
NLP预训练模型
目录
- 开题
- 预训练模型介绍
- 词向量 word2vec
- 带上下文语义的词向量 (ELMo && Bert)
开题
-
ImageNet 预训练模型在计算机视觉领域成功 (ResNet)
ImageNet是斯坦福教授李飞飞组里标注的一个很大的数据集,有超过100万张的图片,然后他都标标出了各种各样的类别。并由此衍生了基于此的比赛。ImageNet
- 是一个超过15 million的图像数据集,大约有22,000类。
- 是由李飞飞团队从2007年开始,耗费大量人力,通过各种方式(网络抓取,人工标注,亚马逊众包平台)收集制作而成,它作为论文在CVPR-2009发布。当时人们还很怀疑通过更多数据就能改进算法的看法。
- 深度学习发展起来有几个关键的因素,一个就是庞大的数据(比如说ImageNet),一个是GPU的出现。(还有更优的深度模型,更好的优化算法,可以说数据和GPU推动了这些的产生,这些产生继续推动深度学习的发展)。
有一个相关的大赛,是做几千分类的任务,然后还有基于ImageNet的更加复杂的任务,比如说是物体识别、图像分类之类的,在这个任务上面就诞生了一大批的深度学习的模型,比如说非常有代表性的叫做ResNet.
-
ResNet
ResNet呢是一个超有152层的这样的一个非常深度的卷积神经网络。ResNet的作者何凯明也因此摘得CVPR2016最佳论文奖。深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的一件里程碑事件,可以看下ResNet在ILSVRC和COCO 2015上的战绩:ResNet在ILSVRC和COCO 2015上的战绩

令人惊喜的是,该模型不止于在ImageNet上的优秀表现,人们发现他还可以做其他的Downstream Task,也就是其他的下游任务。其效果可以迁移。这就是种预训练模型,它并不仅仅是说应用在它本身训练的任务上面,它可以作为一个迁移学习的方法迁移到一些别的任务当中去。 -
Collobert et al.,Natural Language Processing(Almost)from Scratch,2011很多人NLP领域的研究者认为这是一篇划时代的文章。
