主要内容
- 基本概念
- 虚拟文件系统
- 数据块缓存
- 打开文件的数据结构
- 文件分配
- 空闲空间列表
- 多磁盘管理-RAID
- 磁盘调度
基本概念
- 文件系统和文件
- 文件描述符
- 目录
- 文件别名
- 文件系统种类
文件系统:一种用于持久性存储的系统抽象
- 在存储器上:组织、控制、导航、访问和检索数据
- 大多数计算机系统包含文件系统
- 个人电脑、服务器、笔记本电脑iPod、Tivo/机顶盒、手机/掌上电脑
- Google可能是由一个文件系统构成的
文件:文件系统中一个单元的相关数据在操作系统中的抽象
分配文件磁盘空间
- 管理文件块(哪一块属于哪一个文件)
- 管理空闲空间(哪一块是空闲的)
- 分配算法(策略)
管理文件集合
- 定位文件及其内容
- 命名:通过名字找到文件的接口
- 最常见:分层文件系统
- 文件系统类型(组织文件的不同方式)
提供的便利及特征
- 保护:分层来保护数据安全
- 可靠性/持久性:保持文件的持久即使发生崩溃、媒体错误、攻击等
文件属性
- 名称、类型、位置、大小、保护、创建者、创建时间、最近修改时间、…
文件头
- 在存储元数据中保存了每个文件的信息
- 保存文件的属性
- 跟踪哪一块存储块属于逻辑上文件结构的哪个偏移
文件描述符
文件使用模式
使用程序必须在使用前先“打开”文件
f = open (name,flag) ; ... ... = read(f,---) ; ... close(f);
内核跟踪每个进程打开的文件
- 操作系统为每个进程维护一个打开文件表
- 一个打开文件描述符是这个表中的索引
需要元数据数据来管理打开文件:
- 文件指针:指向最近的一次读写位置,每个打开了这个文件的进程都这个指针
- 文件打开计数:记录文件打开的次数–当最后一个进程关闭了文件时,允许将其从打开文件表中移除
- 文件磁盘位置:缓存数据访问信息
- 访问权限:每个程序访问模式信息
用户视图:
- 持久的数据结构
系统访问接口
- 字节的集合(UNIX)
- 系统不会关心你想存储在磁盘上的任何的数据结构!
操作系统内部视角
- 块的集合(块是逻辑转换单元,而扇区是物理转换单元)
- 块大小<>扇区大小;在UNIX中,块的大小是4KB
当用户说:给我2-12字节空间时会发生什么
- 获取字节所在的块
- 返回块内对应部分
如果说要写2-12字节呢?
- 获取块
- 修改块内对应部分
- 写回块
在文件系统中的所有操作都是在整个块空间上进行的
- 举个例子, getc(,putc() :即使每次只访问1字节的数据,也会缓存目标数据4096字节
用户怎么访问文件
- 在系统层面需要知道用户的访问模式
顺序访问:按字节依次读取
- 几乎所有的访问都是这种方式
随机访问:从中间读写
- 不常用,但是仍然重要.例如,虚拟内存支持文件:内存页存储在文件中
- 更加快速–不希望获取文件中间的内容的时候也必须先获取块内所有字节。
基于内容访问:通过特征
- 许多系统不提供此种访问方式,相反,数据库是建立在索引内容的磁盘访问上(需要高效的随机访问)
文件结构
无结构
- 单词、比特的队列
简单记录结构
- 列
- 固定长度
- 可变长度
复杂结构
- 格式化的文档(如,MS Word,PDF)
- 可执行文件
- ...
