CocosCreator ScrollView性能优化
本文基于CocosCreator2.1.2版本
原文链接:https://blog.csdn.net/zzx023/article/details/99851564
CocosCreator的ScrollView组件是游戏开发中的常用组件,我们经常在一些商城界面、排行榜界面、任务列表、背包系统等模块中会使用到它,同时它也是开销非常大的地方。当我们的需要显示的条目比较多时,单纯简单的去使用的话,性能很不好。CocosCreator只是实现了最基本的ScrollView,但相应的优化还需要我们根据项目的情况来进行针对性的优化。
当数据量比较大时,我们很容易碰到两个问题:
DrawCall的数量比较高,渲染性能比较低
整个scrollview的节点数太多,导致隐藏或显示界面时的onEnable和Disable开销比较大
比如下面的这个界面(demo中的ScrollView1场景)
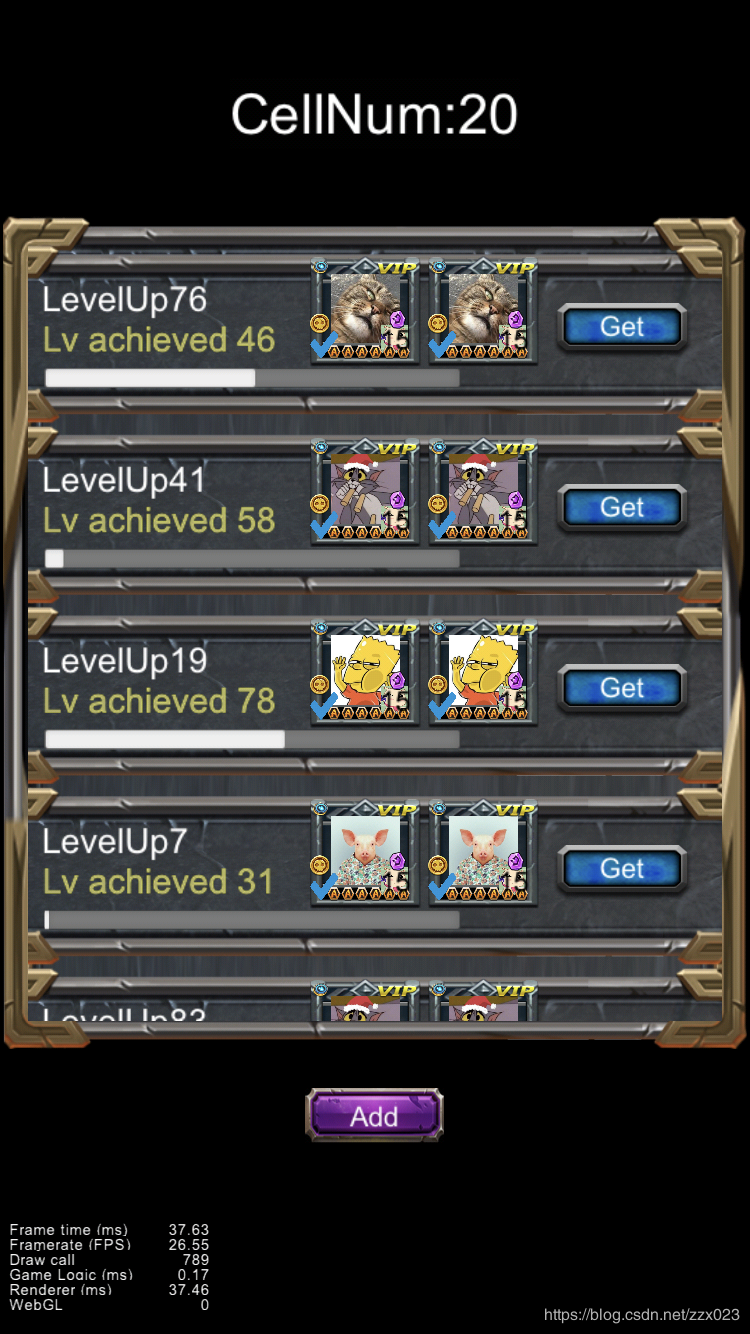
ScrollView当中有20个Cell,总共的DrawCall达到了790,单个Cell大概有50个节点,总共就有差不多1000个节点,这时我们的开销会变得非常的大。
