爬格子问题(经典强化学习问题) Sarsa 与 Q-Learning 的区别
SARSA v.s. Q-learning
爬格子问题,是典型的经典强化学习问题。
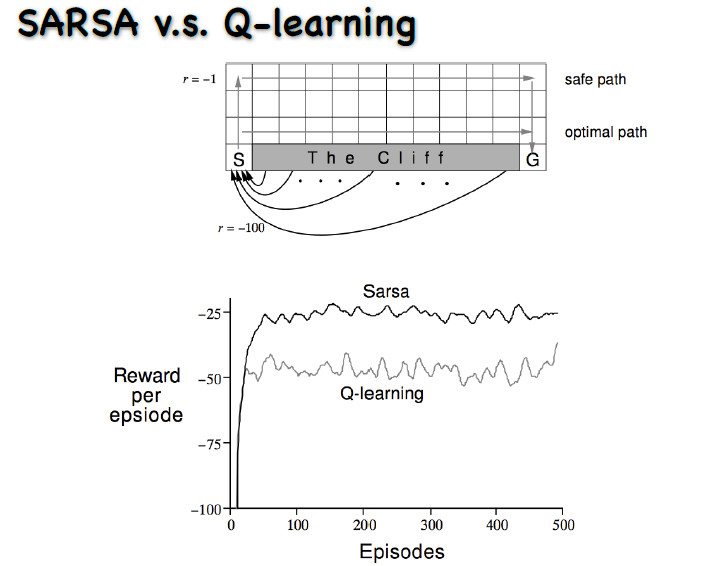
动作是上下左右的走,每走一步就会有一个-1的奖赏。从初始状态走到最终的状态,要走最短的路才能使奖赏最大。图中有一个悬崖,一旦走到悬崖奖赏会极小,而且还要再退回这个初始状态。

