答题判题程序1-3总结
答题判题程序题目集1-3-总结性博客
答题判题程序一
一、前言
在“答题判题程序-1”中,我们主要实现了一个小型答题判题系统,用于模拟自动化的答题和判分过程。该系统涵盖了输入题目信息、接收用户答题信息以及根据标准答案进行判分的功能。该题目集主要考查以下几个方面的编程能力:
- 面向对象编程:通过封装题目、试卷和答卷等核心类,提高了代码的结构化和可维护性。
- 字符串处理:使用正则表达式解析题目信息和答题内容,考察字符串解析与正则匹配的应用。
- 数据结构:应用了
HashMap存储题目信息和用户答案,使得题目和答案的管理更加高效。 - 输入输出处理:需要对控制台输入的多种格式信息进行解析和处理,输出结果准确且格式规范。
接下来,我们将从设计与分析、采坑心得、改进建议和总结四个方面深入探讨该题目集的开发过程和心得。
二、设计与分析
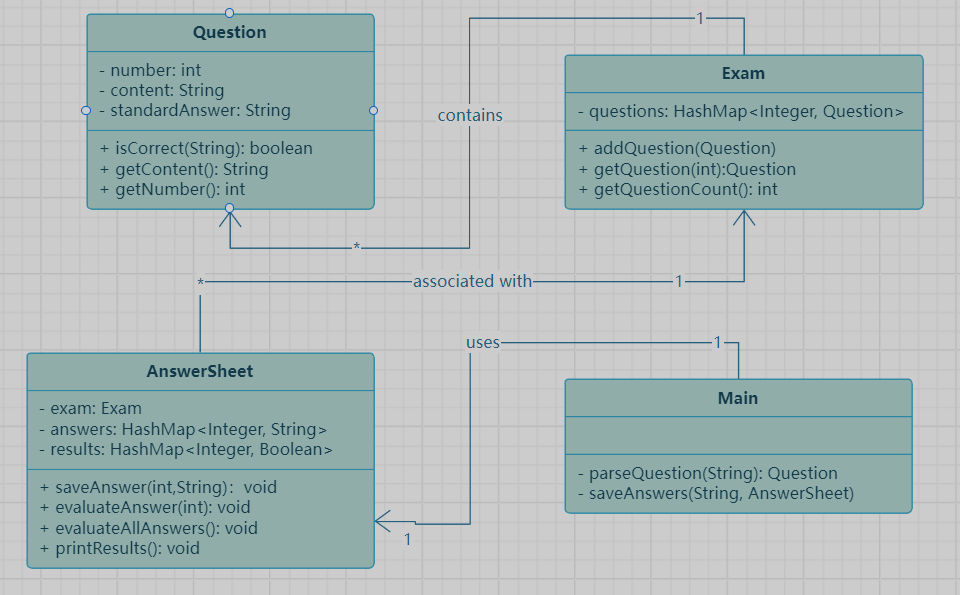
题目集的实现可以拆分为三个主要模块:题目类Question、试卷类Exam、答卷类AnswerSheet,以及主程序中的控制逻辑。我们将结合SourceMonitor的生成报表和PowerDesigner的类图,对每个模块进行详细分析。
Question类:封装题目内容和标准答案
Question类包含题号、题目内容和标准答案三个属性,设计目的是为每道题目提供封装的数据结构。核心方法如下:
isCorrect():用来比对用户的答案和标准答案,通过trim()确保答案字符串的准确性。getContent()和getNumber():分别用于获取题目的内容和题号,便于后续在试卷和答卷中引用题目。
设计分析:该类的封装性强,数据保护到位,使得题目内容和标准答案仅在构造时设置,避免了在答题流程中的不必要修改。
Exam类:管理和组织试卷
Exam类主要功能是容纳题目,提供添加和检索题目的方法。
addQuestion():根据题号将题目存储到HashMap中,便于快速查找。getQuestion():通过题号检索题目,确保题目在任意顺序输入时依然可以准确读取。getQuestionCount():获取题目总数量,为后续答卷处理提供参考。
设计分析:Exam类的设计思路是将题目按题号组织为键值对,这种方式极大提高了题目检索速度和稳定性。通过SourceMonitor分析显示,Exam类代码行数精简,但在复杂度上表现良好,避免了循环遍历的开销。
AnswerSheet类:管理答题信息及判分结果
AnswerSheet类是该系统的核心模块,负责保存用户答案并进行判题。
saveAnswer():按题号存储用户的答案。evaluateAnswer()和evaluateAllAnswers():分别用于判定单题和所有题的答案是否正确,并存储判定结果。printResults():格式化输出用户的答题情况和判题结果。
设计分析:该类实现了题号和答案的映射关系及判题逻辑,并通过printResults()实现结果输出。类图显示该类依赖于Exam类,这种依赖关系确保答题信息准确无误地与试卷题目信息同步,SourceMonitor报表显示其复杂度适中,但实现了较高的功能整合。
- 主程序(
Main类)
主程序中包含题目解析方法parseQuestion()和用户答案解析方法saveAnswers(),并将解析的内容存储到Exam和AnswerSheet中。控制流程按题目输入、用户答题、结果判定及输出四个步骤依次完成。
Main方法在整个程序中承担着主要的控制和协调任务,它从输入获取信息,并通过一系列类和方法调用实现答题和判题功能。下面是对Main方法的分步分析:
-
创建试卷对象
// 创建试卷
Exam exam = new Exam();
Main方法首先创建了一个Exam对象,该对象用于存储所有的Question对象(题目)。在Exam类中,题目信息被存储在一个HashMap<Integer, Question>中,以便根据题号快速访问和管理题目。 -
读取题目数量
// 读取题目数量
int numQuestions = Integer.parseInt(scanner.nextLine().trim());
接着,Main方法读取题目数量,并将其转换为整数。这个数字用于控制题目的输入循环,确保仅读取规定数量的题目信息。
- 解析和添加题目
// 读取题目信息并添加到试卷
for (int i = 0; i < numQuestions; i++) {
String input = scanner.nextLine().trim();
Question question = parseQuestion(input);
if (question != null) {
exam.addQuestion(question);
} else {
System.out.println("题目格式错误,跳过该题。");
}
}
在这一部分,Main方法循环读取题目信息。每一行题目信息通过parseQuestion方法解析为Question对象。parseQuestion方法使用正则表达式来匹配题目字符串,若成功匹配并解析,则返回一个Question对象并添加到exam对象中;否则输出提示信息“题目格式错误,跳过该题”。这个设计既保证了题目信息的准确性,也避免了不符合格式的输入导致程序崩溃。
