

仿scikit-learn模式写的kNN算法
一、什么是kNN算法
k邻近是指每个样本都可以用它最接近的k个邻居来代表。
核心思想:如果一个样本在特征空间中的k个最相邻的样本中大多数属于一个某类别,则该样本也属于这个类别。
二、将kNN封装成kNNClassifier
1、训练样本的特征在二维空间中的表示
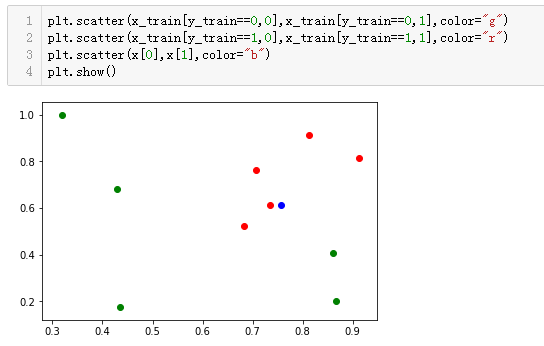 、
、
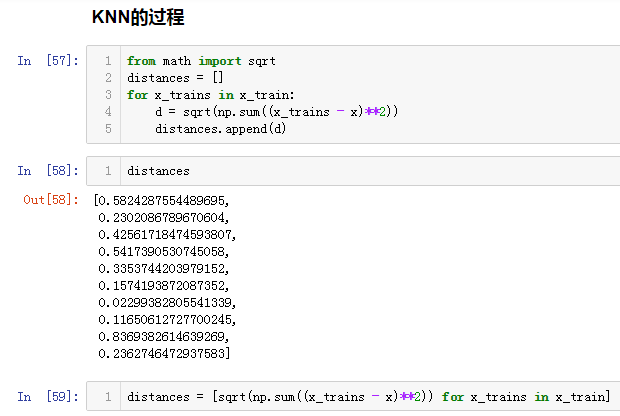
2、kNN的训练过程如下图
3、完整代码(kNN.py)

import numpy as np from math import sqrt from collections import Counter from metrics import accuracy_score class kNNClassifier(): def __init__(self, k): """初始化kNN分类器""" assert k >= 1, "k must be valid" self.k = k self._x_train = None self._y_train = None def fit(self, x_train, y_train): """根据训练集x_train和y_train训练kNN分类器""" assert x_train.shape[0] == y_train.shape[0], \ "the size of x_train must be equal to the size of y_train" assert x_train.shape[0] >= self.k, "the size of x_train must be at least k" self._x_train = x_train self._y_train = y_train return self def predict(self, X_predict): """给定待预测数据集X_train,返回表示x_train的结果向量""" assert self._x_train is not None and self._y_train is not None, \ "must fit before predict" assert X_predict.shape[1] == self._x_train.shape[1] , \ "the feature number of X_predict must be equal to x_train" y_predict = [self._predict(x) for x in X_predict] return np.array(y_predict) def _predict(self, x): """给定待预测数据x,返回x预测的结果值""" assert x.shape[0] == self._x_train.shape[1], \ "the feature number of x must be equal tu x_train" distances = [sqrt(np.sum((x_train-x)**2)) for x_train in self._x_train] nearest = np.argsort(distances) topK_y = [self._y_train[i] for i in nearest[:self.k]] votes = Counter(topK_y) return votes.most_common(1)[0][0] def score(self, X_test, y_test): """根据数据集X_test 和y_test 得到当前模型的准确度""" y_predict = self.predict(X_test) return accuracy_score(y_test, y_predict) def __repr__(self): return "kNN(k=%d)" % self.k if __name__ == "__main__": x_train = np.array([[0.31864691, 0.99608349], [0.8609734 , 0.40706129], [0.86746155, 0.20136923], [0.4346735 , 0.17677379], [0.42842348, 0.68055183], [0.70661963, 0.76155652], [0.73379517, 0.6123456 ], [0.68330672, 0.52193524], [0.11192091, 0.07885633], [0.99273292, 0.62484263]]) y_train = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1]) k = 6 x = np.array([0.756789,0.6123456]) knn = kNNClassifier(k) knn.fit(x_train,y_train) x_predict = x.reshape(1,-1) print(knn.predict(x_predict))
三、测试结果
[1]
四、问题
1、如果直接将上面训练得到的模型直接放在真实环境中使用,但是模型没有得到验证,会造成模型很差,会有真实损失。
2、真实环境下很难拿到符合条件的数据去测试
解决办法:
1、将训练数据拿出一部分作为测试数据,通过测试数据直接判断模型好坏。
2、在模型进入真实环境前改进模型
1、train_test_split.py
import numpy as np def train_test_split(X, Y, train_ratio=0.8, seed=None): """将数据X和Y按照train_ratio分割成x_train,y_train,x_test,y_test""" assert X.shape[0] == Y.shape[0], "the size of X must equal to the size of Y" assert 0.0 <= train_ratio <= 1.0, "train_ratio must be valid" if seed: np.random.seed(seed) shuffled_indexes = np.random.permutation(len(X)) train_size = int(len(X) * train_ratio) train_indexes = shuffled_indexes[:train_size] test_indexes = shuffled_indexes[train_size:] x_train = X[train_indexes] y_train = Y[train_indexes] x_test = X[test_indexes] y_test = Y[test_indexes] return x_train,y_train,x_test,y_test
2、实际操作
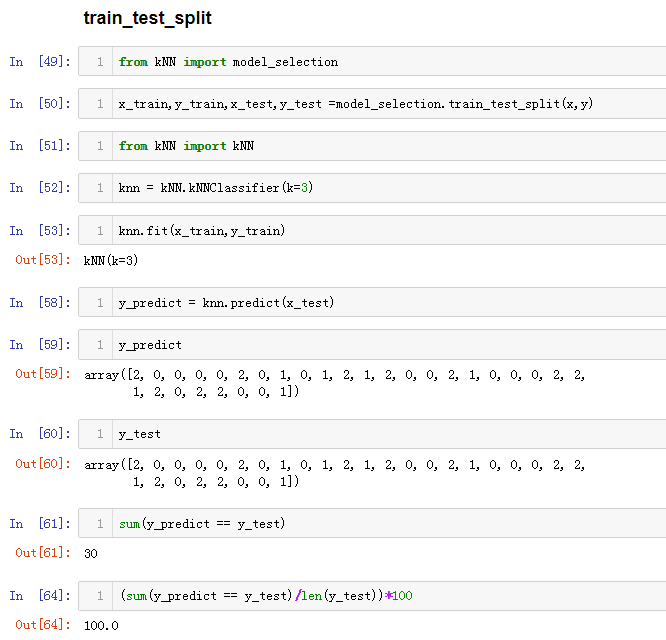
2、从最终的结果来看,该模型与原始数据的标签的吻合达到100%。
五、scikit-learn中的train_test_split
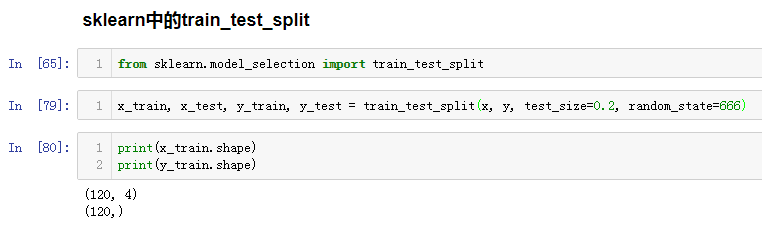
分类:
人工智能与机器学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY