如何识别图像边缘? (转载)
日期: 2016年7月22日
图像识别(image recognition)是现在的热门技术。
文字识别、车牌识别、人脸识别都是它的应用。但是,这些都算初级应用,现在的技术已经发展到了这样一种地步:计算机可以识别出,这是一张狗的照片,那是一张猫的照片。

这是怎么做到的?
让我们从人眼说起,学者发现,人的视觉细胞对物体的边缘特别敏感。也就是说,我们先看到物体的轮廓,然后才判断这到底是什么东西。
计算机科学家受到启发,第一步也是先识别图像的边缘。
加州大学的学生 Adit Deshpande 写了一篇文章《A Beginner's Guide To Understanding Convolutional Neural Networks》,介绍了一种最简单的算法,非常具有启发性,体现了图像识别的基本思路。

首先,我们要明白,人看到的是图像,计算机看到的是一个数字矩阵。所谓"图像识别",就是从一大堆数字中找出规律。
怎样将图像转为数字呢?一般来说,为了过滤掉干扰信息,可以把图像缩小(比如缩小到 49 x 49 像素),并且把每个像素点的色彩信息转为灰度值,这样就得到了一个 49 x 49 的矩阵。
然后,从左上角开始,依次取出一个小区块,进行计算。
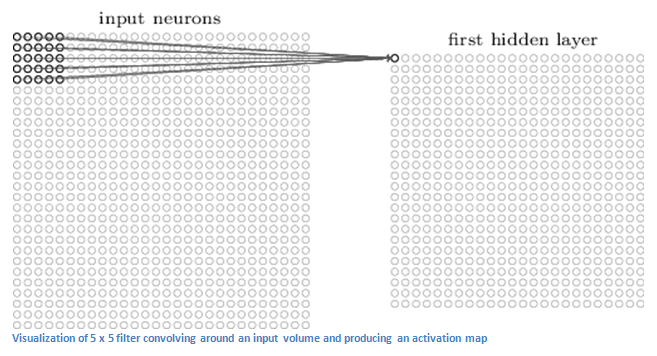
上图是取出一个 5 x 5 的区块。下面的计算以 7 x 7 的区块为例。
接着,需要有一些现成的边缘模式,比如垂直、直角、圆、锐角等等。
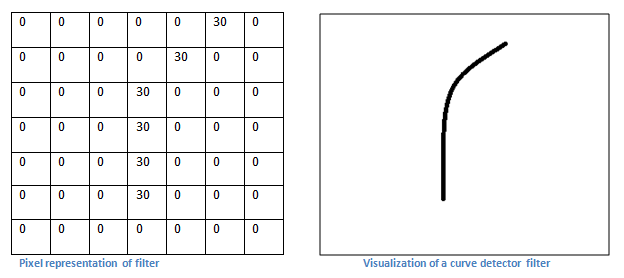
上图右边是一个圆角模式,左边是它对应的 7 x 7 灰度矩阵。可以看到,圆角所在的边缘灰度值比较高,其他地方都是0。
现在,就可以进行边缘识别了。下面是一张卡通老鼠的图片。
取出左上角的区块。
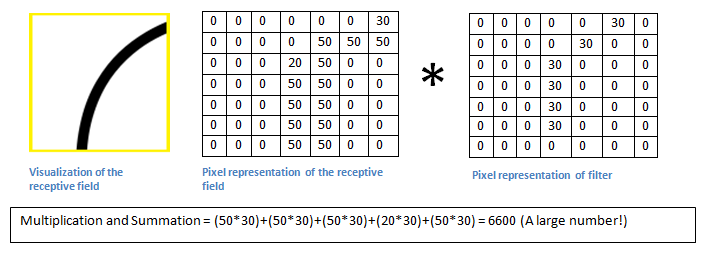
取样矩阵与模式矩阵对应位置的值相乘,进行累加,得到6600。这个值相当大,它说明什么呢?

取样矩阵移到老鼠头部,与模式矩阵相乘,得到的值是0。
乘积越大就说明越匹配,可以断定区块里的图像形状是圆角。通常会预置几十种模式,每个区块计算出最匹配的模式,然后再对整张图进行判断。
(完)
文档信息
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
- 发表日期: 2016年7月22日
- 更多内容: 档案 » 算法与数学
- 文集:《前方的路》,《未来世界的幸存者》
- 社交媒体:
 twitter,
twitter, weibo
weibo
posted on 2018-12-16 00:06 Angry_Panda 阅读(349) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号