Hadoop
Hadoop
搭建环境
伪分布式:
-
解压:tar -zxvf hadoop.... -C /usr/local/src
-
mv hadoop.... hadoop
-
修改环境变量:vim /root/.bash_profile
添加:
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=HADOOP_HOME/bin:$HADOOOP_HOME/sbin
-
source /root/.bash_profile
-
修改配置文件( hadoop/etc/hadoop):
-
vim hadoop-env.sh 修改jdk路径
-
vim core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/data</value> </property> -
vim hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property> -
vim mapred-env.sh 修改jdk路径
-
复制mapred-site.xml.e..... 为mapred-site.xml
命令为:cp mapred-site.xml.e..... mapred-site.xml
-
vim mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> -
vim yarn-env.sh 修改jdk路径
-
vim yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
配置完成后,格式化namenode: hadoop namenode -format
或: hdfs namenode -format
-
启动hadoop,并前往浏览器查看状况(访问路径:http://192.168.233.110:50070/)
-
启动;
简单粗暴型:
start-all.sh
单独启动namenode 、datanode 、resourcemanager:
start-dfs.sh start-yarn.sh
单一节点启动:
namenode
hadoop-daemon.sh start namenode
datanode
hadoop-daemon.sh start datanode
-
-
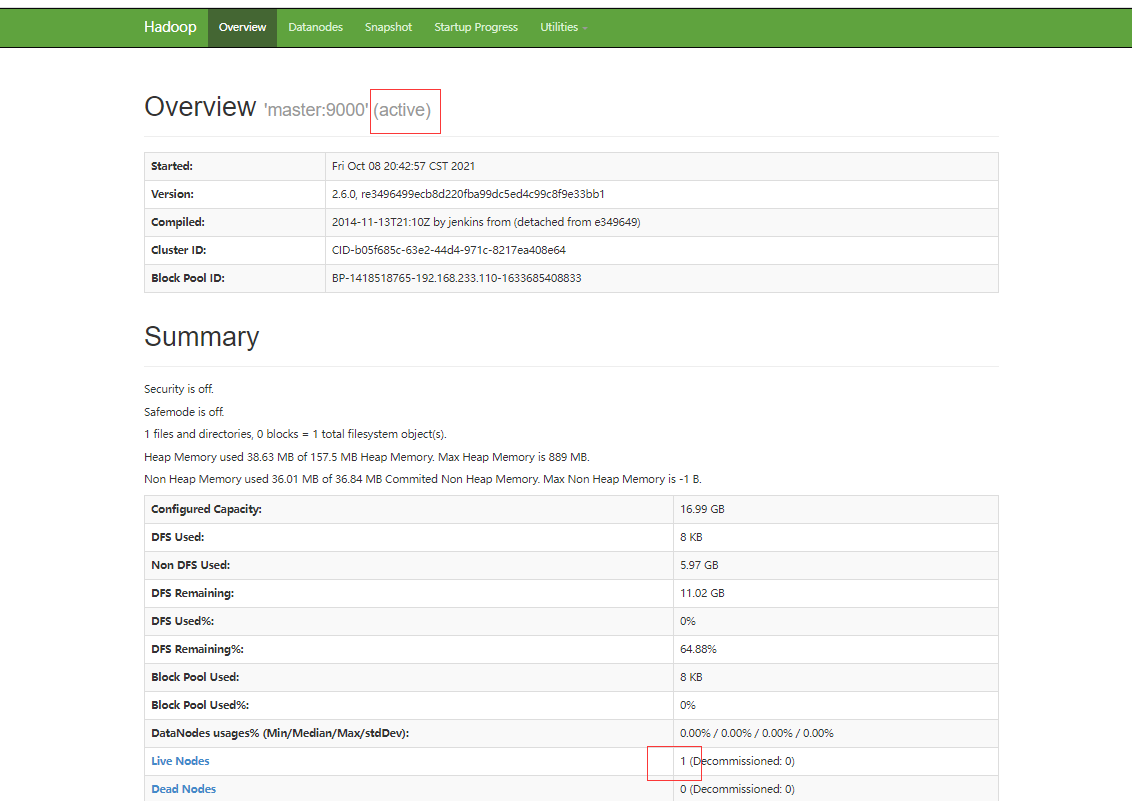
分布式
此为在伪分布式基础上配置:
-

删除/opt下的hadoop(伪分布式的日志及数据在这个文件中)
-
修改hdfs-site.xml文件,将副本数量修改为:3 (根据自己的需要改)
-
修改slaves文件,修改为datanode节点(即把所有机器的名字放进去,一个占一行)
如:
master hadoop01 hadoop02 -
重新格式化namenode : hadoop namenode -format
-
把hadoop完整的拷贝到其它机器上:
[root@hadoop01 src]# scp -r hadoop/ hadoop03:$PWD
-
环境变量/root/.bash_profile也拷贝给其它机器(记得source)
-
启动hadoop: start-all.sh
-
前往浏览器查看状况
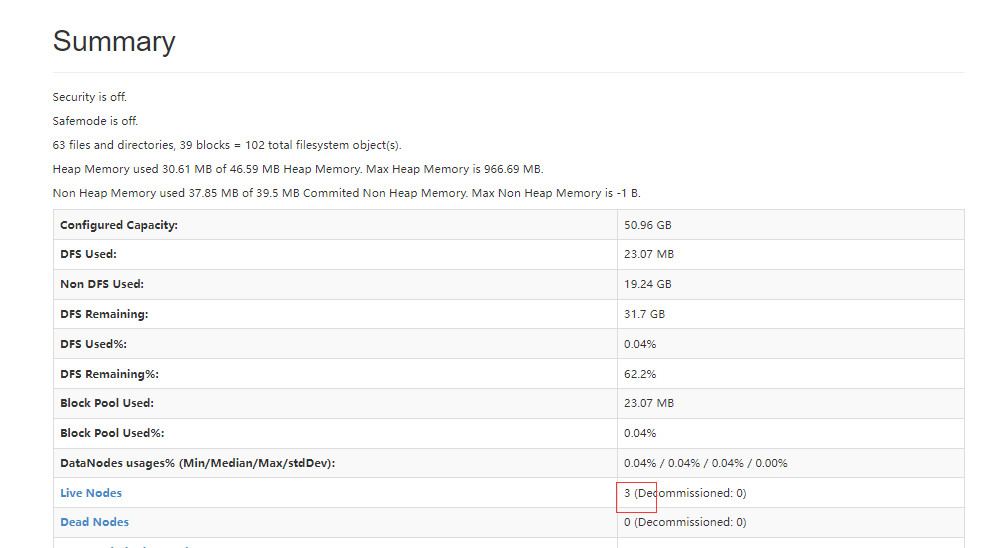
hadoopHA高可用
- vim core-site.xml
<!-- 指定hdfs的nameservice为,如myns1,统一对外提供服务的名字
不再单独指定某一个机器节点-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myns1/</value>
</property>
<!-- 指定hadoop数据存储目录,自己指定 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data</value>
</property>
<!-- 依赖zookeeper,所以指定zookeeper集群访问地址,名字为不同集群机器的hostname -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
- vim hdfs-site.xml
<!-- 指定副本的数量 -->
<property>
<name>fs.replication</name>
<value>3</value>
