大数据学习笔记
一、环境搭建
1.安装前准备
-
关闭禁用防火墙:
- 关闭:systemctl stop firewalld
- 禁用:systemctl disable firewalld
-
修改主机名:
-
vim /etc/hostname
或者: hostnamectl set-hostname xxx
-
-
修改ip地址: vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改如下图:
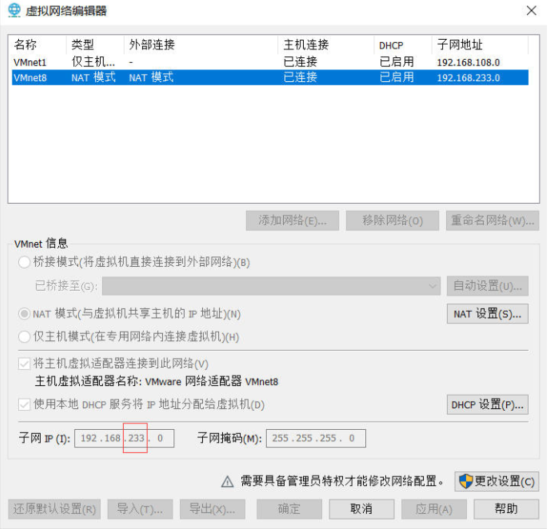
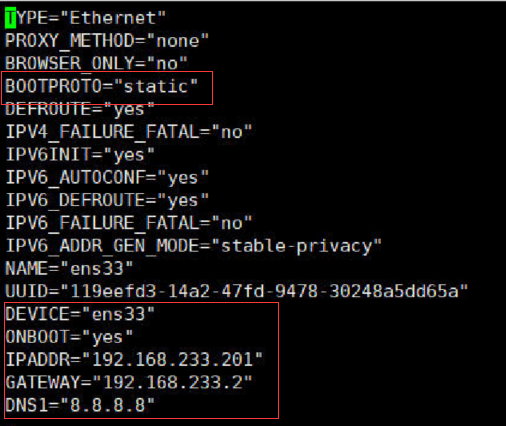
-
编写hosts文件: vim /etc/hosts,添加想要主机名和ip地址
如右图:

-
如有其它设备,则远程拷贝到其它设备:
命令如下: scp /etc/hosts 192.168.233.202:/etc/
-
-
创建/h3cu : mkdir /h3cu ;并跳转至该目录: cd /h3cu
-
连接远程上传工具,上传所需组件
2.配置免密登录
-
回到根目录:cd /root
-
ssh-keygen -t rsa
-
ssh-copy-id -i root@xxx
分别拷贝给所有机器(包括自己)
3.安装jdk
-
删除centos自带的jdk,相关命令如下:
-
查看当前java版本:java -version
-
查看当前java文件:rpm -qa | grep java
-
删除命令如下:
rpm -e --nodeps java-x.x.x-openjdk-headless....
rpm -e --nodeps java-x.x.x-openjdk-x.x.x.xx-...
-
-
解压上传的jdk组件,相关命令如下:
- cd /h3cu
- tar -zxvf jdk-........ -C /usr/local/src
- cd /usr/local/src
- mv jdk-.... jdk
-
修改环境变量,对root生效:
-
vim /root/.bash_profile
-
添加如下两条语句:
export JAVA_HOME=/usr/local/src/jdk
export PATH=JAVA_HOME/bin
-
source /root/.bash_profile
-
-
远程拷贝到其它机器上:
相关命令如下:
scp -r /usr/local/src/jdk/ hadoop02:/usr/local/src/
scp -r /root/.bash_profile hadoop02:/root/
注意:拷贝完每台机器都需要 'source' 一下
4.安装mysql
-
卸载自带的mariadb:
- 查看:rpm -qa | grep mariadb
- 删除:rpm -e --nodeps mariadb...
- cd /h3cu
- rpm -ivh Mysql-server....rpm
- rpm -ivh Mysql-client-....rpm
-
进行第一次登录mysql,并设置密码:
-
登录:mysql -uroot
-
登录后设置密码:
mysql>set password=password('123456')
-
授予远程登录权限:
-
mysql> grant all privileges on . to 'root'@'%' identified by '123456' with grant option;
-
mysql> flush privileges;
-
-
使用Windows连接数据库软件进行连接测试,连接成功则安装成功!
5.搭建hadoop环境
a、伪分布式:
-
解压:tar -zxvf hadoop.... -C /usr/local/src
-
mv hadoop.... hadoop
-
修改环境变量:vim /root/.bash_profile
添加:
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=HADOOP_HOME/bin:$HADOOOP_HOME/sbin
-
source /root/.bash_profile
-
修改配置文件( hadoop/etc/hadoop):
-
vim hadoop-env.sh 修改jdk路径
-
vim core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/data</value> </property> -
vim hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property> -
vim mapred-env.sh 修改jdk路径
-
复制mapred-site.xml.e..... 为mapred-site.xml
命令为:cp mapred-site.xml.e..... mapred-site.xml
-
vim mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> -
vim yarn-env.sh 修改jdk路径
-
vim yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
配置完成后,格式化namenode: hadoop namenode -format
或: hdfs namenode -format
-
启动hadoop,并前往浏览器查看状况(访问路径:http://192.168.233.110:50070/)
-
启动;
简单粗暴型:
start-all.sh
单独启动namenode 、datanode 、resourcemanager:
start-dfs.sh start-yarn.sh
单一节点启动:
namenode
hadoop-daemon.sh start namenode
datanode
hadoop-daemon.sh start datanode
-
-
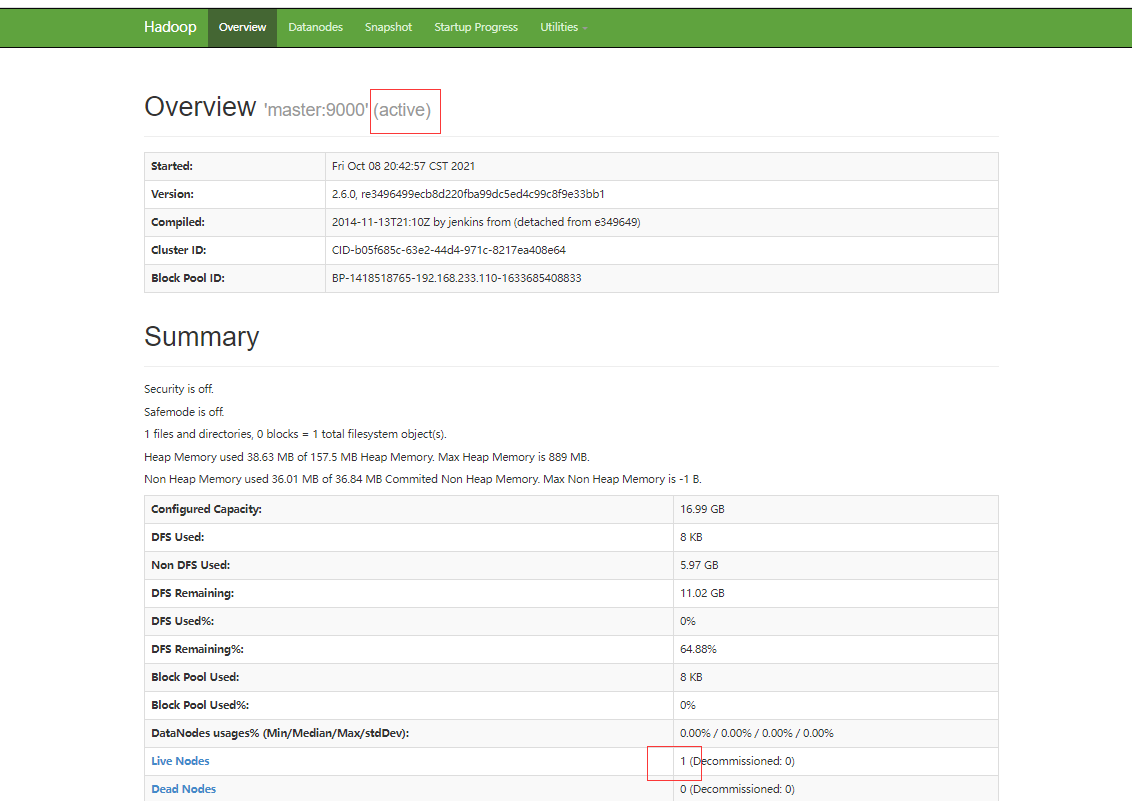
b、分布式
此为在伪分布式基础上配置:
-

删除/opt下的hadoop(伪分布式的日志及数据在这个文件中)
-
修改hdfs-site.xml文件,将副本数量修改为:3 (根据自己的需要改)
-
修改slaves文件,修改为datanode节点(即把所有机器的名字放进去,一个占一行)
如:
master hadoop01 hadoop02 -
重新格式化namenode : hadoop namenode -format
-
把hadoop完整的拷贝到其它机器上:
[root@hadoop01 src]# scp -r hadoop/ hadoop03:$PWD
-
环境变量/root/.bash_profile也拷贝给其它机器(记得source)
-
启动hadoop: start-all.sh
-
前往浏览器查看状况
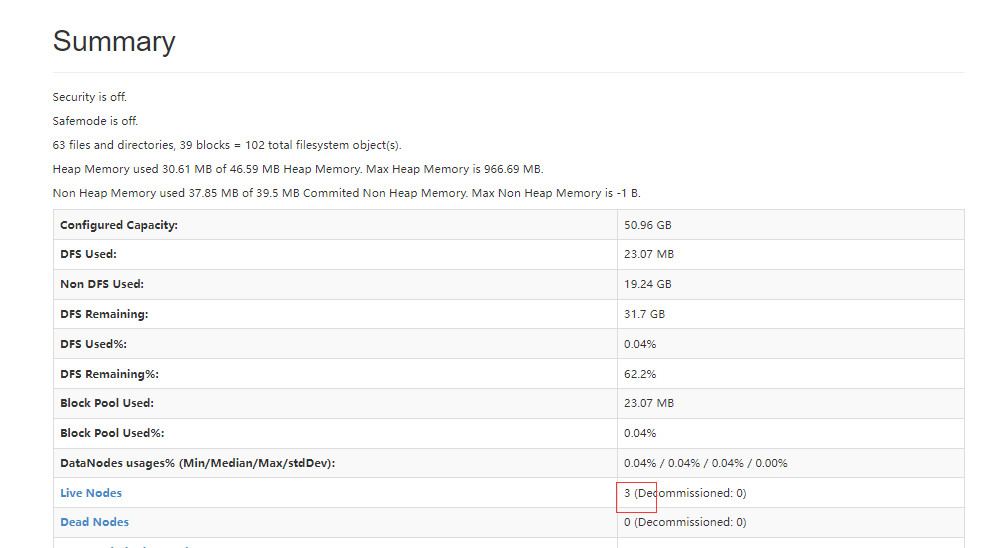
c、hadoopHA高可用
- vim core-site.xml
<!-- 指定hdfs的nameservice为,如myns1,统一对外提供服务的名字
不再单独指定某一个机器节点-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myns1/</value>
</property>
<!-- 指定hadoop数据存储目录,自己指定 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data</value>
</property>
<!-- 依赖zookeeper,所以指定zookeeper集群访问地址,名字为不同集群机器的hostname -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
- vim hdfs-site.xml
<!-- 指定副本的数量 -->
<property>
<name>fs.replication</name>
<value>3</value>
</property>
<!-- 指定hdfs的nameservice为myns1(在core-site.xml配置的一致) -->
<property>
<name>dfs.nameservices</name>
<value>myns1</value>
</property>
<!-- hadoopHA下面有两个Namenode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址,myns1为前后对应的,hadoop01是其中一个namenode地址 -->
<property>
<name>dfs.namenode.rpc-address.myns1.nn1</name>
<value>hadoop01:9000</value>
</property>
<!-- nn1的http通信地址,myns1为前后对应的 -->
<property>
<name>dfs.namenode.http-address.myns1.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的RPC通信地址,myns1为前后对应的,hadoop03是其中一个namenode地址 -->
<property>
<name>dfs.namenode.rpc-address.myns1.nn2</name>
<value>hadoop03:9000</value>
</property>
<!-- nn2的http通信地址,myns1为前后对应的 -->
<property>
<name>dfs.namenode.http-address.myns1.nn2</name>
<value>hadoop03:50070</value>
</property>
<!-- 指定namenode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop03:8485;hadoop02:8485/myns1</value>
</property>
<!-- 指定namenode在本地磁盘存放数据的位置
journaldata目录自己创建并且指定
-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换,监控体系发现activi挂了,把备用的启用 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<!-- 此处配置在安装的时候切记检查不要换行 ,注意myns1是上面配置的集群服务名 -->
<property>
<name>dfs.client.failover.proxy.provider.myns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行符分隔,即每个机制暂用一行
主要是防止脑裂,确保死的彻底 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆,注意这里是id_rsa文件地址 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<!-- 如果直接使用root,则路径为 /root/.ssh/id_rsa -->
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
- vim mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定mapreduce的历史服务器地址和端口号 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 指定mapreduce的web访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
- vim yarn-site.xml
<!-- 开启YARN高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id,该value可以随意 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<!-- 指定zookeeper集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop03:2181,hadoop02:2181</value>
</property>
<!-- 要运行MapReduce程序必须配置的附属服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Yarn集群的聚合日志最长保留时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
- vim slaves
将集群datanode节点机器名放在这里,换行即可,如:
hadoop01
hadoop02
hadoop03
-
远程拷贝到其它机器:
scp -r /usr/local/src/hadoop/etc/hadoop hadoop02:/usr/local/src/hadoop/etc
-
搭好后启动步骤:
-