如上图所示,起始点为S, 终点为G , 没走一步奖励为-1, 进入悬崖中奖励为-100并且跳转回起始点,本问题的最终目的是求解出最优路径。
--------------------------------------------------------------------------
这里采用 Sarsa 和 Q-learning 强化学习中两种经典的TD值迭代法求解,先说下结论:
Q-learning 和 Sarsa 最终学到的策略都是随机策略(不是确定性的策略),但是我们可以把随机策略转化为确定性策略,一般我们可以直接将随机策略中状态S下动作值q(s,a)最大的动作作为确定性策略中的选择动作,从而得到确定性策略。
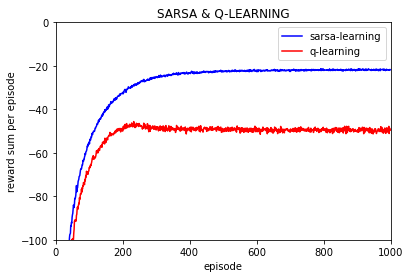
最终转化后的确定性策略中Sarsa算法更偏向选择安全的路径从而远离悬崖,而Q-learning得到的确定性策略所得到的路径更偏向紧沿着悬崖,因此q-learning算法所走路径长度短于Sarsa (确定性策略下),但是在实际的测试效果(此时都是使用未转化为确定性策略前的随机策略)可以看到Sarsa方法可以取得比Q-Learing更好的效果,这听起来很矛盾,就像上面第二个图中对两种算法每回合的回报值的对比图就可以看出 Sarsa算法强于Q-learning (Sarsa算法每回合的回报值高于Q-learning,也就是说Sarsa算法走的路径要短于Q-learning)。
------------------------------------------------------------------------------------------
实验中参数设置:
总实验次数 1 次
学习率 0.1
每次实验回合数500
折扣因子 0.95
探索率 epsilon 为 0.1
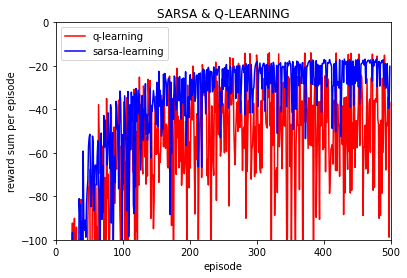
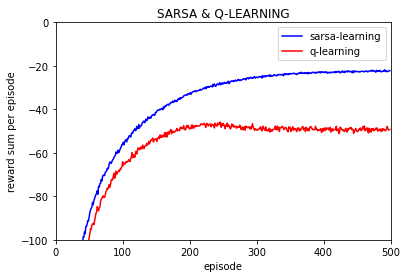
可以看到只做一次实验的话q-learning和Sarsa-learing 的波动很大,不同episode的回报值(这里不考虑折扣率,但是在学习过程中考虑折扣率),
但是仍然可以看到q-learning每episode的回报值要低于Sarsa 的。由于一次实验每回合的回报值波动过大,下面的实验都是进行10000次取平均。
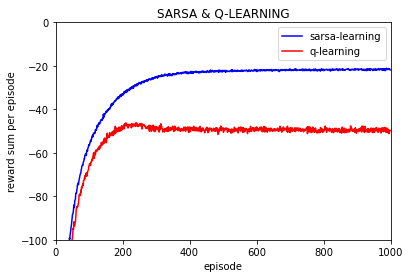
为了更近一步,做100次实验,结果:
总实验次数 100 次
学习率 0.1
每次实验回合数500
折扣因子 0.95
探索率 epsilon 为 0.1
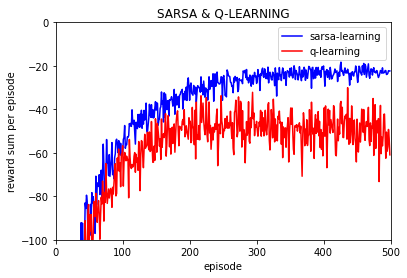
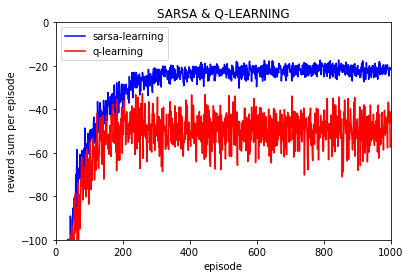
首先要解释一点,上图中的每回合回报值是平均值,也就是说那个 reward per episode 是多次实验的平均值,如进行10000次重复实验,每次实验都进行500个episode的训练。
其次要解释的是,Q-learning可以学习到比Sarsa更好的确定性策略,但是如果直接使用学习到的随机策略的话 Q-learning实际寻找的路径要差于Sarsa, 这是因为Q-learning和Sarsa的动作选择策略或者说最终学习到的随机策略是epsilon-greedy策略而不是确定性的greedy策略,因此最终策略是以概率形式随机选择一个动作而不是根据确定值选择固定动作,这样每次选择动作的时候也带着试探,因此Sarsa的最终随机策略因为要更加绕远却更加安全不容易掉入到悬崖中,而Q-learning学习到的随机策略是更偏向于紧贴悬崖的,而最终策略由于是随机策略,也就是说会一直保持一定的探索的,所以Q-learning更容易掉入到悬崖中从而有差于Sarsa算法的表现。
------------------------------------------------------------------------------
注:
终止点的q值是不参与训练的,而且默认为0,也就是说终止点为S' , 前一状态为S 的话,
q-learning: q(s, a)=q(s, a) + step_size*( r + γ . max{a} q(s' , a' ) - q(s, a) )
sarsa: q(s, a)=q(s, a) + step_size*( r + γ . epsilon-greedy q(s' , a' ) - q(s, a) )
可以看成:
q-learning: q(s, a)=q(s, a) + step_size*( r - q(s, a) )
sarsa: q(s, a)=q(s, a) + step_size*( r - q(s, a) )
因为状态s选择动作a后进入终点,因此也可以把 q(s, a) 直接看为 获得的即时奖励 r, 即 -1 。
----------------------------------------------------------------
总实验次数 10000 次
学习率 0.1
每次实验回合数 500
折扣因子 0.95
探索率 epsilon 为 0.1
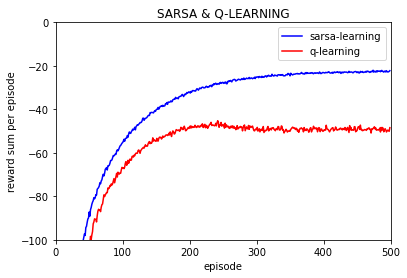
q-learning 学习:


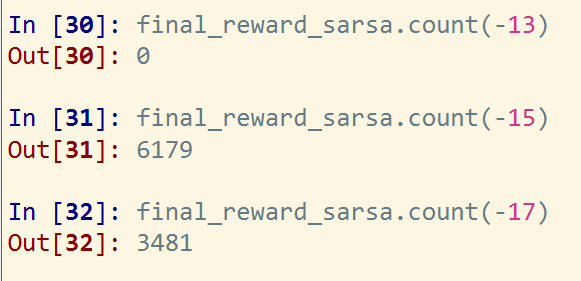
10000次实验q-learning,每次实验500回合,将最终学习到的epsilon-greedy策略转为greedy策略,10000次实验中全部实验的最终奖励为-13(这里不考虑折扣率),也就是说10000次实验每个实验500回合训练后转换的greedy策略都是紧沿着悬崖走的。
Sarsa 学习:



10000次实验sara学习,每次实验500回合,将最终学习到的epsilon-greedy策略转为greedy策略,10000次实验中8622次实验可以找到终点大部分其中大部分的奖励为-15,还有一部分为-17,并且均值为-15.45, 也就是说10000次实验每个实验500回合训练后转换的greedy策略都是要绕开悬崖一些走的。
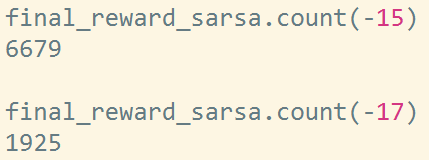

可以看到sara的10000次实验中奖励为-15的实验6679个,奖励-17的实验为1925个。
同时还需要注意,有1378个实验不能找到终点(代码中设置的,如果进入死循环那么自动结束寻找终点,这里设置走10000步没有找到终点判断为进入死循环)
还有一个有意思的地方是:

说明没有找到终点的1378次sara实验获得的奖励均为-10000,也就是这10000步的寻找路径过程中并没有进入悬崖,而是在普通的节点之间循环的跳转。
--------------------------------------
同样实验环境再重新做10000次实验:
q-learning:

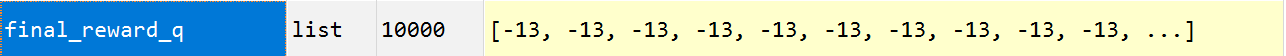
10000次实验,转换后的确定性策略全部以最短路径到终点,奖励值均为 -13 。
sarsa:

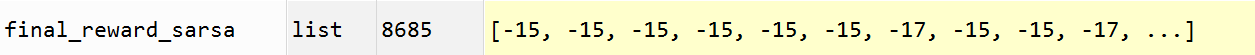



sarsa实验10000次 8685次找到终点,其中奖励回报-15的有6809,回报-17的有1855 。

sarsa实验10000次 1315 次没有找到终点,其中奖励回报均为 -10000, 即在普通点上进入死循环的寻路过程,未有一次实验进入到悬崖中的 。
----------------------------
同样实验环境第三次重新做10000次实验:
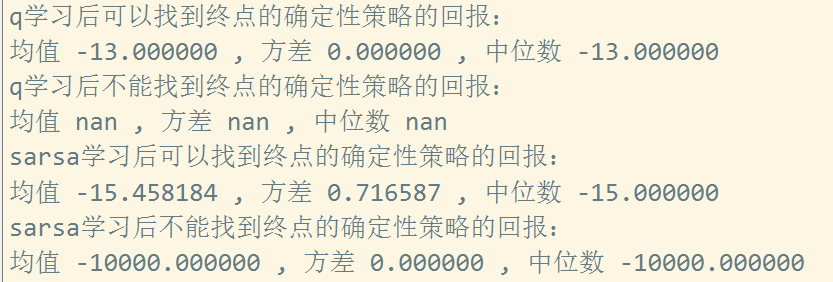




可以看到,上面同样的实验环境做三组10000次实验发现,q_learning训练后的确定性策略10000次实验全部找到最优路径(回报值-13),sarsa训练后的确定性策略大部分可以找到终点,其中基本都是次优解(奖励都是-15, -17, -19),说明q-learning 学习到的确定性策略是沿着悬崖的,sarsa学习到的确定性策略是偏离悬崖的。
--------------------------------
同样实验环境做第第四组实验:
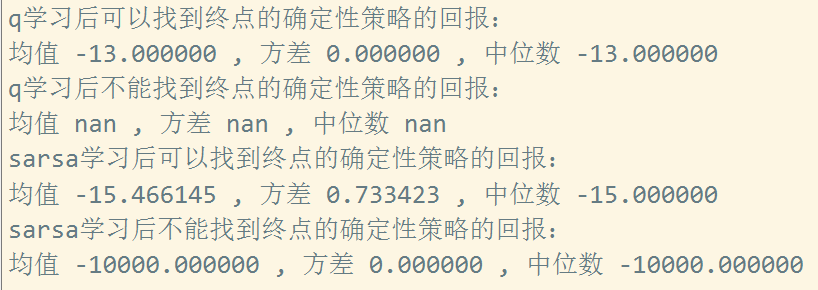


发现这回 sarsa最终获得的确定性策略回报值除了 -15, -17, -19 以外还有了 -21 。
如下:


分别打印出几类路径的具体历史状态的访问记录(每个类别举出几个例子):
-15:

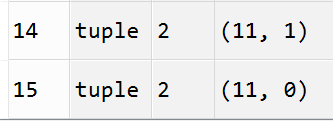
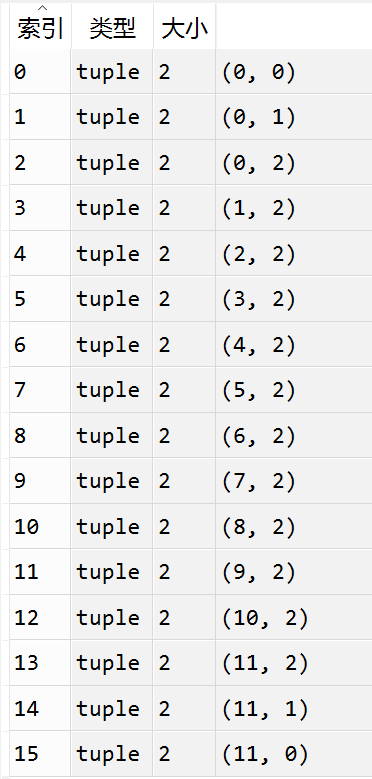
-17:




-19:






-21:



----------------------------------------------------------------
总实验次数 10000 次
学习率 0.1
每次实验回合数 1000
折扣因子 0.95
探索率 epsilon 为 0.1
q-learning 学习:


Sarsa 学习到的状态值:





----------------------------------------------------------------
总实验次数 10000 次
学习率 0.1
每次实验回合数 500
折扣因子 1.0
探索率 epsilon 为 0.1
q-learning 学习到的状态值:



q_learning学习,10000次实验得到的确定性策略都能走到终点并得到最短路径,回报均为 -13 。
Sarsa 学习到的状态值:



sarsa学习 10000次实验得到的确定性策略有1058次没有走到终点,进入普通点之间跳转的死循环,回报均为 -10000。走到最终点的实验中:

可以看到Sarsa 走到最终点的实验中回报值有 -15, -17, -19 三种, 其中以 -15 回报奖励为主。
----------------------------------------------------------------
总实验次数 10000 次
学习率 0.1
每次实验回合数 1000
折扣因子 1.0
探索率 epsilon 为 0.1
q-learning 学习到的状态值:



Sarsa 学习到的状态值:




---------------------------------------
针对以上内容说下个人观点:
Q-learning在训练学习时对评估动作采用greedy策略,在对评估东西进行评估时(对原状态s动作a后跳转到的状态s' 根据greedy策略选择要评估的 q(s' , a' ) ), 即使下一状态S' 有可能因为某动作进入到一个十分糟糕的环境也步过多考虑,只要S' 状态有某个动作可以跳转到更好的状态即可, 因此Q-learning 更偏向于确定性策略下的最优策略,而忽略该策略可能潜在的风险,比如与极差的策略相近,只要与较好策略相近即可。
Sarsa在训练学习时对评估动作采用epsilon-greedy策略(更多的考虑不同动作后跳转到不同状态所造成的影响),所以探索性较强,相比于Q-learning更多的考虑悬崖状态的影响,因此更偏向于远离悬崖。
因此,以epsilon-greedy策略执行的时候 Q-learning即使更偏向于走最优的路径但是由于与极差的策略(或路径)相近仍然会以一定概率进入到极差路径中,因此平均下来Q-learning的表现不如Sarsa, 而Sarsa更多的考虑下一状态可能进入的各种环境(造成极好路径和极坏路径的状态),因此更偏向于绕远但是更安全的路径,由于进入到极差路径的可能性也随之降低因此平均起来要比Q-learning表现好。但是,将训练获得的epsilon-greedy策略转换为greedy策略,算法在执行时不进行探索,这时Q-learning选择走最优路径,即使这样也更靠近极坏的路径中,但是因为不进行探索所以最终不会进入极差的路径中,因此表现好于Sarsa, 而Sarsa由于更偏向于绕远但是更安全的路径,这时由于Q-learning不会进入极差路径中(进入悬崖状态),因此表现不如Q-learning 。
以上是个人理解,是否正确不敢保证。
=========================================================
如果这个问题中没有悬崖的话,那么运行结果如何呢?
环境为无悬崖的情况:
参数:
总实验次数 10000 次
学习率 0.1
每次实验回合数 500
折扣因子 0.95
探索率 epsilon 为 0.1
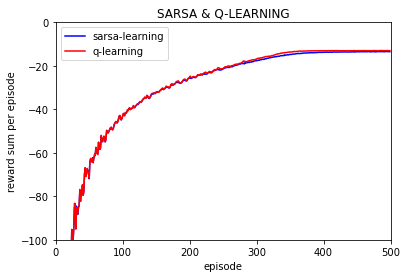
这时候发现如果没有悬崖的话 q-learning 和 sarsa 在训练期间运行的效果大致相同,基本上是重合的两个曲线。
不过这时候将500episode训练好的epsilon-greedy策略转换为greedy策略后:

q-learning 10000次实验全部以最短路径走到终点。
sarsa:




可以看到sarsa算法 10000次实验后9453次实验可以找到最终点,其中奖励值为 -19, -17, -15, -13, -11 五种类型, 其中以最短路径 回报值 -11 为主。

sarsa算法10000次实验中547次实验无法找到终点,而且全部进入各状态跳转的死循环。
--------------------------------------------------------------------------------
环境为无悬崖的情况:
参数:
总实验次数 10000 次
学习率 0.1
每次实验回合数 1000
折扣因子 0.95
探索率 epsilon 为 0.1
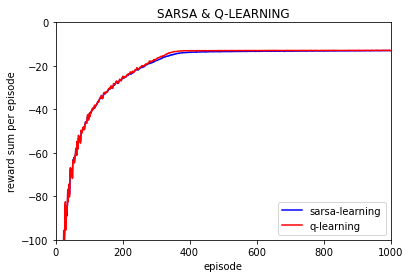
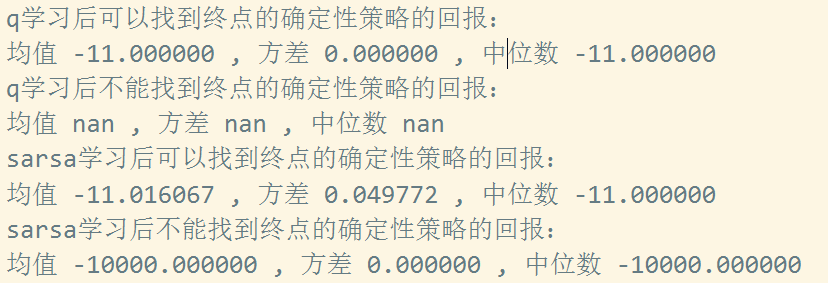

