pikachu(渗透测试)靶场通关笔记(持续更新)
pikachu渗透测试靶场
靶场的搭建:
打开浏览器搜索pikachu的搭建或者找搭建好的,网上有很多佬都写过,我就不写了
暴力破解:
概述:
Burte Force(暴力破解)概述
暴力破解是一攻击具手段,在web攻击中,一般会使用这种手段对应用系统的认证信息进行获取,其过程就是使用大量的认证信息在认证接口进行尝试登录,直到得到正确的结果 为了提高效率,暴力破解一般会使用带有字典的工具来进行自动化操作
理论上来说,大多数系统都是可以被暴力破解的,只要攻击者有足够强大的计算能力和时间,所以断定一个系统是否存在暴力破解漏洞,其条件也不是绝对的,我们说一个web应用系统存在暴力破解漏洞,一般是指该web应用系统没有采用或者采用了比较弱的认证安全策略,导致其被暴力破解的“可能性”变的比较高
这里的认证安全策略, 包括:
1.是否要求用户设置复杂的密码;
2.是否每次认证都使用安全的验证码(想想你买火车票时输的验证码~)或者手机otp;
3.是否对尝试登录的行为进行判断和限制(如:连续5次错误登录,进行账号锁定或IP地址锁定等);
4.是否采用了双因素认证; ...等等
千万不要小看暴力破解漏洞,往往这种简单粗暴的攻击方式带来的效果是超出预期的!
从来没有哪个时代的黑客像今天一样热衷于猜解密码 ---奥斯特洛夫斯基
基于表单的暴力破解:
这里是一个登录界面,我们随意输入一个账号和密码上去,让后用bp进行抓包,如下图:
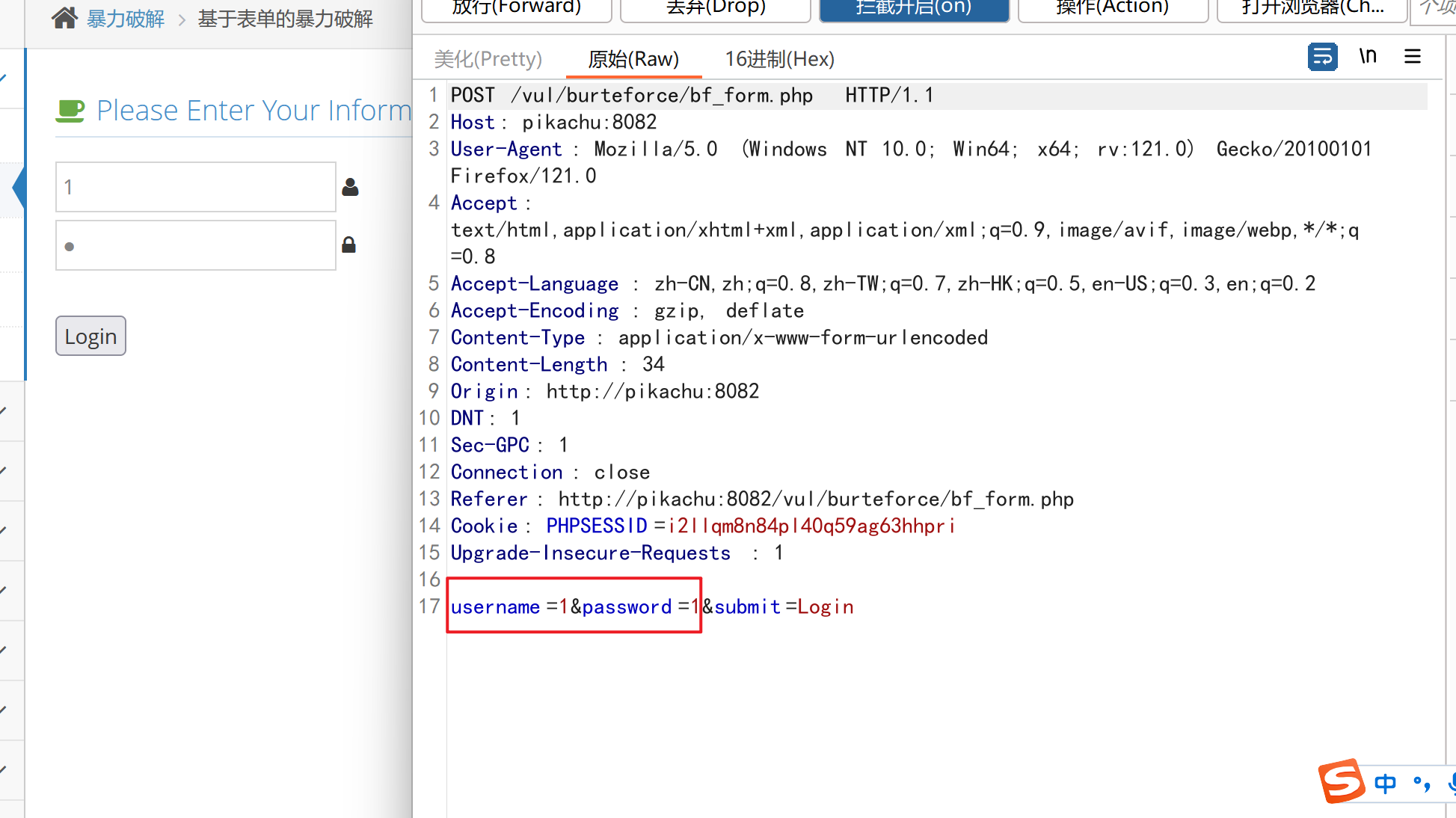
然后右键,点击发送到Intruder

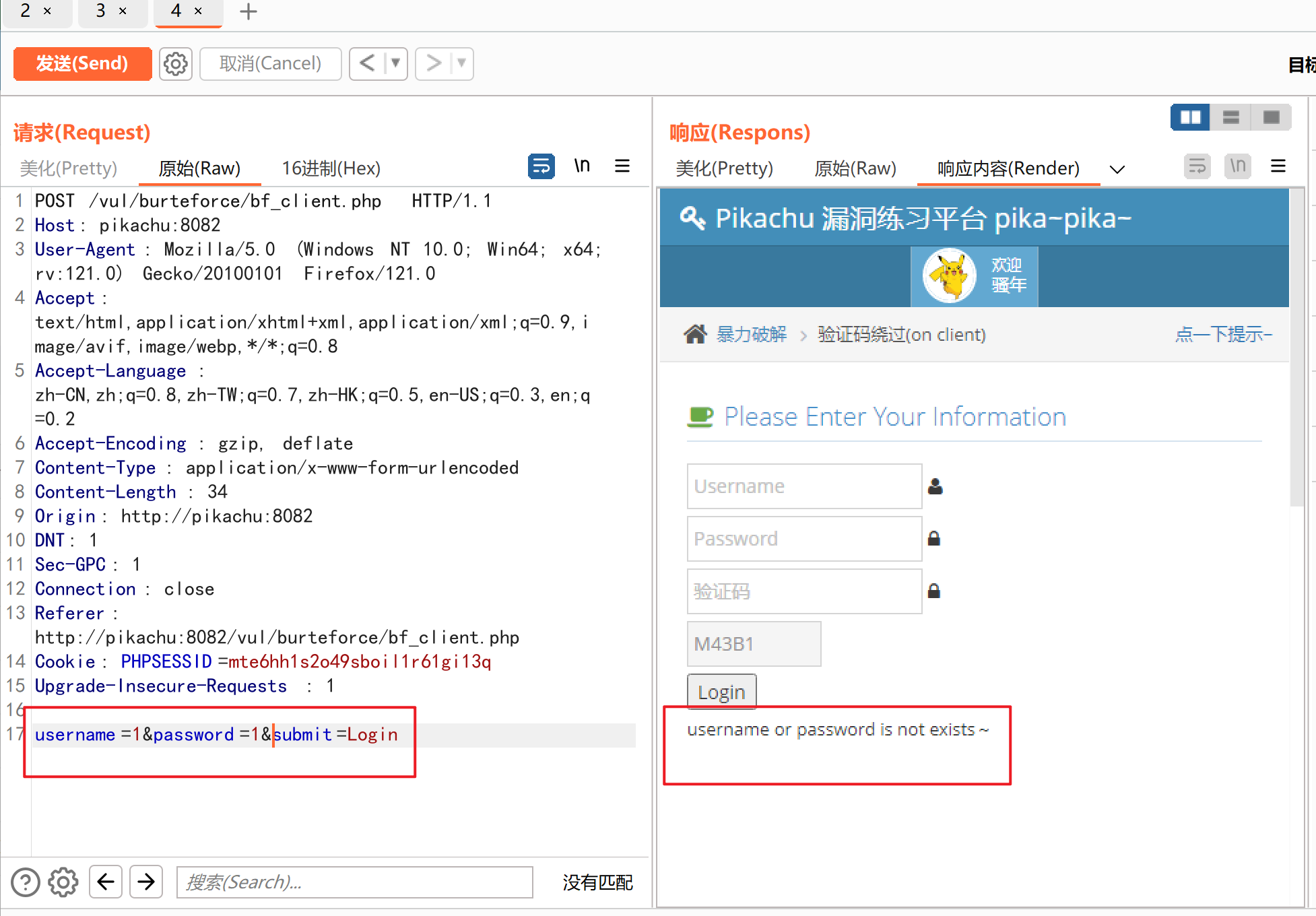
进入 Intruder界面后,我们需要选择需要对需要破解的数据进行标记,并且选择攻击方式(Attack type)
首先选择clear,清除所有位置,然后分别选中username和password输入的数据进行标记,点击Add,最后选择攻击方式Cluster bomb,因为这里需要爆破的是用户名和密码,所以要选择多个playload集合进行攻击

随后进入Payloads模块,在payload set 1位置,也就是username位置,上传关于我们的账号的字典,在2位置选择我们的password字典,这里如果没有字典,可以去网上查找,或者直接手动添加爆破的数据
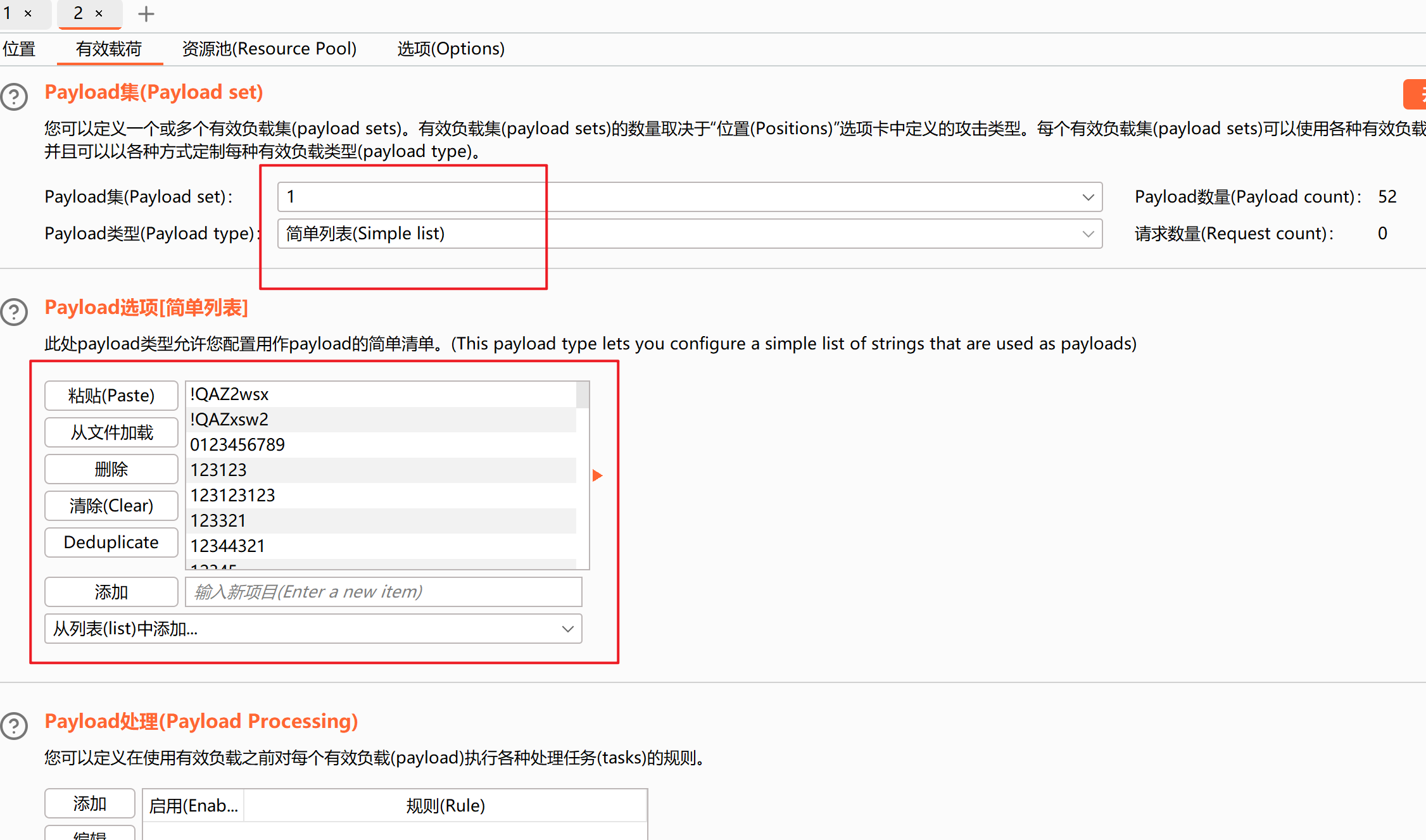

然后点开始攻击,爆破结束后,我们可以根据返回数据长度来判断正确的账号密码,返回长度不同于其他数据包的,就是正确的账号密码,也可以查看其对应的响应内容来判断,此处账号:admin 密码:123456

最后成功登陆
验证码绕过(on server):
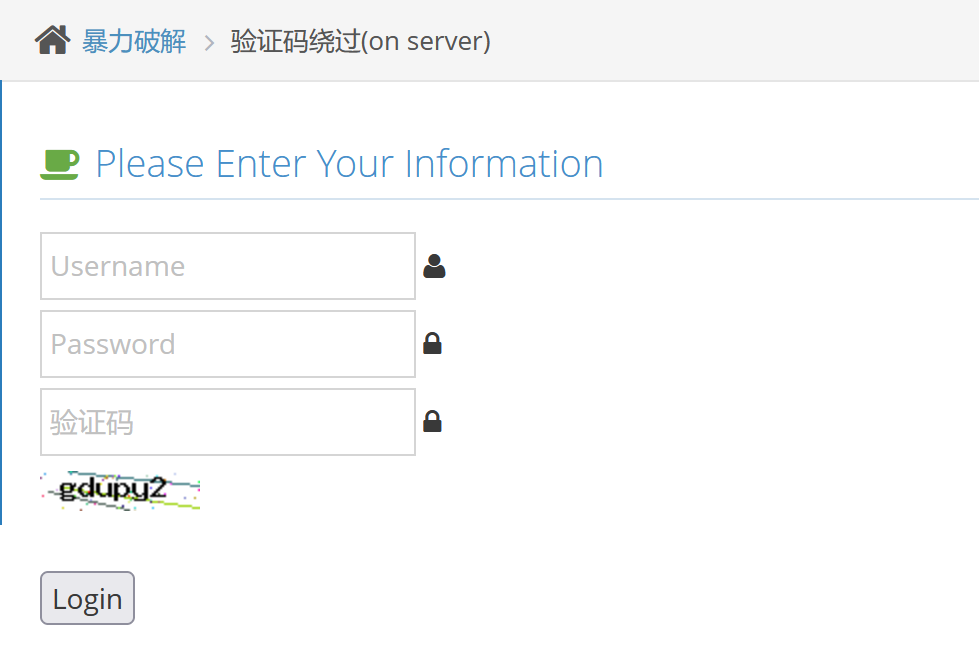
这里是一个带有验证码的登陆界面,我们试着输入错的用户名和密码以及验证码的时候,它会提示说验证码错误:
我们再输入正确的验证码和错误的用户名和密码,来看一下:
它显示用户名和密码错误,而且只有当页面刷新的时候,它的验证码才会重新刷新,想到有些服务器的后台是不会刷新验证码的,所以我们进行抓包重放来看一下:
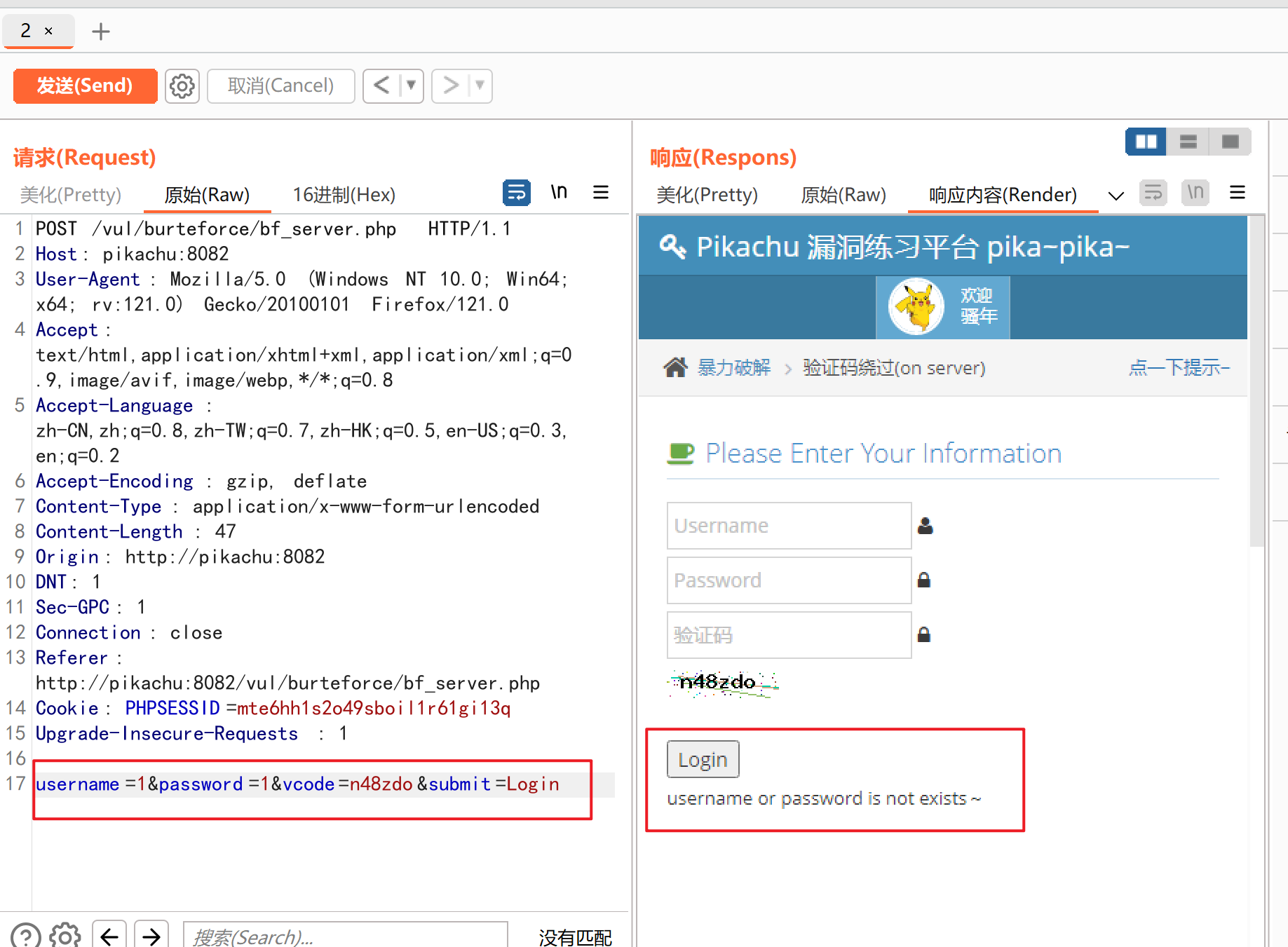
经过多次验证,我们抓到包之后拦截下来,发送到重放器里面,但我们不刷新页面,验证码就不会更新,验证码就可以重复利用,只要不放包让它刷新了,验证码就不会改变,现在我们就发送到Intruder,进行爆破

这里还是和上一个一样,只不过多了一个验证码
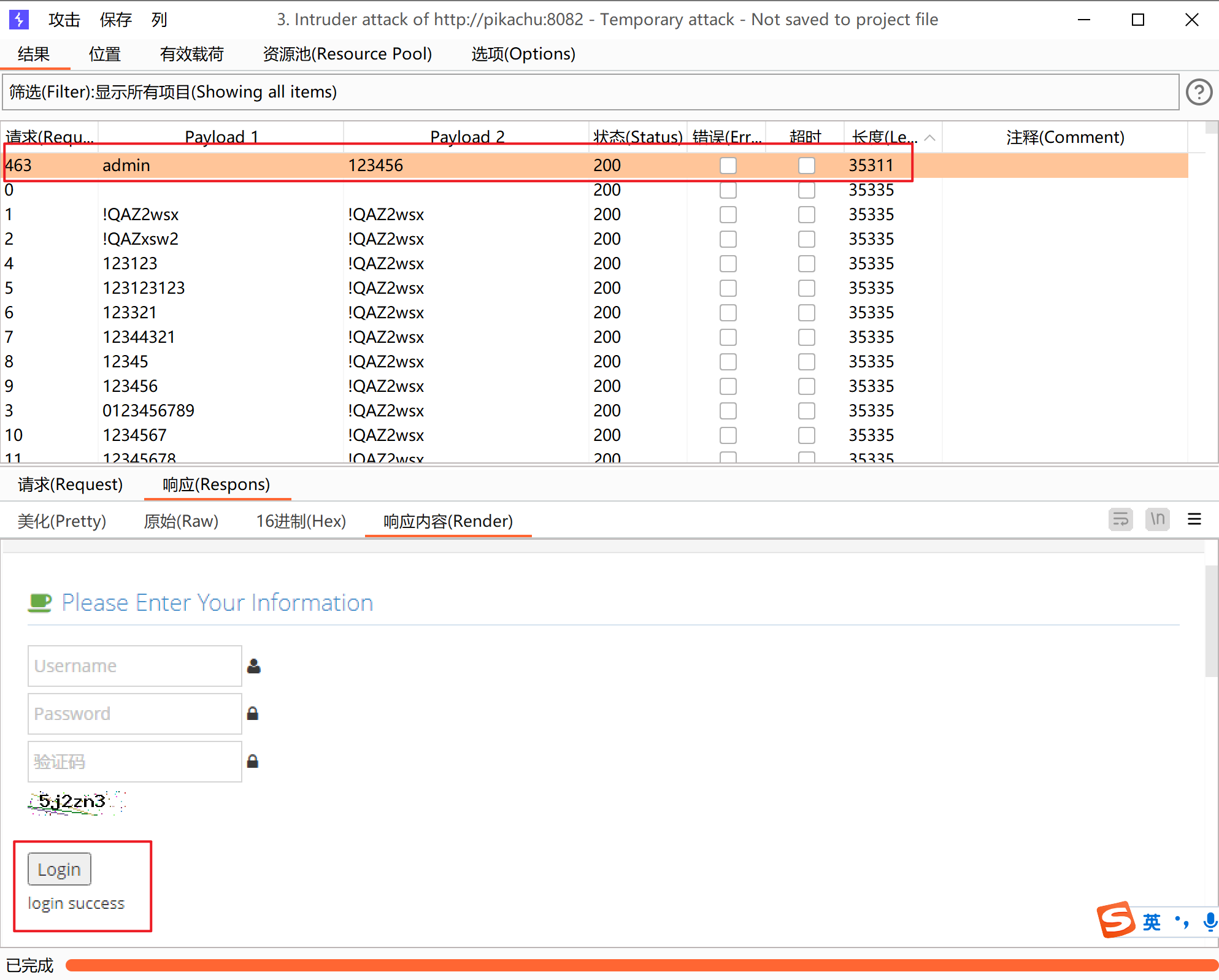
成功登陆
验证码绕过(on client):
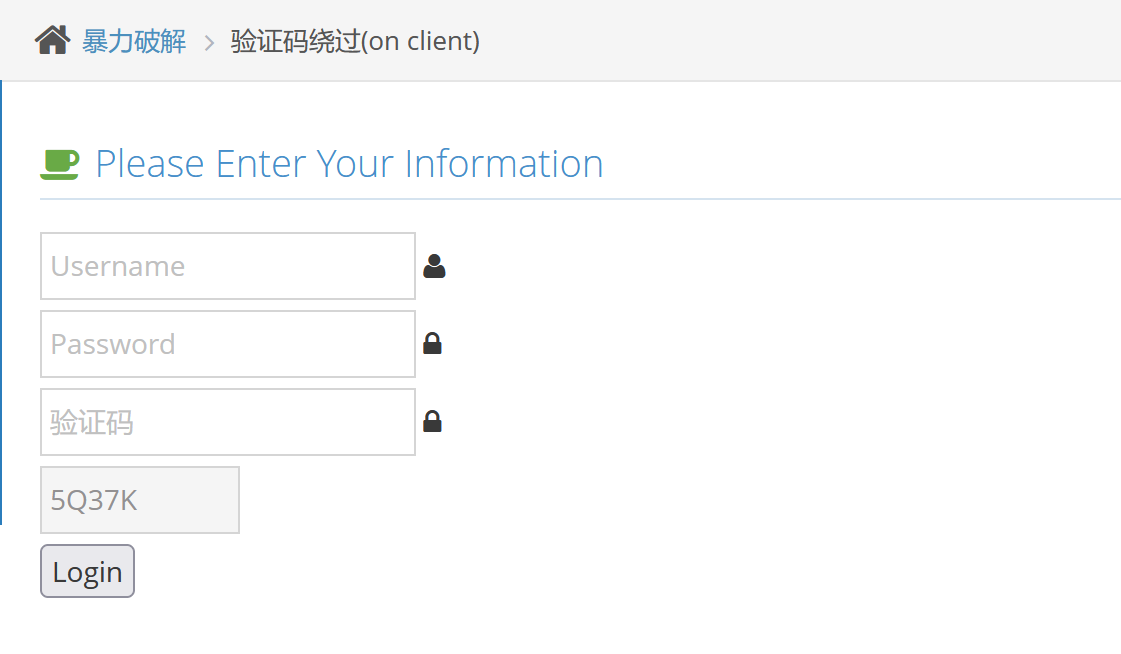
我们依旧随意填账号和密码,填正确的验证码,显示用户名和密码错误,我们输入错误的验证码看一下
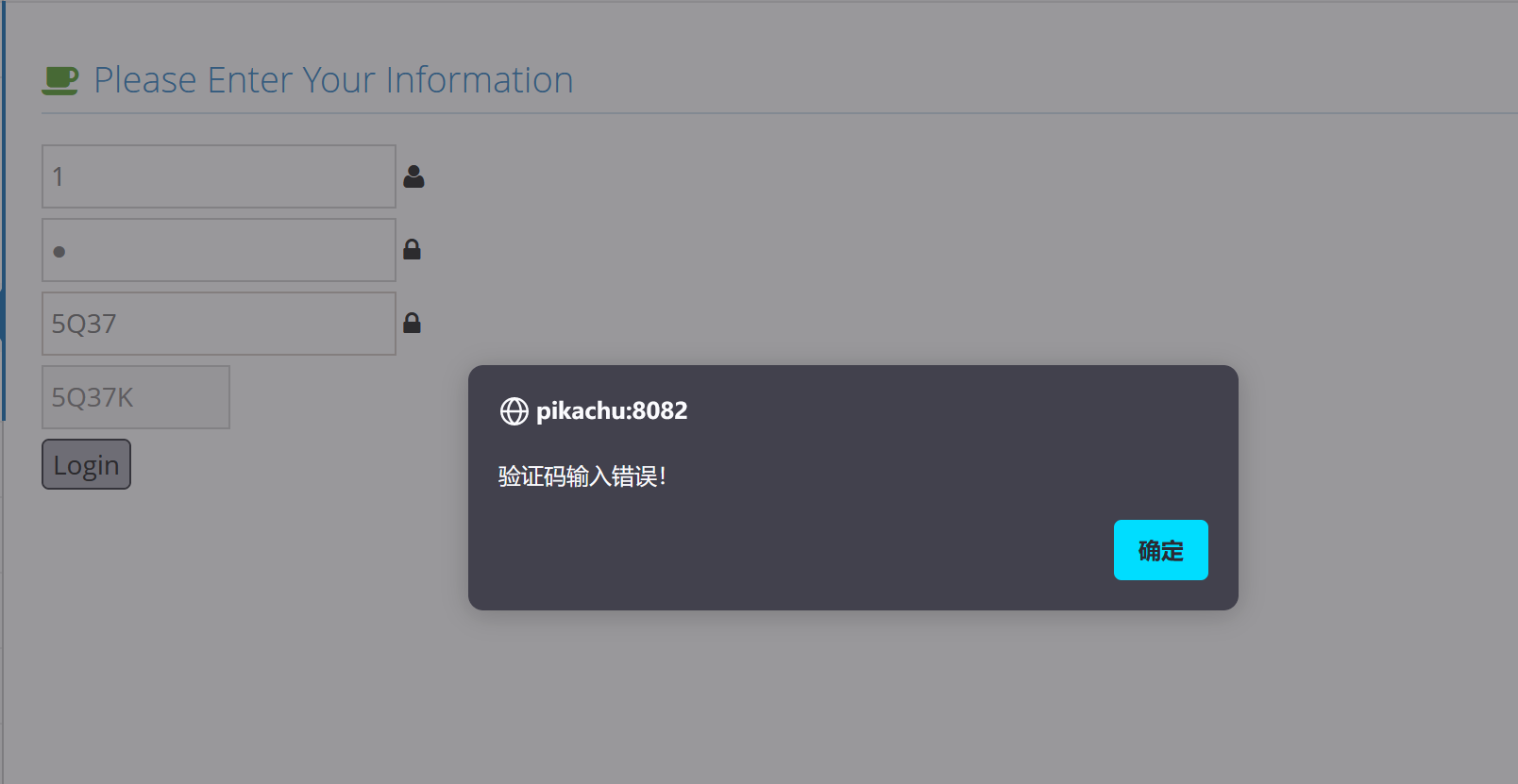
这里弹出一个验证码错误的弹窗,查看一下它的源码:
<script language="javascript" type="text/javascript">
var code; //在全局 定义验证码
function createCode() {
code = "";
var codeLength = 5;//验证码的长度