分别在每个机器上启动zookeeper集群
bin/zkServer.sh start
成功标志:jps后看到 QuorumPeerMain 进程
-
每个机器上启动 journalnode (最好是奇数台机器)
hadoop-daemon.sh start journalnode
jps 查看 journalnode进程
-
在一个namenode节点上进行格式化(配置了两个namenode机器,只需要一台电脑上格式化)
格式化之前需要先删除之前hadoop留下的日志和数据文件,方法可见分布式处开头
删除之后再进行格式化工作
hadoop namenode -format
-
格式化后namenode的机器上找到存放数据的data目录,然后拷贝到另外一个namenode机器的data目录下,保持初始元数据一致。
scp -r data hadoop03:/opt/hadoop/
-
在任何一个namenode上执行zkfc -formatZK操作(#格式化zookeeper):
hdfs zkfc -formatZK
-
start-dfs.sh
-
start-yarn.sh(在自己配置的对应任何一台resourcemanager机器上执行)
-
测试:
-
分别在每个机器上jps查看状态
-
分别访问两个namenode机器上的50070界面,查看状态是否一个是Active,另外一个是Standby
-
测试访问一下yarn集群
-
可用测试,测试主备切换
方法: 将active状态的namenode进程干掉,kill -9 xxxxid
再使用单节点启动方式启动namenode:hadoop-daemon.sh start namenode
-
-
-
搭建成功后第二次启动:
-
首先在每一台机器上启动zookeeper
zkServer.sh satrt
-
让后直接 start-all.sh
补充:
-
在另外一台resourceManager机器上单独启动resourceManager进程:
yarn-daemon.sh start resourcemanager
-
yarn高可用测试和hadoop一样,访问的端口是8088
hadoop-daemon.sh start namenode
-
启动历史服务器
mr-jobhistory-daemon.sh start historyserver -
yarn-daemon.sh start nodemanager
-
yarn-daemon.sh start resourcemanager
-
然后两台机器分别启动resourcemanager即可
-
命令方式查看hadoop状态:hdfs haadmin -getServiceState nn2
-
命令方式查看yarn状态:yarn rmadmin -getServiceState rm1
6.zookeeper搭建
-
解压zookeeper包: tar -zxvf zookeeper-......... -C /usr/local/src
-
cd /usr/local/src 执行:mv zookeeper..... zookeeper
-
cd zookeeper/conf 执行:cp zoo_sample.cfg zoo.cfg
-
vim zoo.cfg 配置如下:

-
cd ../ 执行: mkdir zkdatas
-
cd zkdatas 执行:vim myid
1 -
cd /usr/local/src 执行:scp -r zoo.cfg hadoop02:$PWD (如果有其它机器则执行此步,没有则跳过 ,拷贝完后需要修改myid的内容)
-
启动zookeeper步骤:
-
cd /usr/local/src/zookeeper
-
bin/zkServer.sh start
启动成功后jps会看到QuorumPeerMain 进程,未出现则证明配置有误,请修改!
补充:查看zookeeper身份: bin/zkServer.sh status
-
7.hive环境搭建
-
解压:tar -zxvf apach-hive....... -C /usr/local/src
-
cd /usr/local/src 执行:
-
vim /root/.bash_profile (记得source)
export HIVE_HOME=/usr/local/src/hive export PATH=$PATH:$HIVE_HOME/bin -
cd /usr/local/src/hive/conf 执行: cp hive-env.sh.template hive-env.sh
export JAVA_HOME=/usr/local/src/jdk export HADOOP_HOME=/usr/local/src/hadoop export HIVE_HOME=/usr/local/src/hive -
cp hive-default.xml.template hive-site.xml (管理元数据配置)
注意:写的时候字母大小写不能变
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://l:3306/hive?createDatabaseIfNotExist=true&characterEncoding=utf8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <property> <name>hive.querylog.location</name> <value>/usr/local/src/hive/tmp</value> </property> <property> <name>hive.exec.local.scratchdir</name> <value>/usr/local/src/hive/tmp</value> </property> <property> <name>hive.downloaded.resources.dir</name> <value>/usr/local/src/hive/tmp</value> </property> -
将mysql的jdbc驱动包拷贝到/hive/lib/ : cp /h3cu/mysql-connector-java-.... /usr/local/src/hive/lib/
-
将 hive/lib 下的 jline-2.12.jar 到hadoop中:cp jline-2.12.jar /usr/local/src/hadoop/share/hadoop/yarn/lib/
-
cd /usr/local/src/hadoop/share/hadoop/yarn/lib 执行:rm -rf jline-0.9.94.jar
-
cd /usr/local/src/hive/bin 初始化hive元数据仓库: schematool -dbType mysql -initSchema
初始化成功图:

8.spark环境搭建
-
解压:tar -zxvf spark-........ -C /usr/local/src
-
cd /usr/local/src 执行: mv spark-..... spark
-
vim /root/.bahs_profile (改完记得source)
export SPARK_HOEM=/usr/local/src/spark export PATH=$PATH:$SPARK_HOME:/bin:$SPATK_HOME/sbin -
cd /usr/local/src/spark/conf 并执行:
-
cp spark-env.sh.template spark-env.sh
-
vim spark-env.sh
export SPARK_LOCAL_IP=192.168.233.110 #本机ip,每一台都不一样 export JAVA_HOME=/usr/local/src/jdk export SPARK_MASTER_HOST=master #主机名 export SPARK_MASTER_PORT=7707 export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=1g export SPARK_CONF_DIR=/usr/local/src/spark/conf -
cp slaves.template slaves 并 vim slaves (如果没有从节点可忽略此步骤)
该文件中配置从节点的主机名,如:hadoop02 , node02
hadoop02 hadoop03
-
9.sqoop环境搭建
-
解压 tar -zxvf /h3cu/sqoop..........tar -C /usr/local/src 并重命名为:mv sqoop ........ sqoop
-
vim /root/.bash_profile (记得source)
export SQOOP_HOME=/usr/local/src/sqoop export path=$path:$SQOOP_HOME/bin -
cd $SQOOP_HOME/conf
-
cp sqoop-env-template.sh sqoop-env.sh 并vim sqoop-env.sh 内容如下:
export HADOOP_COMMON_HOME=/usr/local/src/hadoop export HADOOP_MAPRED_HOME=/usr/local/src/hadoop export HIVE_HOME=/usr/local/src/hive export ZOOKEEPER_HOME=/usr/local/src/zookeeper -
把sqoop里的lib下的jar都发送到hdfs相同目录下
-
使用:使用前需要先启动hadoop然后直接使用命令即可!
二、python爬虫
1.解析HTML:
lxml 是一种python编写的库,可以迅速、灵活的处理xml和html
使用:根据版本的不同,有如下两种:
-
形式1:
from lxml import etree
转换成树形结构对象:
obj=etree.HTML(htmlStr)
-
形式2:
from lxml import html
getHtml=requests.get(url,headers=header)
htmlObj=html.fromstring(getHtml.content.decode("utf8"))
htmlObj.xpath("")
a、xpath语法:
| 表达式 | 说明 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| @ | 选取属性 |
| . | 选择当前节点 |
| 节点名 | 1选取此节点所有子节点 |
| //book | 选取所有book子元素,而不管它们在文档中的位置 |
| div//book | 选择属性div元素的后代的所有book元素,而不管它们位于div之下的什么位置 |
| //@lang | 选取名为lang的所有属性 |
b、举例
| 路径表达式 | 结果 |
|---|---|
| /div/div[1] | 选取数据div元素的第一个div元素 |
| /div/div[last()] | 选取属于div元素的最后一个div元素 |
| /div/div[last()-1] | 选取属于div元素的倒数第二个div元素 |
| /div/div[position()❤️] | 选取最前面的两个属于div元素的子元素的book元素 |
| //title[@lang] | 选取所有拥有名为lang属性的title元素 |
| //title[@lang='eng'] | 选取所有lang属性值为eng的title元素 |
2.解析json
import json
str='{"result":0,"data":[{"id":"664","numbers":"42235"}],"msg":"\u6210\u529f"}'
obj=json.loads(str)
xxrs=obj['data'][0]['numbers']
print(xxrs)#结果:42235
3.正则表达式
菜鸟教程:https://www.runoob.com/python/python-reg-expressions.html
正则表达式:
| 字符 | 描述 |
|---|---|
| […] | 用来表示一组字符, 单独列出, 例如, [amk]匹配a, m或k |
| [^…] | 不在[]中的字符, 例如, [^abc]匹配除了a, b, c之外的字符 |
| * | 匹配0个或多个的表达式 |
| + | 匹配1个或者多个的表达式 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段, 非贪婪方式 |
| 精确匹配n次前面的表示 | |
| 匹配n到m次由前面的正则表达式定义的片段, 贪婪模式 | |
| a|b | 匹配a或者b |
| ( ) | 匹配括号内的表达式, 也表示一个组 |
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
|---|---|
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
a.常用方法:
- re.findall()
使用案例:
import re
a="声明:python是一门简单的语言!python是一门好用的语言!"
