RNN的大致解释
大白话总结:RNN是个对时序/序列敏感的。中间的hidden layer是存在memory的。
RNN是一种比较复杂的网络结构,每一个layer还会利用上一个layer的一些信息。
比如说,我们要做slot filling的task。我们有两个句子,一个是“arrive Taipei on November 2nd”,另一个是“leave Taipei on November 2nd”。我们可以发现在第一个句子中,Taipei是destination,而第二个句子中Taipei是departure。如果我们不去考虑Taipei前一个词的话,Taipei的vector只有一个,那么同样的vector进来吐出的predict就是一致的。所以我们在做的时候就需要把前一个的结果存起来,在下一个词进来的时候用了参考。
所以这样我们就在neuron中设计一个大脑来存储这个值。所以网络长这样:
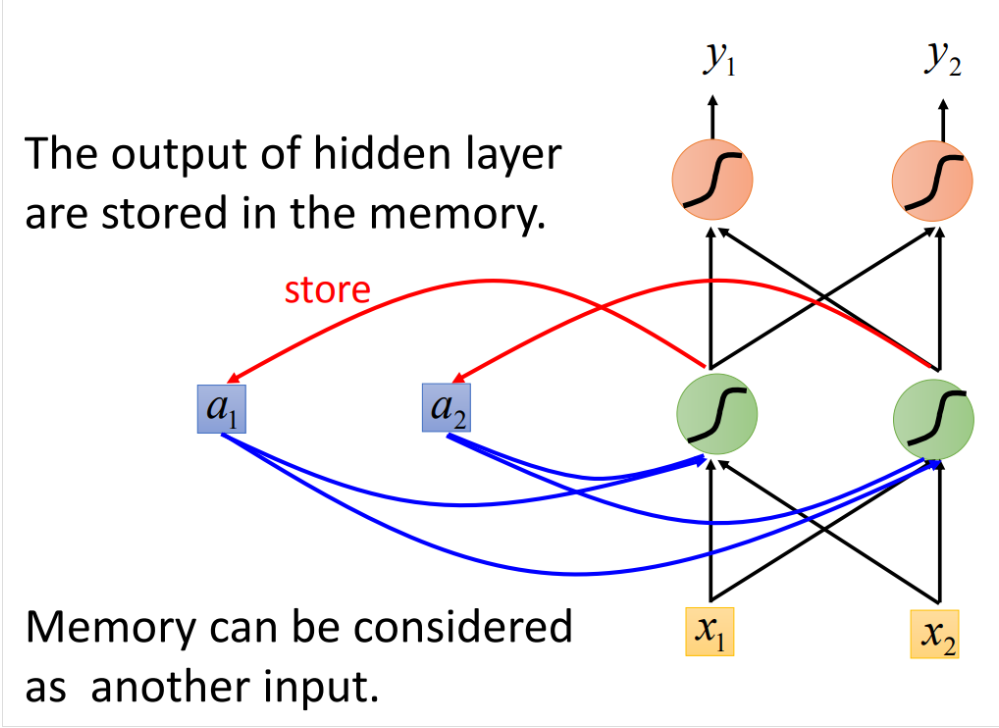
我们用这个网络来举例。假设我们每个weight都是1,每个activation都是linear的。那么我们现在有一个序列(1,1),(1,1),(2,2),那么一开始memory里面的值是(a1=0,a2=0),现在将序列第一个值传入network,我们得到(x1=1,x2=1),因为active function都是linear的,所以经过第一个hidden layer,我们输出的就是1×a1+1×a2+1×x1+1×x2,两个节点一致。所以第一个hidden layer得到(2,2),同时我们将(2,2)保存起来,更新一下得到(a1=2,a2=2),output layer是(4,4),所以得到第一个(y1=4,y2=4)。第二个input (1,1),同样计算一下,hidden layer得到的是(6,6)和(a1=6,a2=6),output layer是(12,12)。同理第三个input最后得到的output是(32,32),所最后得到的三个output序列是(4,4),(12,12),(32,32)。