</property>
<!-- 指定hdfs的nameservice为myns1(在core-site.xml配置的一致) -->
<property>
<name>dfs.nameservices</name>
<value>myns1</value>
</property>
<!-- hadoopHA下面有两个Namenode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址,myns1为前后对应的,hadoop01是其中一个namenode地址 -->
<property>
<name>dfs.namenode.rpc-address.myns1.nn1</name>
<value>hadoop01:9000</value>
</property>
<!-- nn1的http通信地址,myns1为前后对应的 -->
<property>
<name>dfs.namenode.http-address.myns1.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的RPC通信地址,myns1为前后对应的,hadoop03是其中一个namenode地址 -->
<property>
<name>dfs.namenode.rpc-address.myns1.nn2</name>
<value>hadoop03:9000</value>
</property>
<!-- nn2的http通信地址,myns1为前后对应的 -->
<property>
<name>dfs.namenode.http-address.myns1.nn2</name>
<value>hadoop03:50070</value>
</property>
<!-- 指定namenode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop03:8485;hadoop02:8485/myns1</value>
</property>
<!-- 指定namenode在本地磁盘存放数据的位置
journaldata目录自己创建并且指定
-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换,监控体系发现activi挂了,把备用的启用 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<!-- 此处配置在安装的时候切记检查不要换行 ,注意myns1是上面配置的集群服务名 -->
<property>
<name>dfs.client.failover.proxy.provider.myns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行符分隔,即每个机制暂用一行
主要是防止脑裂,确保死的彻底 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆,注意这里是id_rsa文件地址 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<!-- 如果直接使用root,则路径为 /root/.ssh/id_rsa -->
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
- vim mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定mapreduce的历史服务器地址和端口号 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 指定mapreduce的web访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
- vim yarn-site.xml
<!-- 开启YARN高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id,该value可以随意 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<!-- 指定zookeeper集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop03:2181,hadoop02:2181</value>
</property>