#findall() 返回数据为list格式
result=re.findall("python(.*)!",a)# ['是一门简单的语言!python是一门好用的语言']
result2=re.findall("python(.*?)!",a)#['是一门简单的语言','是一门好用的语言']
# (.*)贪婪匹配,会尽可能的往后匹配
# (.*?) 非贪婪匹配,会尽可能少的匹配,是否加?影响匹配结果的长度
4.scrapy使用步骤:
- 新建文件夹(scrapyPro)存放scrapy文件
- 到scrapyPro目录下,执行:scrapy startproject scrapyOne
- 进入到scrapyOne下的spiders目录执行:scrapy genspider 爬虫名称 xxx.com
- 用编码工具修改settings.py 中的robots 设置为false
- 修改爬虫程序代码
- 运行爬虫:scrapy crawl 爬虫名称
a.scrapy使用小知识
-
Settings.py文件介绍:
项目名:BOT_NAME = ‘xxxx‘
遵循ROBOT协议:ROBOTSTXT_OBEY = False
用户身份:USER_AGENT =‘xxxx’
最大并发数:CONCURRENT_REQUESTS=32默认为16
下载延迟:DOWNLOAD_DELAY = 3
每个域名最大并发数:CONCURRENT_REQUESTS_PER_DOMAINCookie设置:COOKIES_ENABLED默认为true,下次请求带上cookie
默认请求头设置:DEFAULT_REQUEST_HEADERS一系列中间件、缓存、http请求的配置等(不常用)
-
爬虫项目的工程目录及各个组成的作用:
scrapy.cfg:项目配置文件。
settings.py:项目设置文件。pipelines.py:项目管道文件,主要用于对
Items定义的数据进行加工与处理。
middlewares.py:项目的中间件文件。
items.py:项目的数据容器文件,用于定义获取的数据。
init.py:初始化文件。
spiders目录:爬虫目录,例如,创建文件、编写爬虫解析规则等
b.数据存储的四种格式
-
以txt文本形式存储:
class xxxxPipeline: def __init__(self): self.file=open("test.txt","w",encoding="utf8") def process_item(self,item,spider): row='{},{},{},{}\n'.format(item['name'], item['age'],item['zy'],item['dy']) self.file.write(row) return item def close(self): self.file.close() -
CSV格式
import csv class xxxxPipeline: def __init__(self): self.file = open('../moot2.csv','a',encoding='utf-8',newline='') self.writer = csv.writer(self.file,delimiter=';') self.writer.writerow(['表头1','表头2',.....]) def process_item(self,item,spider): self.writer.writerow([item['title'],item['price'],......]) return item def close(self): self.file.close() -
json格式:
import json class xxxxPipeline: def __init__(self): self.file = open('../moot2.json','a',encoding='utf-8') def process_item(self,item,spider): jsonstr = json.dumps(dict(item),ensure_ascii=False) self.file.write(jsonstr+'\n') return item def close(self): self.file.close() -
mysql存储
import pymysql class xxxxPipeline: def __init__(self): self.conn = pymysql.connect(host='IP/localhost', user='root',password='123456', port=3306,db='数据库名') self.cursor = self.conn.cursor() def process_item(self,item,spider): sql = "insert into tb_moot values(null,%s,%s,......)" self.cursor.execute(sql,(item['title'],item['price'],.......)) self.conn.commit() return item def close(self): self.cursor.close() self.conn.close()
三、sqoop的常用命令
导入(import):从非集群 - -> 集群
导出(export):集群 --> 非集群
-
列出mysql数据库中的所有数据库:
sqoop list-databases -connect jdbc:mysql://192.168.1.10:3306 -username root -password 123456 -
通过sqoop执行sql语句
sqoop eval -connect jdbc:mysql:///sqoop -username root -password root -query "select * from employee where id=5" -
mysql导入到hdfs
[hadoop@node01 ~]$ sqoop import \ > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root \ > --password 123456 \ > --table Person \ > --target-dir /sqoop/person \ # 指定导出目录 > --delete-target-dir \ # 如果导出目录存在,就先删除 > --fields-terminated-by '\t' \ # 指定字段数据分隔符 > --m 1 #指定map task数,默认是4个 # \ 表示隔开每个参数 -
hdfs导出到mysql
sqoop export \ --connect jdbc:mysql://node1:3306/userdb \ --username sqoop \ --password sqoop \ --table employee \ --export-dir /user/hadoop/emp/ --input-fields-terminated-by ',' -
从MySQL导入到hive
[hadoop@node01 ~]$ sqoop import \ > --connect jdbc:mysql://node01:3306/sqooptest \ > --username root \ > --password 123456 \ > --table Person \ > --hive-import \ > --hive-database sqooptohive \ > --hive-table person1 \ > --m 1 -
从hdfs导出数据到MySQL(需要先建mysql中的表)
sqoop export \ --connect jdbc:mysql://localhost:3306/wht \ --username root \ --password 123456 \ --table wht_test2 \ --fields-terminated-by ',' \ --export-dir /user/hive/warehouse/wht_test1
四、mapreduce的使用
一下案例写之前需要导入jar包依赖:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
1.单词计数案例:
package com.xyz;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author 小勇子start
* @create 2021-10-11 16:35
*/
public class WordCount {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf=new Configuration();
Job job= Job.getInstance(conf);
//这里是对jar包的类,map的类和reduce的类三者的映射
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//这里是对map输出的关键字和值对应类型的映射
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//这里是对reduce输出的关键字和值对应类型的映射
job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
//数据输入路径(此处为本地测试)
FileInputFormat.setInputPaths(job,new Path("C:\\Users\\小勇子\\Desktop\\大数据培训\\练习\\mapreduceTest\\src\\data\\test.txt"));
//数据输出路径(此处为本地测试)
FileOutputFormat.setOutputPath(job,new Path("C:\\Users\\小勇子\\Desktop\\大数据培训\\练习\\mapreduceTest\\src\\data\\out1"));
boolean flag=job.waitForCompletion(true);
System.exit(flag?0:1);
}
static class Map extends Mapper<LongWritable,Text, Text, IntWritable>{
/*Text的包有很多,注意导的是:org.apache.hadoop.io.Text
在map中前两个数据类型基本固定
后两个代表着要输出的类型,如果有reduce,则以该类型发送给reduce
*/没有reduce则直接以该类型输出到目标
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] str=value.toString().split(",");
for (String s:str) {
context.write(new Text(s),new IntWritable(1));
}
}
}
static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
/*
<Text,IntWritable,Text,IntWritable>
前两个是map发过来关键字和值的类型
后两个是reduce输出关键字和值的类型
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int len=0;
for (Object s:values) {
len++;
}
context.write(key,new IntWritable(len));
}
}
}
2.数据清洗案例:
package com.xyz2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author 小勇子start
* @create 2021-10-11 17:23
*/
public class RepeatProcessing {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf=new Configuration();
Job job= Job.getInstance(conf);
job.setJarByClass(RepeatProcessing.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputValueClass(NullWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
//此处为本地测试
FileInputFormat.setInputPaths(job,new Path("C:\\Users\\小勇子\\Desktop\\大数据培训\\练习\\mapreduceTest\\src\\data\\test2.txt"));
//此处为本地测试
FileOutputFormat.setOutputPath(job,new Path("C:\\Users\\小勇子\\Desktop\\大数据培训\\练习\\mapreduceTest\\src\\data\\out2"));
boolean flag=job.waitForCompletion(true);
long repeat=job.getCounters().findCounter(Count.repeatCount).getValue();
System.out.println("重复的行数为:"+repeat);
System.exit(flag?0:1);
}
static enum Count{//枚举计数
repeatCount
}
static class Map extends Mapper<LongWritable, Text,Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
static class Reduce extends Reducer<Text, NullWritable,Text,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
Counter counter=context.getCounter(Count.repeatCount);
int len=0;
for (Object s:values) {
len++;
}
long val= counter.getValue();
val+=len-1;
counter.setValue(val);
context.write(key,NullWritable.get());
}
}
}
3.topN案例:
package com.xyz;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.*;
/**
* @author 小勇子start
* @create 2021-09-30 19:53
*/
public class Task2_4 {
static class TaskMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(";");
String filmName = line[0];//电影名称
String filmType = line[6];//电影类型
String[] types = filmType.split("/|、|,");
for (String s : types) {
s=s.trim();
if (s.length() > 2) {
for (int i = 2; i < s.length(); i += 2) {
String newStr = s.substring(i - 2, i);
context.write(new Text(newStr), new Text(filmName));
}
} else
context.write(new Text(s), new Text(filmName));
}
}
}
static class TaskReduce extends Reducer<Text, Text, Text, IntWritable> {
ArrayList<Object[]> arrayList=new ArrayList<Object[]>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//此处用set是因为Iterable<Text> values中存储的值中有重复的电影名称,需要取不同名字的个数
HashSet set=new HashSet();
for (Text s : values) {
set.add(s);
}
Object[] data={set.size(),key.toString()};
arrayList.add(data);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Object[] data=arrayList.toArray();
Arrays.parallelSort(data, new Comparator<Object>() {
@Override
public int compare(Object o1, Object o2) {
Object[] o_1=(Object[]) o1;
Object[] o_2=(Object[]) o2;
return (int)o_2[0]-(int)o_1[0];
}
});
for (Object d:data) {
Object[] d1=(Object[]) d;
context.write(new Text(d1[1].toString()),new IntWritable((int)d1[0]));
}
/*取前3个
for (int i=0;i<3;i++) {
Object[] d1=(Object[]) data[i];