var checkCode = document.getElementById("checkCode");
var selectChar = new Array(0, 1, 2, 3, 4, 5, 6, 7, 8, 9,'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z');//所有候选组成验证码的字符,当然也可以用中文的
for (var i = 0; i < codeLength; i++) {
var charIndex = Math.floor(Math.random() * 36);
code += selectChar[charIndex];
}
//alert(code);
if (checkCode) {
checkCode.className = "code";
checkCode.value = code;
}
}
function validate() {
var inputCode = document.querySelector('#bf_client .vcode').value;
if (inputCode.length <= 0) {
alert("请输入验证码!");
return false;
} else if (inputCode != code) {
alert("验证码输入错误!");
createCode();//刷新验证码
return false;
}
else {
return true;
}
}
createCode();
</script>
发现这里它将验证验证码的代码写在了前端,通过深入的学习后知道,任何在前端进行验证的都是完全没有作用的
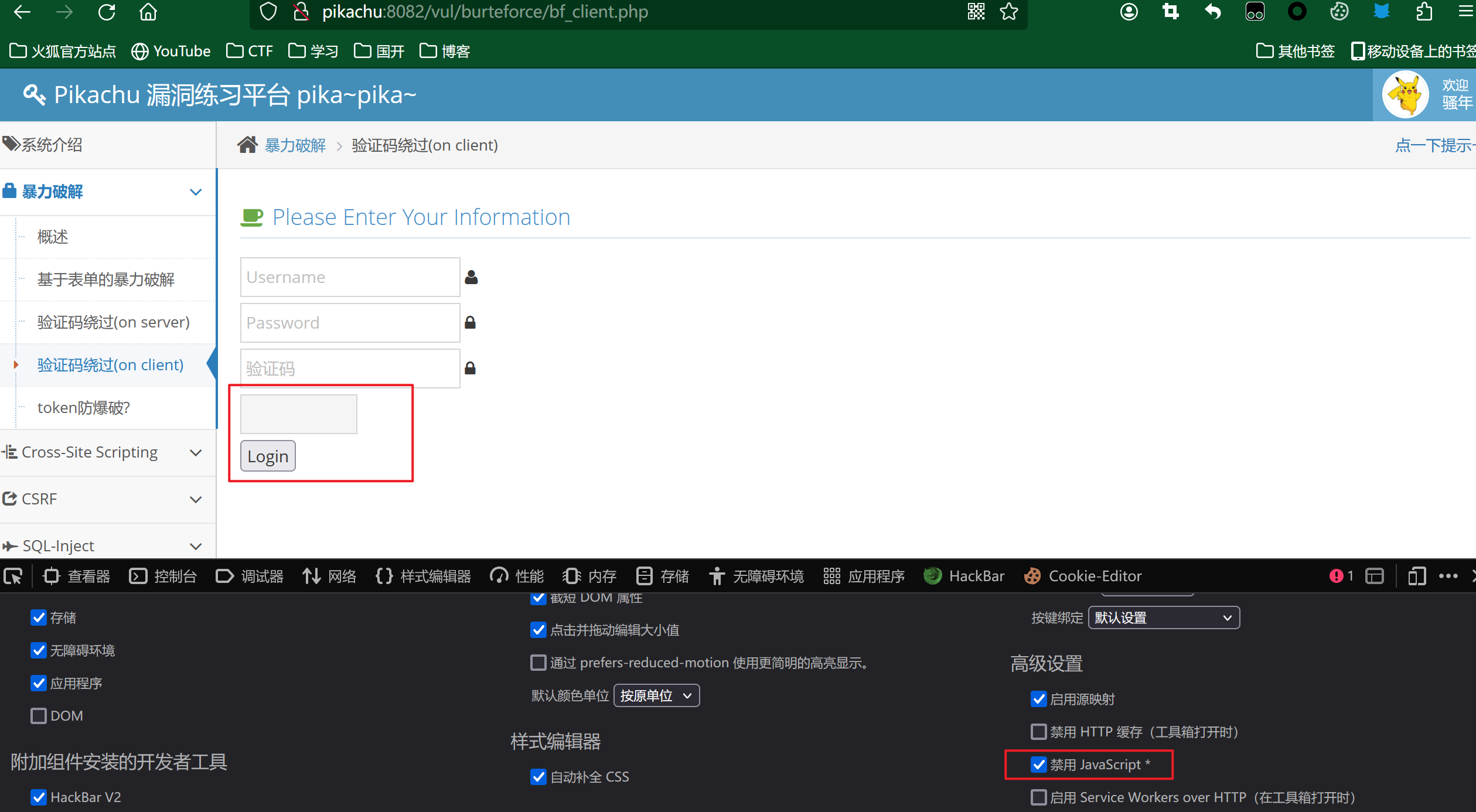
这里我们只需要F12,然后在设置里或者F1,选择禁用JavaScrip,那这里前端的验证功能就没用了,如图
这里我们也可以进行抓包来验证一下
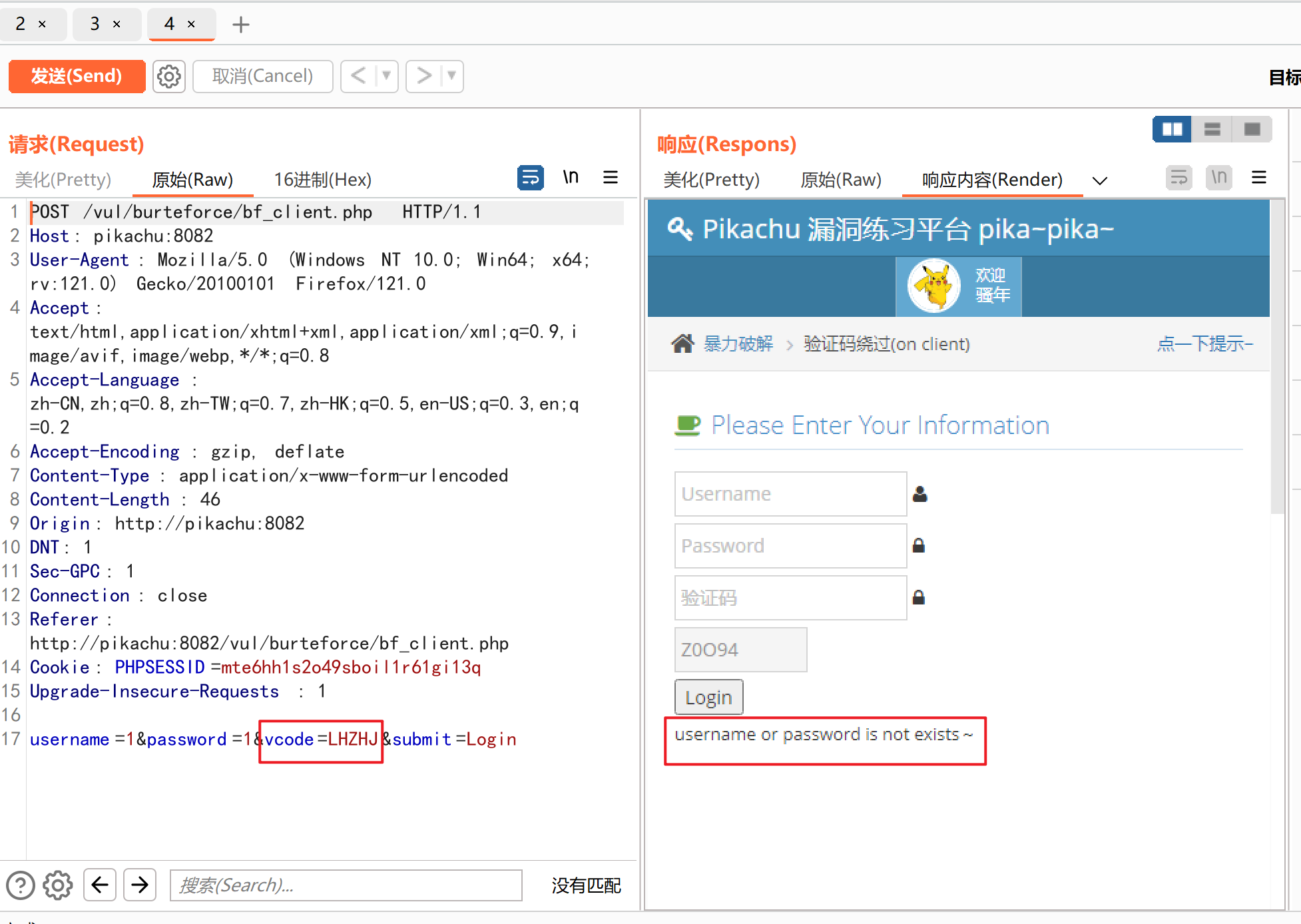
这里我们实验发现,当我们将验证码参数删除之后,它也不会显示报错,那就说明验证码写在前端是没用的,然后进行爆破来获取用户名和密码:

登陆成功
token防爆破?