接下来我们进行一些常规的优化:
首先我们要做的就是合并渲染批次,降低DrawCall,提升渲染性能, 使用自动图集或使用TexturePacker对碎图进行打包处理,这样的话可以让多个Sprite渲染的纹理都是同一张图集图片,这样的话就可以合并这些sprite的渲染批次,减少DrawCall以及CPU的运算开销。
这里我使用了AutoAtlas来实现,关于AutoAtlas的使用可以参考文档:Auto-atlas Asset
让我们来看下效果:

同样是20个cell,DrawCall降低到了556,相比较之前有了比较明显的降低。
不过这还不够,如果你是在Google的Chrome浏览器上进行调试的话,推荐你可以使用spector.js这个插件,通过这个插件你可以看到每个DrawCall对于纹理的处理情况。
对于原生开发的话,我们可以使用XCode中的GPU analysis功能
开启dynamicAtlas功能,开启这个功能你可以在main.js中的window.boot()方法内加入下面的两行代码即可:


开启之后我们可以看到DrawCall大幅下降,部分DrawCall已经合并
接下来是对于Label的处理。
Label的处理跟前面我们的优化方案选择有关系。
如果我们使用了自动图集或TexturePacker对碎图进行合并的话,我们可以选择Label使用bmfont字体,而不是使用系统字体。同时我们将bmfont使用到的纹理资也一起合并到图集资源中。
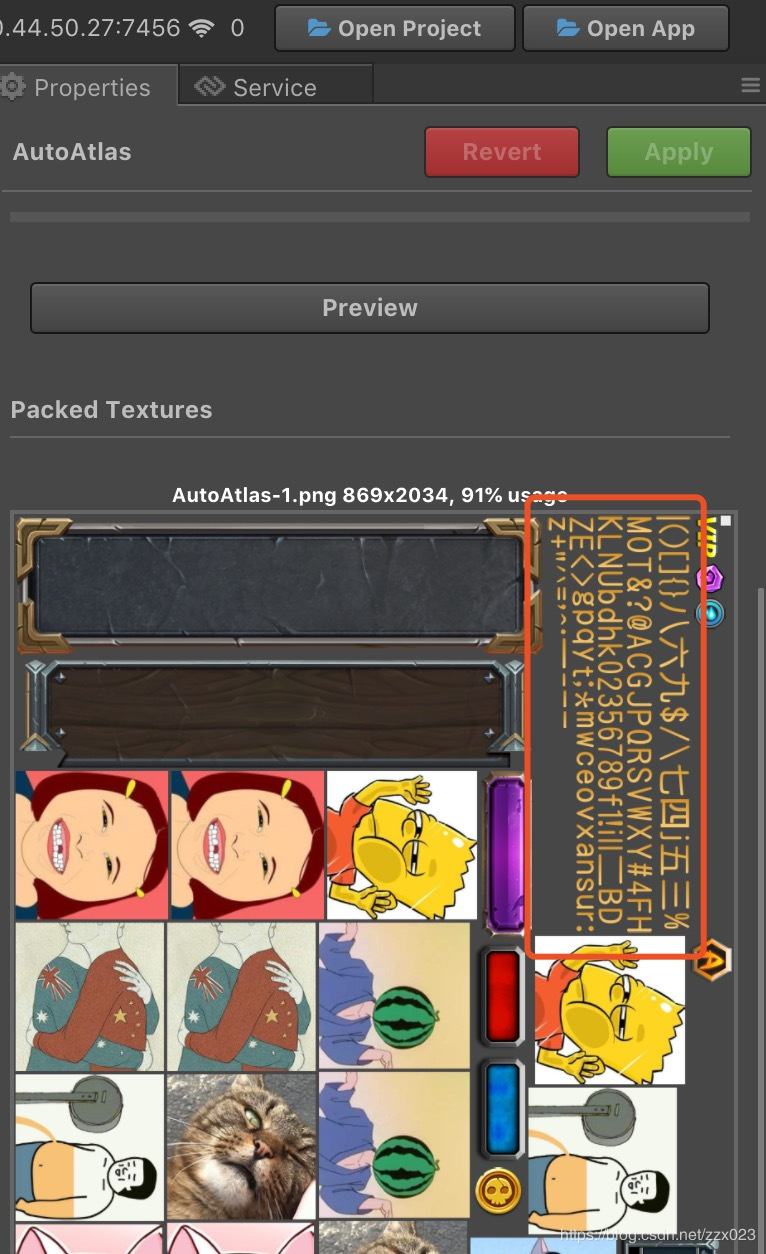
可以看到我们的DrawCall又进一步的降低了,目前运行的效果是330个DrawCall
如果我们前面使用的是dynamicAtlas的功能,那么我们可以选择Label使用系统字体,同时我们将Label的CacheMode属性更改为BITMAP

这个模式下会将Label的纹理当作一个Sprite纹理,并且参与到dynamicAtlas中去。这样就可以跟sprite的纹理进行合批处理

从这两个方案可以看出来,都是想办法对DrawCall进行合并批处理,只是使用dynamicAtlas的话更加的智能,同时也可以更好的适应复杂的节点结构。但需要注意的是,dynamicAtlas会有额外的CPU计算以及动态纹理的绘制开销,因此需要根据项目的情况去选择使用。