context.write(new Text(d1[1].toString()),new IntWritable((int)d1[0]));
}
*/
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Task2_4.class);
job.setMapperClass(TaskMap.class);
job.setReducerClass(TaskReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("C:\\Users\\小勇子\\Desktop\\大数据培训\\练习\\作业\\7月25日晚上任务\\数据\\2-1"));
FileOutputFormat.setOutputPath(job, new Path("C:\\Users\\小勇子\\Desktop\\大数据培训\\练习\\作业\\7月25日晚上任务\\数据\\2-42"));
boolean flag = job.waitForCompletion(true);
System.exit(flag ? 0 : 1);
}
}
4.join案例(自定义Writable)
package com.xyz;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author 小勇子start
* @create 2021-10-12 10:32
*/
public class JoinDemo {
static class MyDataWritable implements Writable {
private String flag;//标记
private String data;//一行数据
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(flag);
dataOutput.writeUTF(data);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.flag=dataInput.readUTF();
this.data=dataInput.readUTF();
}
public String getFlag(){
return flag;
}
public void setFlag(String flag){
this.flag=flag;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
}
static class Map extends Mapper<LongWritable, Text, IntWritable,MyDataWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] str=value.toString().split(",");
int id=Integer.valueOf(str[0]);
String fileName=((FileSplit)context.getInputSplit()).getPath().getName();
MyDataWritable myData=new MyDataWritable();
myData.setData(value.toString());
if(fileName.contains("customers"))
myData.setFlag("kh");
else
myData.setFlag("order");
context.write(new IntWritable(id),myData);
}
}
static class Reduce extends Reducer<IntWritable,MyDataWritable,Text, NullWritable>{
@Override
protected void reduce(IntWritable key, Iterable<MyDataWritable> values, Context context) throws IOException, InterruptedException {
String khData="";
String oData="";
for (MyDataWritable m:values) {
if (m.getFlag().equals("kh"))
khData=m.getData();
else
oData=m.getData();
}
String newData=khData+","+oData;
context.write(new Text(newData),NullWritable.get());
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf=new Configuration();
Job job= Job.getInstance(conf);
job.setJarByClass(JoinDemo.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputValueClass(MyDataWritable.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
//此处为本地测试
FileInputFormat.setInputPaths(job,new Path("C:\\Users\\小勇子\\Desktop\\大数据培训\\练习\\joinDemo\\DemoOne\\join\\"));
//此处为本地测试
FileOutputFormat.setOutputPath(job,new Path("C:\\Users\\小勇子\\Desktop\\大数据培训\\练习\\joinDemo\\DemoOne\\join\\out1"));
boolean flag=job.waitForCompletion(true);
System.exit(flag?0:1);
}
}
5.时间日期格式化
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author 小勇子start
* @create 2021-10-11 17:53
*/
public class DateTimeFormat {
public static void main(String[] args) throws ParseException {
String dateStr="2021.09.05";
SimpleDateFormat sdf=new SimpleDateFormat("yyyy.MM.dd");
SimpleDateFormat sdf1=new SimpleDateFormat("yyyy-MM-dd");
Date oldDate=sdf.parse(dateStr);
String newDateStr=sdf1.format(oldDate);
Date newDate=sdf1.parse(newDateStr);
System.out.println(oldDate);//结果:Sun Sep 05 00:00:00 CST 2021
System.out.println(newDateStr);//结果:2021-09-05
System.out.println(newDate);//结果:Sun Sep 05 00:00:00 CST 2021
}
}
6.mapreduce项目打jar包
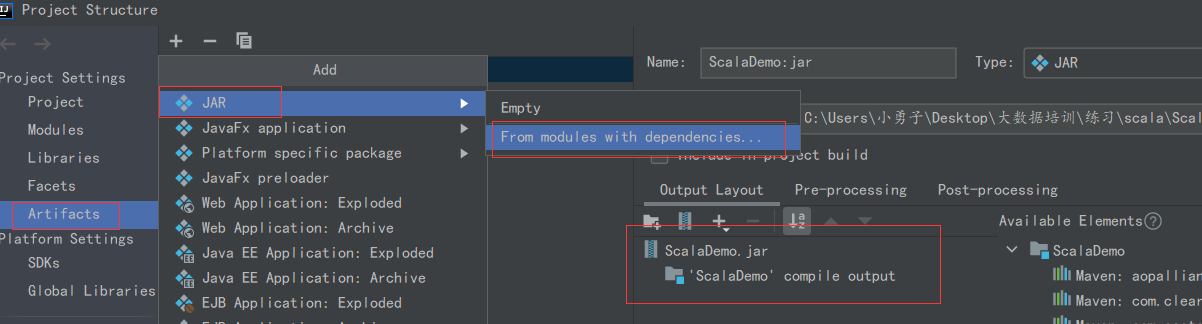
- 右键项目 Open Module Settings
- 找到左侧 Artifacts,点击中间的 +号,选择JAR,然后选择“”“From Module With dependicies”
- 选择要执行的Main方法
- 点击idea上面的Builde菜单,选择Builder Artifacts。然后builder即可(如果改了代码,直接点击Rebuild
- 打包后将jar包上传至linux中
7.运行jar包
- 在linux中创建一个文本文件,然后上传至hdfs中
- 开始运行程序: hadoop jar xxxx.jar com.xyzy.test1.MyWordDriver /xxx.txt /out1
如果你程序中输入,输出路径是写死的(即不是用的args[0]这样的方式),那么/xxx.txt 和/out1就不需要了 ;在上传后jar包所在的位置执行上述命令,否则jar包前面使用绝对路径。
五、hdfs常用命令
- 上传文件:hdfs dfs -put /opt/test/xxx.txt /test1
- 删除文件夹:hdfs dfs -rm -r /test
- 创建文件夹:hdfs dfs -mkdir /test
- 下载文件到本地:hdfs dfs -get /user.txt /opt
- 查看/test目录下所有文件的总行数:hdfs dfs -cat /test1/* | wc -l
- 查看文件后前20行:hdfs dfs -cat /datas/access_log | head -20
- 查看文件后30行:hdfs dfs -cat /datas/access_log | tail -30
- 查看文件第3行到第10行:hdfs dfs -cat /datas/access_log | sed -n '3,10p'
六、hive
1.常用命令
-
创建内部表:
hive>create table tablename(name string,age int ,birth string) >row format delimited >fields terminated by ',' >lines terminated by '\n'; 或者: hive>create table (name string,age int ,birth string) row format delimited fields terminated by ',' lines terminated by '\n'; 区别:第一种写完之后,如果报错,只能显示任意一个 > 后面的代码 第二种写完后如果报错,可以全部出现 -
创建外部表:
hive>create external table tablename(name string,age int ,birth string) >row format delimited >fields terminated by ',' >lines terminated by '\n'; -
编辑表信息:
-
修改表名:alter table emp rename to employee;
-
修改字段:
alter table emp change name ename string;
alter table emp change salary salary double;
-
添加列:alter table emp add columns (dept string);
-
-
数据加载如入表:
load data [local] inpath 'filePath' [overwrite] into table tableName;
-
使用案例
load data local inpath '/opt/temp/hive_local.txt' overwrite into table employee;
-
-
查询语句与mysql基本一致!
2.自定义函数
写之前需要导入jar包依赖:
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
package com.xyz;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* @author 小勇子start
* @create 2021-10-06 13:26
*/
public class HiveOne extends UDF {
public String evaluate(String hsp) {
if (hsp.equals("协和医院") || hsp.equals("同济医院") || hsp.equals("四川大学华西医院") || hsp.equals("中国人民解放军总医院") || hsp.equals("第四军医大学西京医院"))
return "三甲";
else if(hsp.equals("复旦大学附属中山医院") || hsp.equals("中山大学附属第一医院") || hsp.equals("复旦大学附属华山医院") || hsp.equals("北京大学第一医院"))
return "二甲";
else if(hsp.equals("中国医科大学附属第一医院") || hsp.equals("中南大学湘雅二医院") || hsp.equals("北京大学第三医院"))
return "一甲";
else
return "";
}
}
3.使用自定义函数
-
将自定义好的函数打成jar包上传至Linux
-
启动hive
-
添加jar包:add jar /opt/test/xxxx.jar
-
创建自定义临时函数:create temporary function 方法名 as 'com.xyz.HiveOne';
使用案例:
hive> select h.hsp.zdy(h.hsp) , count(*) from tb_hospital h group by h.hsp;
补充:将结果写入本地文件中:
insert overwrite local directory '/opt/temp/xxx' row format delimited fields terminated by ',' select * from tb_xxx;
七、spark数据分析
1.Scala常用语法
运用maven创建项目,需要导入如下依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
-
main方法:
def main(args:Array[String]):Unit={ } -
变量
var i:Int=1 //在类中自带get和set功能 val a:Int=2 //常量,在类中只有get功能 var arr:Array[String]=Array("abc","bcd","cde") -
类型转换
var num:Int=20 var str:String=num.toString var num2:Int=str.toInt -
条件判断
var score:Int=88 if(score==100){ println("优秀") }else if (score>=90){ println("良好") }else{ println("继续加油") } -
循环:
//遍历arr var arr=Array("java","python","scala") //方式1 for(a<-arr){ println(a) } //方式2 arr.foreach(println) //循环1到1(包括1和10) for(a<-1 to 10){ println(a) } -
元组
//声明赋值: var t=(4.13,"hello",44) //取值: println(t._1) //4.13 println(t._2) //hello -
函数:
def test(x:Int,y:Int):Int={ x+y //返回值时不需要加return } -
RDD的创建
//使用集合、数组创建RDD val arr = Array(1,2,3,4,5) val rdd = sc.parallelize(arr) 或者 val rdd = sc.makeRDD(arr) rdd.collect() 转为数组 //通过外部存储创建RDD //Hdfs上: sc.textFile(“hdfs://master:9000/wordcount.txt”) //本地测试 sc.textFile(“data/xxx.csv”) //通过其他RDD得到新的RDD val rdd = sc.parallielize(Array(1,2,3,4,5)) arl rdd2 = rdd.map(_*2)
2.常用方法
-
计数器:
//定义累加器: val longAccum=sc.longAccumulator("count") //累加器增加: longAccum.add(1)//每次增加1 //获取累加器数据 print("累加器结果是:"+longAccum.value) -
去重:distinct()
文本行数:count()
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /** * @author 小勇子start * @create 2021-10-12 14:03 */ object DistinctDemo { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("test1") val sc=new SparkContext(sparkConf) val rdd=sc.textFile("data/distinct.txt") val count1:Long=rdd.count(); val rdd2=rdd.distinct() val count2:Long=rdd2.count() println("清除的数据条数有:"+(count1-count2)) // rdd2.saveAsTextFile("data/out1") sc.stop() } } -
过滤:filter :false删除,true保留
