spark安装
Spark在Windows的安装:
1.安装jdk,scala,python,hadoop,spark
jdk版本:1.8
下载路径:jdk下载
scala版本:因为hadoop用的是2.7.3,对应的scala应该是2.11的版本。这里下载的是2.11.12
下载路径:scala下载 (因为是windows的安装,所以下载.msi就可以)
python版本:如果使用python3就用3.6版本,如果使用python2就用2.7
下载路径:python版本
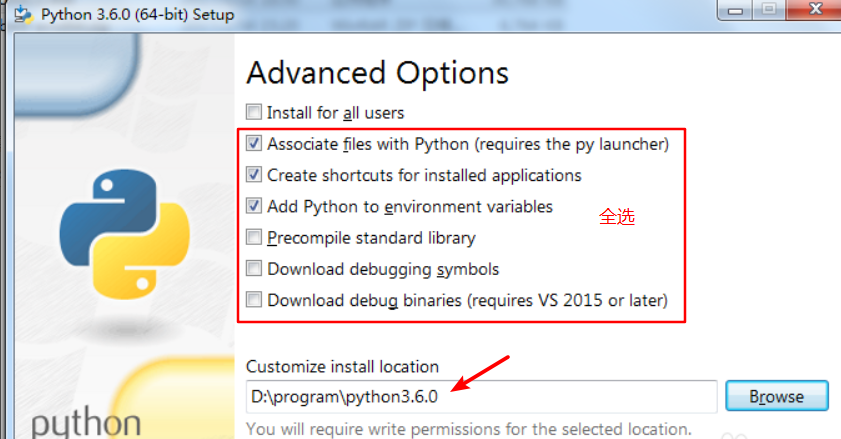
python在安装时,有下面步骤:

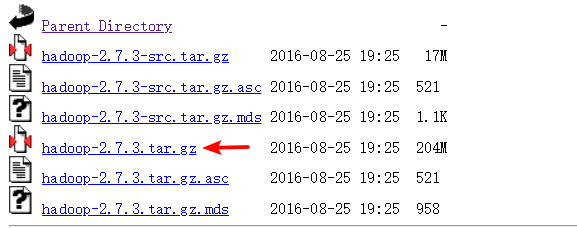
hadoop版本:2.7.3
下载地址:hadoop下载
hadoop配置过程:
进入hadoop安装目录下的etc/hadoop:
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/data/dfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/data/dfs/datanode</value> </property> </configuration>
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
hadoop-env.cmd
set JAVA_HOME=C:\Program Files\Java\jdk1.8.0_151 set HADOOP_IDENT_STRING=%USERNAME% set HADOOP_PREFIX=C:\Users\xym48\softwares\hadoop-2.7.3 set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop set YARN_CONF_DIR=%HADOOP_CONF_DIR% set PATH=%PATH%;%HADOOP_PREFIX%\bin
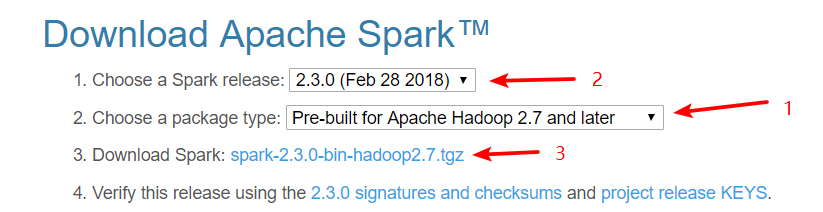
spark版本:安装hadoop版本下载,
下载地址:spark下载
2.配置环境路径:
我的电脑——右键:属性——高级系列属性——环境变量
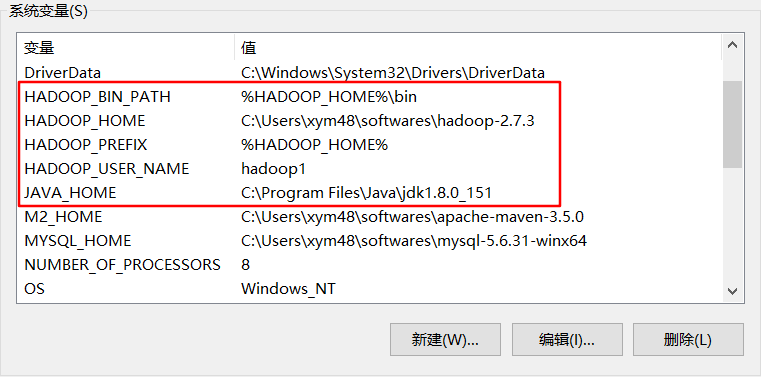
编辑path:

3.验证:
命令提示符——右键:以管理员身份运行
验证java:jdk -version
验证scala:scala
验证python:python
验证hadoop:进入${HADOOP_HOME}/bin ,执行‘hdfs namenode -format;再进入sbin,执行start-all.sh。
验证spark:spark-shell
Spark在Linux下的安装:
jdk,hadoop安装:https://www.cnblogs.com/xym4869/p/8472477.html
python:ubuntu16默认安装python3,验证:python -V
scala安装:下载.tgz,类似jdk安装,验证:scala -version
spark安装:类似jdk安装,验证:bin/spark-shell

 浙公网安备 33010602011771号
浙公网安备 33010602011771号