这里提示说token防爆破,所以首先我们先来了解一下什么是token
"token"通常指的是一个用于验证用户身份和授权访问的令牌。它是一种特殊的字符串或代码,由服务器生成并分配给经过身份验证的用户。用户在成功登录后,服务器会颁发一个token给客户端(例如Web浏览器),客户端将在随后的请求中将该token作为身份验证凭据发送给服务器。
简单来说就是服务器给前端发的身份证,前端向服务器发送请求时都要带上这个身份证,服务器通过这个身份证来判断是否是合法请求
我们再回到登陆界面,F12来查看一下,发现在用户名和密码下面进行验证的token:
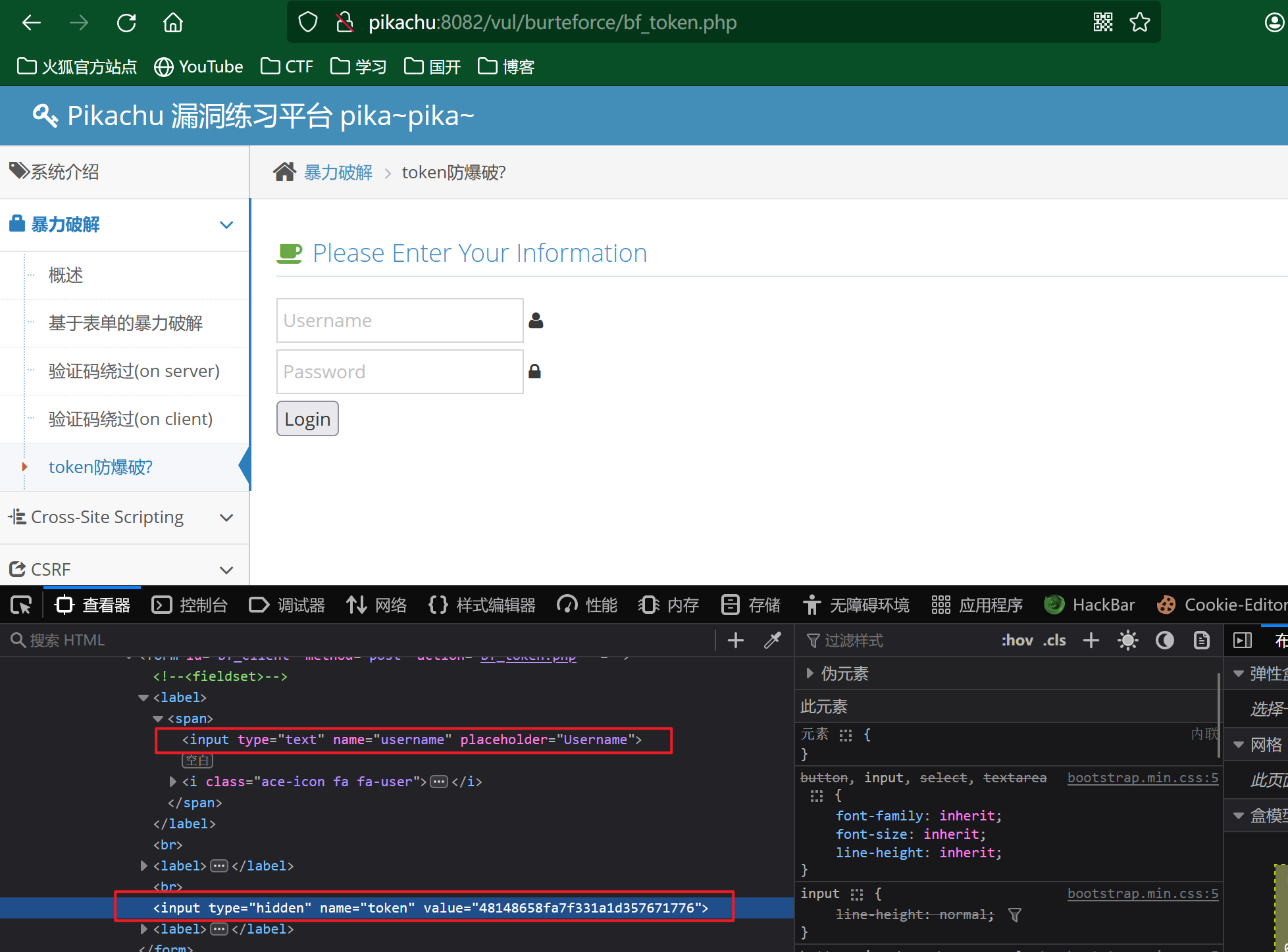
这里有了token的验证,那这里我们适用与已知账号的情况,或者已知账号和密码一一对应的情况,而且这里我们暴力破解的方式也要进行改变,但还是一样的先抓包,发送到Intruder
然后这里我们的攻击方式选择 交叉(Pitchfork)
攻击类型为音叉的时候,例如你要爆破账号和密码,你的账号字典为123,456;你的密码字典为147,258。那么你爆破的次数就为2次了,分别是(123,147),(456,258),也就是说账号字典和密码字典是一一对应的
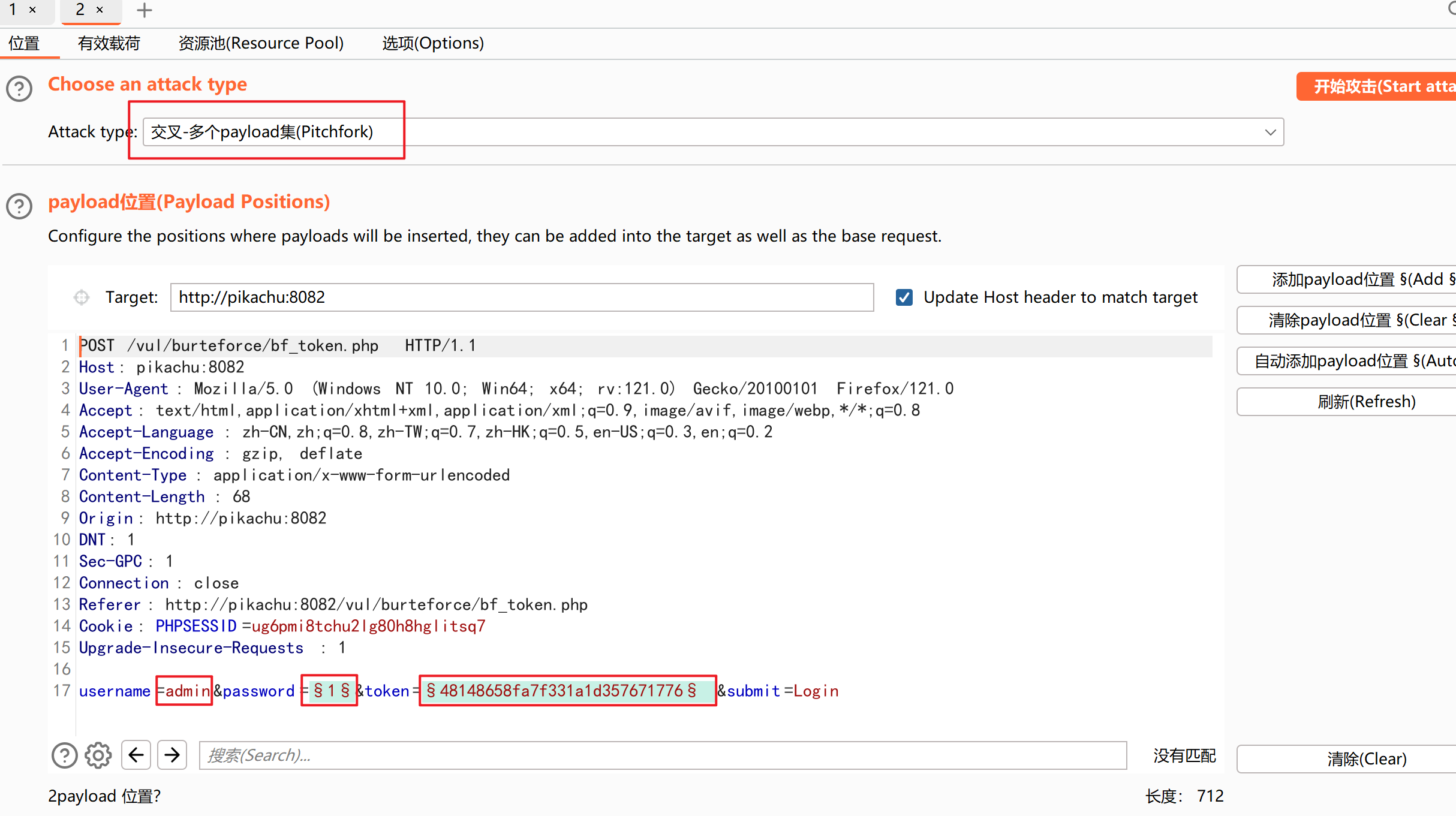
然后我们来到payload集模块,这里password的payload集还是一样的添加字典进去,但是token的payload集我们就要来设置一下