sarsa 算法有9834次实验greedy策略走到终点,分布:
------------------------------
环境为无悬崖的情况:
参数:
再次做一组相同设置:
总实验次数 10000 次
学习率 0.1
每次实验回合数 1000
折扣因子 0.95
探索率 epsilon 为 0.1
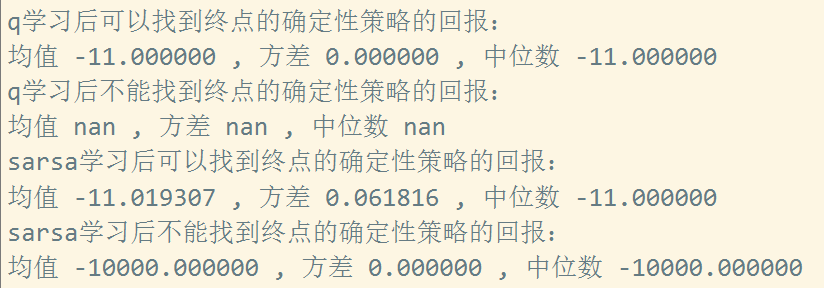
可以看到大致运行的效果是差不多的, 不过这次加入了每episode回合下动作值q的变化,并取10000次实验的平均值:
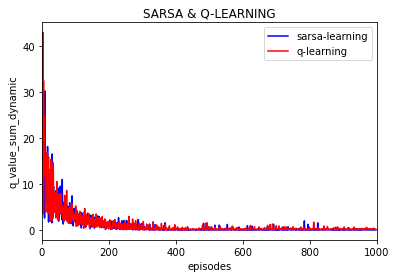
可以看到每一个动作q值随之episode的增加逐渐趋于稳定,逼近0 。(这里的每episode的q的变化是取了10000次实验的平均值)
----------------------------------------
同样的设置,这时实验分别设置为10次,100次, 1000次,并对结果取平均,如下:
10次:
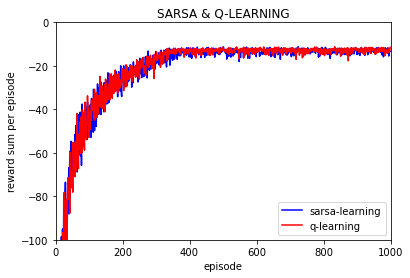
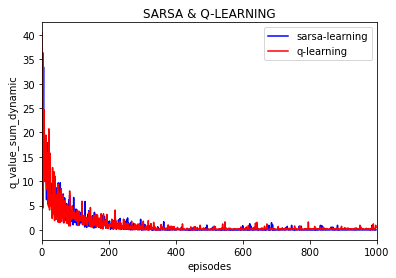
100次:
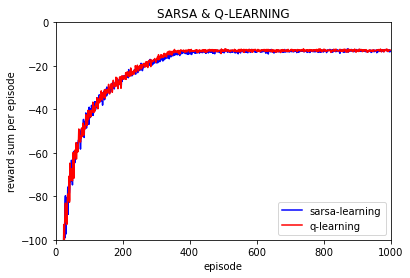
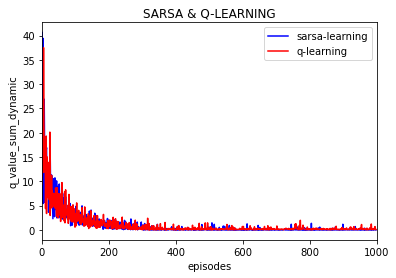
1000次:
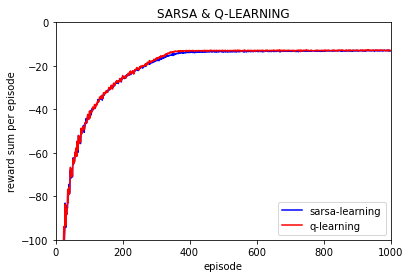
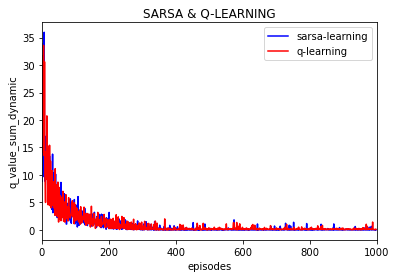
------------------------------
环境为有悬崖的情况:
参数:
学习率 0.1
每次实验回合数 1000
折扣因子 0.95
探索率 epsilon 为 0.1
实验1次:
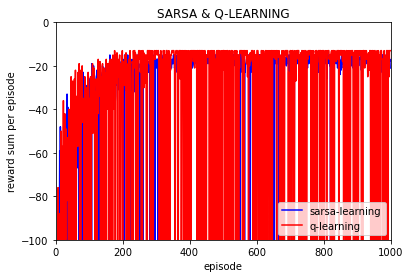
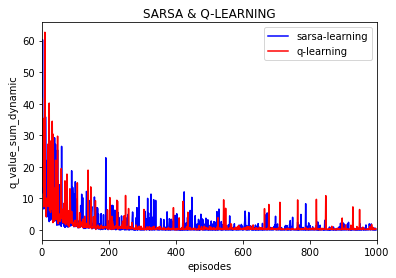
实验10次:
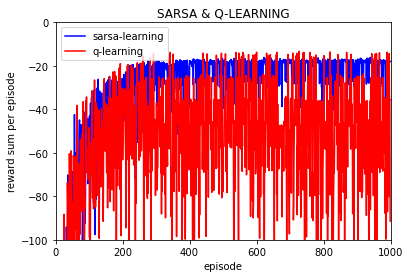
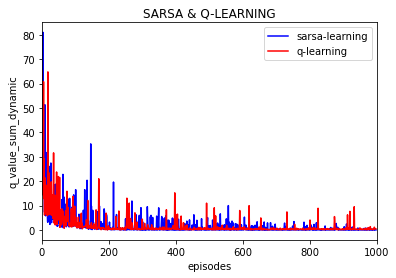
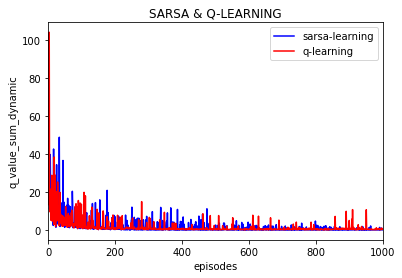
实验100次:
实验1000次:
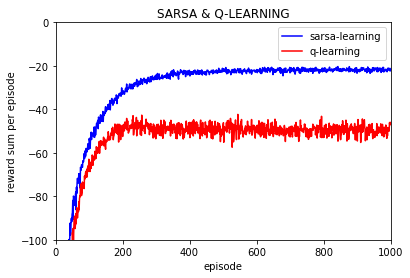
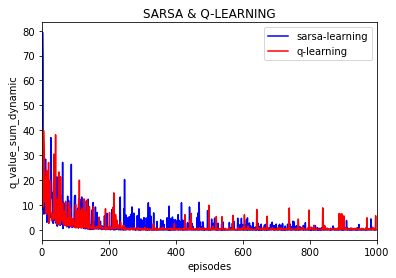
实验10000次:
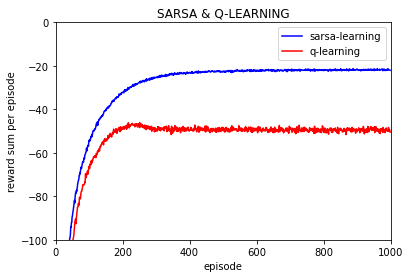
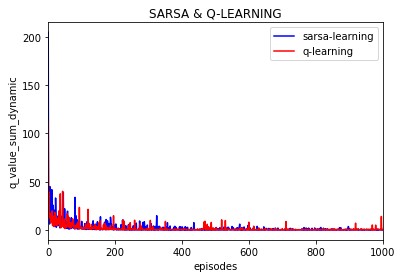
可以看到Q值的大学随着训练逐渐保持不变,基本上可以当做是收敛的,也就是说策略是收敛的。
