
事务使用场景★★★★★
事务的使用场景
本文完全照搬CSDN博主 斗者_2013 原创文章:事务使用场景详解
原文链接:(1条消息) 事务使用场景详解_斗者_2013的博客-CSDN博客_事务的应用场景
仅用作个人学习,特此声明
1、问题描述
事务在开发过程大家应该都经常使用,但是事务具体有哪些使用场景?什么时候需要使用事务,什么时候不需要添加事务呢?一个都是查询操作的方法是否需要添加事务?
最常见的一种回答:
如果一个方法中,执行了多个insert,update,delete操作就需要添加事务。
这样的答案,我最多只能给60分,因为可以说只要是个程序员基本都知道,完全不能体现对事务认识的深度。
2、事务是什么?
Transactions are atomic units of work that can be committed or rolled back. When a transaction makes multiple changes to the database, either all the changes succeed when the transaction is committed, or all the changes are undone when the transaction is rolled back
事务是由一组SQL语句组成的原子操作单元,其对数据的变更,要么全都执行成功(Committed),要么全都不执行(Rollback)。
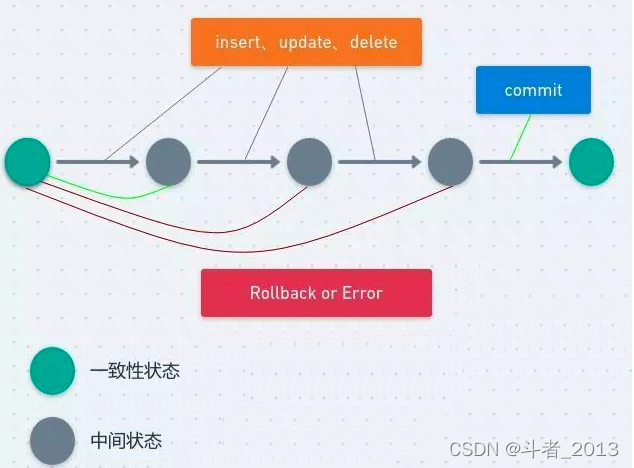
3、事务特性
InnoDB实现的数据库事务具有常说的ACID属性,即原子性(atomicity),一致性(consistency)、隔离性(isolation)和持久性(durability)。
原子性:事务被视为不可分割的最小单元,所有操作要么全部执行成功,要么失败回滚(即还原到事务开始前的状态,就像这个事务从来没有执行过一样)一致性:在成功提交或失败回滚之后以及正在进行的事务期间,数据库始终保持一致的状态。如果正在多个表之间更新相关数据,那么查询将看到所有旧值或所有新值,而不会一部分是新值,一部分是旧值隔离性:事务处理过程中的中间状态应该对外部不可见,换句话说,事务在进行过程中是隔离的,事务之间不能互相干扰,不能访问到彼此未提交的数据。这种隔离可通过锁机制实现。有经验的用户可以根据实际的业务场景,通过调整事务隔离级别,以提高并发能力持久性:一旦事务提交,其所做的修改将会永远保存到数据库中。即使系统发生故障,事务执行的结果也不能丢失
4、典型场景
4.1 原子性保障——多个insert,update,delete操作
这个应该是大家最熟悉的一种场景,保证多个insert,update,delete操作要么全都执行成功(Committed),要么全都不执行(Rollback)。
原子性的特点:
- 1、针对单事务的控制
- 2、针对多个insert,update,delete操作
示例:
执行方法,添加多个商品。添加事务控制,保障所有商品要么全部添加成功,要么全部添加失败。
@Transactional(rollbackFor = Exception.class)
public void addList(List list){
list.forEach(e->{
goodsStockMapper.add(e);
});
}
4.2 隔离性保障——幻读、不可重复、脏读
事务处理过程中的中间状态应该对外部不可见,换句话说,事务在进行过程中是隔离的,事务之间不能互相干扰,不能访问到彼此未提交的数据。
幻读、不可重复需要在同一个事务中进行多次相同的查询才能体现,真是项目中需要这样操作的场景很少。
脏读就是读到其他事务没有提交的数据,只要隔离级别不是读未提交(Read Uncommitted)就不会出现。
所以相比对幻读、不可重复、脏读这些开发过程中基本不会遇到的问题,我们更应该关注事务的隔离性对业务产生的影响。
