

selenium之POM模式的实现
POM是Page Object Model的缩写,中文意思是页面对象模型,POM是通过分离测试对象和测试脚本来实现的。
POM主要有以下优点:
1. 把web ui对象从测试脚本分离,代码和测试脚本分离。
2. 每一个页面对应一个页面类,页面的元素写到这个页面类中。
3. 页面类主要包括该页面的元素定位,和这些元素相关的操作代码封装的方法。
4. 代码复用,从而减少测试脚本代码量。
5. 层次清晰,同时支持多个编写自动化脚本开发。
6. 页面类和逻辑方法都起一个有意义的名称,方便他人快速编写脚本和维护脚本。
通过一个例子来看下POM的实现:
下面以登录QQ邮箱为例的线性脚本:
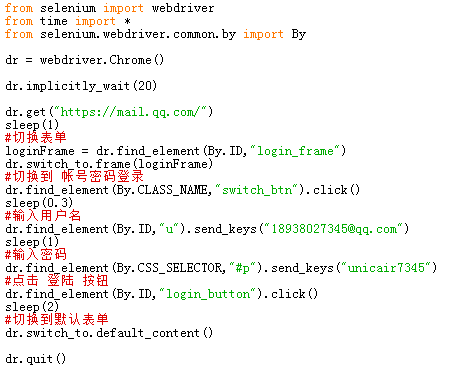
这个用例只操作5个元素,就暴露出来了一些代码冗余和可读性的问题。如果有更多功能,那么用例代码更加厚重,可读性也是大大降低,我们需要对此代码进行优化,通过POM来实现。
首先,我们要分离测试对象和测试脚本,我们分别创建四个脚本文件,basePage.py用于初始化页面属性,打开浏览器,定义查找元素的方式,homePage.py用于定义被测网址首页未登录前的操作,定义登录按钮和表单的定位方式,loginPage.py 用于定义页面元素对象,每一个元素都封装成函数,login_test.py 测试用例脚本。元素的操作方法定义在Page页面,用例脚本通过调用Page中的函数来实现邮箱的登录。把上述4个脚本放在同级目录的不同的文件夹下,如下:
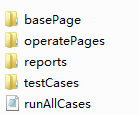
basePage.py的代码如下:

homePage.py的代码如下:

loginPage.py的代码如下:
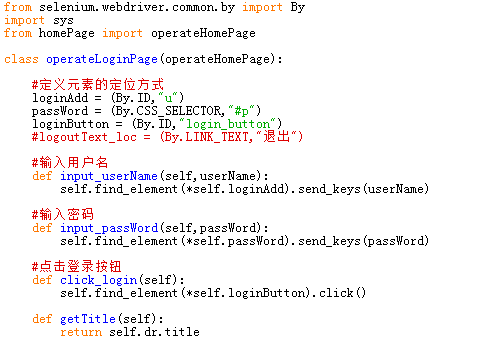
login_test.py测试用例代码如下:

通过使用POM进行重新构造代码结构后,测试用例代码的可读性提高很多,元素写成函数的方式,不需要每次都写find_element,直接在脚本中调用函数就可以使用。这种方式方便对脚本进行后期的维护管理,当元素属性发生变化时,我们只需要对一个页面中的函数定义进行更改即可。