我们选择选项(Options),然后往下滑
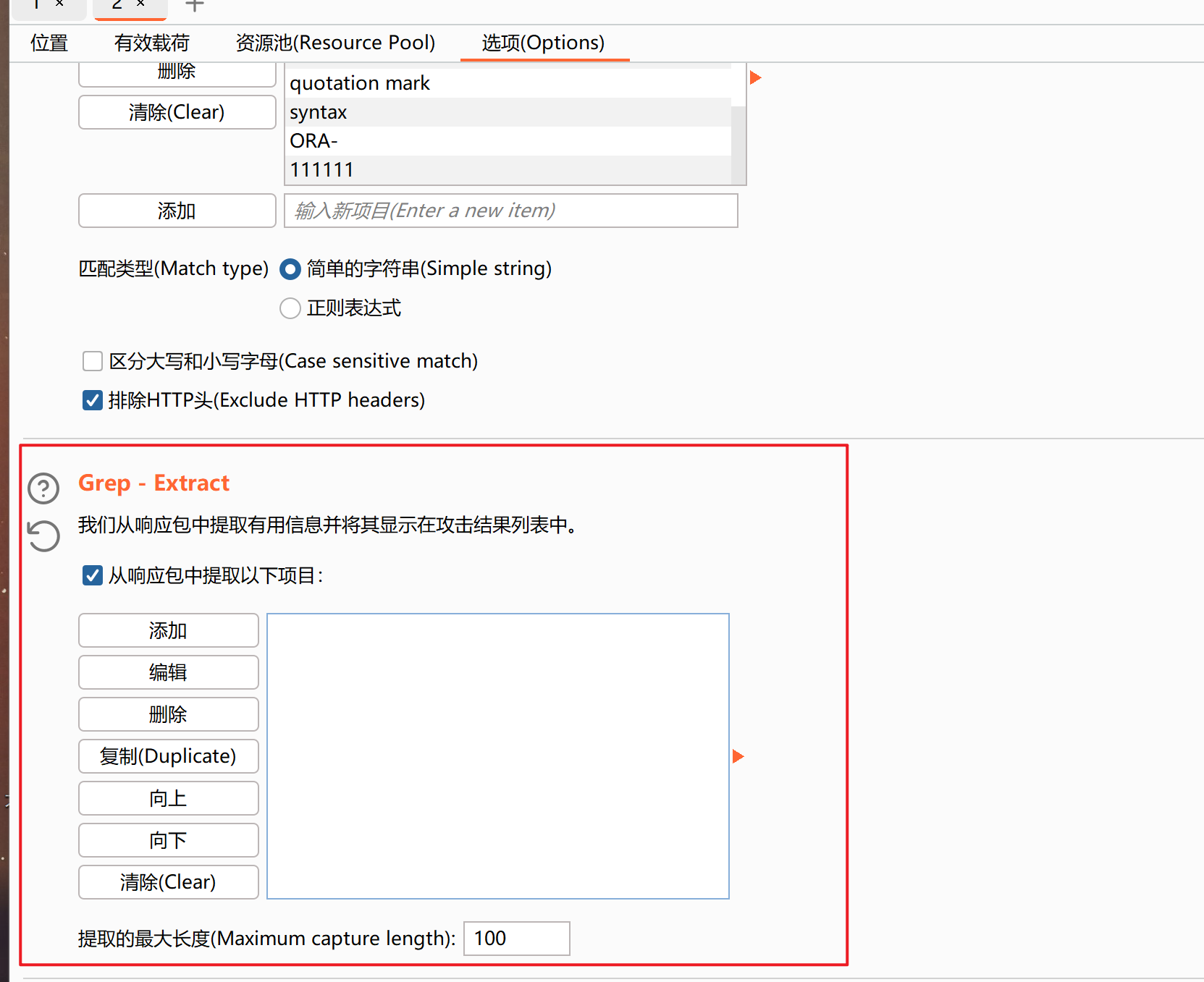
找到Grep-Extract,然后点击添加(add)
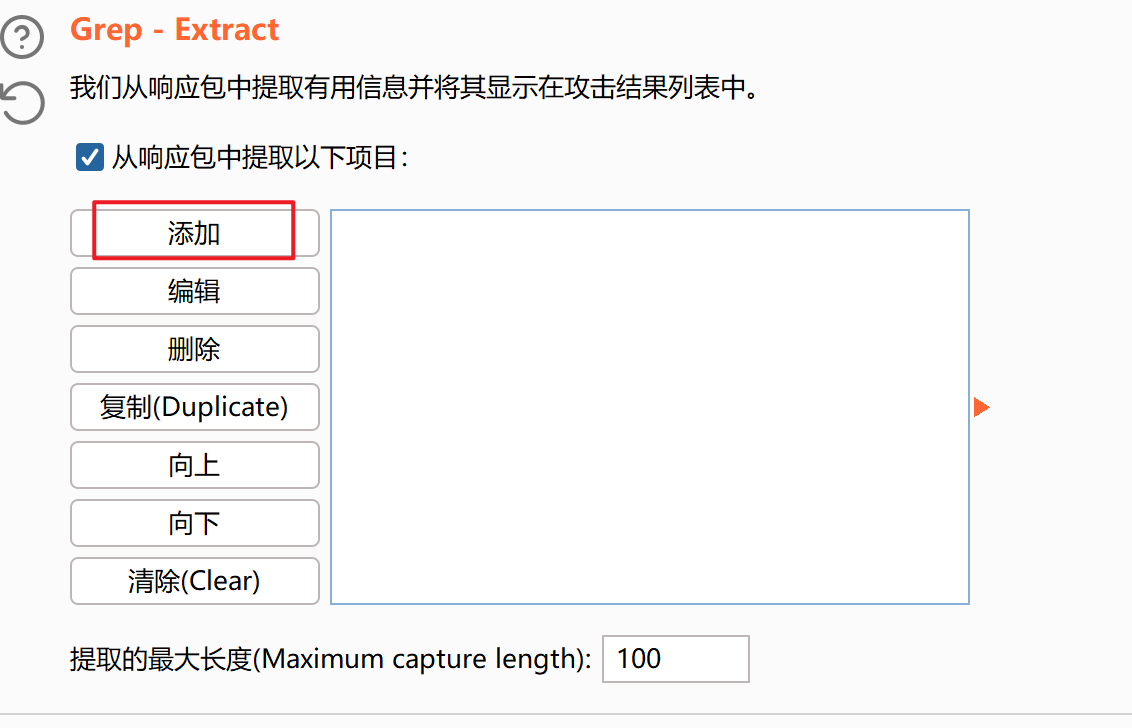
点击刷新,获取响应包
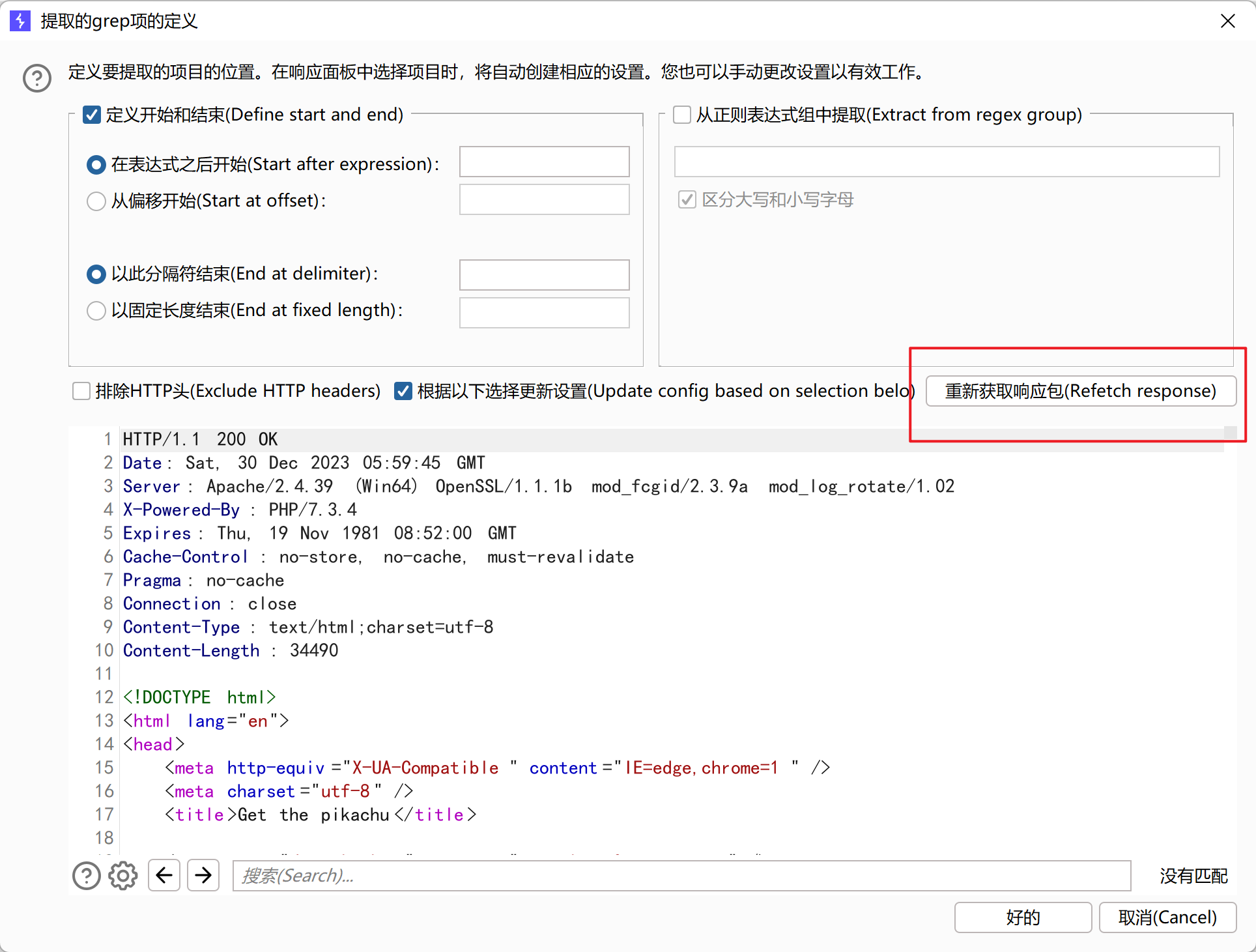
在搜索框搜索token,复制并选中token后面value里面对应的token值,然后点好的(OK)
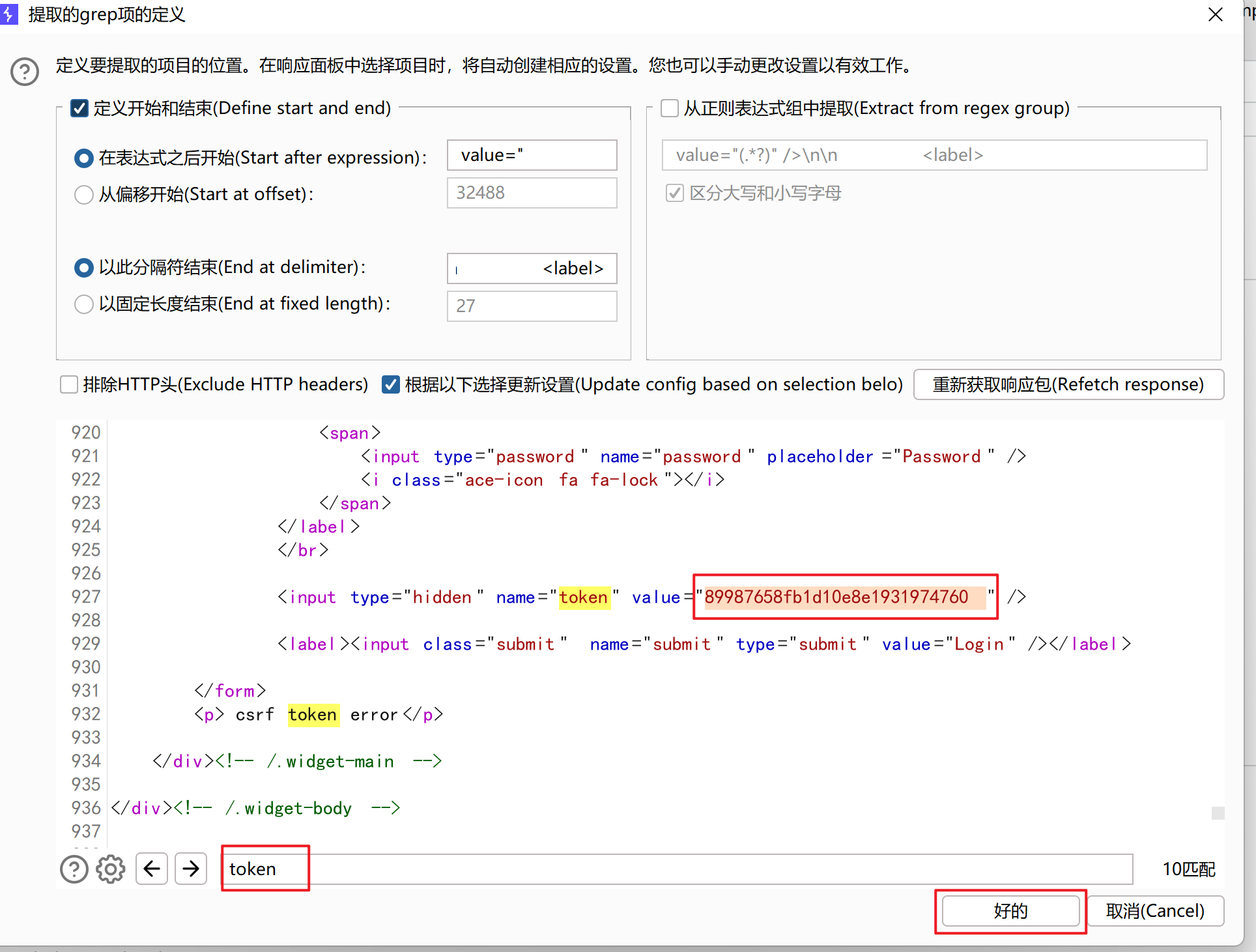
现在又返回到payload集,设置token,选择递归匹配(Recursive grep)将复制的token复制到first request里面
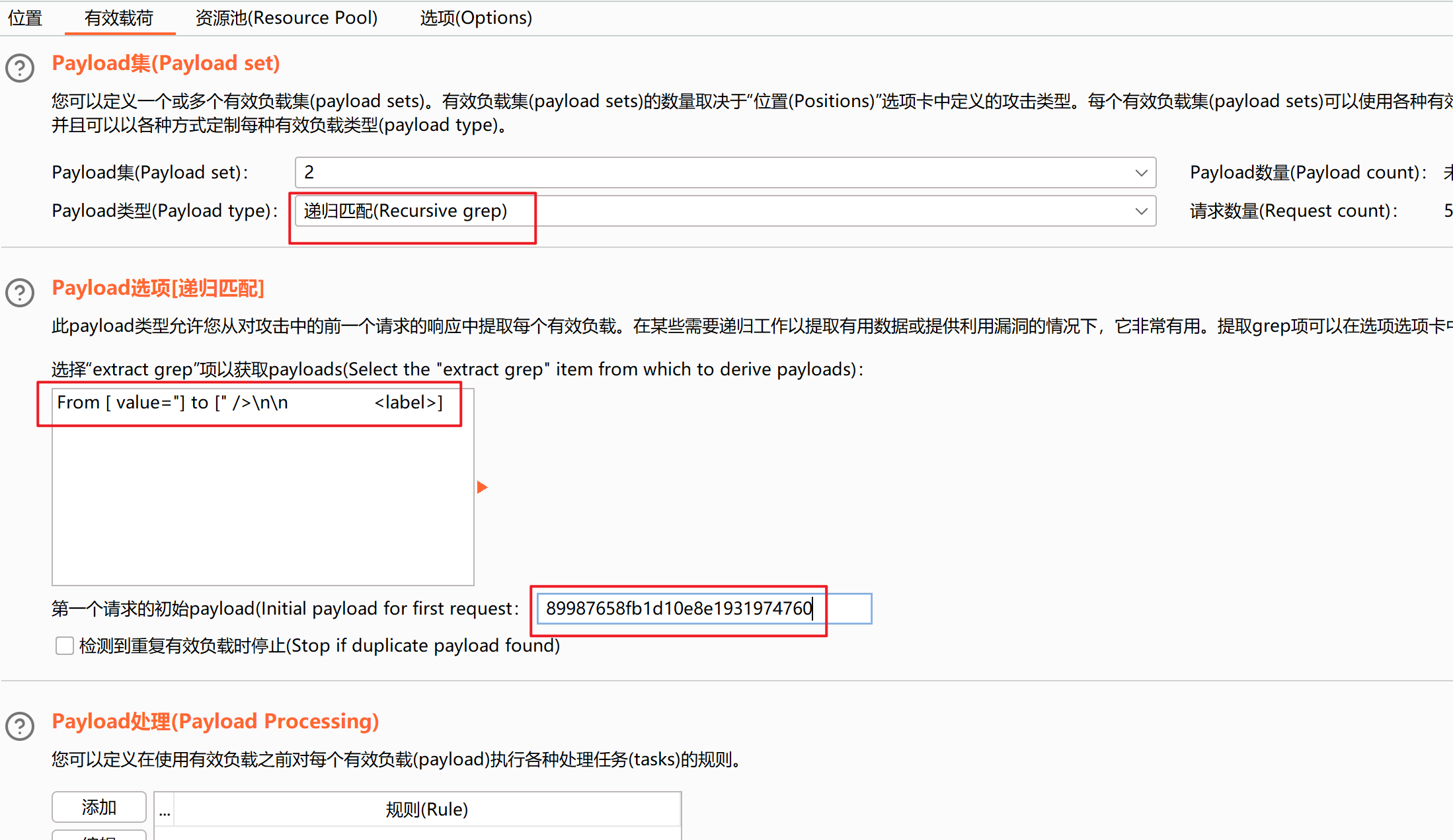
然后开始攻击
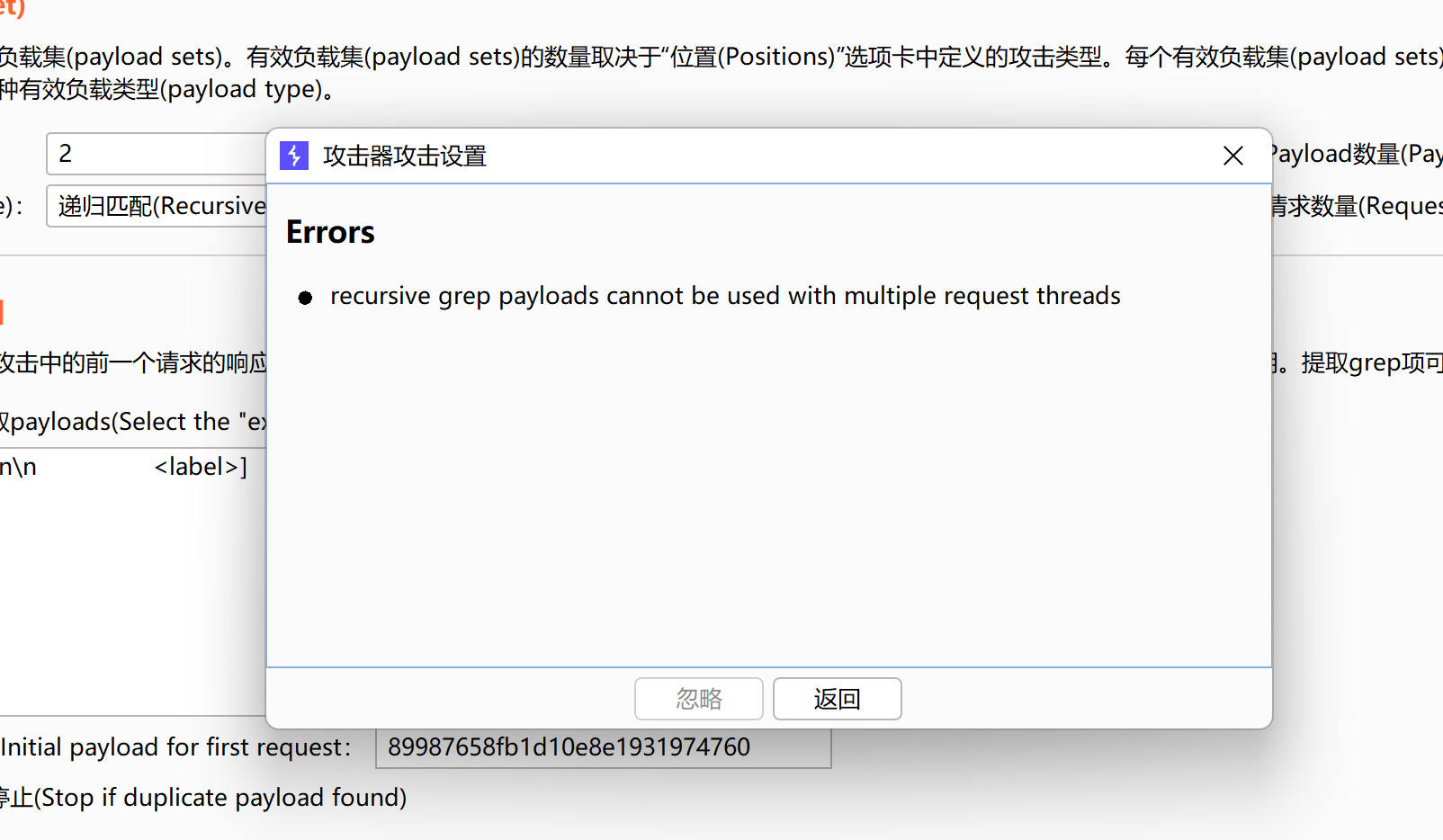
这时如果弹出这样的弹窗,因为我们设置token是递归匹配,所以我们来到资源池(Resource Pool)模块,选择创建新的资源池,并把最大请求数改为1
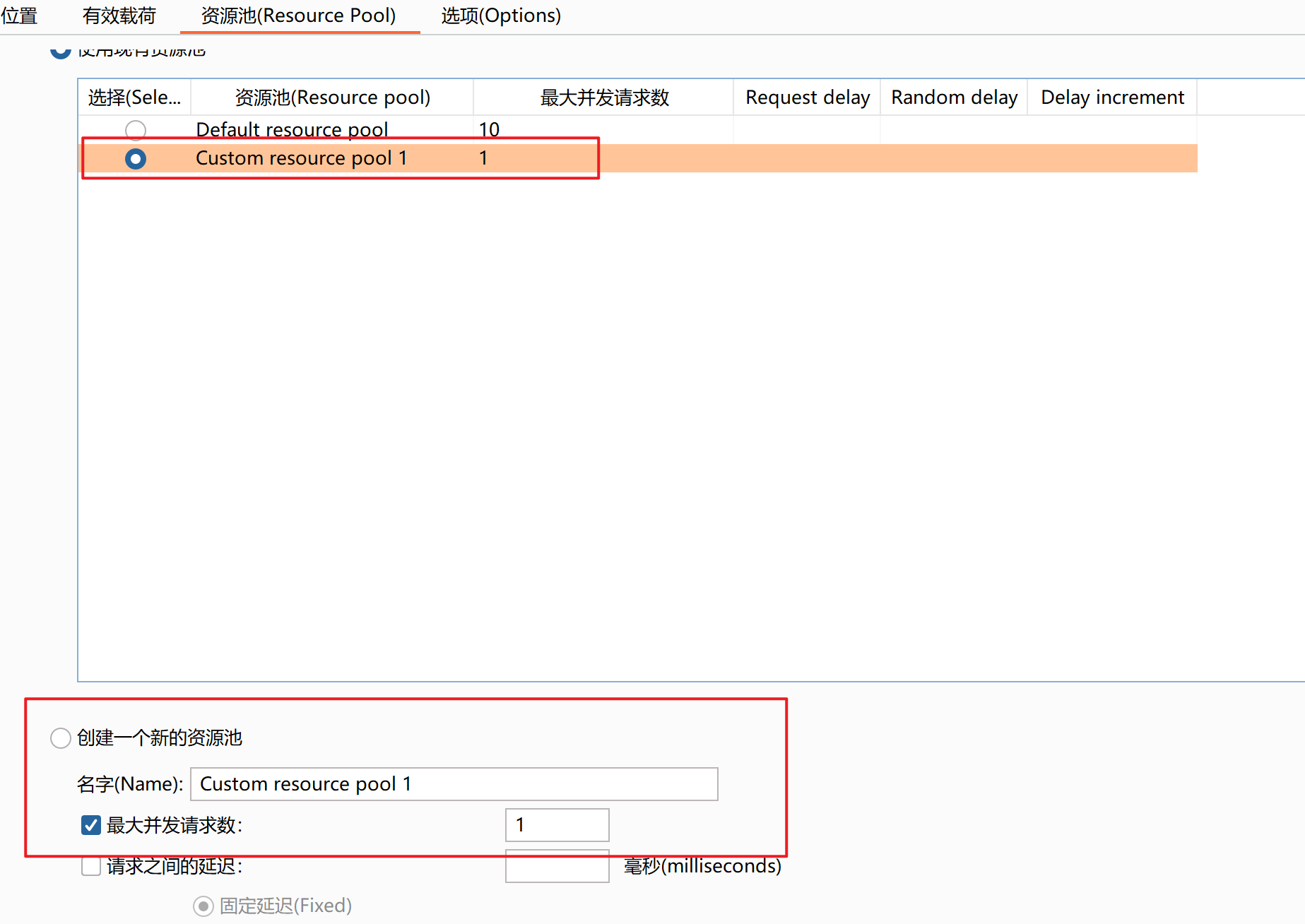
然后再点开始攻击
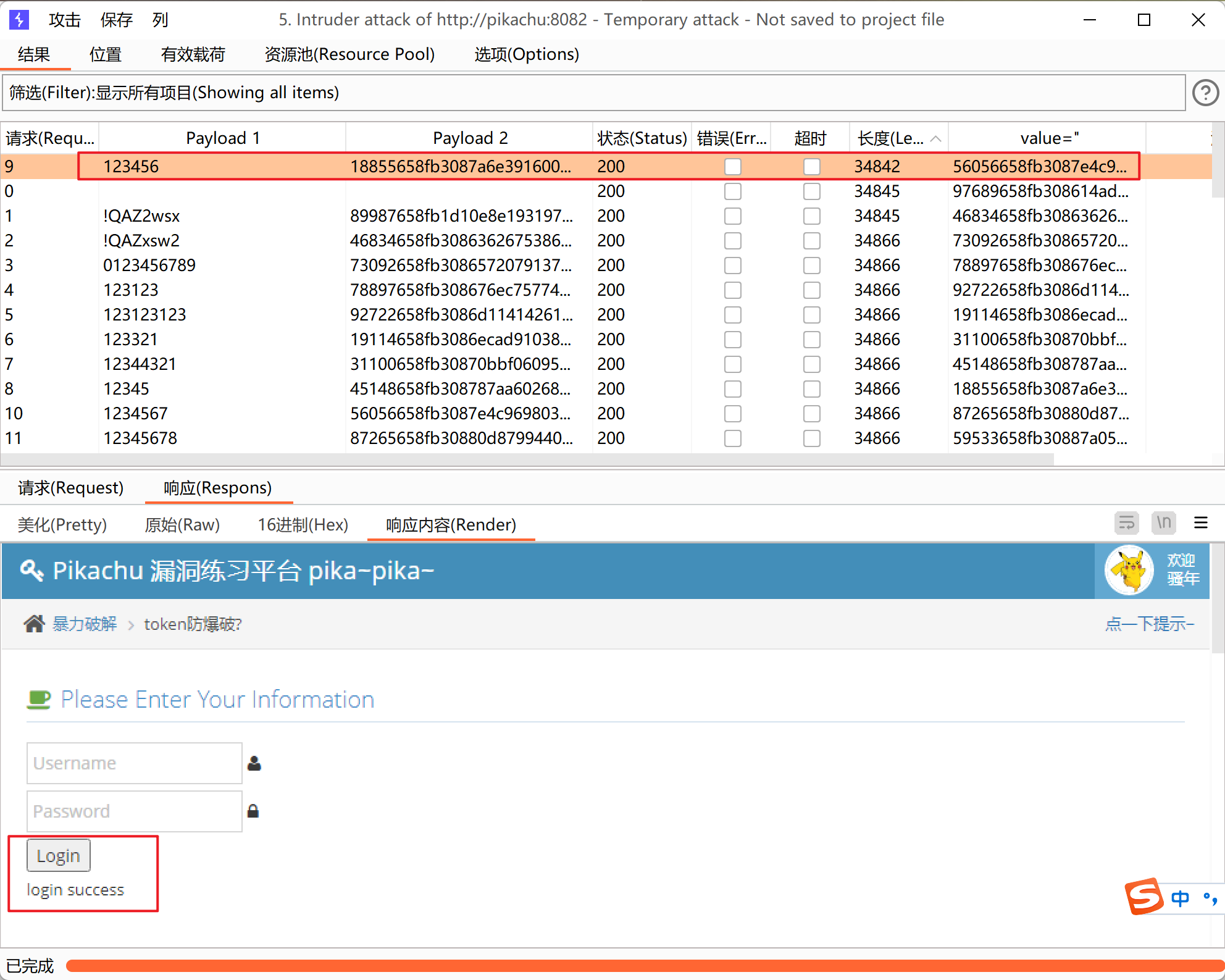
最后登陆成功
Cross-Site Scripting(XSS):