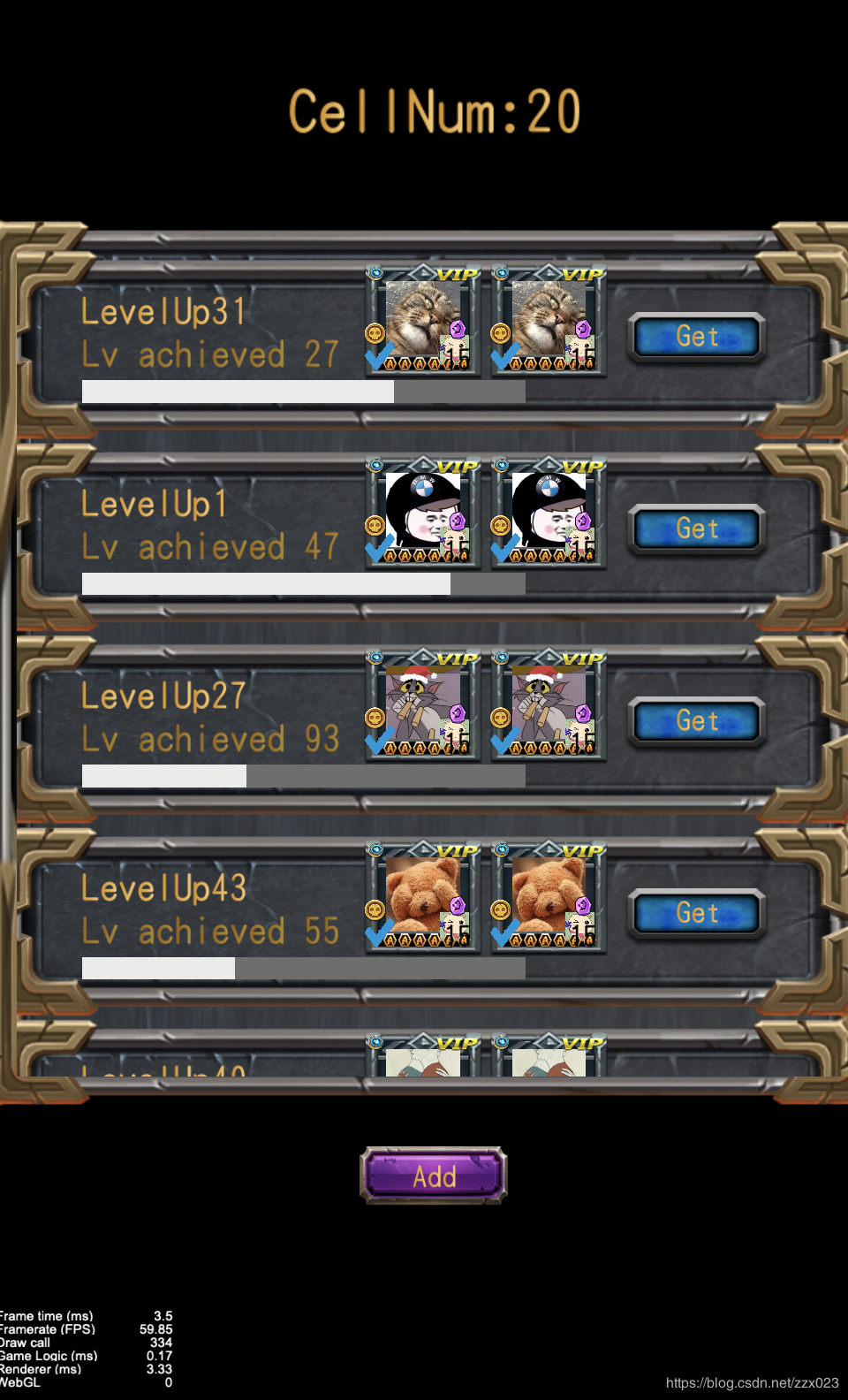
通过cell的位置进行计算,让显示范围外节点的opacity为0,即不显示,减少dc
在可视范围外的节点,本身我们就不可见,所以就不需要它再进行绘制,平白增加Drawcall。我们可以将这些可视范围外节点的opacity属性设置为0,从而避免绘制,可以有效的降低DrawCall
update (dt) { var viewRect = cc.rect(- this.view.width / 2, - this.content.y - this.view.height, this.view.width, this.view.height); for (let i = 0; i < this.content.children.length; i++) { const node = this.content.children[i]; if (viewRect.intersects(node.getBoundingBox())) { node.opacity = 255; } else { node.opacity = 0; } } }