多用户系统中的文件共享是很必要的
访问控制
- 谁能够获得哪些文件的哪些访问权限
- 访问模式:读、写、执行、删除、列举等
文件访问控制列表(ACL)
- <文件实体,权限>
Unix模式
- <用户|组|所有人,读|写|可执行>
- 用户ID识别用户,表明每个用户所允许的权限及保护模式
- 组ID允许用户组成组,并指定了组访问权限
指定多用户/客户如何同时访问共享文件
- 和过程同步算法相似
- 因磁盘I/O和网络延迟而设计简单
Unix文件系统(UFS)语义
- 对打开文件的写入内容立即对其他打开同一文件的其他用户可见
- 共享文件指针允许多用户同时读取和写入文件
会话语义
- 写入内容只有当文件关闭时可见
锁
- 一些操作系统和文件系统提供该功能
目录
文件以目录的方式组织起来
目录是一类特殊的文件
- 每个目录都包含了一张表<name,pointer to file header>
目录和文件的树型结构
- 早期的文件系统是扁平的
(只有一层目录)
层次名称空间

典型操作
- 搜索文件
- 创建文件
- 删除文件
- 枚举目录
- 重命名文件
- 在文件系统中遍历一个路径
操作系统应该只允许内核模式修改目录
- 确保映射的完整性
- 应用程序能够读目录(如ls)
文件名的线性列表,包涵了指向数据块的指针
- 编程简单
- 执行耗时
Hash表- hash数据结构的线性表
- 减少目录搜索时间
- 碰撞–两个文件名的hash值相同
- 固定大小
名字解析:逻辑名字转换成物理资源(如文件)的过程
- 在文件系统中:到实际文件的文件名(路径)
- 遍历文件目录直到找到目标文件
举例:解析“/bin/ls”
- 读取root的文件头(在磁盘固定位置)
- 读取root的数据块
- 搜索“bin”项读取bin的文件头
- 读取bin的数据块;搜索“ls”项
- 读取ls的文件头
当前工作目录
- 每个进程都会指向一个文件目录用于解析文件名
- 允许用户指定相对路径来代替绝对路径
-
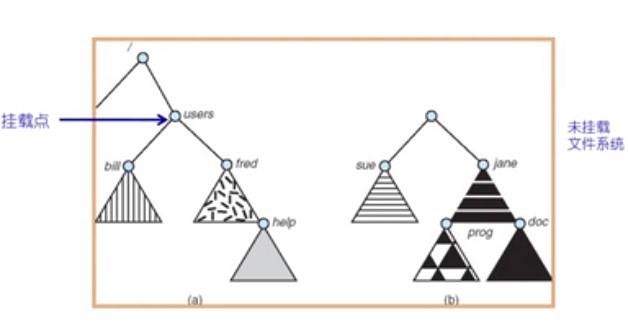
一个文件系统需要先挂载才能被访问
-
一个未挂载的文件系统被挂载在挂载点上
文件别名
两个或多个文件名关联同一个文件
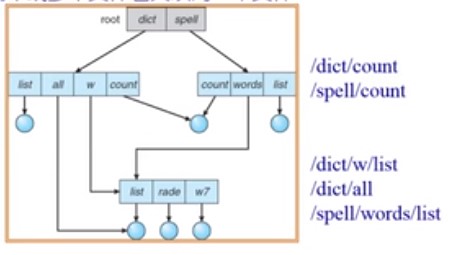
硬链接:多个文件项指向一个文件
软链接:以“快捷方式”指向其他文件
通过存储真实文件的逻辑名称来实现
如果删除一个有别名的文件会如何呢?
- 这个别名将成为一个“悬空指针”
Backpointers方案:
- 每个文件有一个包含多个backpointers的列表,所以删除所有的backpointers
- Backpointers使用菊花链管理
添加一个间接层:目录项数据结构
- 链接–已存在文件的另外一个名字(指针)
- 链接处理–跟随指针来定位文件
循环
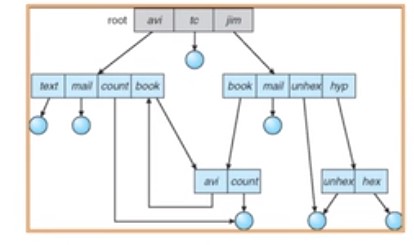
我们如何保证没有循环呢?
- 只允许到文件的链接,不允许在子目录的链接
- 每增加一个新的链接都用循环检测算法确定是否合理
更多实践
- 限制路径可遍历文件目录的数量
文件系统种类
磁盘文件系统
- 文件存储在数据存储设备上,如磁盘.