概述:
XSS(跨站脚本)概述
Cross-Site Scripting 简称为“CSS”,为避免与前端叠成样式表的缩写"CSS"冲突,故又称XSS。一般XSS可以分为如下几种常见类型:
1.反射性XSS;
2.存储型XSS;
3.DOM型XSS;
XSS漏洞一直被评估为web漏洞中危害较大的漏洞,在OWASP TOP10的排名中一直属于前三的江湖地位。
XSS是一种发生在前端浏览器端的漏洞,所以其危害的对象也是前端用户。
形成XSS漏洞的主要原因是程序对输入和输出没有做合适的处理,导致“精心构造”的字符输出在前端时被浏览器当
作有效代码解析执行从而产生危害。
因此在XSS漏洞的防范上,一般会采用“对输入进行过滤”和“输出进行转义”的方式进行处理:
输入过滤:对输入进行过滤,不允许可能导致XSS攻击的字符输入;
输出转义:根据输出点的位置对输出到前端的内容进行适当转义;
你可以通过“Cross-Site Scripting”对应的测试栏目,来进一步的了解该漏洞。
反射型xss(get) :
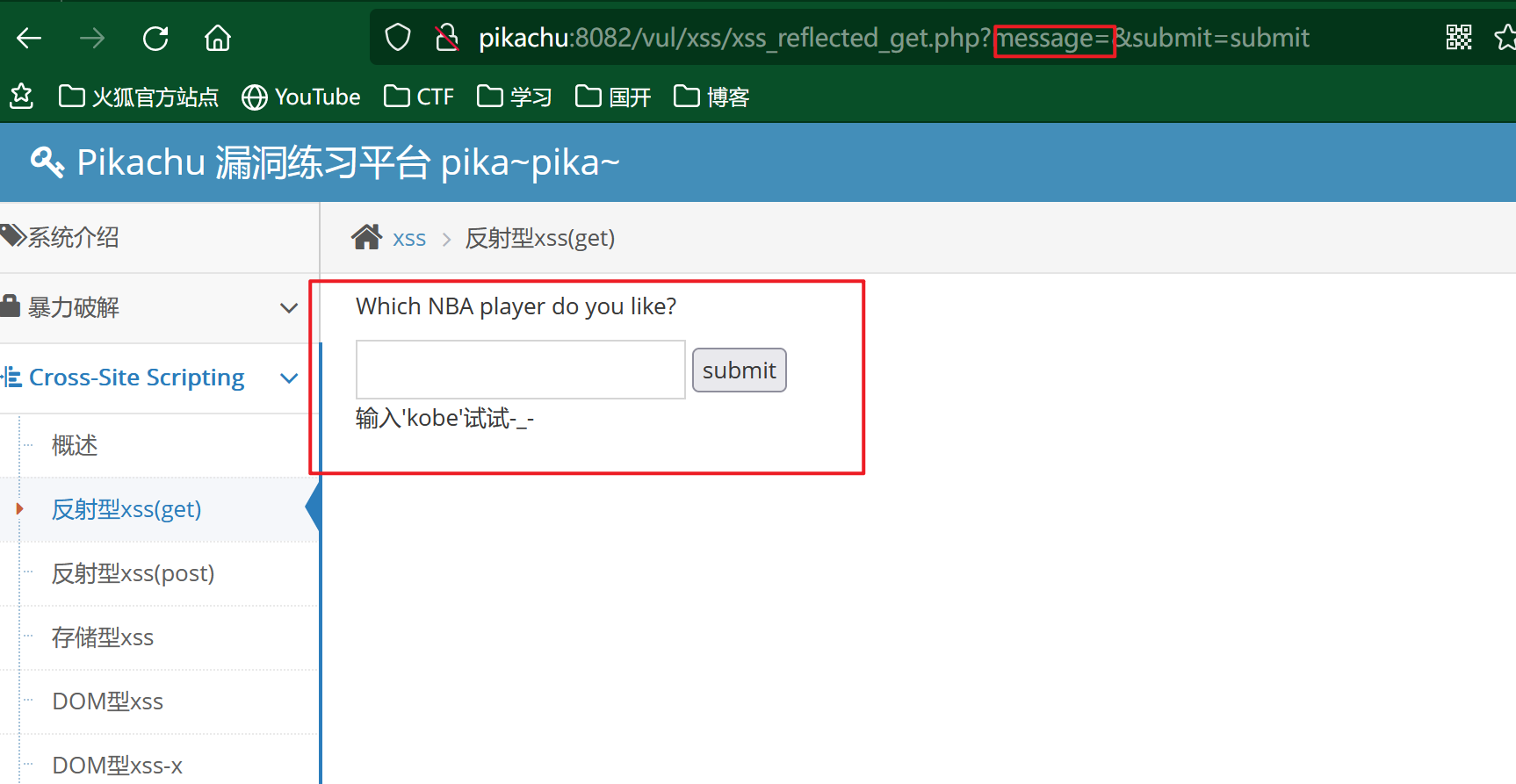
由于是GET类型传参,我们构造来payload:
<script>alert('xss')</script>

这里输入时我们发现输入完('xss')就不能输入了,明显超过长度限制的
这么我们F12,右键那个输入宽然后点检查,将它的最大长度改成100,我们就可以正常输入我们的payload了