事务的默认隔离级别可重复读(Repeatable Read)基本满足日常开发90%的场景,一般不建议调整。
隔离性的特点:
1、针对多事务间数据可见性的控制。
2、控制加锁的粒度和加锁、释放锁的时机,提高事务的并发能力。
示例场景:
读到其他事务未提交数据,导致超卖。
1、幻读:
SELECT count(1) FROM books WHERE price < 100;
/* 时间顺序:1,事务: T1 */
INSERT INTO books(name,price) VALUES ('深入理解Java虚拟机',90); COMMIT;
/* 时间顺序:2,事务: T2 */
SELECT count(1) FROM books WHERE price < 100;
/* 时间顺序:3,事务: T1 */
可串行化(Serializable)会对事务所有读、写的数据全都加上读锁、写锁和范围锁,所以由于T1事务对价格小于100的范围内的数据都加读锁、写锁和范围锁,所以T2不能插入价格为90的数据,所以不存在幻读的情况。
2、不可重复读
SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */
UPDATE books SET price = 110 WHERE id = 1; COMMIT; /* 时间顺序:2,事务: T2 */
SELECT * FROM books WHERE id = 1; COMMIT; /* 时间顺序:3,事务: T1 */
假如隔离级别是可重复读的话,由于数据已被事务 T1 施加了读锁且读取后不会马上释放,所以事务 T2 无法获取到写锁,更新就会被阻塞,直至事务 T1 被提交或回滚后才能提交。
读已提交对事务涉及的数据加的写锁会一直持续到事务结束,但加的读锁在查询操作完成后就马上会释放。
读已提交的隔离级别缺乏贯穿整个事务周期的读锁,无法禁止读取过的数据发生变化,此时事务 T2 中的更新语句可以马上提交成功,这也是一个事务受到其他事务影响,隔离性被破坏的表现。
事实上由于Mysql的MVCC机制,可重复读(Repeatable Read)和读已提交(Read Committed)在读的时候都不会加锁。如果读取的行正在执行delete或者update操作,这时读操作不会因此去等待行上锁的释放。相反的,InnoDB存储引擎会去读取行的一个快照数据。实现了对读的非阻塞,读不加锁,读写不冲突。
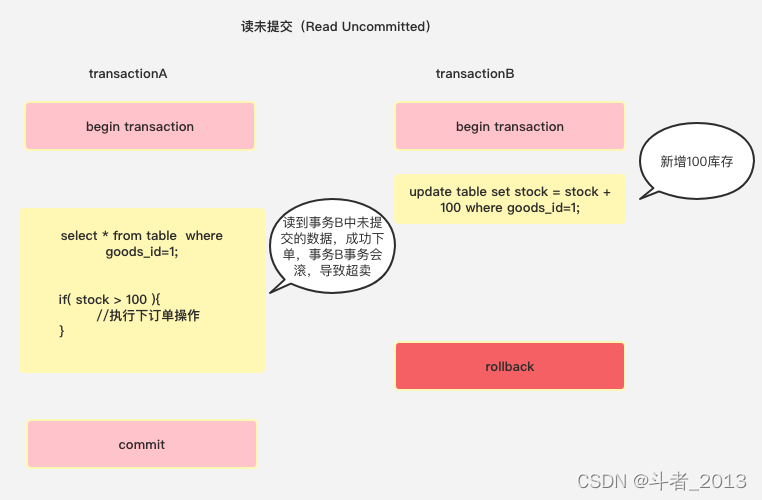
3、读未提交
读未提交(Read Uncommitted):对事务涉及的数据只加写锁,会一直持续到事务结束,但完全不加读锁。
SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */
/* 注意没有COMMIT */
UPDATE books SET price = 90 WHERE id = 1; /* 时间顺序:2,事务: T2 */
/* 这条SELECT模拟购书的操作的逻辑 */
SELECT * FROM books WHERE id = 1; /* 时间顺序:3,事务: T1 */
ROLLBACK;
该级别下,读取数据前不用先获取读锁。由于T1读取数据时不需要去加读锁,所以T2修改数据后,不用等在commit提交释放写锁,T1立刻就能读取到修改后的数据。
读未提交在数据上完全不加读锁,这反而令它能读到其他事务加了写锁的数据,即上述事务 T1 中两条查询语句得到的结果并不相同。如果你不能理解这句话中的“反而”二字,请再重读一次写锁的定义:写锁禁止其他事务施加读锁,而不是禁止事务读取数据,如果事务 T1 读取数据并不需要去加读锁的话,就会导致事务 T2 未提交的数据也马上就能被事务 T1 所读到。这同样是一个事务受到其他事务影响,隔离性被破坏的表现。
4.3 一致性保障——针对多个表的查询统计
很多同学一直认为,一个方法中如果都是查询请求,就不需要添加事务控制。那么真的是这样吗?
