
CSDN大数据技术:
部分摘录:
加州大学伯克利分校AMP实验室博士Matei Zaharia:Spark的现状和未来 ----(Matei Zaharia是加州大学伯克利分校AMP实验室博士研究生,Databricks公司的联合创始人兼现任CTO。Zaharia致力于于大规模数据密集型计算的系统和算法。研究项目包括:Spark、Shark、Multi-Resource Fairness、MapReduce Scheduling、SNAP Sequence Aligner)
Spark是发源于美国加州大学伯克利分校AMPLab的集群计算平台,立足于内存计算,从多迭代批量处理出发,兼收并蓄数据仓库、流处理和图计算等多种计算范式,是罕见的全能选手。
Project History:
Spark started as research project in 2009
Open sourced in 2010
Growing community since
Entered Apache lncubator in June 2013
Release Growth:
Spark 0.6 ---- Java API、Maven、standalone mode ,17 contributors
Spark 0.7 ---- Python API、Spark Streaming ,31 contributors
Spark 0.8 ---- YARN、MLlib、monitoring UI ,67 contributors ---- High availability for standalone mode (0.8.1)
Spark 0.9 ---- Scala 2.10 support、Configuration system、Spark Streaming improvement
Projects Bulit on Spark:
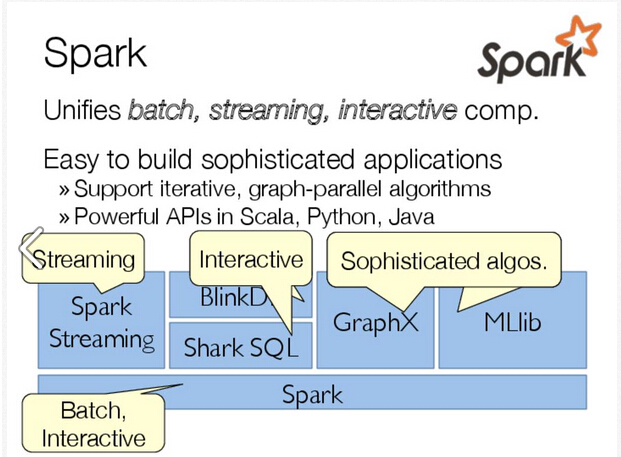
Shark(SQL)、Spark Streaming(real-time)、GraphX(graph)、MLbase(machine learning)
Databricks公司CEO Ion Stoica:将数据转化为价值 ----(Ion Stoica是UC Berkeley计算机教授,AMPLab共同创始人,弹性P2P协议Chord、集群内存计算框架Spark、集群资源管理平台Mesos都出自他)
Turning Data into Value
What do We Need?
interactive queries(交互式查询) ---- enable faster decision
Queries on streaming data(基于数据流的查询) ---- enable decisions on real-time data ---- Eg:fraud detection(欺诈检测)、detect DDoS attacks(检测DDoS攻击)
Sophisticated data processing(复杂的数据处理) ---- enable "better" decision

Our Goal:
Support batch、Streaming、and interactive computation(批处理、流处理、交互计算)...... in a unified framework
Easy to develop sophisticated algorithms(e.g..,graph,ML algos)
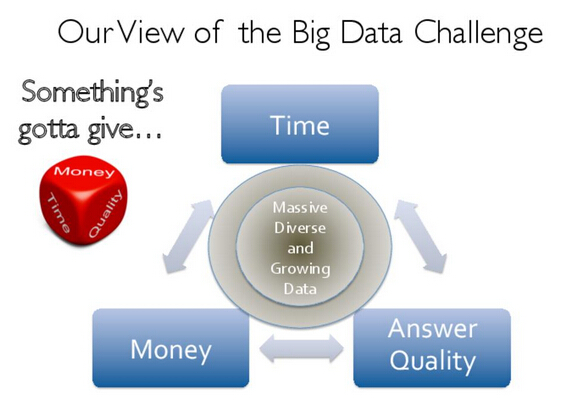
Big Data Challenge:Time 、Money 、Answer Quality
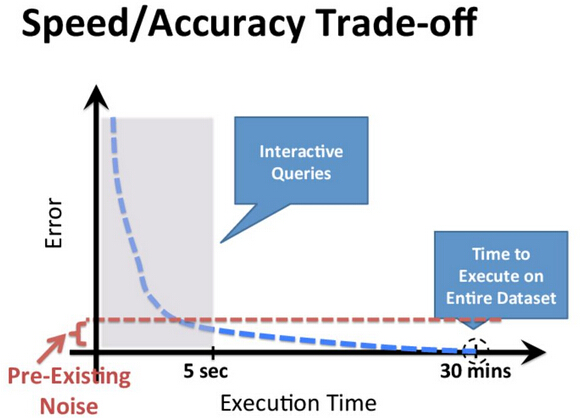
处理速度与精确性的权衡:反比
Tim Tully :集成Spark/Shark到雅虎数据分析平台
Sharethrough数据专家Ryan Weald:产品化Spark流媒体
Keys to Fault Tolerance:
Receive fault tolerance ---- Use Actors with supervisor、Use self healing connection pools
Monitoring job progress
RDDs:弹性分布式数据集
Low latency & Scale (低延时&大规模)
iterative and Interactive computation (迭代式和交互式计算)
Databricks创始人Patrick Wendell:理解Spark应用程序的性能 ---- (专注于大规模数据密集型计算。致力于Spark的性能基准测试,同时是spark-perf的合著者。此次峰会他就Spark 深度挖掘、UI概述和测试设备、普通性能和错误)
Summary of Components:
Tasks:Fundamental unit of work
Stage:Set of tasks that run in parallel
DAG:Logical graph of RDD operations
RDD:Parallel dataset with partitions
Demo of perf UI ---- Problems:
Scheduling and launching tasks
Execution of tasks
Writing data between stages
Collecting results
Databricks客户端解决方案主管Pat McDonough:用Spark并行程序设计 ---- (从Spark的性能、组件等方面全面介绍Spark的各种优异性能)



UC Berkeley博士Tathagata Das:用Spark流实时大数据处理 ---- (什么是Spark流,为什么选择Spark流,其性能和容错机制)



DStreams+RDDs=Power
Fault-tolerance:
Batches of input data are replicated in memory for fault-tolerance
Data lost due to worker failure,can be recomputed from replicated input data
All transformations are fault-tolerant,and exactly-once transformations
Higher throughput than Storm:
Spark Streaming:670K records/sec/node
Storm:115K records/sec/node
Fast Fault Recovery:
Recovers from faults/stragglers within 1 sec
Spark 0.9 in Jan 2014 ---- out of alpha
Automated master fault recovery
Performance optimizations
Web UI,and better monitoring capabilities
Cluster Manager UI ---- Standalone mode:<master>:8080
Executor Logs ---- Stored by cluster manager on each worker
Spark Driver Logs ---- Spark initializes a log4j when created ,Include log4j.properties file on the classpath
Application Web UI ---- http://spark-application-host:4040 ---- For executor / task / stage / memory status,etc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号