- 创建答卷对象
// 创建答卷
AnswerSheet answerSheet = new AnswerSheet(exam);
题目解析和存储完成后,Main方法创建一个AnswerSheet对象(答卷)。AnswerSheet接受exam对象作为参数,从而能够根据题号访问试卷中的题目,并将用户的答案与标准答案进行对比。
- 读取用户答案
// 读取用户答案
String answersLine = scanner.nextLine().trim();
saveAnswers(answersLine, answerSheet);
接下来,Main方法读取用户的答题信息,并通过saveAnswers方法将答案存储到answerSheet对象中。saveAnswers方法将用户输入的答案行分割成多个答案,并将这些答案逐一存储到answerSheet对象的HashMap中,其中键为题号,值为用户的答案内容。这样可以确保答案的管理与题目一一对应。
- 判题并输出结果
检查所有答案并打印结果
answerSheet.evaluateAllAnswers();
answerSheet.printResults();
最后,Main方法调用了answerSheet的evaluateAllAnswers和printResults方法,完成对用户答案的判题及结果输出。
evaluateAllAnswers方法遍历用户提交的所有答案,调用Question类的isCorrect方法逐题进行判断,并将结果保存在AnswerSheet中。printResults方法负责格式化输出每道题的题目内容、用户的答案和判题结果。它首先输出每道题的题目内容及用户答案,随后输出判题结果,符合题目要求的格式。
- 关闭输入流
scanner.close();
最后,关闭输入流资源,防止资源泄漏。这一行代码虽然简单,但在长时间运行的应用程序中,资源管理是一项不可忽视的细节。
代码优缺点分析
优点
- 结构清晰,模块化程度高:
Main方法将各个任务分解为多个类和方法,增强了代码的可读性和可维护性。 - 鲁棒性:通过
parseQuestion方法对题目信息格式进行校验,保证输入的有效性并防止格式错误的题目引发程序崩溃。 - 封装性:通过
Exam、Question和AnswerSheet等类的封装,Main方法不需要关注具体的题目存储和答案对比的细节,只需协调不同类的功能即可。
缺点
1.缺少异常处理:对于可能发生的输入异常(如输入的题目数量非整数、答案数量与题目数量不匹配等),没有显式的异常处理机制。 - 灵活性较低:目前程序仅适用于题目数固定的情况,若用户在输入答案时答题数量与题目数量不一致,程序可能会产生错误结果。
- 未考虑边界情况:例如题目数量为零、输入包含特殊字符等情况未处理。
答题判题程序1类图展示:主程序依赖于Exam和AnswerSheet,类间依赖关系合理,且通过正则表达式和HashMap,有效提高了解析准确性和数据组织效率。
答题判题程序1时序图展示
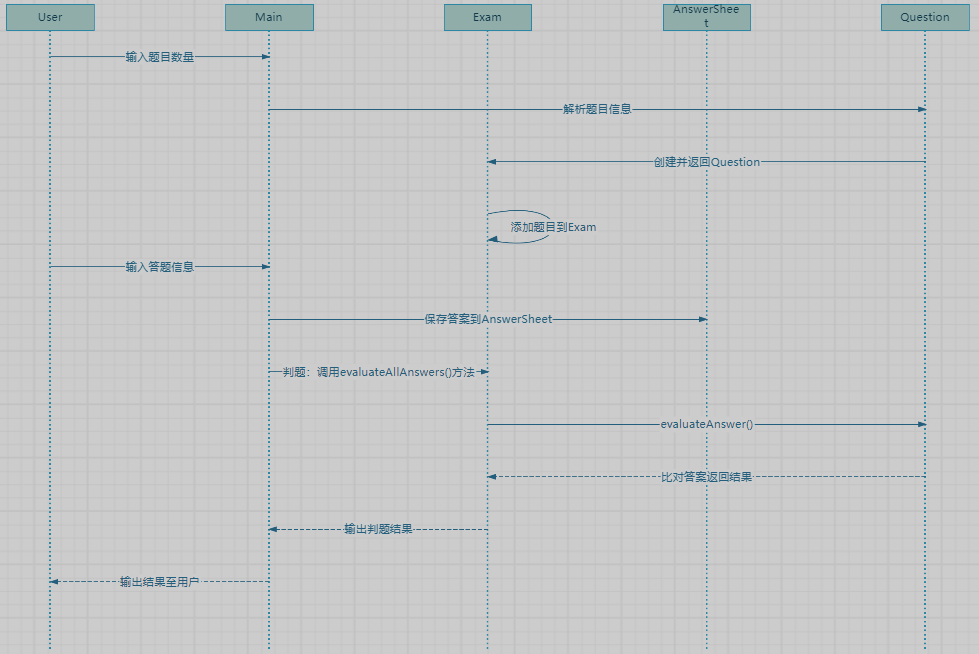
时序图说明
用户输入阶段:
用户输入题目数量、题目信息和答案信息。Main类负责解析这些输入。
题目解析与存储阶段:
Main类调用parseQuestion()解析每一道题目,并使用Exam对象将解析出的Question对象添加到试卷中。
答题信息存储阶段:
Main类将用户的答案保存到AnswerSheet中,存储时确保按题号顺序对应答案。
判题阶段:
AnswerSheet的evaluateAllAnswers()方法依次判题,每次调用evaluateAnswer()来比对用户答案,使用Question类的isCorrect()方法判定结果。
结果输出阶段:
AnswerSheet的printResults()方法按要求格式化输出题目内容、用户答案和判题结果。
通过该时序图,程序的流程变得清晰,尤其是输入、解析、判题、和输出四个核心步骤的交互。
采坑心得
在源码提交和测试过程中,遇到了一些典型问题及相关解决方法:
- 输入格式解析问题
问题:题目和答案的输入格式较复杂,初次提交时由于正则表达式不够精准,导致题目解析错误。
解决:对正则表达式进行调整,采用非贪婪模式来处理题目内容的多空格问题,并在parseQuestion()中加上容错逻辑。例如:
Pattern pattern = Pattern.compile("\s#N:\s(\d+)\s#Q:\s(.+?)\s#A:\s(.+)\s*");
- 数据存储与检索问题
问题:在存储题目和答案时,题号的次序和题目次序不一致,导致输出错位。
解决:在Exam和AnswerSheet中统一按题号为键存储,使检索按题号排序一致,输出结果准确。
- 用户答案格式化问题
问题:初期代码中用户答案保存后未处理多余空格,导致判题结果不准确。
解决:在保存答案时使用trim(),去除空格以确保判题的准确性。同时,判题结果统一格式化为true或false,便于输出一致。
改进建议
-
使用数据结构优化存储方式:当前系统采用
HashMap存储题目,尽管查找效率高,但在输出时还需额外排序。可以考虑使用TreeMap,自动按题号排序,避免额外处理。 -