这是一篇非常重量级的文章,在这个NLP领域有一篇叫做Natural Language Processing(Almost)from Scratch。前几年的时候有一个采访,我记得是采访20位NLP领域里面的专家,都是一些各个大公司的研究员或者是一些学校的教授,然后他们就有人就采访他们说问你认为就是当今这10年来或者这几十年来,最重要的一篇LP的文章是什么?然后有很多人提了这篇文章,natural language processing from scratch。
这篇文章的厉害之处在于:
- 在11年的时候创新性的用了很多深度学习的方法来解决NLP的问题。-- 这在三年后引起了大量关注。
- 在NLP中引入了词向量的概念。-- 单词转成词向量,我们后续很多操作都是基于这些词向量做的一些模型的架构。
总结:在之前的一些imagenet的比赛中,alexNet的文章等用了深度学习取得了冠军,让大家认识到深度学习是个非常厉害的东西,后来ResNet有152层神经网络后,人们就更加关注DL,然后这篇文章就把DL引入到了NLP领域。
词向量
最开始的语言表示
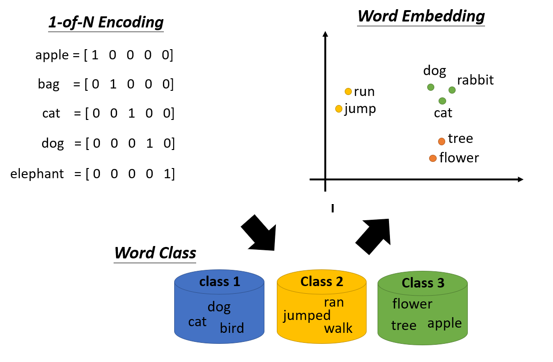
文字的向量表示
word2vec
文本:非结构化数据/不可计算 转换》 向量:结构化数据/可计算
那word embedding实际上可以做到通过读海量的文档内容,然后理解单词的意思。比如 The cat sat on the pat和The dog sat on the pat这两句话,cat和dog是接近的。
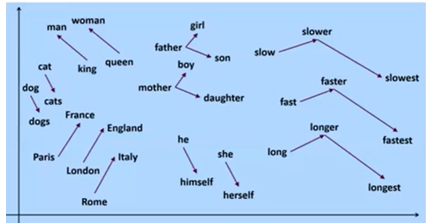
评估方法:单词相似度,词向量的几何规律
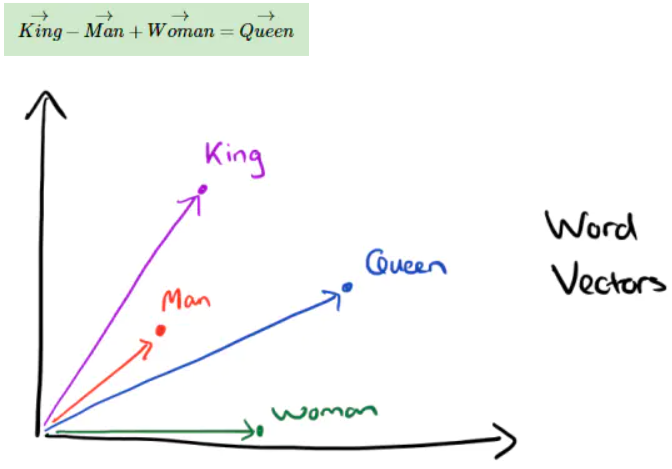
word2vec 还发现有趣的单词类比推理现象,即 V(king) - V(man) + V(woman) ≈ V(queue)
词向量基本思想是通过训练将每个词映射成 K 维实数向量后,可通过词之间的距离(比如 cosine 相似度、欧氏距离等)来判断它们之间的语义相似度。
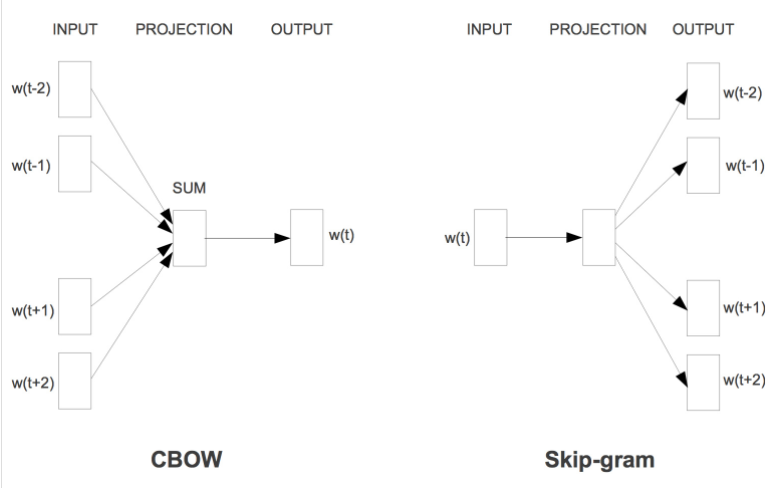