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /** * @author 小勇子start * @create 2021-10-12 14:03 */ object FilterDemo { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("test1") val sc = new SparkContext(sparkConf) val longAccum=sc.longAccumulator("count") val rdd = sc.textFile("data/test.txt") val rdd2 = rdd.filter(!_.startsWith("id")) //过滤表头 //val rdd2=rdd.filter(!_.endsWith("e")) //过滤以“e”结尾的数据 val rdd3 = rdd2.filter(x => {//过滤分数小于50的科目 val str = x.split(",") val score = str(2).toInt if (score > 50) true else{ longAccum.add(1) false } }) rdd3.saveAsTextFile("data/out3") print("分数小于50的数据条数是:"+longAccum.value) sc.stop() } } -
map() :适合用来格式化输出格式
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /** * @author 小勇子start * @create 2021-10-12 14:03 */ object MapDemo { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("test1") val sc = new SparkContext(sparkConf) val rdd = sc.textFile("data/test.txt") val rdd2 = rdd.filter(!_.startsWith("id")) //过滤表头 val rdd3=rdd2.map(x=>{ val str=x.split(",") val name=str(3) val score=str(2) val kc=str(1) val newStr=name+","+score+","+kc newStr }) rdd3.saveAsTextFile("data/out4") sc.stop() } } -
排序:sortBy() ,填两个值,前一个填根据排序的字段,后一个填升降序,默认升序
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /** * @author 小勇子start * @create 2021-10-12 14:03 */ object sortByDemo { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("test1") val sc = new SparkContext(sparkConf) val rdd = sc.textFile("data/test.txt") val rdd2 = rdd.filter(!_.startsWith("id")) val rdd3=rdd2.map(x=>{ val str=x.split(",") val name=str(3) val score=str(2) val kc=str(1) val newStr=name+","+score+","+kc newStr }).sortBy(x=>x.split(",")(1),ascending = false)//降序,默认为true rdd3.saveAsTextFile("data/out5") sc.stop() } }
3.单词计数案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-12 21:22
*/
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(sparkConf)
val rdd=sc.textFile("data/test2.txt")
val rdd2=rdd.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
//flatMap能把数据一次性读取出来,并按"," 分成若干个数据
//reduceByKey(_+_)表示每一个相同的key的value相加 _:代表key,1 :是value
//格式必须是:(k,v)才能使用该方法
rdd2.saveAsTextFile("data/out1")
}
}
4.求科目平均值案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-13 17:16
*/
object GroupByKeyDemo {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test2")
val sc= new SparkContext(sparkConf)
val rdd=sc.textFile("data/test.txt")
val rdd2=rdd.map(x=>{
val str=x.split(",")
val km=str(1)
val score=str(2).toFloat
(km,score)
}).groupByKey().map(x=>{
val km=x._1
var allScore:Float=0;
for(i<-x._2){
allScore+=i
}
km+"的平均分为:"+allScore/x._2.size
})
rdd2.saveAsTextFile("data/out2")
}
}
//groupByKey 根据(k,v)中的k分组,将所有k相同的v都放入同一个iterate中保存起来,返回一个(k,iterate(v1,v2,v3))
5.join案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-13 18:41
*/
object JoinDemo{
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test4")
val sc= new SparkContext(sparkConf)
val rdd1=sc.textFile("data/test.txt")
val rdd2=sc.textFile("data/test_2.txt")
val rdd1_2=rdd1.map(x=>{
val str=x.split(",")
val id=str(5).toInt
(id,x)
})
val rdd2_2=rdd2.map(x=>{
val str=x.split(",")
val id=str(0).toInt
(id,x)
})
rdd2_2.join(rdd1_2).map(x=>{
val str=x._2._2.replace(","+x._1,"")
x._2._1+","+str
}).saveAsTextFile("data/out4")
}
}
6.spark项目打jar包
7.运行jar包
以单词计数为例
[root@master bin]# pwd
/usr/local/src/spark/bin
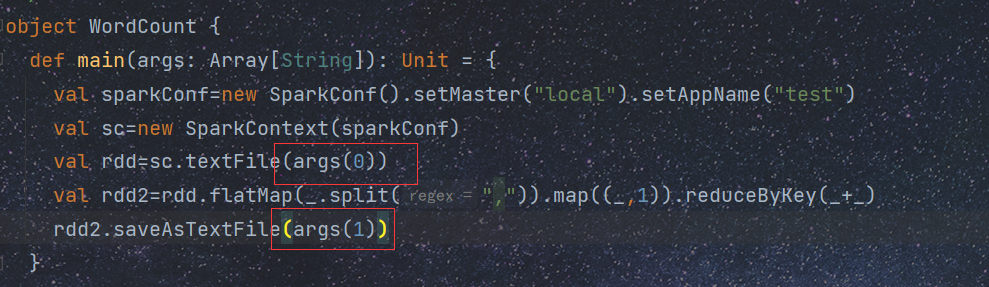
[root@master bin]#spark-submit --master spark:master:7707 --class com.xyz.WordCount /opt/test/ScalaDemo.jar hdfs://master:9000/test/test2.txt hdfs://master:9000/test/out1
--master 后面可以填 local 、spark等等
--class 后面填要运行的主类
/opt/test/ScalaDemo.jar 表示jar包位置
hdfs://master:9000/test/test2.txt 文件输入位置 不能写成 http://master:50070
hdfs://master:9000/test/out1 文件存储位置
输入输出位置与下面对应
八、python 中常用可视化工具库
a、Numpy常用属性及方法
为什么用它:它可以方便的使用数组,矩阵进行计算,包含线性代数。傅里叶变换、随机数生成等大量函数(处理数值型的数组)
import numpy as np
Numpy生成array的属性:
import numpy as np
x=np.array([1,2,3,4,5,6,7,8]) # 一维
x.shape #(8,)
X=np.array([[1,2,3,4],[5,6,7,8]]) # 二维数组
X.shape #(2,4)
#规律:从外往里数元素个数
操作函数
import numpy as np
A=np.arange(10).reshape(2,5) # np.arrage(10)--> array([0,1,2,3,4,5,6,7,8,9])
A.shape # (2,5) A=[[0,1,2,3,4],[5,6,7,8,9]]
test1=A+1 # array([[1,2,3,4,5],[6,7,8,9,10]])
test2=A+3 #array([[0,3,6,9,12],[15,18,21,24,27]])
#......
B=np.arange(1,11).reshape(2,5)
test3=A+B #test3=[[1,3,5,7,9],[11,13,15,17,19]]
test4=B-A #test4=[[1,1,1,1,1],[1,1,1,1,1]]
索引查询
# array[:10] 取前10个数
# array[-3:] 去最后3个数
#
import numpy as np
C=np.random.randint(1,100,10)
#C[-3:]=10#[77 1 30 3 31 10 92 10 10 10]
# 获取数组中最大的前N个数字、
#argsort() 传回排序后的索引下标
print(C[C.argsort()])#排序[ 5 11 31 39 53 53 85 88 95 99]
print(C[C.argsort()[-3:]])#取最大的3个元素[88 95 99]
Numpy中的数学统计函数
import numpy as np
t = np.array([1, 2, 3, 4, 5])
t1=t.sum()#15求和
t2 = t.mean()#3.0 平均值
t3=t.min()#1 最小值
t4=np.median(t) #3.0 中位数
t5 = t.var() # 2.0 方差
t6=t.std()#1.4142135623730951 标准差
Numpy的向量化操作
t = np.array([1, 2, 3, 4, 5])
n=t[t>3].size #注意!没有括号 当然len(t[t>3])也能实现,但是t[t>3].size性能更好,所有时间更短
print(n)
Numpy数组合并
t1=np.array([1,2,3,4])
#t2=np.array([5,6,7,8])
t2=np.array([[5,6,7,8],
[9,10,11,12]])
t3=np.vstack([t1,t2]) #[[1 2 3 4],[5 6 7 8]]
#t4=np.hstack([t1,t2]) #[1,2,3,4,5,6,7,8]
#注意:
#1.vstack:使用是必须保持每个一维数组里的元素里的个数相同
#即:t1=np.array([1,2,3,4])
# t2=np.array([[5,6,7,8],
# [9,10,11,12]])
# 这种情况下使用vstack会报错
#ValueError: all the input array dimensions for the concatenation axis must match exactly, but along dimension 1, the array at index 0 has size 3 and the array at index 1 has size 4
#2.同理:hstack使用是必须保持每个二维数组里的一维数组个数相同
#即:t1=np.array([1,2,3,4])
# t2=np.array([[5,6,7,8],
# [9,10,11,12]])
# 此时np.hstack([t1,t2]) 会报错
#ValueError: all the input arrays must have same number of dimensions, but the array at index 0 has 1 dimension(s) and the array at index 1 has 2 dimension(s)
案例二:
t1=np.array([[1,2,3,4],
[5,6,7,8]])
t2=np.array([[5,6,7,8],
[1,2,3,4]])
t3=np.vstack([t1,t2])
t4=np.hstack([t1,t2])
print(t3)
#[[1 2 3 4]
#[5 6 7 8]
#[5 6 7 8]
#[1 2 3 4]]
print(t4)
#[[1 2 3 4 5 6 7 8]
# [5 6 7 8 1 2 3 4]]
b、pandas
为什么用pandas:它能帮我们处理数值(基于numpy)和字符串及时间序列
pandas的常用方法
Series与DataFrame
data1=[{"name":"黄勇","age":20,"sex":"男"},{"name":"小勇子","age":21,"sex":"男"}]
data2={"name":["hy","xyz"],"age":[20,19],"sex":["男","男"]}
r1=pd.Series(data1)
"""0 {'name': '黄勇', 'age': 20, 'sex': '男'}
1 {'name': '小勇子', 'age': 21, 'sex': '男'}
dtype: object
"""
df1=pd.DataFrame(data1)
'''
name age sex
0 黄勇 20 男
1 小勇子 21 男
'''
r3 = pd.Series(data2)
'''
name [hy, xyz]
age [20, 19]
sex [男, 男]
dtype: object
'''
df2 = pd.DataFrame(data2)
'''
name age sex
0 hy 20 男
1 xyz 19 男
'''
r5=np.vstack([df1,df2])
'''
[['黄勇' 20 '男']
['小勇子' 21 '男']
['hy' 20 '男']
['xyz' 19 '男']]
'''
#print(df1["name"].values.reshape(-1, 1).shape) #(2,1) [[""],[""]]
r6=np.hstack([df1["name"].values.reshape(-1,1),df2["age"].values.reshape(-1,1)])
'''
[['黄勇' 20]
['小勇子' 19]]
'''
#选择多少行多少列
'''
data.csv
是否客栈,评论数,房间数,酒店总间夜
0,686,127,223
0,354,128,64
1,58,50,3
0,65,168,43
0,303,97,69
0,31,314,229'''
data= pd.read_csv("data/data_hotel_mult.csv")
x=data.iloc[:,:-1]#取所有行到最后一列,不包含最后一列
'''
是否客栈 评论数 房间数
0 0 686 127
1 0 354 128
2 1 58 50
3 0 65 168
4 0 303 97
5 0 31 314
'''
c、sklearn
逻辑回归
d、matplotlib
为什么用它:它能将数据进行可视化,将数据更 直观的呈现,使数据更加客观,更具说服力
使用:
# 导包
from matplotlib import pyplot as plt
绘图类型:
| 函数名称 | 描述 |
|---|---|
| Bar | 绘制条形图(柱状图) |
| Plot | 在坐标轴上画线或者标记 |
| Scatter | 绘制x与y的散点图 |
| hist | 绘制直方图 |
画图步骤:
#修改matplotlib默认的字体(需要显示中文就设置)
matplotlib.rc("font",family="KaiTi",weight="bold",size="18")
a = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
b= [0,0,0,0,0,0,0,0,1,1,1,1,1,1,2,2,2,1,1,1]
plt.figure(figsize=(20,8))
x=[i for i in range(11,31)]
#设置图名称
plt.title("我与同桌女朋友个数对比")
#设置轴名称
plt.xlabel("年龄")
plt.ylabel("女朋友个数")
#设置网格alpha为不透明度
plt.grid(alpha=0.3)
#label设置这条折线的图例名称
plt.plot(x,b,label="自己",lineStyle="dashed") #折线图
plt.plot(x,a,label="同桌")
#图例(显示图例,必须放在plot下)
plt.legend(loc="upper left")
# 设置x轴刻度
_xtick_labels = [f"{i}岁" for i in x]
plt.xticks(x,_xtick_labels)
plt.show()
各图中属性配置
plot()函数是绘制二维图形的最基本函数。用于画图它可以绘制点和线,语法格式如下:
# 常用语法
plot(x, y,ls='--',c='r',lw='12.5')
#解释:ls=lineStyle,c=color,lw=lineWidth
#有几条线,就调用几次plot()
marker 可以定义的符号如下:
| 标记 | 符号 | 描述 |
|---|---|---|
| "." |  |
点 |
| "None", " " or "" |  |
没有任何标记 |
| "*" | 星号 |
线类型:
| 线类型标记 | 描述 |
|---|---|
| '-' | 实线 |
| ':' | 点虚线 |
| '--' | 破折线(dashed) |
| '-.' | 点划线 |