假设现在有3个表A,B,C,由于业务请求量非常高,导致3个表一直有新的数据不停的写入。
现在要求分别对3个表中的数据进行聚合统计,然后进行指标计算。
大致逻辑:
select A指标 from 表A; //步骤1
select B指标 from 表B; //步骤2
select C指标 from 表C; //步骤3
汇总指标 = A指标 + B指标 + C指标; //步骤4
如果按照这样去统计,当查询完A指标后,由于业务在正常进行,表B和表C仍然有数据写入,所以最后会导致查询的A,B,C3个指标,并不是同一时刻的,这样的汇总指标也就没有了参考意义。

这个时候就需要对统计的方法添加事务,保证数据的一致性。
一致性:在成功提交或失败回滚之后以及正在进行的事务期间,数据库始终保持一致的状态。如果正在多个表之间更新相关数据,那么查询将看到所有旧值或所有新值,而不会一部分是新值,一部分是旧值。
@Transactional(rollbackFor = Exception.class,isolation = Isolation.REPEATABLE_READ,readOnly = true)
public int count(){
select A指标 from 表A;
select B指标 from 表B;
select C指标 from 表C;
汇总指标 = A指标 + B指标 + C指标;
}
说明:
对汇总统计的方法添加事务控制,且指定事务的隔离级别为可重复读Isolation.REPEATABLE_READ,并设置只读属性readOnly对查询进行优先。
可重复读:总是读取 CREATE_VERSION 小于或等于当前事务 ID 的记录。
由于启动了可重复读事务控制,所以当在统计时间点T1发请统计请求时,针对A,B,C3个表的查询总是只能读取 CREATE_VERSION 小于或等于当前事务 ID 的记录。这样在统计时间点T1后面新增的数据就不会影响我们的查询统计,通过事务将3个表的统计查询拉齐到了同一时间线上。
4.4 悲观锁
如果一个方法中就只有一个简单的查询语句,是否需要添加事务控制?
还真不能简单的say no。
场景:
利用数据库悲观锁实现分布式锁。
@Transactional(rollbackFor = Exception.class)
public void sumGoods(Integer goodsId, Integer num) {
//1、利用for update加悲观锁,也就是写锁,由于写锁具有排他性,保证分布式环境下也可以串行化执行
GoodsStock goodsStock = goodsStockMapper.getStockForUpdate(goodsId);
//2、计算
int sum = redisUtil.get(goodsId) + num;
redisUtil.set(goodsId,sum)
}
说明:
悲观锁一定要配合事务来使用,这样才能保证整个事务方法执行完毕后,自动释放锁。
5、总结
本文主要是对事务的使用场景进行来说明。
1、典型场景,一个方法中包含多个insert,update,delete操作通过添加事务保证原子性,要么全部成功,要么全部失败。
2、还可以通过事务的隔离级别,控制多事务间数据的可见性。
3、针对多个表的查询统计,可以通过添加事务控制将统计时间拉起到同一时间节点,保证数据的一致性。
4、悲观锁必须配合事务使用。
总的来说,事务的使用场景是对事务特性ACID更深层次的认识和运用的一些解读。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号