先对词随机初始化为N维向量,然后Word2vec通过两种种训练模式,使其学习到一些上下文含义。
- 如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』
- 而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
3.带上下文语义的词向量
3.1 ELMO
- 三层双向LSTM语言模型 Peters et al.,Deep contextualized
word representations
方法
在EMLo中,他们使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。
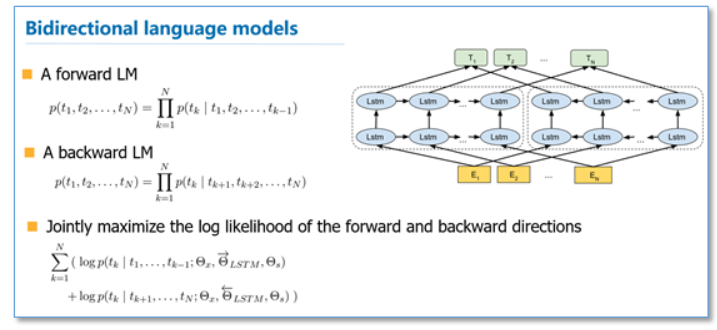
- 词向量拥有了Context 信息
在预训练好这个语言模型之后,ELMo就是根据下面的公式来用作词表示,其实就是把这个双向语言模型的每一中间层进行一个求和。最简单的也可以使用最高层的表示来作为ELMo。

然后在进行有监督的NLP任务时,可以将ELMo直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。总结一下,不像传统的词向量,每一个词只对应一个词向量,ELMo利用预训练好的双向语言模型,然后根据具体输入从该语言模型中可以得到上下文依赖的当前词表示(对于不同上下文的同一个词的表示是不一样的),再当成特征加入到具体的NLP有监督模型里。
实验
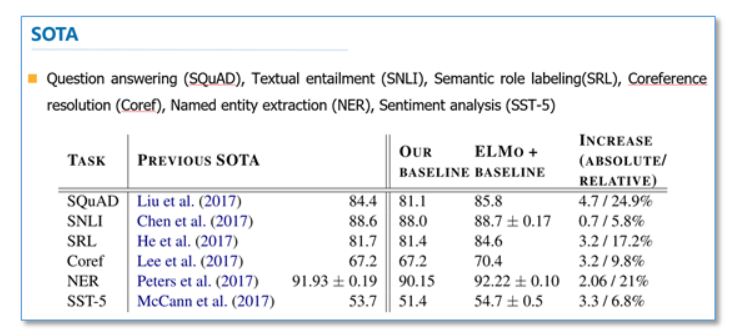
这里我们简单看一下主要的实验,具体实验还需阅读论文。首先是整个模型效果的实验。他们在6个NLP任务上进行了实验,首先根据目前每个任务搭建了不同的模型作为baseline,然后加入ELMo,可以看到加入ELMo后6个任务都有所提升,平均大约能够提升2个多百分点,并且最后的结果都超过了之前的先进结果(SOTA)。
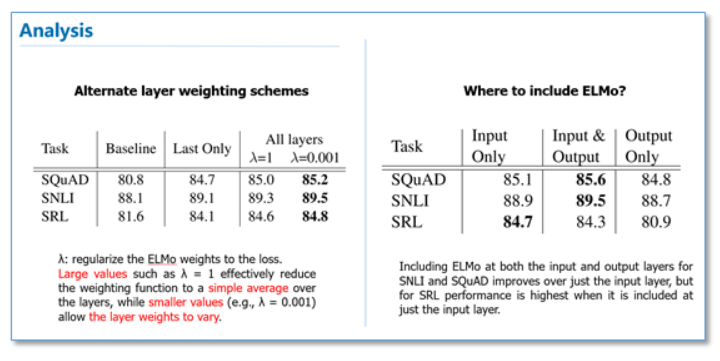
在下面的分析实验中,我们可以看到使用所有层的效果要比只使用最后一层作为ELMo的效果要好。在输入还是输出上面加EMLo效果好的问题上,并没有定论,不同的任务可能效果不一样。