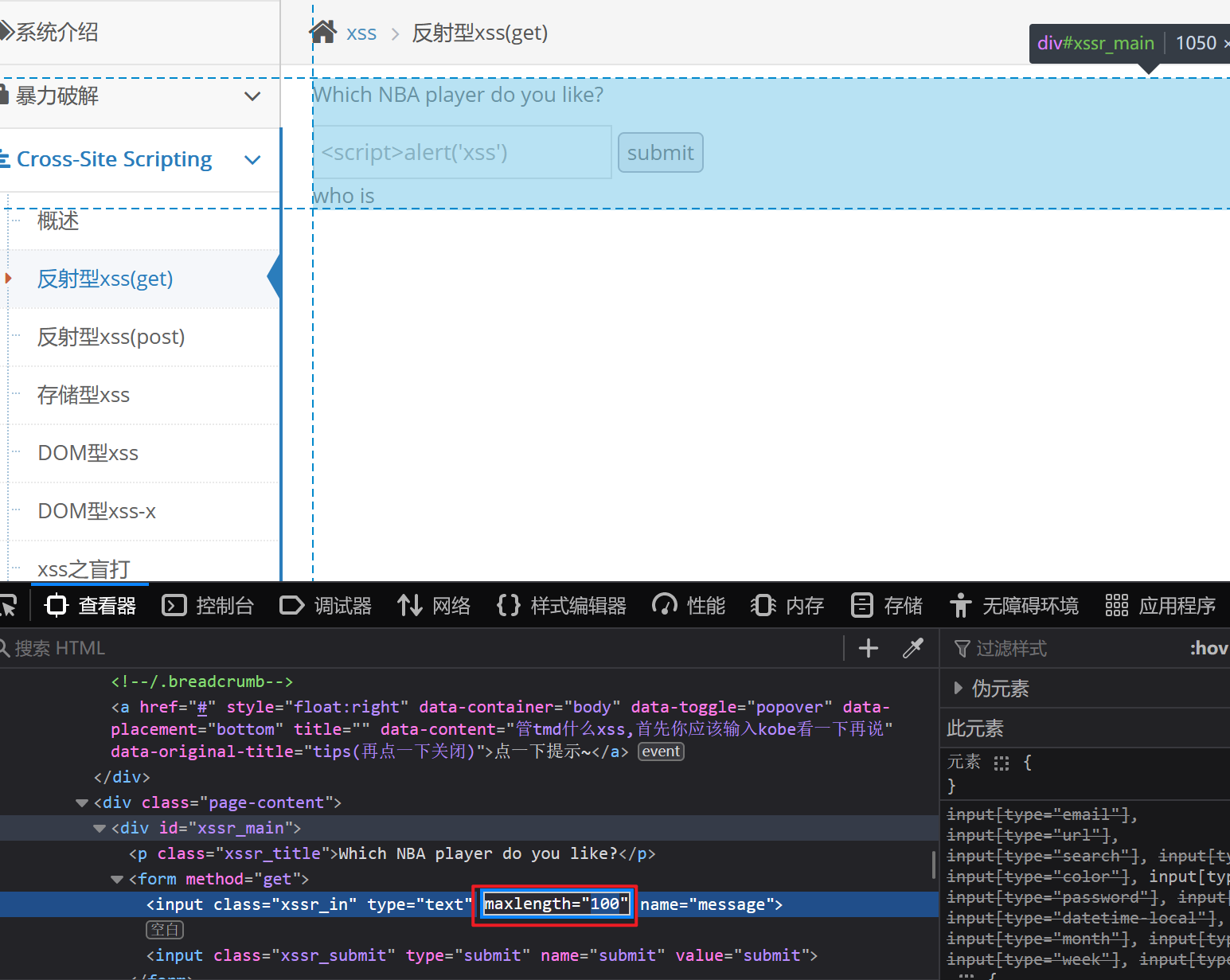
现在我们就可以输入我们的payload:

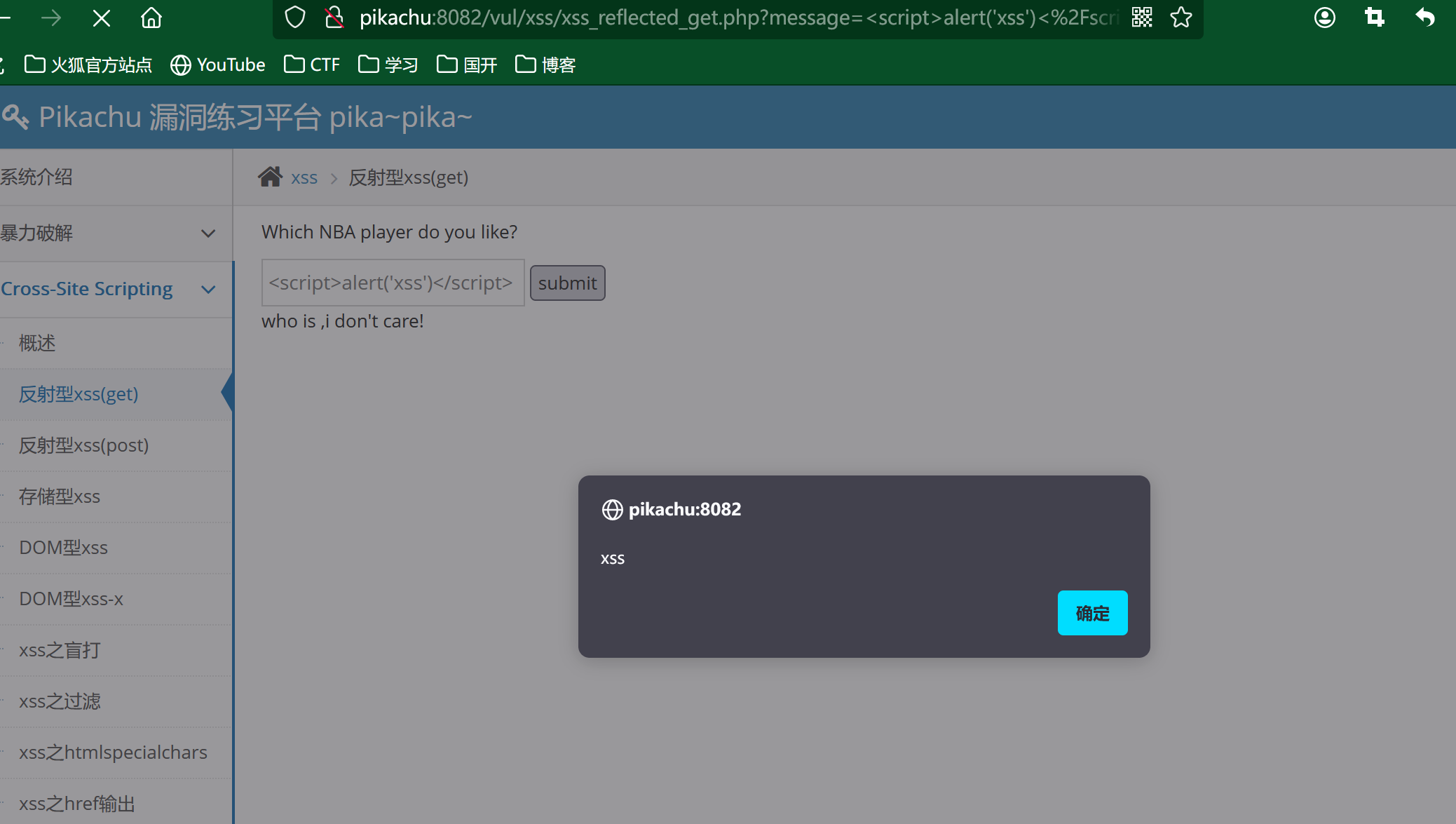
成功弹窗
反射性xss(post):
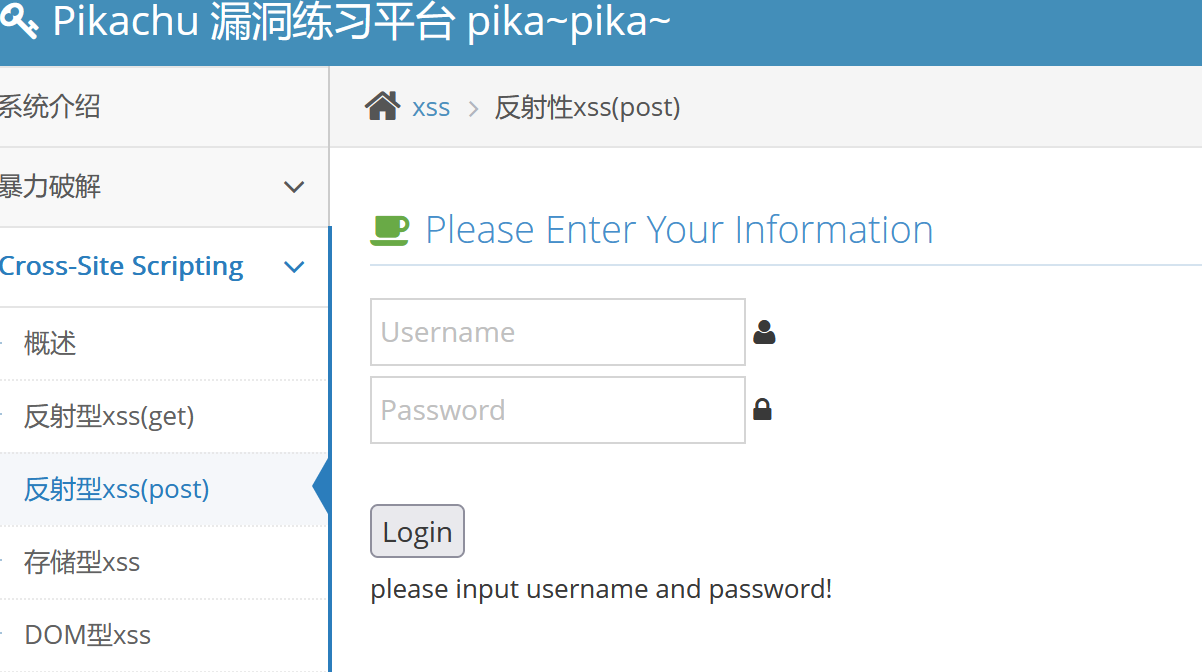
这里是一个登陆界面,但是在第一关爆破的时候我们就得到了管理的账号和密码:
账号:admin
密码:123456
然后我们就可以登陆进去,得到一个输入框:
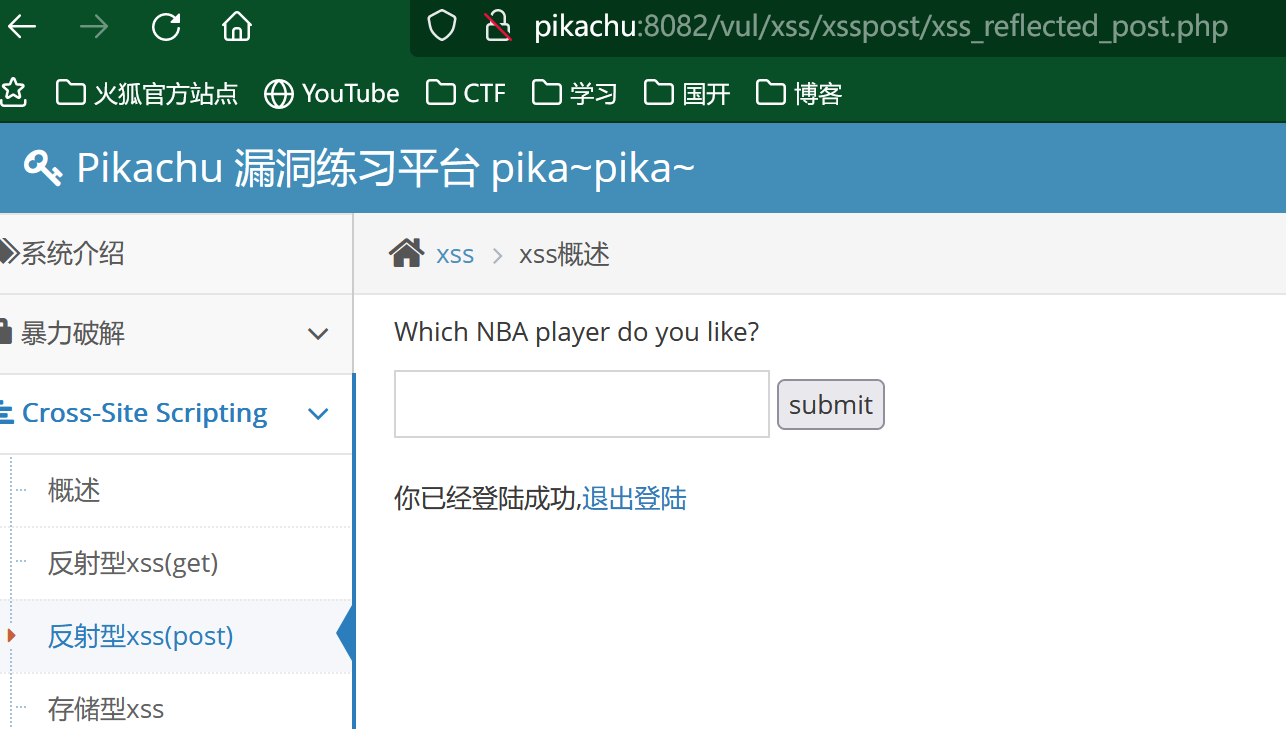
这里我们依旧构造我们的payload来弹出我们登陆的cookie值:
<script>alert(document.cookie)</script>
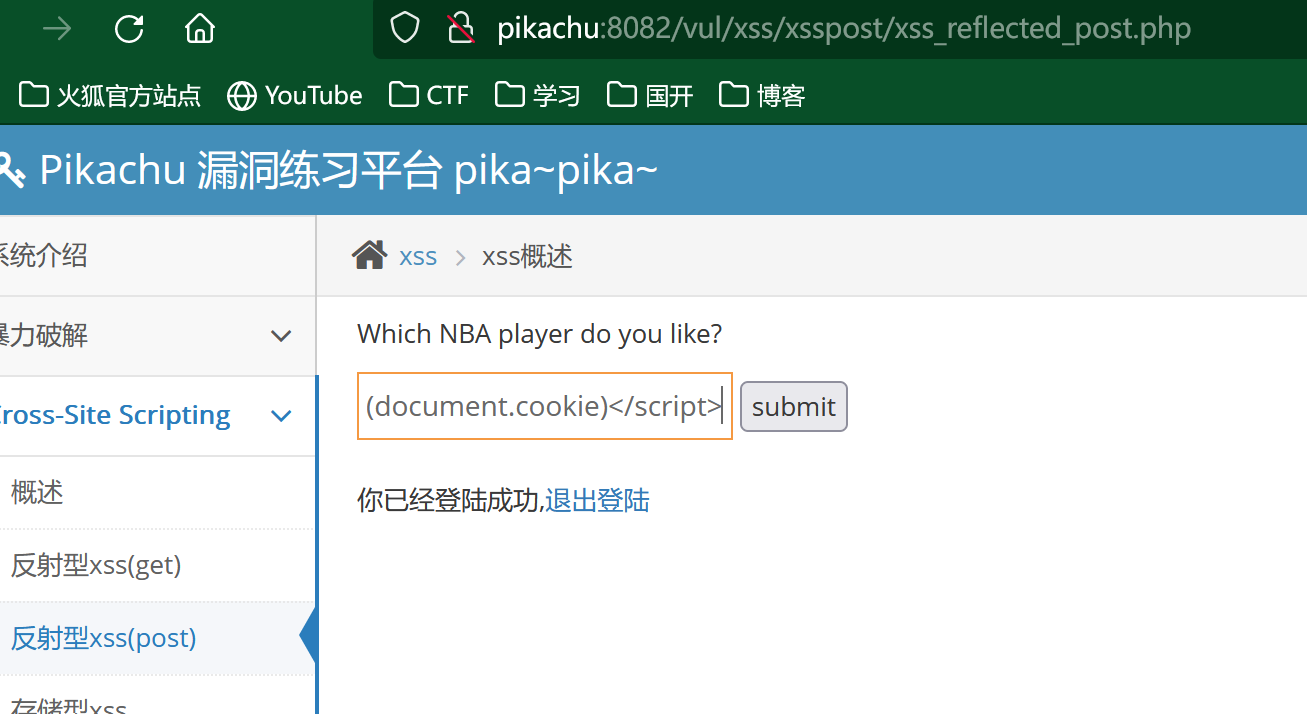
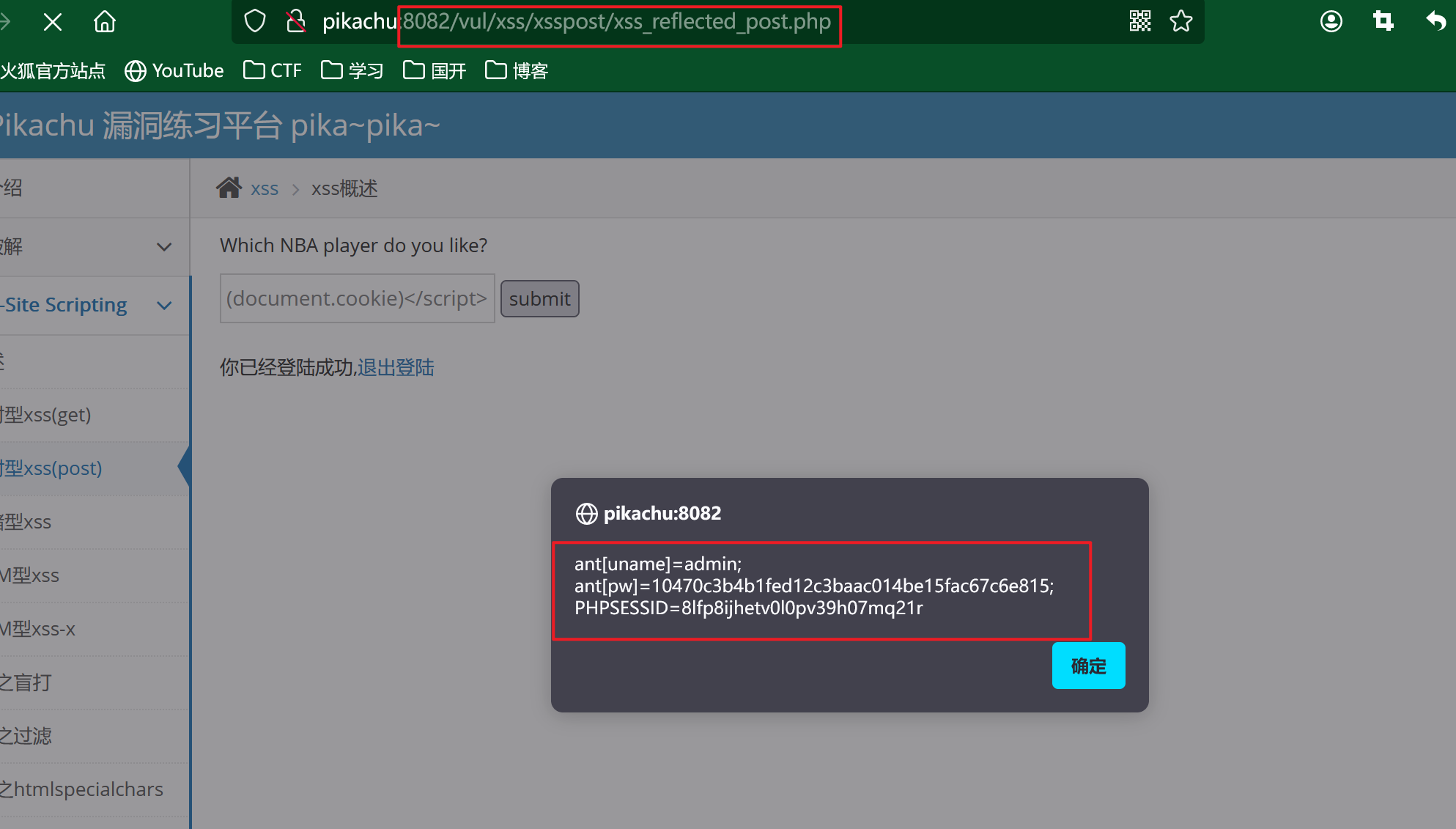
这里我们就弹出来我们的cookie信息
这里就会有人疑惑,这一关和上一关是一样的吗,就多了一个登陆界面,但是是不一样的
两者的区别:上一关是GET型传参,提交的数据会显示在url中,但是这一关是POST型传参,就不会显示在url中
这里我们分析一下POST和GET请求的区别:
1.数据传输方式:
GET请求:数据通过URL中的查询参数附加在URL后面,以明文形式传输数据。
POST请求:数据作为请求的正文发送,而不是通过URL传递。
