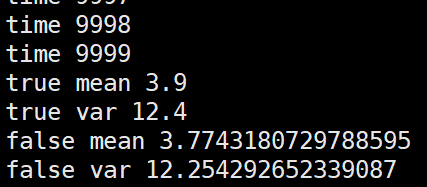
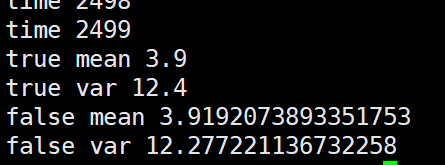
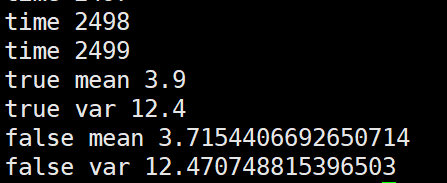
个人观点就是这几种更新方法没有太大的,太明显的性能差距。
----------------------
posted on 2020-10-12 11:55 Angry_Panda 阅读(683) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号