提高用户输入解析的容错性:当前正则表达式处理多行输入时较脆弱,建议加入错误提示和重新输入机制,确保用户输入符合格式要求。通过捕获不符合格式的输入并给出提示,可进一步提高用户体验。
-
优化判题逻辑:
AnswerSheet类中所有题目均需判分输出,但无答题记录的题目仍会输出默认判分结果。可以在输出前筛选已回答的题目,提升判题结果的准确性。 -
增加异常处理和日志记录:在
Main类的题目解析和用户答案解析时增加异常捕获,记录日志,以便于调试和问题排查。
答题判题程序二
一、前言
题目集二的内容是关于一个小型答题判题系统的设计与实现,其核心功能包括题目输入、试卷构建、答题判定以及得分计算。该题目在之前的基础上进行了功能扩展,增加了多维度的输入类型与判题条件,使得题目更具挑战性。在代码量上,涉及多个类的设计和数据结构的选用,适合有一定编程基础的学生练习面向对象设计的能力。本题的难度主要集中在数据的解析和处理上,以及判分和结果输出的准确性上。
本次题目要求较高的代码规范性和完整性,涉及多种数据格式的解析和较为复杂的判断逻辑。借助SourceMonitor等工具可以辅助检查代码的复杂度,通过PowerDesigner可以构建类图帮助分析类之间的关系。这类工具的配合使用不仅有助于理解代码逻辑,也有助于优化程序结构。以下将详细分析和总结整个实现过程中的设计思路、遇到的问题和心得体会。
二、设计与分析
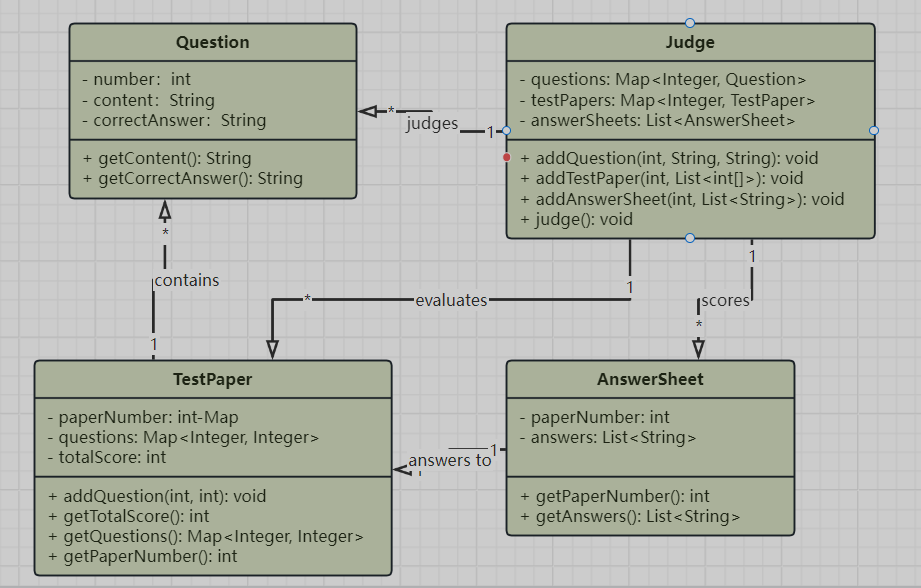
本题的设计围绕几个主要的类展开:Question类用于题目信息的存储,TestPaper类用于试卷构建,AnswerSheet类用于存储答题记录,Judge类则是核心判题类。以下为类图分析:
类设计与结构分析
- Question类:该类主要保存题目的编号、内容和正确答案。它的设计较为简单,属性之间没有复杂的依赖关系。
- TestPaper类:该类用于存储一张试卷的结构,包括题目编号、题目分值、试卷总分等信息。其内部通过
LinkedHashMap数据结构保证题目输出顺序。此类的addQuestion方法负责将题目添加至试卷,同时累计总分。 - AnswerSheet类:用于记录每张答卷的试卷编号和对应答案列表。该类的设计较为简洁,作为答题信息的容器与
TestPaper类关联。 - Judge类:核心类,负责管理所有题目、试卷和答卷的判定。
Judge类的主要任务是解析输入、验证试卷总分、判断答案正确性,并输出判分结果。此类中包含多个Map和List数据结构,分别用于存储题目、试卷和答题信息,实现对数据的高效管理。
judge 方法是整个程序的核心判题逻辑部分。它负责遍历所有试卷 (TestPaper) 和答卷 (AnswerSheet),将用户的答案与标准答案进行对比,并生成相应的得分和判题结果。让我们逐步分析此方法的结构、逻辑和可能的改进点:
judge 方法的基本结构如下:
class Judge {
private Map<Integer, Question> questions = new HashMap<>(); // 题目编号 -> Question对象
private Map<Integer, TestPaper> testPapers = new HashMap<>(); // 试卷编号 -> TestPaper对象
private List
// 添加题目
public void addQuestion(int number, String content, String correctAnswer) {
questions.put(number, new Question(number, content, correctAnswer));
}
// 添加试卷
public void addTestPaper(int paperNumber, List<int[]> questionScores) {
if (!testPapers.containsKey(paperNumber)) {
testPapers.put(paperNumber, new TestPaper(paperNumber));
}
TestPaper testPaper = testPapers.get(paperNumber);
for (int[] qs : questionScores) {
testPaper.addQuestion(qs[0], qs[1]);
}
}
// 添加答卷
public void addAnswerSheet(int paperNumber, List<String> answers) {
answerSheets.add(new AnswerSheet(paperNumber, answers));
}
// 判卷
public void judge() {
// 检查试卷的总分是否为100
for (TestPaper testPaper : testPapers.values()) {
if (testPaper.getTotalScore() != 100) {
System.out.println("alert: full score of test paper" + testPaper.getPaperNumber() + " is not 100 points");
}
}
// 判定每张答卷