<!-- 要运行MapReduce程序必须配置的附属服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Yarn集群的聚合日志最长保留时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
- vim slaves
将集群datanode节点机器名放在这里,换行即可,如:
hadoop01
hadoop02
hadoop03
-
远程拷贝到其它机器:
scp -r /usr/local/src/hadoop/etc/hadoop hadoop02:/usr/local/src/hadoop/etc
-
搭好后启动步骤:
-
分别在每个机器上启动zookeeper集群
bin/zkServer.sh start
成功标志:jps后看到 QuorumPeerMain 进程
-
每个机器上启动 journalnode (最好是奇数台机器)
hadoop-daemon.sh start journalnode
jps 查看 journalnode进程
-
在一个namenode节点上进行格式化(配置了两个namenode机器,只需要一台电脑上格式化)
格式化之前需要先删除之前hadoop留下的日志和数据文件,方法可见分布式处开头
删除之后再进行格式化工作
hadoop namenode -format
-
格式化后namenode的机器上找到存放数据的data目录,然后拷贝到另外一个namenode机器的data目录下,保持初始元数据一致。
scp -r data hadoop03:/opt/hadoop/
-
在任何一个namenode上执行zkfc -formatZK操作(#格式化zookeeper):
hdfs zkfc -formatZK
-
start-dfs.sh
-
start-yarn.sh(在自己配置的对应任何一台resourcemanager机器上执行)
-
测试:
-
分别在每个机器上jps查看状态
-
分别访问两个namenode机器上的50070界面,查看状态是否一个是Active,另外一个是Standby
-
测试访问一下yarn集群
-
可用测试,测试主备切换
方法: 将active状态的namenode进程干掉,kill -9 xxxxid
再使用单节点启动方式启动namenode:hadoop-daemon.sh start namenode
-
-
-
搭建成功后第二次启动:
-
首先在每一台机器上启动zookeeper
zkServer.sh satrt
-
让后直接 start-all.sh
补充:
-
在另外一台resourceManager机器上单独启动resourceManager进程:
yarn-daemon.sh start resourcemanager
-
yarn高可用测试和hadoop一样,访问的端口是8088
hadoop-daemon.sh start namenode
-
启动历史服务器
mr-jobhistory-daemon.sh start historyserver -
yarn-daemon.sh start nodemanager
-
yarn-daemon.sh start resourcemanager
-
然后两台机器分别启动resourcemanager即可
-
命令方式查看hadoop状态:hdfs haadmin -getServiceState nn2
-
命令方式查看yarn状态:yarn rmadmin -getServiceState rm1
hdfs常用命令
- 上传文件:hdfs dfs -put /opt/test/xxx.txt /test1
- 删除文件夹:hdfs dfs -rm -r /test
- 创建文件夹:hdfs dfs -mkdir /test
- 下载文件到本地:hdfs dfs -get /user.txt /opt
- 查看/test目录下所有文件的总行数:hdfs dfs -cat /test1/* | wc -l
- 查看文件后前20行:hdfs dfs -cat /datas/access_log | head -20
- 查看文件后30行:hdfs dfs -cat /datas/access_log | tail -30
- 查看文件第3行到第10行:hdfs dfs -cat /datas/access_log | sed -n '3,10p'


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本