(上图是不同episode时后一episode下所有Q值与前一episode下所有对应的Q值差的绝对值的和)
--------------------------------------------------
============================================================
更正一下,由于代码编写错误,以上的10000次实验每个episode之间q值的差值变化并不是10000次的平均,而是一次的,下面给出更正的10000次实验下episode之间q值变化的曲线(所有q值变化的绝对值之和):
环境为有悬崖的情况:
参数:
学习率 0.1
每次实验回合数 1000
折扣因子 0.95
探索率 epsilon 为 0.1
总实验次数为10000
不同episode之间q值的变化(不同episode下所有q的绝对值之和然后求前后episode的差值):
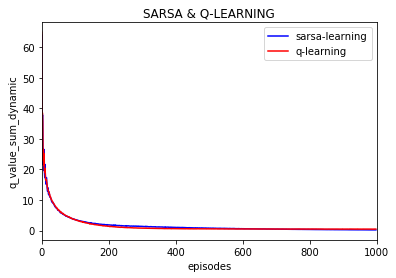
同时给出,所有q的绝对值之和的变化:(episode之间不求差)
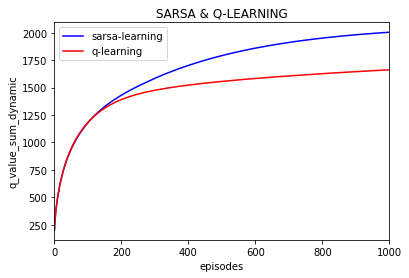
可以看到q的绝对值的和还是在缓慢变化的。
所以又做了下面实验:
环境为有悬崖的情况:
参数:
学习率 0.1
每次实验回合数 5000
折扣因子 0.95
探索率 epsilon 为 0.1
总实验次数为1000
所有q的绝对值之和的变化:(episode之间不求差)
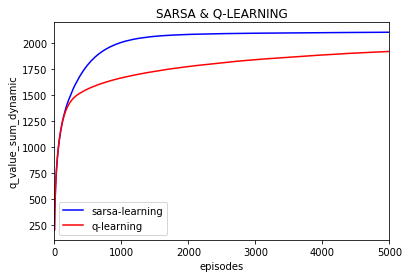
每一episode的奖励平均值:
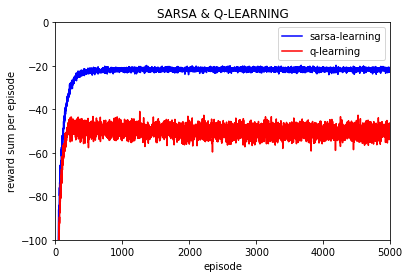
-------------------------------------
环境为有悬崖的情况:
参数:
学习率 0.1
每次实验回合数 10000
折扣因子 0.95
探索率 epsilon 为 0.1
总实验次数为1000
所有q的绝对值之和的变化:(episode之间不求差)
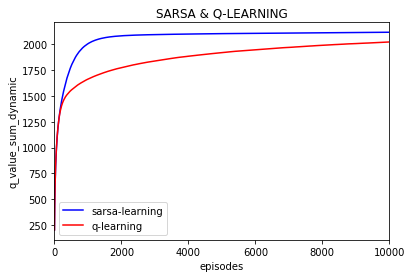
每一episode的奖励平均值:
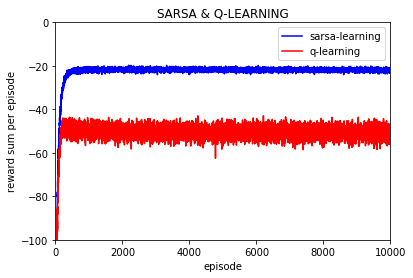
-------------------------------------
环境为有悬崖的情况:
参数:
学习率 0.1
每次实验回合数 50000
折扣因子 0.95
探索率 epsilon 为 0.1
总实验次数为100
所有q的绝对值之和的变化:(episode之间不求差)
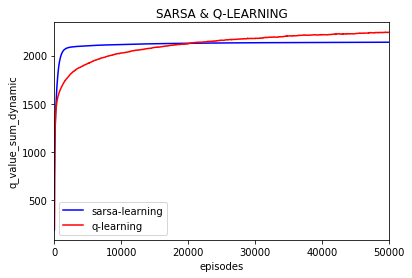
每一episode的奖励平均值:
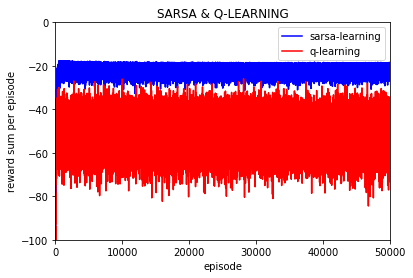
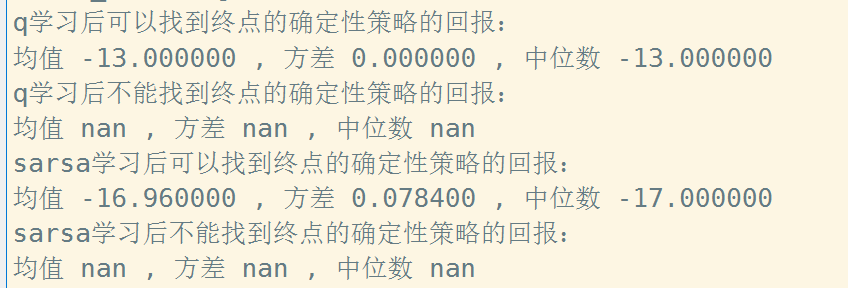