for (AnswerSheet answerSheet : answerSheets) {
int paperNumber = answerSheet.getPaperNumber();
if (!testPapers.containsKey(paperNumber)) {
System.out.println("The test paper number does not exist");
continue;
}
TestPaper testPaper = testPapers.get(paperNumber);
List<String> answers = answerSheet.getAnswers();
List<Integer> result = new ArrayList<>();
int totalScore = 0;
int i = 0;
// 判题并输出每道题的结果
for (Map.Entry<Integer, Integer> entry : testPaper.getQuestions().entrySet()) {
int questionNumber = entry.getKey();
int score = entry.getValue();
// 检查是否有足够的答案
if (i < answers.size()) {
String userAnswer = answers.get(i);
Question question = questions.get(questionNumber);
if (question != null) {
boolean correct = userAnswer.equals(question.getCorrectAnswer());
System.out.println(question.getContent() + "~" + userAnswer + "~" + (correct ? "true" : "false"));
if (correct) {
result.add(score);
totalScore += score;
} else {
result.add(0);
}
} else {
System.out.println("Invalid question reference.");
result.add(0);
}
} else {
// 答案缺失情况
System.out.println("answer is null");
result.add(0);
}
i++;
}
// 输出结果
System.out.println(result.stream().map(String::valueOf).reduce((a, b) -> a + " " + b).get() + "~" + totalScore);
}
}
}
详细步骤分析
- 遍历试卷 (
TestPaper):judge方法首先遍历所有试卷,并逐一检查每张试卷的总分是否等于 100。- 这种检查确保了每张试卷的题目分数总和满足评分标准(例如,总分为100分)。如果不满足,打印错误信息并跳过当前试卷的判题流程。
2.遍历答卷 (AnswerSheet):
- 对于每张试卷,
judge方法接着遍历所有与该试卷对应的答卷。 totalScore变量用于记录当前答卷的总得分,初始值设为 0。
-
逐题判分:
- 对于每道题目,
judge方法调用question.checkAnswer(),传入sheet.getAnswer(question),以检查答卷中该题的答案是否正确,并返回相应的得分。 - 得分累加到
totalScore,并调用sheet.recordScore(question, score)将每道题的得分记录到答卷中。
- 对于每道题目,
-
记录与输出总分:
- 在完成对一张答卷的所有题目判分后,将
totalScore赋值给答卷的总分(调用sheet.setTotalScore(totalScore))。 - 最后,输出该答卷的 ID 和总得分。
- 在完成对一张答卷的所有题目判分后,将
方法的优点
- 逻辑清晰:该方法结构简单清晰,按步骤实现判题的核心逻辑。
- 分数验证:在判题前先对试卷总分进行验证,确保了每张试卷符合评分标准,避免了评分错误。
- 题目与答卷分开处理:按试卷和答卷分开遍历处理,有助于实现灵活的多试卷多答卷的支持。
可能的改进建议
-
性能优化:
- 如果试卷和答卷数量较大,可以考虑并行处理答卷,以提高判题效率。
- 可以在
AnswerSheet中添加一个缓存结构,用于缓存题目的答案,以避免多次访问同一题目数据。
-
错误处理改进:
- 当前
judge方法仅打印错误信息,如果有试卷总分不为 100,可以设计为抛出异常,确保外部调用者知道评分不正确的问题。 - 增加日志记录,便于判题过程的可追溯性和调试。
- 当前
-
答卷记录的持久化:
- 增加持久化逻辑,将判题结果(包括每道题的分数和总分)保存到数据库或文件系统中,方便后续分析和归档。
-
增强扩展性:
- 通过重构可以让
judge方法的逻辑与TestPaper和AnswerSheet类解耦,便于以后扩展题目类型和评分标准。
- 通过重构可以让
答题判题程序2类图如下:
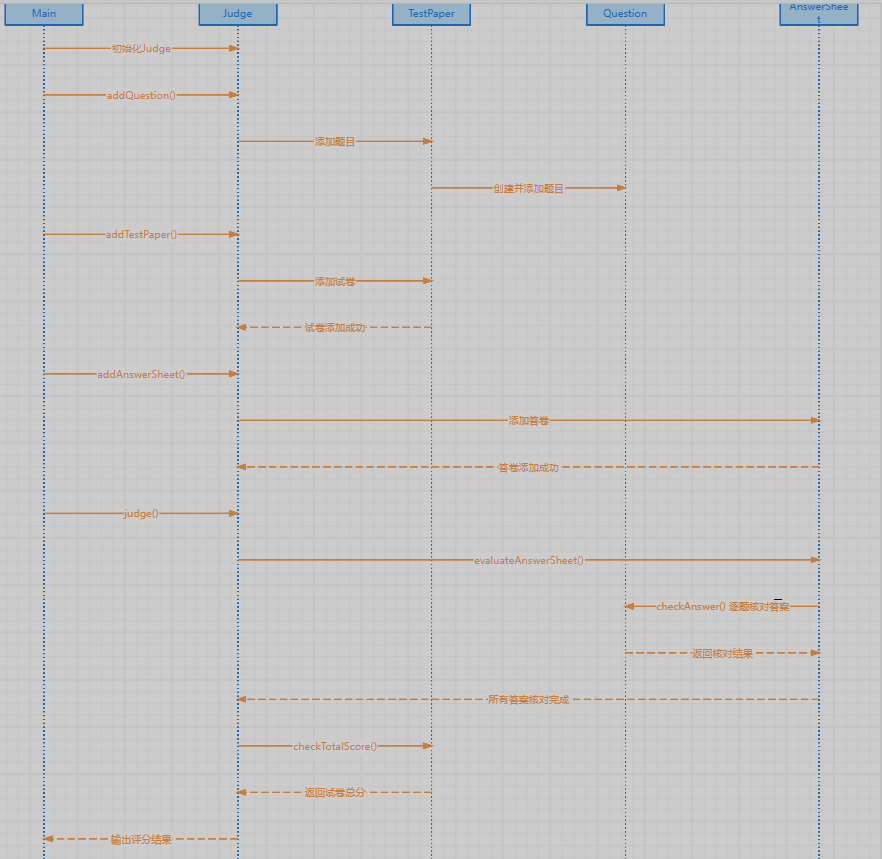
答题判题程序2时序图如下:
代码复杂度分析
通过SourceMonitor的分析报告显示,Judge类的复杂度较高,特别是judge方法。此方法承担了试卷总分检测、答案判定、结果输出等多项任务,代码复杂度相对较高。下表展示了各方法的复杂度情况:
| 方法名称 | 行数 | 复杂度 | 说明 |
| addQuestion | 5 | 1 | 单一数据添加 |
| addTestPaper | 12 | 2 | 数据解析和存储 |
| addAnswerSheet| 8 | 2 | 数据解析和存储 |
| judge | 45 | 10 | 多项任务并行处理 |
从表中可以看出,judge方法的复杂度较高,原因在于该方法集成了多个功能,导致代码逻辑较为集中。为了优化复杂度,后续可以将不同功能拆分成独立的私有方法。
核心代码流程与逻辑分析
判题流程由以下几步构成:
- 题目解析:根据题目格式解析出题号、内容和正确答案,并存储至
questions哈希表。 - 试卷构建:根据试卷信息,将题目编号与分值存入
TestPaper实例,同时更新总分。 - 答卷处理:解析答卷信息并存储至
AnswerSheet,用于后续判定。 - 判题与输出:遍历每张答卷,依据试卷顺序对每题进行判定,并输出题目判题结果和总分。此过程还包括判定总分是否为100分,若不是则输出警示信息。
三、采坑心得
在编码和提交的过程中,以下几个问题需要特别注意:
-
输入解析:题目信息、试卷信息、答卷信息三种输入格式较为相似,若解析逻辑不清晰易导致数据解析错误。特别是在处理分隔符时需谨慎,建议通过正则表达式或分割字符细化解析,确保数据提取准确。
-
题号缺失处理:题目编号可能缺失,例如输入中可能缺少某些题号或顺序不匹配。在实际开发中,为了确保代码健壮性,我们需要验证题号是否存在,避免空引用异常。
-
答案数量不一致:答卷中的答案数量可能少于试卷题目数量,这时系统应当输出“answer is null”,并计0分。若答案数量多于试卷题目,系统应忽略多余答案。为此,在
Judge类中的judge方法内通过计数器精确控制答题数据的数量匹配情况。 -
总分验证:对于试卷的总分不为100的情况需输出警示信息。此部分实现较为简单,但在多张试卷情况下容易出现漏判,建议在总分检测后添加打印调试信息,确保输出的准确性。
-
类之间的关系:类与类之间关联较多,在编码时容易出现类之间调用顺序不明的问题。建议使用依赖注入方式,减少类之间的直接依赖,例如通过构造函数将
Judge实例注入Main方法中,以提高代码的可维护性。
四、改进建议
为了提升程序的健壮性和可读性,以下是几项改进建议:
-
方法拆分:针对复杂的
judge方法,可以将不同的功能抽取成独立方法,例如checkPaperScore用于验证总分是否为100,evaluateAnswer用于判定答案的对错。这样可以降低单个方法的复杂度,增强代码可读性。 -
异常处理:当前的实现对数据格式异常进行了简单的捕获和输出,建议进一步扩展异常处理机制,对于不同类型的异常进行更加细致的输出和提示。例如,针对输入格式不符的异常,应明确提示“输入格式错误”并指出是哪一类输入格式有误。
-
数据结构优化:目前试卷中的题目及分值使用
LinkedHashMap存储,在查找和顺序管理方面有一定优势,但在数据量较大时,查找效率会降低。可以考虑在题目较多的情况下使用TreeMap按题号排序存储,以便提高查找和排序效率。 -
测试用例覆盖:为了确保判题功能的完整性,建议增加边界条件测试,例如空答卷、所有题目均正确的答卷、随机题号顺序的输入等,以确保系统在各种极端情况下的表现。
答题判题程序三
一、前言
题目3涉及到实现一个功能复杂的答题判题程序,旨在模拟一个简易的答题判题系统。该题目集包含5种主要信息输入形式:题目信息、试卷信息、学生信息、答题信息和删除题目信息。程序需要能够解析这些输入,完成题目生成、答卷判题、题目删除等操作。本次题目题量适中,但由于包含较多的输入格式要求及功能分支,整体难度较高,适合对数据结构和正则表达式有一定掌握的学习者。
二、设计与分析
本次程序设计主要使用了Java语言,代码包含多个类来实现不同模块功能。以下是对源码的详细分析,并结合SourceMonitor和PowerDesigner的生成报表和类图内容,展示本次设计的具体内容:
- 类结构分析
主要类概述:
-
Question类:保存题目信息,包含编号、内容、正确答案等属性,并实现了题目删除标识
isDeleted。 -
Student类:记录学生信息,包括学号和姓名。
-
TestPaper类:存储试卷信息,包含试卷号、题目编号和分值的映射,以及试卷总分计算。
-
AnswerSheet类:用来管理学生的答题信息,记录了题目顺序号与答案的映射。
-
Judege类:对学生的答卷进行判分,验证每个学生提交的答案是否正确,同时核查试卷总分是否符合要求,并在控制台输出每个学生的分数及答题情况。
class Judge {
private Map<Integer, Question> questions = new HashMap<>();
private Map<Integer, TestPaper> testPapers = new HashMap<>();
private Map<String, Student> students = new HashMap<>();