颜色类型:
| 颜色标记 | 描述 |
|---|---|
| 'r' | 红色 |
| 'g' | 绿色 |
| 'b' | 蓝色 |
| 'c' | 青色 |
| 'm' | 品红 |
| 'y' | 黄色 |
| 'k' | 黑色 |
| 'w' | 白色 |
柱状图:
#水平柱状图:
plt.bar(x,y,width=0.8,color='r')
#垂直柱状图:
plt.barh(x,y)
散点图:
color='r' #所有点同一个颜色
color=['r','b'...] #定义每一个点的颜色
plt.scatter(x,y,c=color,s=30.4)
解释:s=size
直方图:
a=[131,98,125, 131, 124, 138, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119,128,121]
#组距
d=4
m=max(a)
n=min(a)
#画布
plt.figure(figsize=(20,8),dpi=80)
plt.hist(a)
plt.grid(alpha=0.3)
#设置刻度
plt.xticks(range(n,m+d,d))
plt.show()
九、flask
1.基础配置
初始化
from flask import Flask
app=Flask(__name__,static_url_path='/s',static_folder='statics')
#这里面的__name__指名程序所在的包或模块
#static_url_path='/s' 可以不传,默认为 /+static_folder
#static_folder='statics' 静态文件存储的文件夹,可以不传,默认为static
#template_folder 模板文件存储的文件夹,可以不传,默认为templates
集中管理项目所有配置信息
使用方式:Flask将配置信息保存到了app . config属性中,该属性可以按照字典类型进行操作。
读取:·
#方式1
app.config.get(name)
#方式2
app.config[name]
设置:
方式1:
#从配置对象中加载
#app.config.from_object(配置对象)
class DefaultConfig(object):
'''默认配置'''
SECRET_KEY='gldkrterlkfj'
app=Flask(__name__)
app.config.from_object(DefaultConfig)
方式2:
#从配置文件中加载
#app.config.from_pyfile(配置文件)
新建一个配置文件setting.py
SECRET_KEY='gldkrterlkfj'
在Flask程序中
app=Flask(__name__)
app.config.from_pyfile("setting.py")
@app.route("/")
def index():
print(app.config["SECRET_KEY"])
return "aaaa"
指定路由的请求方式
@app.route("/test",methods=["POST","GET"])
def test():
return "hello"
蓝图的使用
在同一个模块中创建蓝图
from flask import Flask
from flask import Blueprint
app=Flask(__name__)
#创建蓝图对象
test_bp=Blueprint("test",__name__)
#注册蓝图
app.register_blueprint(test_bp,url_prefix="/user")
@test_bp.route("/test")
def test():
return "aaaaa"
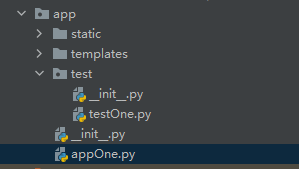
新建模块创建蓝图
目录结构如图所示:
app.test下
# _init_.py
from flask import Blueprint
#创建蓝图对象
test_bp=Blueprint("test",__name__)
#导入蓝图视图文件
from . import testOne
#testOne.py
from . import test_bp
@test_bp.route("/test")
def test():
return "success"
app下的
#_init_.py
from flask import Flask
from app.test import test_bp
app=Flask(__name__)
app.register_blueprint(test_bp,url_prefix="/user")
from app import app
from flask import render_template
@app.route("/")
def hello_world():
return render_template("echarts.html")
if __name__ == '__main__':
app.run()
2.常用语法
a. 路由返回一个静态页面
from flask import send_file
@app.route('/')
def bar():
return send_file("static/html/hello.html")
b. 路由返回一个templates模板
from flask import Flask, render_template
@app.route("/line")
def line():
return render_template("line.html")
c. 传参
后台:
@app.route("/pie")
def pie():
data =[] #要传的数据
return render_template("pie.html", datas=data)
HTML模板:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="/static/js/echarts.js"></script>
<script src="/static/js/jquery.min.js"></script>
</head>
<body>
<script>
//......此处省略n行代码
data: {{ datas | safe }}
//......此处省略n行代码
</script>
</body>
</html>
d.jinja2常用语法
1.控制结构:{% %}
2.去变量值:{{ }}
3.注释:{# #}
4.过滤器:内置函数和字符串处理函数
safe: 渲染时值不转义
capitialize: 把值的首字母转换成大写,其他子母转换为小写
lower: 把值转换成小写形式
upper: 把值转换成大写形式
title: 把值中每个单词的首字母都转换成大写
trim: 把值的首尾空格去掉
striptags: 渲染之前把值中所有的HTML标签都删掉
join: 拼接多个值为字符串
replace: 替换字符串的值
round: 默认对数字进行四舍五入,也可以用参数进行控制
int: 把值转换成整型
使用:{{ data | self }}
5.for循环:
{# 案例1:#}
{% for d in data%}
<li>{{d.name}}</li>
{%endfor%}
{# 案例2:#}
[{% for a in addrs %} '{{ a }}', {% endfor %} ]
3.连接数据库及使用:
from flask_sqlalchemy import SQLAlchemy
import pymysql
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:123456@localhost:3306/flask_db1'
#mysql+pymysql://用户名:密码@ip:端口号/数据库
db = SQLAlchemy()
db.init_app(app)
#对应数据库表的映射
class Student(db.Model):
__tableName__ = 'tb_student'
s_id = db.Column(db.Integer, primary_key=True)
s_name = db.Column(db.String(50))
s_sex = db.Column(db.String(10))
s_birthday = db.Column(db.String(50))
s_addr = db.Column(db.String(50))
s_cid = db.Column(db.Integer)
@app.route('/')
def bar(): # put application's code here
sql = 'select s.s_addr,count(*) from tb_student s group by s.s_addr;'
result = db.session.execute(sql).fetchall()
addrs = []
count = []
for i in result:
addrs.append(i[0])
count.append(i[1])
return send_file("bar.html", addrs=addrs, count=count)
echarts
常用属性
可以看:xyongz的分类:echarts图表
// 标题配置
title: {
backgroundColor: 'rgba(0,0,0,0)',
borderColor: '#ccc', // 标题边框颜色
borderWidth: 0, // 标题边框线宽,单位px,默认为0(无边框)
padding: 5,// 标题内边距,单位px,默认各方向内边距为5, 接受数组分别设定上右下左边距,同css
itemGap: 10,// 主副标题纵向间隔,单位px,默认为10,
left: 'center',//主副标题的水平位置
top: 'center',//主副标题的垂直位置
textStyle: {
fontSize: 18,
fontWeight:'bold', //字体粗细normal、bold、bolder、lighter、100 | 200 | 300|400...
color: 'red' ,// 主标题文字颜色
fontStyle:'oblique'//主标题文字字体的风格 normal(默认)、italic、oblique
},
subtext:'副标题,支持使用 \n 换行'
subtextStyle: {
color: '#aaa' // 副标题文字颜色
}
},
// 图例组件配置:图例组件展现了不同系列的标记(symbol),颜色和名字。可以通过点击图例控制哪些系列不显示。
legend: {
left:20, //图例组件离容器左侧的距离。20 ,20% ,"left","center","right"
top:20,
right:20,
bottom:20,
width:200,//图例组件的宽度,"auto",200.....
height:200,
orient:'vertical',//图例列表的布局朝向。horizontal、vertical
align:'left',//图例标记和文本的对齐 auto(默认)、left、right
padding:5,//图例内边距,单位px,默认各方向内边距为5,接受数组分别设定上右下左边距。
itemGap:10,//图例每项之间的间隔。横向布局时为水平间隔,纵向布局时为纵向间隔。
itemWidth:25,//图例标记的图形宽度
itemHeight:14,//图例标记的图形高度
formatter:null,//用来格式化图例文本,支持字符串模板和回调函数两种形式。
// 使用字符串模板,模板变量为图例名称 {name}
//formatter: 'Legend {name}'
// 使用回调函数
//formatter: function (name) {
//return 'Legend ' + name;
//}
selectedMode:true,
//图例选择的模式,控制是否可以通过点击图例改变系列的显示状态。默认开启图例选择,可以设成 false 关闭。
//除此之外也可以设成 'single' 或者 'multiple' 使用单选或者多选模式。
inactiveColor:'red',//图例关闭时的颜色
selected:{//图例选中状态表
// 选中'系列1'
'系列1': true,
// 不选中'系列2'
'系列2': false
},
textStyle:{
//与上面类似
},
//图例的数据数组。数组项通常为一个字符串,每一项代表一个系列的 name
data:[{
name: '系列1',
// 强制设置图形为圆。
icon: 'circle',
//包括: 'circle', 'rect', 'roundRect', 'triangle', 'diamond', 'pin', 'arrow'
// 设置文本为红色
textStyle: {
color: 'red'
}
},
{
name: '系列2',
// 强制设置图形为圆。
icon: 'rect',
// 设置文本为红色
textStyle: {
color: 'red'
}
}]
//或者:data["name1","name2","name3","name4"]
},
// 直角坐标系网格
grid: {
x: 80,
y: 60,
x2: 80,
y2: 60,
// width: {totalWidth} - x - x2,
// height: {totalHeight} - y - y2,
backgroundColor: 'rgba(0,0,0,0)',
borderWidth: 1,
borderColor: '#ccc'
},
//x坐标轴的配置:
xAxis:{
type:'category',//坐标轴类型
//'value' 数值轴,适用于连续数据。
//'category' 类目轴,适用于离散的类目数据,为该类型时必须通过 data 设置类目数据。
//'time' 时间轴,适用于连续的时序数据,与数值轴相比时间轴带有时间的格式化,在刻度计算上也有所不同,例如会根据跨度的范围来决定使用月,星期,日还是小时范围的刻度。
// 'log' 对数轴。适用于对数数据。
name:"名称",
nameLocation:'end',//'start'、'middle'、'end'
data: ['周一', '周二', '周三', '周四', '周五', '周六', '周日']//数据
//data: [{
//value: '周一',
// 突出周一
//textStyle: {
//fontSize: 20,
// color: 'red'
//}
//}, '周二', '周三', '周四', '周五', '周六', '周日']
},
//y轴
yAxis:{
//y与x轴类似
}
toolbox: {
orient: 'horizontal', // 布局方式,默认为水平布局,可选为:
// 'horizontal' ¦ 'vertical'
x: 'right', // 水平安放位置,默认为全图右对齐,可选为:
// 'center' ¦ 'left' ¦ 'right'
// ¦ {number}(x坐标,单位px)
y: 'top', // 垂直安放位置,默认为全图顶端,可选为:
// 'top' ¦ 'bottom' ¦ 'center'
// ¦ {number}(y坐标,单位px)
color : ['#1e90ff','#22bb22','#4b0082','#d2691e'],
backgroundColor: 'rgba(0,0,0,0)', // 工具箱背景颜色
borderColor: '#ccc', // 工具箱边框颜色
borderWidth: 0, // 工具箱边框线宽,单位px,默认为0(无边框)
padding: 5, // 工具箱内边距,单位px,默认各方向内边距为5,
// 接受数组分别设定上右下左边距,同css
itemGap: 10, // 各个item之间的间隔,单位px,默认为10,
// 横向布局时为水平间隔,纵向布局时为纵向间隔
itemSize: 16, // 工具箱图形宽度
featureImageIcon : {}, // 自定义图片icon
featureTitle : {
mark : '辅助线开关',
markUndo : '删除辅助线',
markClear : '清空辅助线',
dataZoom : '区域缩放',
dataZoomReset : '区域缩放后退',
dataView : '数据视图',
lineChart : '折线图切换',
barChart : '柱形图切换',
restore : '还原',
saveAsImage : '保存为图片'
}
},
// 提示框
tooltip: {
trigger: 'item', // 触发类型,默认数据触发,见下图,可选为:'item'(无类目轴时使用) ¦ 'axis'(有类目轴时使用)
showDelay: 20, // 显示延迟,添加显示延迟可以避免频繁切换,单位ms
hideDelay: 100, // 隐藏延迟,单位ms
transitionDuration : 0.4, // 动画变换时间,单位s
backgroundColor: 'rgba(0,0,0,0.7)', // 提示背景颜色,默认为透明度为0.7的黑色
borderColor: '#333', // 提示边框颜色
borderRadius: 4, // 提示边框圆角,单位px,默认为4
borderWidth: 0, // 提示边框线宽,单位px,默认为0(无边框)
padding: 5, // 提示内边距,单位px,默认各方向内边距为5,
// 接受数组分别设定上右下左边距,同css
axisPointer : { // 坐标轴指示器,坐标轴触发有效
type : 'line', // 默认为直线,可选为:'line' | 'shadow'
lineStyle : { // 直线指示器样式设置
color: '#48b',
width: 2,
type: 'solid'