这里我是将判断逻辑放在了Update函数中,你也可以将这段方法放到ScrollView的滑动回调中去,这样的话不用每帧都计算,只在需要的时候才会去进行计算,节约一些CPU的开销。最终效果我们可以看到,在启用dynamicAtlas的方案上,DrawCall可以降低到68,相比较最原始的790个DrawCall,效果显著。
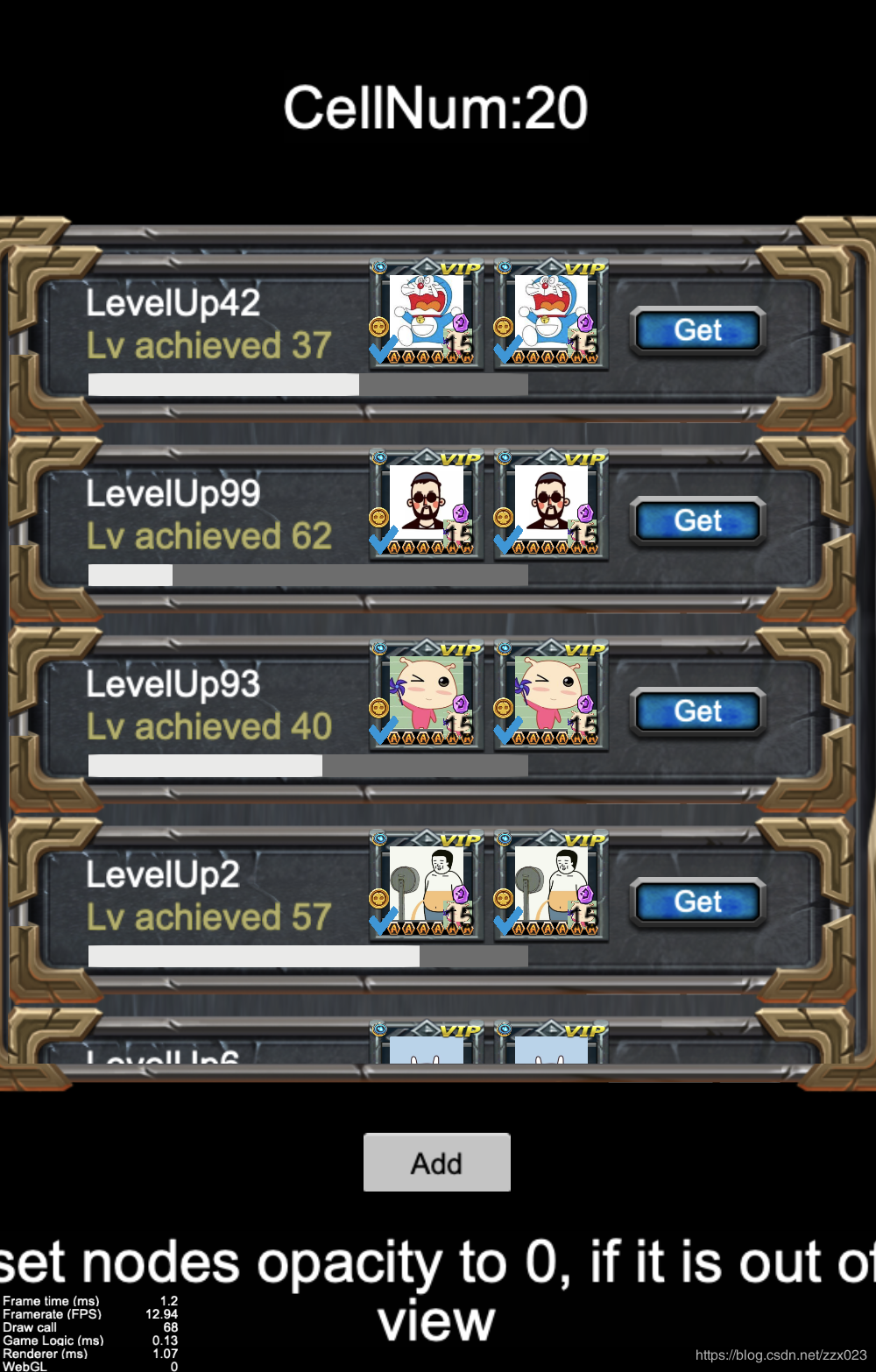
通过对资源的处理,减少cell中使用mask组件的数量,尽量不使用mask组件
由于mask组件需要在 stencil 和 content 前后都添加修改 gl 状态的 render command,因此使用mask会打断我们的DrawCall批处理。因此对于一些特殊的显示,例如圆角的icon等,如果条件允许,尽量不要使用mask组件来进行处理,而是通过对资源进行处理达到同样的效果。
目前mask组件、spine组件、dragonBone组件都会打断批处理,在节点结构上我们要避免被打断的情况发生。

在这个demo当中,每一个icon都有一个使用了mask组件的子节点。我们去除它,效果如下:
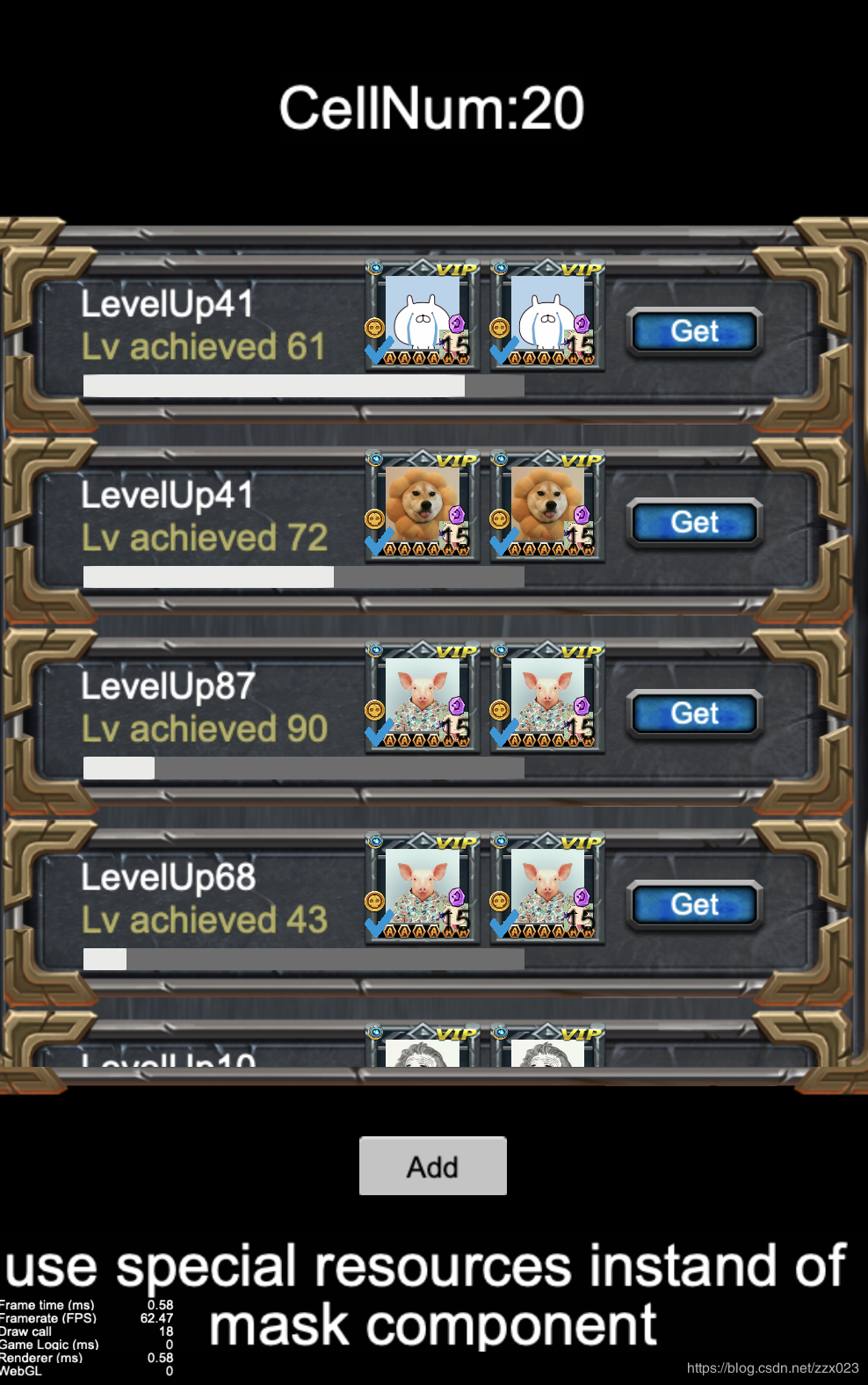
最终就只有18个DrawCall,基本上是很极限的DrawCall优化了。毕竟ScrollView本身就有一个mask组件,这个组件我们无法避免,必须要使用。
对cell节点进行复用,减少节点数,这一块改动比较大. 前面我们都是对DrawCall的优化,但实际的节点数量还是很多。当显示或隐藏这个界面时,大量的节点会带来大量的enable和disable的开销。因此我们通过复用节点,根据滑动情况,实时更新cell位置以及显示内容,从而减少节点的数量。
可以参考CocosCreator官方示例中的ListView示例,原理如下:
具体代码可以参考demo工程中的ScrollView3场景的实现,最终效果如下:

20个Cell的ScrollView,实际上只是7个Cell节点在不停的复用显示,从而表现出来的。与之前的效果以及DrawCall相同,但实际使用的节点数大大降低,大约有300个节点,相比较之前的1000个节点大幅降低。
以上就是ScrollView在性能优化当中的一些常用手段。当然也有一些非常用的手段,这些通常只适用于特殊的项目需求,在这里就不一一介绍了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号