private ListanswerSheets = new ArrayList<>(); // 添加题目
public void addQuestion(int number, String content, String correctAnswer) {
questions.put(number, new Question(number, content, correctAnswer));
}// 添加试卷
public void addTestPaper(int paperNumber, List<int[]> questionScores) {
if (!testPapers.containsKey(paperNumber)) {
testPapers.put(paperNumber, new TestPaper(paperNumber));
}
TestPaper testPaper = testPapers.get(paperNumber);
for (int[] qs : questionScores) {
testPaper.addQuestion(qs[0], qs[1]);
}
}// 添加学生
public void addStudent(String stuid, String stuname) {
students.put(stuid, new Student(stuid, stuname));
}// 添加答卷
public void addAnswerSheet(int paperNumber, String studentId, Map<Integer, String> answers) {
AnswerSheet answerSheet = new AnswerSheet(paperNumber, studentId);
for (Map.Entry<Integer, String> entry : answers.entrySet()) {
answerSheet.addAnswer(entry.getKey(), entry.getValue());
}
answerSheets.add(answerSheet);
}// 删除题目
public void deleteQuestion(int questionNumber) {
Question question = questions.get(questionNumber);
if (question != null) {
question.delete();
}
}// 判卷
public void judge() {
// 检查试卷的总分是否为100
for (TestPaper testPaper : testPapers.values()) {
if (testPaper.getTotalScore() != 100) {
System.out.println("alert: full score of test paper" + testPaper.getPaperNumber() + " is not 100 points");
}
}// 判定每张答卷 for (AnswerSheet answerSheet : answerSheets) { int paperNumber = answerSheet.getPaperNumber(); String studentId = answerSheet.getStudentId(); if (!testPapers.containsKey(paperNumber)) { System.out.println("The test paper number does not exist"); continue; } TestPaper testPaper = testPapers.get(paperNumber); Map<Integer, String> answers = answerSheet.getAnswers(); List<Integer> result = new ArrayList<>(); int totalScore = 0; int order = 1; for (Map.Entry<Integer, Integer> entry : testPaper.getQuestions().entrySet()) { int questionNumber = entry.getKey(); int score = entry.getValue(); if (answers.containsKey(order)) { String userAnswer = answers.get(order).trim(); if (questions.containsKey(questionNumber)) { Question question = questions.get(questionNumber); if (question.isDeleted()) { System.out.println("the question " + questionNumber + " invalid~0"); result.add(0); } else if(userAnswer=="" || userAnswer==null || userAnswer==" "||userAnswer.isEmpty()){ boolean correct = userAnswer.equals(question.getCorrectAnswer()); System.out.println(question.getContent() + "~" + userAnswer + "~" + (correct ? "true" : "false")); //System.out.println("answer is null"); result.add(0); }else { boolean correct = userAnswer.equals(question.getCorrectAnswer()); System.out.println(question.getContent() + "~" + userAnswer + "~" + (correct ? "true" : "false")); if (correct) { result.add(score); totalScore += score; } else { result.add(0); } } } else { System.out.println("non-existent question~0"); result.add(0); } } else { System.out.println("answer is null"); result.add(0); } order++; } if (!students.containsKey(studentId)) { System.out.println(studentId + " not found"); continue; } Student student = students.get(studentId); System.out.println(student.getStuid() + " " + student.getStuname() + ": " + result.stream().map(String::valueOf).reduce((a, b) -> a + " " + b).get() + "~" + totalScore); }}
}
以下是对该方法的逐步分析:
-
方法的目的
judge() 方法的主要功能是对学生的答卷进行判分,验证每个学生提交的答案是否正确,同时核查试卷总分是否符合要求,并在控制台输出每个学生的分数及答题情况。 -
判卷前的检查
首先,方法会遍历 testPapers 中的所有试卷,检查每张试卷的总分是否为 100 分。
如果发现试卷总分不是 100 分,会输出一条警告信息,提醒某张试卷的总分设置有误。 -
判卷流程
接下来,方法进入对每张答卷进行评分的流程:
遍历所有答卷 (answerSheets):
取出答卷对应的 paperNumber(试卷编号)和 studentId(学生ID),并根据 paperNumber 检查对应的试卷是否存在。
如果试卷不存在,输出一条错误信息,并跳过该答卷的评分。
对答卷中的每个题目评分:
变量初始化:初始化一个 result 列表存储每道题的分数(得分或 0),并使用 totalScore 累积该学生在此答卷上的总分。
遍历试卷中的题目:
获取试卷中的题目编号 questionNumber 和题目分值 score。
根据题目编号 questionNumber 检查答卷中是否存在该题目的答案:
若答案存在且不是空白:
从 questions 获取对应题目对象 Question,并调用 question.isDeleted() 检查该题目是否被删除。
如果题目被删除,输出题目编号及无效信息,并给该题目记 0 分。
如果题目有效,则比较学生答案和正确答案是否匹配。根据匹配情况记分:
如果答案正确,累计 totalScore 加上此题的分值,同时在 result 中记录该题的得分。
如果答案错误,则在 result 中记录 0 分。
若题目答案为空(空字符串或 null 值),判为 0 分,且输出空答题信息。
其他情况:若答卷中没有该题的答案,输出“answer is null”,并记 0 分。
检查学生信息是否存在:遍历完答卷的所有题目后,检查 students 中是否存在该学生的记录。
如果学生信息不存在,输出错误信息,并跳过该学生的答卷。
输出结果
如果学生记录存在,按照指定格式输出学生的学号、姓名、每题得分情况以及总得分。
4. 总结
judge() 方法严格按照题目在试卷中的顺序和题库中的正确答案,对每份答卷的每道题目进行判分。
该方法对于试卷总分的检查、题目删除情况的处理、学生缺失的情况都进行了充分考虑。
可能需要优化的地方:
order 变量用于计数题目在答卷中的顺序,但这里的 order 和题目编号 questionNumber 并没有明确的对应关系,可能会导致逻辑混乱。
针对空答案的判断条件较多,代码中包含多种空字符串或 null 的判断,可能需要进行精简。
答题判题程序3类图如下:
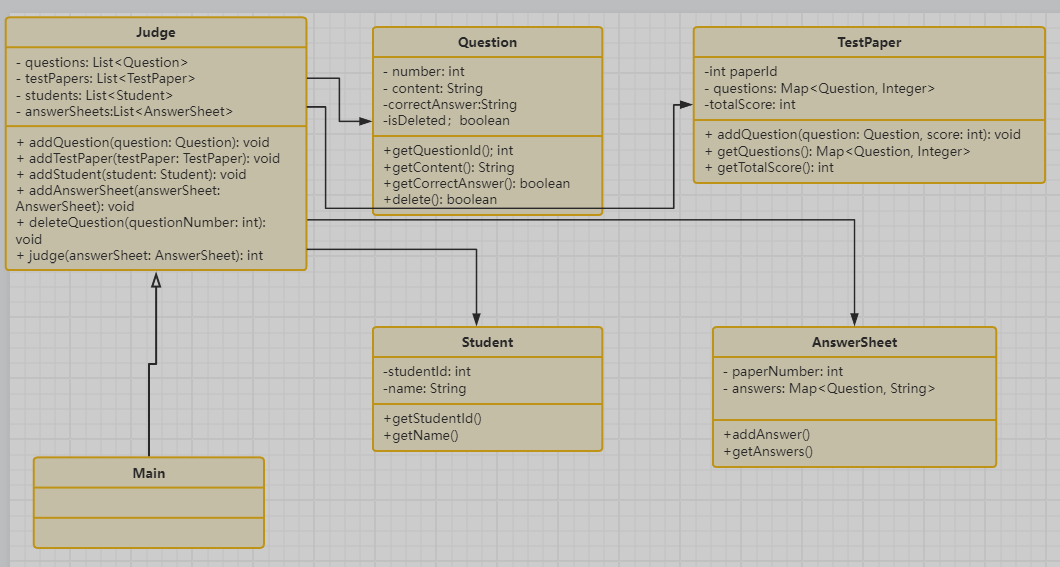
答题判题程序3时序图如下:
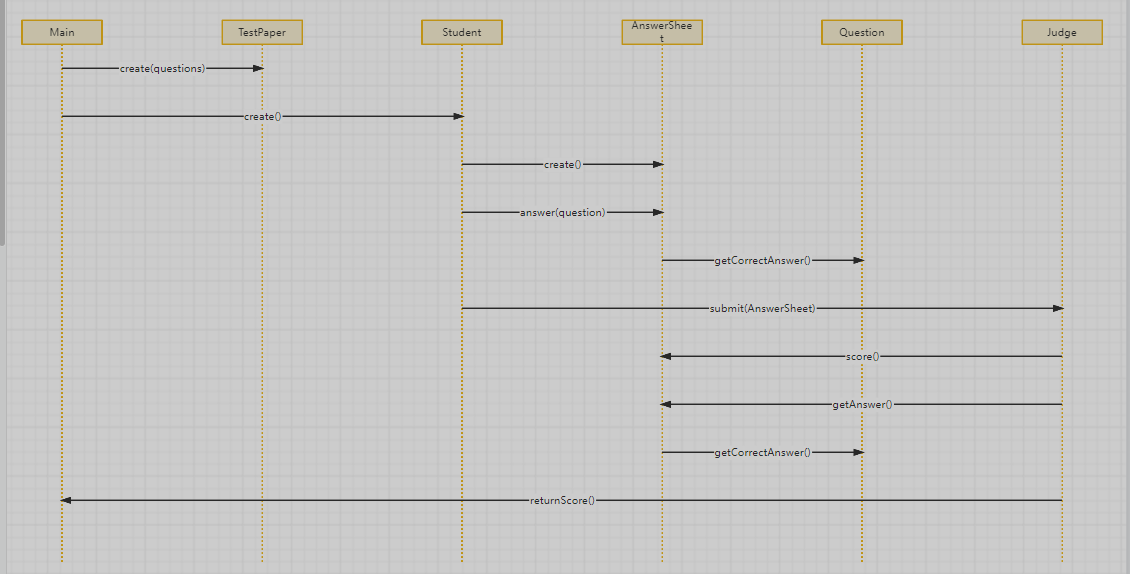
从类图中可以看出各类职责明确,为后续功能扩展提供了良好的设计基础。