2.数据长度限制:
GET请求:有长度限制,受浏览器和服务器对URL长度的限制。
POST请求:没有固定的长度限制,适合传输大量数据。
3.数据安全性:
GET请求:数据以明文形式暴露在URL中,容易被窃听和拦截。
POST请求:数据在请求正文中传输,并可以使用加密协议(如HTTPS)进行传输,相对更安全。
4.数据缓存:
GET请求:可以被浏览器缓存,可以提高性能。
POST请求:通常不被浏览器缓存。
存储型xss:
这里看到是一个留言板,我们还是构造我们的payload:
<script>alert('xss')</script>
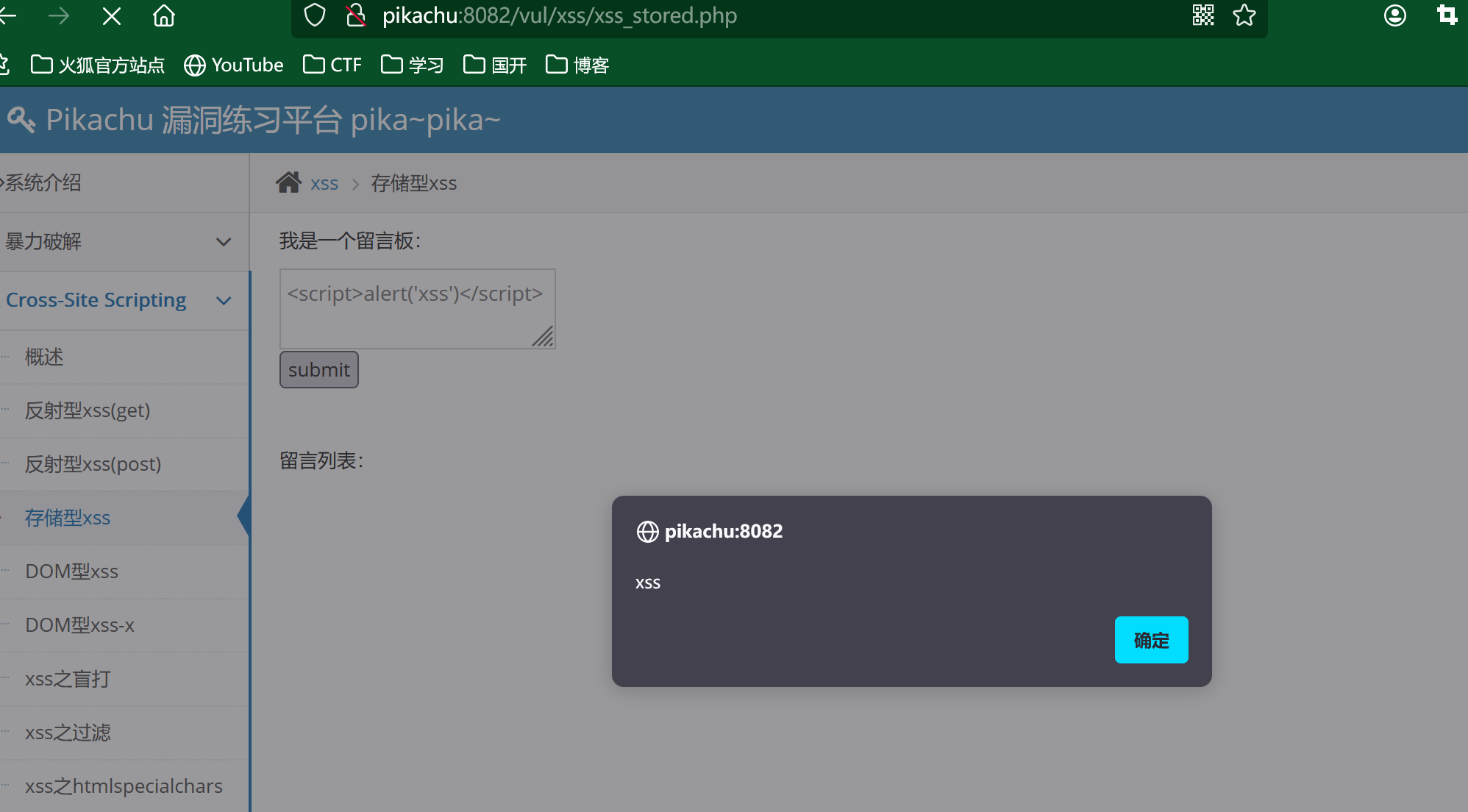
提交后,得到xss的弹窗
此时我们在留言板上输入hello,点击提交时又会得到弹窗,而且也会将我们输入的信息进行存储起来:
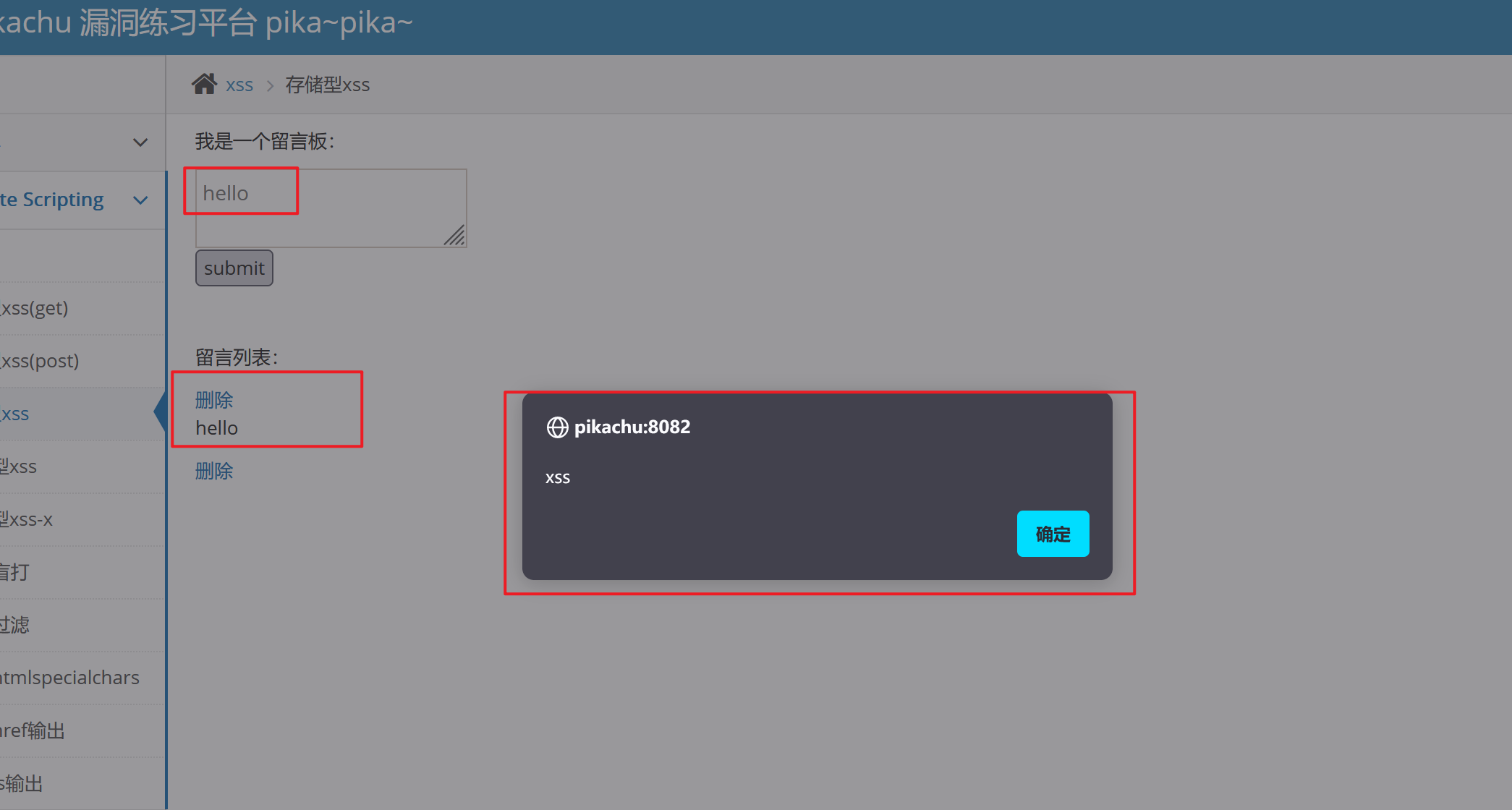
不仅是这样,我们进行页面切换,再切换回来或者刷新的时候,我们发现它的弹窗也还是在着的,这里就说明我们写入的payload已经被存储起来了
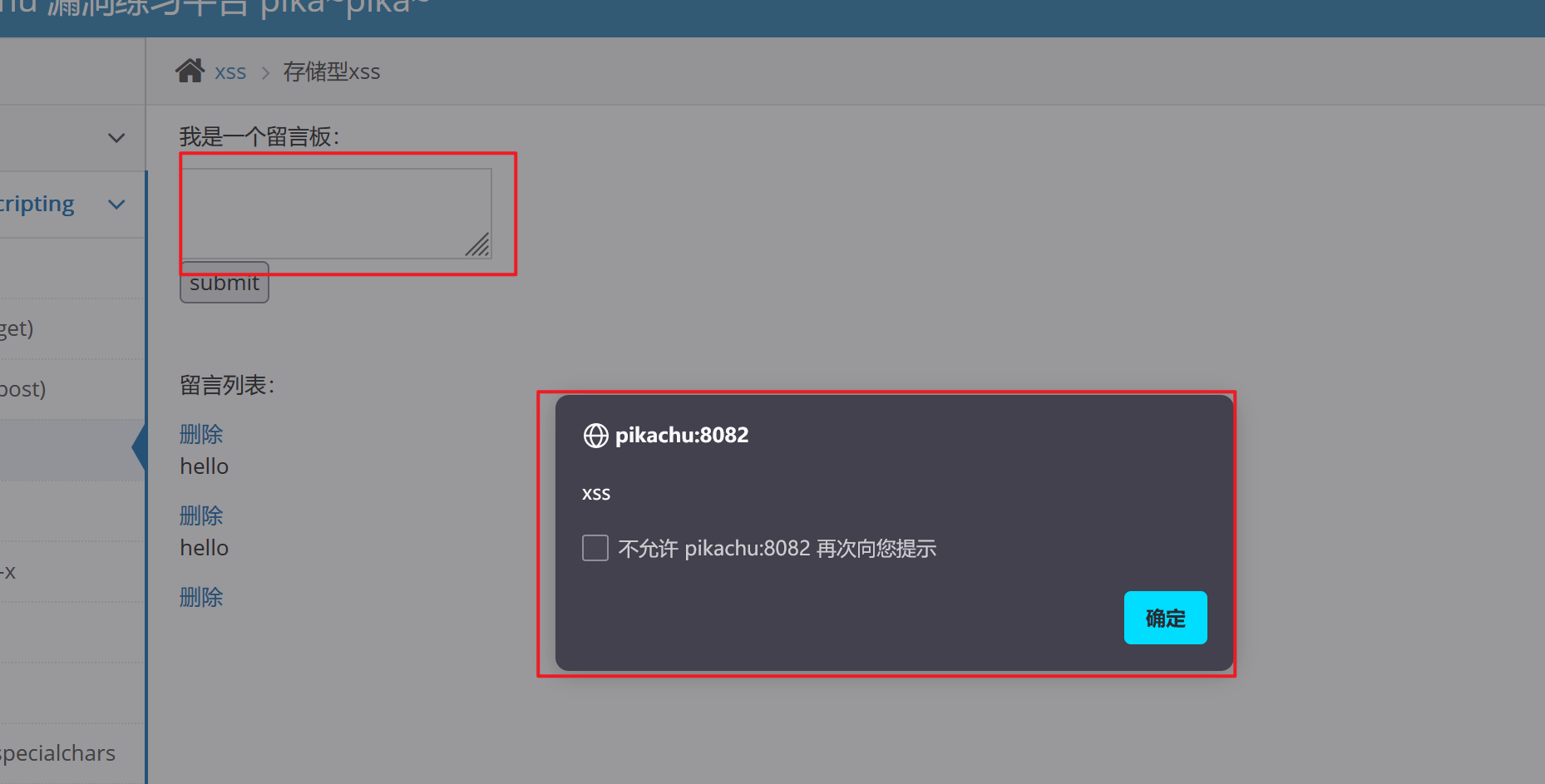
这就是存储性与反射性永久性和一次性的区别,它会永久的存储在数据库中。
DOM型xss:
这里在次之前我们要先看一下什么是DOM


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!