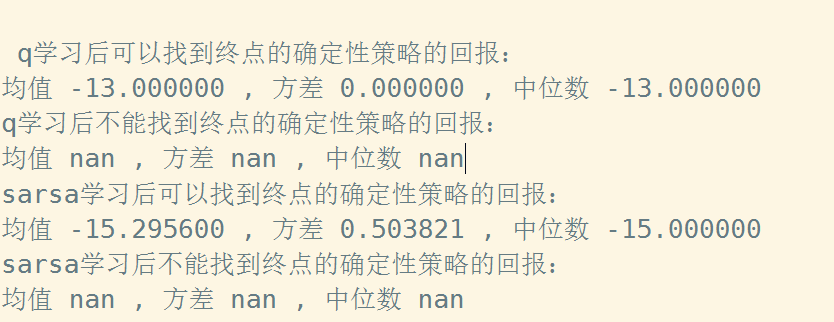
可以看到使用表格法的话只要训练时间足够长最终转化为的确定性策略都是可以走到最终点的。
=============================================================
环境为有悬崖的情况:
参数:
学习率 0.1
每次实验回合数 1000
折扣因子 0.95
探索率 epsilon 为 前500个episode固定为0.1,从500到1000episode组建降低为0
总实验次数为10000
所有q的绝对值之和的变化:(episode之间不求差)
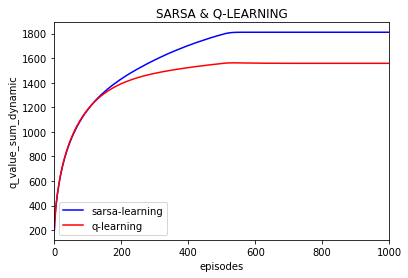
每一episode的奖励平均值:
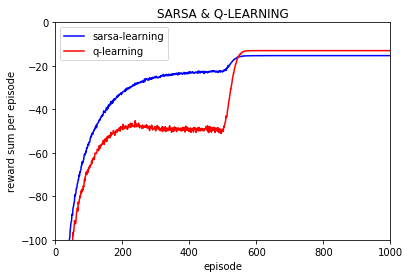
==========================
-----------------------------------------------------------
可以看到500episode之后随着探索率的下降 每episode所得到的回报逐渐保持不变,并且q-learning获得的回报迅速超过sarsa,因为此时q-learning降低了探索,减少了进入悬崖的可能并紧沿着悬崖的路径走,同时也可以看到q-learning和sarsa算法在500episode之后所学习到的q值逐渐保持不变,加快了算法的收敛(如果不降低探索率的话q-learning在50000episode之后仍在有小幅度的变化)
个人感觉: q-learning 对策略的探索力度更大,所以也容易使策略更不稳定,但同时对最优策略探索力度也更大。从本文的实验结果上看,感觉q-learning 的收敛性不如sarsa,因为在各个episode上q-learning获得的回报变动更大,而sarsa获得的回报值变动很小,但是随着训练的episode的增加逐渐减少探索率epsilon那么q-learning和sarsa都可以得到很好的收敛,当然评价q-learning和sarsa收敛快慢不能用这一个简单实验来下结论,有悬崖的情况下q-learning的学习过程更不稳定收敛可能稍差些但是在无悬崖的时候sarsa和q-learning的效果相当,而且在强化学习中收敛速度不应该太看重而是更应该关注能否收敛的问题。
-------------------------------------------------
本文代码:
https://gitee.com/devilmaycry812839668/cliff_walking
posted on 2019-01-24 09:25 Angry_Panda 阅读(4206) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号