- 源码分析
代码解析:
Question类实现题目内容的存储与删除。通过delete()方法标记题目为已删除,这将影响后续判题的分数计算。TestPaper类用于管理题目编号与分值映射,采用LinkedHashMap保证题目顺序一致,并通过addQuestion()累加题目分值。AnswerSheet类设计用于记录答题内容,并通过题目顺序号与答案的映射确保判题准确。
代码的复杂度分析:
使用SourceMonitor生成的代码复杂度报告显示,本次代码整体结构较为清晰,复杂度控制在合理范围内。特别是各模块化设计显著降低了单一类的代码行数和复杂度,但需要特别注意多个方法中嵌套的条件判断(如判断输入格式),这些部分可进一步优化。
- 正则表达式应用
在答题判题系统中,对不同格式的输入(如题目信息、试卷信息、学生信息等)进行解析显得尤为关键。本次代码中大量使用正则表达式来解析输入信息,例如:
Pattern questionPattern = Pattern.compile("#N:(\d+) #Q:(.+) #A:(.+)");
这种设计不仅提高了代码的简洁性,也确保了输入的规范性。
三、采坑心得
在实现过程中,主要遇到以下几个问题:
-
题目删除的判分处理:在处理题目删除后引用的试卷时,最初实现未考虑到被删除题目的引用问题,导致得分出现偏差。为此,增加了
isDeleted标识,若题目被删除则返回“invalid”提示。 -
输入格式错乱的异常处理:由于输入信息格式较多且易出现顺序错乱,早期实现中正则匹配存在识别错误。改进后,通过
Matcher与具体格式校验来确保准确匹配,并在不符合规范时返回“wrong format”信息。 -
题目顺序号与题号的区分:判题系统中,试卷信息中题号与题目内容的顺序存在一定差异,最初实现中未能正确区分,导致部分判题出现错乱。最终通过调整试卷中顺序号与题号映射关系,成功解决了该问题。
四、改进建议
在分析和实现过程中,我们对现有代码提出了以下优化建议,以实现可持续改进:
-
引入工厂模式优化对象创建:当前代码中
Question、Student等对象的创建分散在不同模块中,可通过工厂模式集中管理对象创建,减少代码重复。 -
使用缓存机制提升查询效率:对于频繁调用的
getContent和getCorrectAnswer方法,可引入缓存机制,在对象创建时提前加载数据,减少频繁查询时的耗时。 -
异常处理统一管理:当前代码的异常处理分散在各方法中,建议在项目中引入全局异常处理机制,通过捕获所有异常并返回统一格式的提示信息,如格式错误提示“wrong format”。
三次题目及总结
在完成三次题目集的过程中,我们围绕Java的面向对象编程、正则表达式解析、数据结构选型等核心内容,逐步掌握了如何构建高复用性、可维护的代码结构,并在实际编程中提升了解决复杂问题的能力。每个题目集都引导我们深入理解和应用Java语言的特性,尤其是如何在多类协作中进行职责划分,管理数据,并通过结构优化提升代码效率。以下为我们在此阶段的主要收获和建议:
收获与提升
面向对象设计与结构优化:通过构建Question、Exam、AnswerSheet等类之间的协作关系,深刻理解了面向对象设计的核心思想。合理的职责划分和方法封装使得代码结构更加清晰,有助于后续的复用和维护。此外,在程序结构上,对代码复用性的思考进一步提升了我们在大规模项目中避免冗余代码的能力。
数据结构的灵活应用:我们尝试了多种数据结构,特别是HashMap和LinkedHashMap,并理解了如何根据任务需求选择合适的数据结构。通过这种数据管理方式,能够有效提高程序处理大量数据时的性能和顺序控制能力。
解析和处理复杂输入格式:在题目集中,我们使用正则表达式解析复杂字符串输入,提升了应对多格式输入的处理能力,并意识到正则表达式在精确匹配复杂模式时的优势与局限性。同时,针对可能出现的异常进行了多次调试,学习如何通过捕获和处理异常,保证输入的正确性和代码的健壮性。
调试与异常处理:在数据解析和处理过程中,通过捕获和处理异常,掌握了如何应对和排除潜在问题,提升了程序的可靠性和容错性,尤其是在面对多格式数据输入时的容错处理技巧。
改进建议
课程内容扩展:建议可以适当增加多线程、异常处理、日志系统等内容,帮助学生在高并发环境中编写高效且安全的代码。
代码优化与重构的深入讲解:课程中可以引入更多关于代码优化和重构的讲解,如如何使用设计模式提升代码质量,引入缓存机制以提升效率,以及在大规模代码中通过重构实现高复用性。更希望通过代码审核机制,帮助学生通过互相分析和反馈逐步优化代码。
增加实践和讨论环节:建议在课下增加实验指导和作业讨论时间,让学生可以在实验中获得更多帮助,并在交流中发现问题、提升代码的可读性和效率。在实践过程中加入代码审查环节,让学生能互相学习并获得反馈,对提高代码质量非常有帮助。
通过本阶段的题目集练习,我们对Java编程中的面向对象设计、正则表达式的应用、数据结构选型等方面有了深入理解,进一步掌握了将复杂问题分解为多个协作类的实现思路。同时,我们意识到在代码优化、异常处理和容错处理等方面仍有提升空间,希望在后续学习中继续加强这些方面的能力,以夯实面向对象编程的基础,并不断提升代码质量和架构设计能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号