},
shadowStyle : { // 阴影指示器样式设置
width: 'auto', // 阴影大小
color: 'rgba(150,150,150,0.3)' // 阴影颜色
}
},
formatter:'{b0}: {c0}<br />{b1}: {c1}',
//模板变量有 {a}, {b},{c},{d},{e},分别表示系列名,数据名,数据值等。 在 trigger 为 'axis' 的时候,会有多个系列的数据,此时可以通过 {a0}, {a1}, {a2} 这种后面加索引的方式表示系列的索引。 不同图表类型下的 {a},{b},{c},{d} 含义不一样。 其中变量{a}, {b}, {c}, {d}在不同图表类型下代表数据含义为:
//折线(区域)图、柱状(条形)图、K线图 : {a}(系列名称),{b}(类目值),{c}(数值), {d}(无)
//散点图(气泡)图 : {a}(系列名称),{b}(数据名称),{c}(数值数组), {d}(无)
//地图 : {a}(系列名称),{b}(区域名称),{c}(合并数值), {d}(无)
//饼图、仪表盘、漏斗图: {a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
textStyle: {
color: '#fff'
}
},
}
常用图表默认代码:
可以看:xyongz的分类:echarts图标
a、折线图
1)基础折线图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
xAxis: {
type: 'category',
data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
},
yAxis: {
type: 'value'
},
series: [
{
data: [150, 230, 224, 218, 135, 147, 260],
type: 'line'
}
]
};
option && myChart.setOption(option);
2)折线叠堆图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
title: {
text: 'Stacked Line'
},
tooltip: {
trigger: 'axis'
},
legend: {
data: ['Email', 'Union Ads', 'Video Ads', 'Direct', 'Search Engine']
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
toolbox: {
feature: {
saveAsImage: {}
}
},
xAxis: {
type: 'category',
boundaryGap: false,
data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
},
yAxis: {
type: 'value'
},
series: [
{
name: 'Email',
type: 'line',
stack: 'Total',
data: [120, 132, 101, 134, 90, 230, 210]
},
{
name: 'Union Ads',
type: 'line',
stack: 'Total',
data: [220, 182, 191, 234, 290, 330, 310]
},
{
name: 'Video Ads',
type: 'line',
stack: 'Total',
data: [150, 232, 201, 154, 190, 330, 410]
},
{
name: 'Direct',
type: 'line',
stack: 'Total',
data: [320, 332, 301, 334, 390, 330, 320]
},
{
name: 'Search Engine',
type: 'line',
stack: 'Total',
data: [820, 932, 901, 934, 1290, 1330, 1320]
}
]
};
option && myChart.setOption(option);
b、柱状图
1)基础柱状图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
xAxis: {
type: 'category',
data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
},
yAxis: {
type: 'value'
},
series: [
{
data: [120, 200, 150, 80, 70, 110, 130],
type: 'bar'
}
]
};
option && myChart.setOption(option);
2)瀑布图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
title: {
text: 'Waterfall Chart',
subtext: 'Living Expenses in Shenzhen'
},
tooltip: {
trigger: 'axis',
axisPointer: {
type: 'shadow'
},
formatter: function (params) {
var tar = params[1];
return tar.name + '<br/>' + tar.seriesName + ' : ' + tar.value;
}
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
xAxis: {
type: 'category',
data: ['Total', 'Rent', 'Utilities', 'Transportation', 'Meals', 'Other']
},
yAxis: {
type: 'value'
},
series: [
{
name: 'Placeholder',
type: 'bar',
stack: 'Total',
itemStyle: {
borderColor: 'transparent',//transparent 透明
color: 'transparent'
},
emphasis: {//强调颜色(个人认为没必要写)
itemStyle: {
borderColor: 'transparent',
color: 'transparent'
}
},
data: [0, 1700, 1400, 1200, 300, 0]
},
{
name: 'Life Cost',
type: 'bar',
stack: 'Total',
label: {
show: true,
position: 'inside'
},
data: [2900, 1200, 300, 200, 900, 300]
}
]
};
option && myChart.setOption(option);
c、堆叠柱状图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
tooltip: {
trigger: 'axis',
axisPointer: {
type: 'shadow'
}
},
legend: {},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
xAxis: [
{
type: 'category',
data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
}
],
yAxis: [
{
type: 'value'
}
],
series: [
{
name: 'Direct',
type: 'bar',
emphasis: {
focus: 'series'
},
data: [320, 332, 301, 334, 390, 330, 320]
},
{
name: 'Email',
type: 'bar',
stack: 'Ad',
emphasis: {
focus: 'series'
},
data: [120, 132, 101, 134, 90, 230, 210]
},
{
name: 'Union Ads',
type: 'bar',
stack: 'Ad',
emphasis: {
focus: 'series'
},
data: [220, 182, 191, 234, 290, 330, 310]
},
{
name: 'Video Ads',
type: 'bar',
stack: 'Ad',
emphasis: {
focus: 'series'
},
data: [150, 232, 201, 154, 190, 330, 410]
},
{
name: 'Search Engine',
type: 'bar',
data: [862, 1018, 964, 1026, 1679, 1600, 1570],
emphasis: {
focus: 'series'
},
markLine: {
lineStyle: {
type: 'dashed'
},
data: [[{ type: 'min' }, { type: 'max' }]]
}
},
{
name: 'Baidu',
type: 'bar',
barWidth: 5,
stack: 'Search Engine',
emphasis: {
focus: 'series'
},
data: [620, 732, 701, 734, 1090, 1130, 1120]
},
{
name: 'Google',
type: 'bar',
stack: 'Search Engine',
emphasis: {
focus: 'series'
},
data: [120, 132, 101, 134, 290, 230, 220]
},
{
name: 'Bing',
type: 'bar',
stack: 'Search Engine',
emphasis: {
focus: 'series'
},
data: [60, 72, 71, 74, 190, 130, 110]
},
{
name: 'Others',
type: 'bar',
stack: 'Search Engine',
emphasis: {
focus: 'series'
},
data: [62, 82, 91, 84, 109, 110, 120]
}
]
};
option && myChart.setOption(option);
d、饼图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
option = {
title: {
text: 'Referer of a Website',
subtext: 'Fake Data',
left: 'center'
},
tooltip: {
trigger: 'item'
},
legend: {
orient: 'vertical',
left: 'left'
},
series: [
{
name: 'Access From',
type: 'pie',
radius: '50%',
data:[
{ value: 1048, name: 'Search Engine' },
{ value: 735, name: 'Direct' },
{ value: 580, name: 'Email' },
{ value: 484, name: 'Union Ads' },
{ value: 300, name: 'Video Ads' }
],
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
option && myChart.setOption(option);
e、南丁格尔玫瑰图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
title: {
text: 'Nightingale Chart',
subtext: 'Fake Data',
left: 'center'
},
tooltip: {
trigger: 'item',
formatter: '{a} <br/>{b} : {c} ({d}%)'
},
legend: {
left: 'center',
top: 'bottom',
data: ['rose1','rose2', 'rose3', 'rose4', 'rose5','rose6','rose7','rose8']
},
toolbox: {
show: true,
feature: {
mark: { show: true },
dataView: { show: true, readOnly: false },
restore: { show: true },
saveAsImage: { show: true }
}
},
series: [
{
name: 'Radius Mode',
type: 'pie',
radius: [20, 140],
center: ['25%', '50%'],
roseType: 'radius',
itemStyle: {
borderRadius: 5
},
label: {
show: false
},
emphasis: {
label: {
show: true
}
},
data: [
{ value: 40, name: 'rose 1' },
{ value: 33, name: 'rose 2' },
{ value: 28, name: 'rose 3' },
{ value: 22, name: 'rose 4' },
{ value: 20, name: 'rose 5' },
{ value: 15, name: 'rose 6' },
{ value: 12, name: 'rose 7' },
{ value: 10, name: 'rose 8' }
]
},
{
name: 'Area Mode',
type: 'pie',
radius: [20, 140],
center: ['75%', '50%'],
roseType: 'area',
itemStyle: {
borderRadius: 5
},
data: [
{ value: 30, name: 'rose 1' },
{ value: 28, name: 'rose 2' },
{ value: 26, name: 'rose 3' },
{ value: 24, name: 'rose 4' },
{ value: 22, name: 'rose 5' },
{ value: 20, name: 'rose 6' },
{ value: 18, name: 'rose 7' },
{ value: 16, name: 'rose 8' }
]
}
]
};
option && myChart.setOption(option);
f、基础雷达图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
title: {
text: 'Basic Radar Chart'
},
legend: {
data: ['Allocated Budget', 'Actual Spending']
},
radar: {
// shape: 'circle',
indicator: [//指标
{ name: 'Sales', max: 6500 },
{ name: 'Administration', max: 16000 },
{ name: 'Information Technology', max: 30000 },
{ name: 'Customer Support', max: 38000 },
{ name: 'Development', max: 52000 },
{ name: 'Marketing', max: 25000 }
]
},
series: [
{
name: 'Budget vs spending',
type: 'radar',
data: [
{
value: [4200, 3000, 20000, 35000, 50000, 18000],
name: 'Allocated Budget'
},
{
value: [5000, 14000, 28000, 26000, 42000, 21000],
name: 'Actual Spending'
}
]
}
]
};
option && myChart.setOption(option);
g、数据聚合图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
// See https://github.com/ecomfe/echarts-stat
echarts.registerTransform(ecStat.transform.clustering);
const data = [
[3.275154, 2.957587],
[-3.344465, 2.603513],
[0.355083, -3.376585],
[1.852435, 3.547351],
[-2.078973, 2.552013],
[-0.993756, -0.884433],
[2.682252, 4.007573],
[-3.087776, 2.878713],
[-1.565978, -1.256985],
[2.441611, 0.444826],
[-0.659487, 3.111284],
[-0.459601, -2.618005],
[2.17768, 2.387793],
[-2.920969, 2.917485],
[-0.028814, -4.168078],
[3.625746, 2.119041],
[-3.912363, 1.325108],
[-0.551694, -2.814223],
[2.855808, 3.483301],
[-3.594448, 2.856651],
