



Spring Boot集成sharding-jdbc实现分库分表
一、水平分割
1、水平分库
1)、概念:
以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中。
2)、结果
每个库的结构都一样;数据都不一样;
所有库的并集是全量数据;
2、水平分表
1)、概念
以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中。
2)、结果
每个表的结构都一样;数据都不一样;
所有表的并集是全量数据;
二、Shard-jdbc 中间件
1、架构图
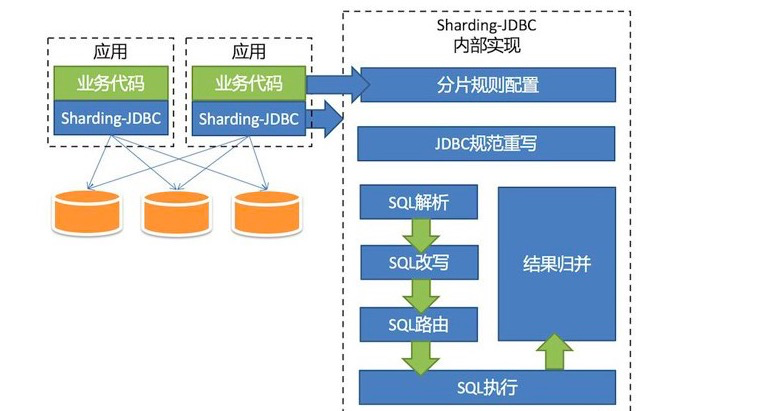
2、特点
1)、Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零。
2)、适用于任何基于Java的ORM框架,如Hibernate、Mybatis等 。
3)、可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
4)、以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖。
5)、分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
6)、SQL解析功能完善,支持聚合、分组、排序、limit、or等查询。
三、项目演示

核心代码块
数据源配置文件
spring:
datasource:
# 数据源:shard_one
dataOne:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_one?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 数据源:shard_two
dataTwo:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_two?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 数据源:shard_three
dataThree:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_three?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
数据库分库策略/**
* 数据库映射计算
*/
public class DataSourceAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(DataSourceAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分库算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "ds_" + ((hash % 2) + 2) ;
}
}
数据表1分表策略
/**
* 分表算法
*/
public class TableOneAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableOneAlg.class);
/**
* 该表每个库分5张表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分表算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "table_one_" + (hash % 5+1);
}
}
数据表2分表策略/**
* 分表算法
*/
public class TableTwoAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableTwoAlg.class);
/**
* 该表每个库分5张表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分表算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "table_two_" + (hash % 5+1);
}
}
数据源集成配置/**
* 数据库分库分表配置
*/
@Configuration
public class ShardJdbcConfig {
// 省略了 druid 配置,源码中有
/**
* Shard-JDBC 分库配置
*/
@Bean
public DataSource dataSource (@Autowired DruidDataSource dataOneSource,
@Autowired DruidDataSource dataTwoSource,
@Autowired DruidDataSource dataThreeSource) throws Exception {
ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration();
shardJdbcConfig.getTableRuleConfigs().add(getTableRule01());
shardJdbcConfig.getTableRuleConfigs().add(getTableRule02());
shardJdbcConfig.setDefaultDataSourceName("ds_0");
Map<String,DataSource> dataMap = new LinkedHashMap<>() ;
dataMap.put("ds_0",dataOneSource) ;
dataMap.put("ds_2",dataTwoSource) ;
dataMap.put("ds_3",dataThreeSource) ;
Properties prop = new Properties();
return ShardingDataSourceFactory.createDataSource(dataMap, shardJdbcConfig, new HashMap<>(), prop);
}
/**
* Shard-JDBC 分表配置
*/
private static TableRuleConfiguration getTableRule01() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("table_one");
result.setActualDataNodes("ds_${2..3}.table_one_${1..5}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new TableOneAlg()));
return result;
}
private static TableRuleConfiguration getTableRule02() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("table_two");
result.setActualDataNodes("ds_${2..3}.table_two_${1..5}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new TableTwoAlg()));
return result;
}
}