3.2 BERT
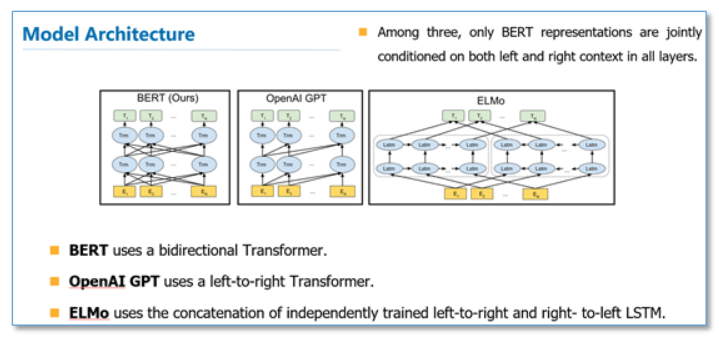
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。这篇论文把预训练语言表示方法分为了基于特征的方法(代表ELMo)和基于微调的方法(代表OpenAI GPT)。而目前这两种方法在预训练时都是使用单向的语言模型来学习语言表示。
这篇论文中,作者们证明了使用双向的预训练效果更好。其实这篇论文方法的整体框架和GPT类似,是进一步的发展。具体的,他们BERT是使用Transformer的编码器来作为语言模型,在语言模型预训练的时候,提出了两个新的目标任务(即遮挡语言模型MLM和预测下一个句子的任务),最后在11个NLP任务上取得了SOTA。

方法
在语言模型上,BERT使用的是Transformer编码器,并且设计了一个小一点Base结构和一个更大的Large网络结构。

对比一下两种语言模型结构,BERT使用的是Transformer编码器,由于self-attention机制,所以模型上下层直接全部互相连接的。而而ELMo使用的是双向LSTM,虽然是双向的,但是也只是在两个单向的LSTM的最高层进行简单的拼接。所以作者们任务只有BERT是真正在模型所有层中是双向的。
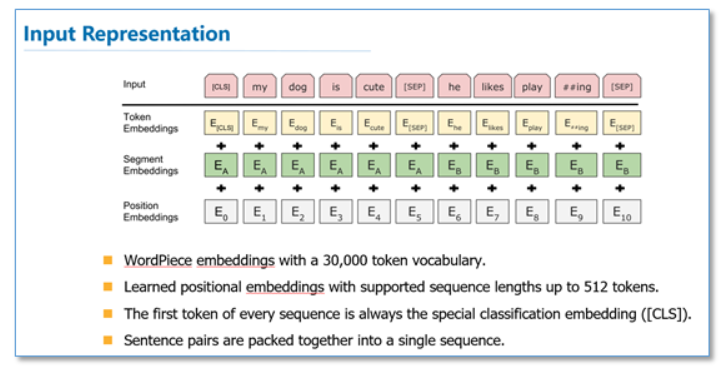
而在模型的输入方面,BERT做了更多的细节,如下图。他们使用了WordPiece embedding作为词向量,并加入了位置向量和句子切分向量。并在每一个文本输入前加入了一个CLS向量,后面会有这个向量作为具体的分类向量。
在语言模型预训练上,他们不在使用标准的从左到右预测下一个词作为目标任务,而是提出了两个新的任务。第一个任务他们称为MLM,即在输入的词序列中,随机的挡上15%的词,然后任务就是去预测挡上的这些词,可以看到相比传统的语言模型预测目标函数,MLM可以从任何方向去预测这些挡上的词,而不仅仅是单向的。但是这样做会带来两个缺点:1)预训练用[MASK]提出挡住的词后,在微调阶段是没有[MASK]这个词的,所以会出现不匹配;2)预测15%的词而不是预测整个句子,使得预训练的收敛更慢。但是对于第二点,作者们觉得虽然是慢了,但是效果提升比较明显可以弥补。

对于第一点他们采用了下面的技巧来缓解,即不是总是用[MASK]去替换挡住的词,在10%的时间用一个随机词取替换,10%的时间就用这个词本身。

而对于传统语言模型,并没有对句子之间的关系进行考虑。为了让模型能够学习到句子之间的关系,作者们提出了第二个目标任务就是预测下一个句子。其实就是一个二元分类问题,50%的时间,输入一个句子和下一个句子的拼接,分类标签是正例,而另50%是输入一个句子和非下一个随机句子的拼接,标签为负例。最后整个预训练的目标函数就是这两个任务的取和求似然。

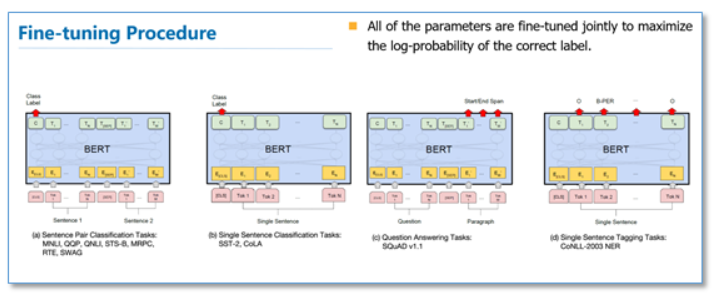
在微调阶段,不同任务的模型如下图,只是在输入层和输出层有所区别,然后整个模型所有参数进行微调。
实验
下面我们列出一下不同NLP上BERT的效果。
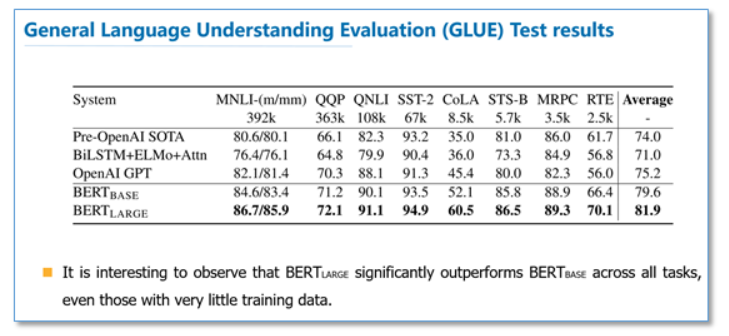
GLUE结果:
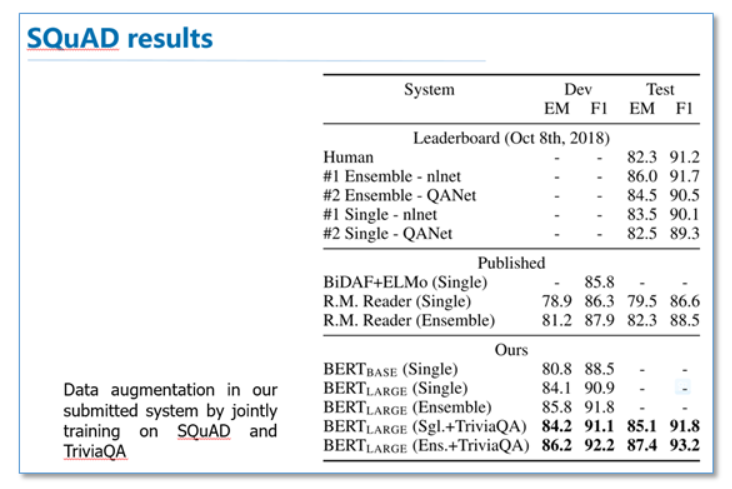
QA结果:
实体识别结果:

可以看到在这些所有NLP任务上,BERT都取得了SOTA,而且相比EMLo和GPT的效果提升还是比较大的。
在预训练实验分析上,可以看到本文提出的两个目标任务的作用还是很有效的,特别是在MLM这个目标任务上。
总结
最后进行简单的总结,和传统的词向量相比,使用语言模型预训练其实可以看成是一个句子级别的上下文的词表示,它可以充分利用大规模的单语语料,并且可以对一词多义进行建模。而且从后面两篇论文可以看到,通过大规模语料预训练后,使用统一的模型或者是当成特征直接加到一些简单模型上,对各种NLP任务都能取得不错的效果,说明很大程度上缓解了具体任务对模型结构的依赖。在目前很多评测上也都取得了SOTA。ELMo也提供了官网供大家使用。但是这些方法在空间和时间复杂度上都比较高,特别是BERT,在论文中他们训练base版本需要在16个TGPU上,large版本需要在64个TPU上训练4天,对于一般条件,一个GPU训练的话,得用上1年。还有就是可以看出这些方法里面都存在很多工程细节,一些细节做得不好的话,效果也会大大折扣。