[0.421993, -2.372646],
[1.650821, 3.407572],
[-2.082902, 3.384412],
[-0.718809, -2.492514],
[4.513623, 3.841029],
[-4.822011, 4.607049],
[-0.656297, -1.449872],
[1.919901, 4.439368],
[-3.287749, 3.918836],
[-1.576936, -2.977622],
[3.598143, 1.97597],
[-3.977329, 4.900932],
[-1.79108, -2.184517],
[3.914654, 3.559303],
[-1.910108, 4.166946],
[-1.226597, -3.317889],
[1.148946, 3.345138],
[-2.113864, 3.548172],
[0.845762, -3.589788],
[2.629062, 3.535831],
[-1.640717, 2.990517],
[-1.881012, -2.485405],
[4.606999, 3.510312],
[-4.366462, 4.023316],
[0.765015, -3.00127],
[3.121904, 2.173988],
[-4.025139, 4.65231],
[-0.559558, -3.840539],
[4.376754, 4.863579],
[-1.874308, 4.032237],
[-0.089337, -3.026809],
[3.997787, 2.518662],
[-3.082978, 2.884822],
[0.845235, -3.454465],
[1.327224, 3.358778],
[-2.889949, 3.596178],
[-0.966018, -2.839827],
[2.960769, 3.079555],
[-3.275518, 1.577068],
[0.639276, -3.41284]
];
var CLUSTER_COUNT = 6;
var DIENSIION_CLUSTER_INDEX = 2;
var COLOR_ALL = [
'#37A2DA',
'#e06343',
'#37a354',
'#b55dba',
'#b5bd48',
'#8378EA',
'#96BFFF'
];
var pieces = [];
for (var i = 0; i < CLUSTER_COUNT; i++) {
pieces.push({
value: i,
label: 'cluster ' + i,
color: COLOR_ALL[i]
});
}
option = {
dataset: [
{
source: data
},
{
transform: {
type: 'ecStat:clustering',
// print: true,
config: {
clusterCount: CLUSTER_COUNT,
outputType: 'single',
outputClusterIndexDimension: DIENSIION_CLUSTER_INDEX
}
}
}
],
tooltip: {
position: 'top'
},
visualMap: {
type: 'piecewise',
top: 'middle',
min: 0,
max: CLUSTER_COUNT,
left: 10,
splitNumber: CLUSTER_COUNT,
dimension: DIENSIION_CLUSTER_INDEX,
pieces: pieces
},
grid: {
left: 120
},
xAxis: {},
yAxis: {},
series: {
type: 'scatter',
encode: { tooltip: [0, 1] },
symbolSize: 15,
itemStyle: {
borderColor: '#555'
},
datasetIndex: 1
}
};
option && myChart.setOption(option);
h、气泡图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
const data = [
[
[28604, 77, 17096869, 'Australia', 1990],
[31163, 77.4, 27662440, 'Canada', 1990],
[1516, 68, 1154605773, 'China', 1990],
[13670, 74.7, 10582082, 'Cuba', 1990],
[28599, 75, 4986705, 'Finland', 1990],
[29476, 77.1, 56943299, 'France', 1990],
[31476, 75.4, 78958237, 'Germany', 1990],
[28666, 78.1, 254830, 'Iceland', 1990],
[1777, 57.7, 870601776, 'India', 1990],
[29550, 79.1, 122249285, 'Japan', 1990],
[2076, 67.9, 20194354, 'North Korea', 1990],
[12087, 72, 42972254, 'South Korea', 1990],
[24021, 75.4, 3397534, 'New Zealand', 1990],
[43296, 76.8, 4240375, 'Norway', 1990],
[10088, 70.8, 38195258, 'Poland', 1990],
[19349, 69.6, 147568552, 'Russia', 1990],
[10670, 67.3, 53994605, 'Turkey', 1990],
[26424, 75.7, 57110117, 'United Kingdom', 1990],
[37062, 75.4, 252847810, 'United States', 1990]
],
[
[44056, 81.8, 23968973, 'Australia', 2015],
[43294, 81.7, 35939927, 'Canada', 2015],
[13334, 76.9, 1376048943, 'China', 2015],
[21291, 78.5, 11389562, 'Cuba', 2015],
[38923, 80.8, 5503457, 'Finland', 2015],
[37599, 81.9, 64395345, 'France', 2015],
[44053, 81.1, 80688545, 'Germany', 2015],
[42182, 82.8, 329425, 'Iceland', 2015],
[5903, 66.8, 1311050527, 'India', 2015],
[36162, 83.5, 126573481, 'Japan', 2015],
[1390, 71.4, 25155317, 'North Korea', 2015],
[34644, 80.7, 50293439, 'South Korea', 2015],
[34186, 80.6, 4528526, 'New Zealand', 2015],
[64304, 81.6, 5210967, 'Norway', 2015],
[24787, 77.3, 38611794, 'Poland', 2015],
[23038, 73.13, 143456918, 'Russia', 2015],
[19360, 76.5, 78665830, 'Turkey', 2015],
[38225, 81.4, 64715810, 'United Kingdom', 2015],
[53354, 79.1, 321773631, 'United States', 2015]
]
];
option = {
backgroundColor: new echarts.graphic.RadialGradient(0.3, 0.3, 0.8, [
{
offset: 0,
color: '#f7f8fa'
},
{
offset: 1,
color: '#cdd0d5'
}
]),
title: {
text: 'Life Expectancy and GDP by Country',
left: '5%',
top: '3%'
},
legend: {
right: '10%',
top: '3%',
data: ['1990', '2015']
},
grid: {
left: '8%',
top: '10%'
},
xAxis: {
splitLine: {
lineStyle: {
type: 'dashed'
}
}
},
yAxis: {
splitLine: {
lineStyle: {
type: 'dashed'
}
},
scale: true
},
series: [
{
name: '1990',
data: data[0],
type: 'scatter',
symbolSize: function (data) {
return Math.sqrt(data[2]) / 5e2;
},
emphasis: {
focus: 'series',
label: {
show: true,
formatter: function (param) {
return param.data[3];
},
position: 'top'
}
},
itemStyle: {
shadowBlur: 10,
shadowColor: 'rgba(120, 36, 50, 0.5)',
shadowOffsetY: 5,
color: new echarts.graphic.RadialGradient(0.4, 0.3, 1, [
{
offset: 0,
color: 'rgb(251, 118, 123)'
},
{
offset: 1,
color: 'rgb(204, 46, 72)'
}
])
}
},
{
name: '2015',
data: data[1],
type: 'scatter',
symbolSize: function (data) {
return Math.sqrt(data[2]) / 5e2;
},
emphasis: {
focus: 'series',
label: {
show: true,
formatter: function (param) {
return param.data[3];
},
position: 'top'
}
},
itemStyle: {
shadowBlur: 10,
shadowColor: 'rgba(25, 100, 150, 0.5)',
shadowOffsetY: 5,
color: new echarts.graphic.RadialGradient(0.4, 0.3, 1, [
{
offset: 0,
color: 'rgb(129, 227, 238)'
},
{
offset: 1,
color: 'rgb(25, 183, 207)'
}
])
}
}
]
};
option && myChart.setOption(option);
i、k线图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
xAxis: {
data: ['2017-10-24', '2017-10-25', '2017-10-26', '2017-10-27']
},
yAxis: {},
series: [
{
type: 'candlestick',
data: [
[20, 34, 10, 38],
[40, 35, 30, 50],
[31, 38, 33, 44],
[38, 15, 5, 42]
]
}
]
};
option && myChart.setOption(option);
j、基础盒须图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
title: [
{
text: 'Michelson-Morley Experiment',
left: 'center'
},
{
text: 'upper: Q3 + 1.5 * IQR \nlower: Q1 - 1.5 * IQR',
borderColor: '#999',
borderWidth: 1,
textStyle: {
fontWeight: 'normal',
fontSize: 14,
lineHeight: 20
},
left: '10%',
top: '90%'
}
],
dataset: [
{
// prettier-ignore
source: [
[850, 740, 900, 1070, 930, 850, 950, 980, 980, 880, 1000, 980, 930, 650, 760, 810, 1000, 1000, 960, 960],
[960, 940, 960, 940, 880, 800, 850, 880, 900, 840, 830, 790, 810, 880, 880, 830, 800, 790, 760, 800],
[880, 880, 880, 860, 720, 720, 620, 860, 970, 950, 880, 910, 850, 870, 840, 840, 850, 840, 840, 840],
[890, 810, 810, 820, 800, 770, 760, 740, 750, 760, 910, 920, 890, 860, 880, 720, 840, 850, 850, 780],
[890, 840, 780, 810, 760, 810, 790, 810, 820, 850, 870, 870, 810, 740, 810, 940, 950, 800, 810, 870]
]
},
{
transform: {
type: 'boxplot',
config: { itemNameFormatter: 'expr {value}' }
}
},
{
fromDatasetIndex: 1,
fromTransformResult: 1
}
],
tooltip: {
trigger: 'item',
axisPointer: {
type: 'shadow'
}
},
grid: {
left: '10%',
right: '10%',
bottom: '15%'
},
xAxis: {
type: 'category',
boundaryGap: true,
nameGap: 30,
splitArea: {
show: false
},
splitLine: {
show: false
}
},
yAxis: {
type: 'value',
name: 'km/s minus 299,000',
splitArea: {
show: true
}
},
series: [
{
name: 'boxplot',
type: 'boxplot',
datasetIndex: 1
},
{
name: 'outlier',
type: 'scatter',
datasetIndex: 2
}
]
};
option && myChart.setOption(option);
k、漏斗图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
title: {
text: 'Funnel'
},
tooltip: {
trigger: 'item',
formatter: '{a} <br/>{b} : {c}%'
},
toolbox: {
feature: {
dataView: { readOnly: false },
restore: {},
saveAsImage: {}
}
},
legend: {
data: ['Show', 'Click', 'Visit', 'Inquiry', 'Order']
},
series: [
{
name: 'Funnel',
type: 'funnel',
left: '10%',
top: 60,
bottom: 60,
width: '80%',
min: 0,
max: 100,
minSize: '0%',
maxSize: '100%',
sort: 'descending',
gap: 2,
label: {
show: true,
position: 'inside'
},
labelLine: {
length: 10,
lineStyle: {
width: 1,
type: 'solid'
}
},
itemStyle: {
borderColor: '#fff',
borderWidth: 1
},
emphasis: {
label: {
fontSize: 20
}
},
data: [
{ value: 60, name: 'Visit' },
{ value: 40, name: 'Inquiry' },
{ value: 20, name: 'Order' },
{ value: 80, name: 'Click' },
{ value: 100, name: 'Show' }
]
}
]
};
option && myChart.setOption(option);
l、仪表图
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
tooltip: {
formatter: '{a} <br/>{b} : {c}%'
},
series: [
{
name: 'Pressure',
type: 'gauge',
detail: {
formatter: '{value}'
},
data: [
{
value: 50,
name: 'SCORE'
}
]
}
]
};
option && myChart.setOption(option);


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?