那么我们可以想一下,如果现在的序列顺序变化一下,结果是否会不一致?如果现在的序列是(1,1),(2,2),(1,1),我们得到的是(4,4),(16,16),(36,36)。结果发生了变化。所以RNN对序列是敏感的,这样的特性就表示,在slot filling的task里面,我们前面的arrive和leave将会影响后面接着的Taipei的结果。
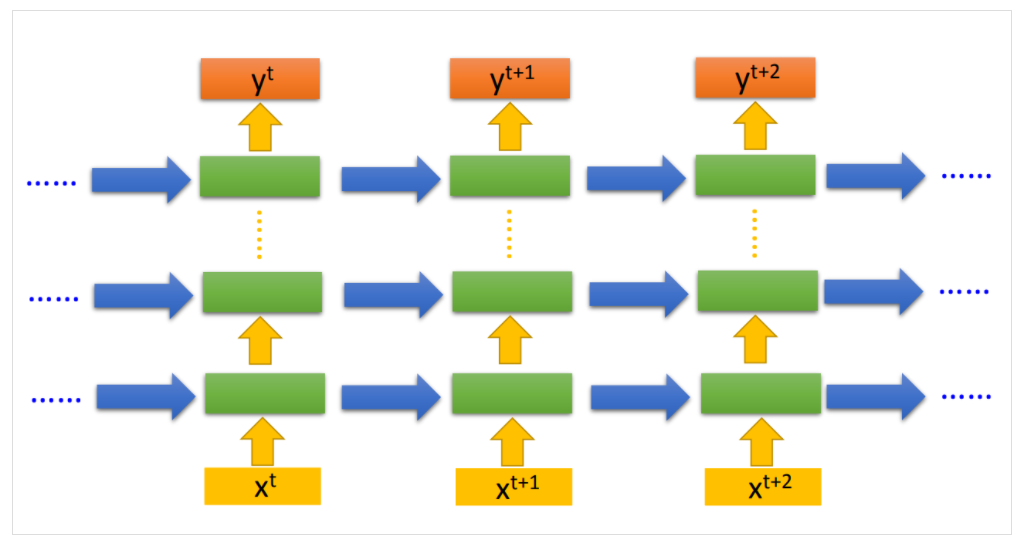
当然RNN也可以是深度的,设计上就是
另外RNN也可以双向训练:
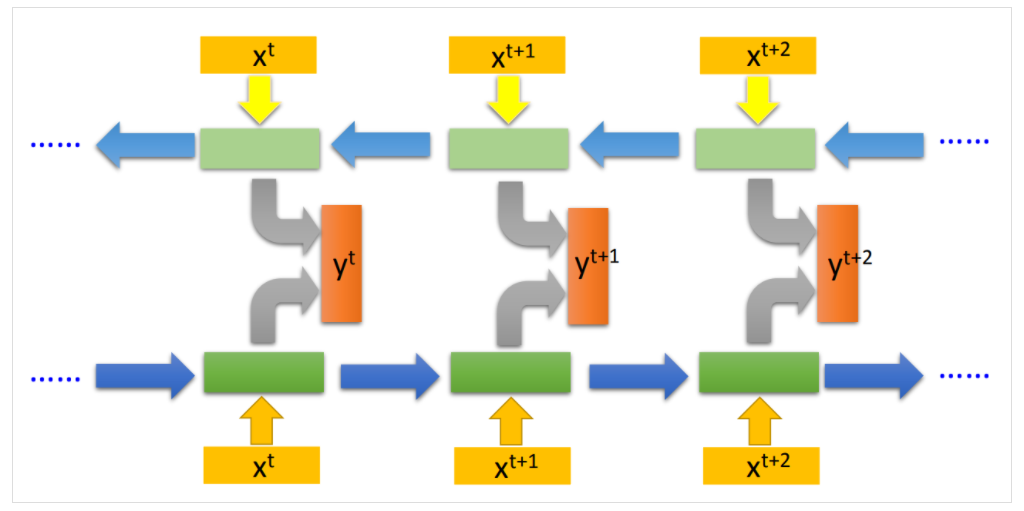
这里也需要注意一下,RNN不是训练好多个NN,而是一个NN用好多遍。所以可以看到RNN里面的这些network的参数都是一致的。
那这个是一个非常原始简单的RNN,每一个输入都会被memory记住。现在RNN的标准做法基本上已经是LSTM。LSTM是一个更加复杂的设计,最简单的设计,每一个neuron都有四个输入,而一般的NN只有一个输入。
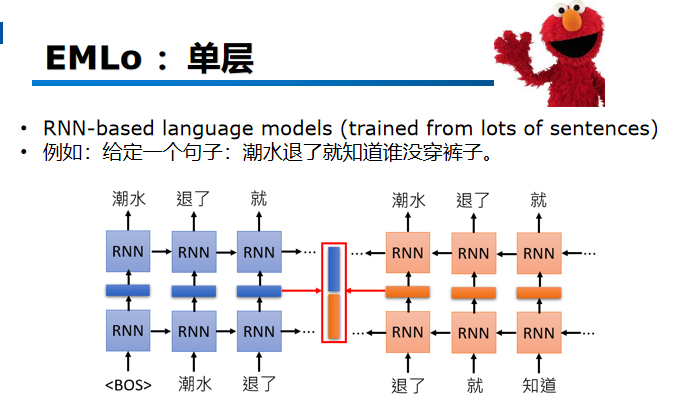
那如果用rnn的话,其实只需要大量的句子,去http上爬各种句子,不需要打lable。
比如下面这个句子:潮水退了就知道谁没穿裤子。
那么rnn就类似一种预测下一个词的模型。比如我这里输入一个BOS就输出潮水,输入潮水我就希望输出退了,这个model训练的时候,他所学习到的技能,就是去预测下一个token是谁。也就是给他很多句子,让他去学,下一个token 是什么。学完以后,我们说他的hidden lay就是输入词的Contextualized vector了,因为model中的隐藏层hidden layer就是学到的东西。