- 例如:FAT,NTFS,ext2/3,IS09660,等
数据库文件系统
- 文件根据其特征是可被寻址(辨识)的
- 例如:WinFS
日志文件系统
- 记录文件系统的修改/事件
- 例如: journaling file system
网络/分布式文件系统
- 例如:NFS,SMB,AFS,GFS
- 文件可以通过网络被共享
-
- 文件位于远程服务器
- 客户端远程挂载服务器文件系统
- 标准系统文件访问被转换成远程访问
- 标准文件共享协议:NFS for Unix,CIFS for Windows
- 分布式文件系统的问题
- 客户端和客户端上的用户辨别起来很复杂
- 例如,NFS是不安全的
- 一致性问题
- 错误处理模式
特殊/虚拟文件系统
分层结构
- 上层:虚拟(逻辑)文件系统
- 底层:特定文件系统模块

目的
- 对所有不同文件系统的抽象
功能
- 提供相同的文件和文件系统接口
- 管理所有文件和文件系统关联的数据结构
- 高效查询例程,遍历文件系统
- 与特定文件系统模块的交互
卷控制块(Unix:“superblock”)
- 每个文件系统一个
- 文件系统详细信息
- 块、块大小、空余块、计数/指针等
文件控制块(Unix:“vnode”or “inode”)
- 每个文件一个
- 文件详细信息
- 许可、拥有者、大小、数据库位置等
目录节点(Linux:“dentry”)
- 每个目录项一个(目录和文件)
- 将目录项数据结构及树型布局编码成树型数据结构
- 指向文件控制块、父节点、项目列表等
抽象文件系统图
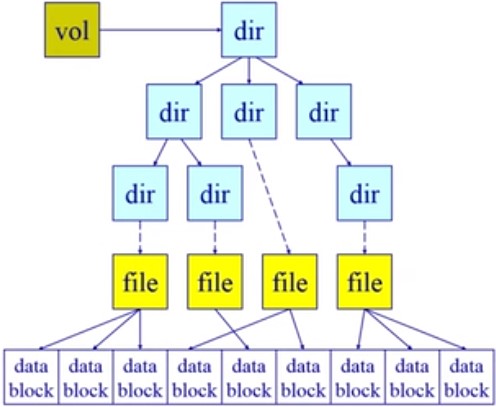
文件系统数据结构
- 卷控制块(每个文件系统一个)
- 文件控制块(每个文件一个)
- 目录节点(每个目录项一个)
持续存储在二级存储中
- 在分配在存储设备中的数据块中
当需要时加载进内存
- 卷控制模块:当文件系统挂载时进入内存
- 文件控制块:当文件被访问时进入每次
- 目录节点:在遍历一个文件路径时进入内存
数据块缓存

数据块按需读入内存
- 提供read(操作
- 预读:预选读取后面的数据块
数据块使用后被缓存
- 假设数据将会再次被使用
- 写操作可能被缓存和延迟写入
两种数据块缓存方式
- 普通缓冲区缓存
- 页缓存:统一缓存数据块和内存页
分页要求
- 当需要一个页时才将其载入内存
支持存储
- 一个页(在虚拟地址空间中)可以被映射到一个本地文件中(在二级存储中)

文件数据块的页缓存
- 在虚拟内存中文件数据块被映射成页
- 文件的读/写操作被转换成对内存的访问
- 可能导致缺页和/或设置为脏页
- 问题:页置换-从进程或文件页缓存中?
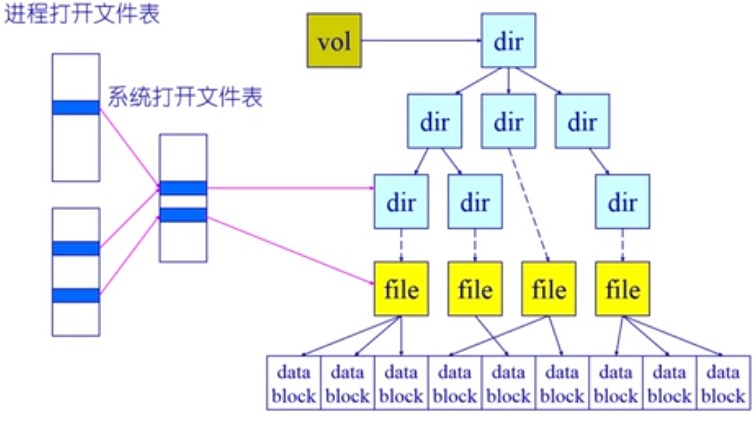
打开文件的数据结构
打开文件描述
- 每个被打开的文件一个
- 文件状态信息
- 目录项、当前文件指针、文件操作设置等
打开文件表
- 一个进程一个
- 一个系统级的
- 每个卷控制块也会保存一个列表
- 所以如果有文件被打开将不能被卸载
- 一些操作系统和文件系统提供该功能
- 调节对文件的访问
- 强制和劝告:
- 强制–根据锁保持情况和需求拒绝访问
- 劝告–进程可以查找锁的状态来决定怎么做
文件分配
- 大多数文件都很小
- 需要对小文件提供强力的支持
- 块空间不能太大
- 一些文件非常大
- 必须支持大文件(64-bit文件偏移).大文件访问需要相当高效
如何为一个文件分配数据块
分配方式
- 连续分配
- 链式分配
- 索引分配
指标
- 高效:如存储利用(外部碎片)
- 表现:如访问速度
连续分配
文件头指定起始块和长度
位置/分配策略
- 最先匹配,最佳匹配, ...
优势
- 文件读取表现好
- 高效的顺序和随机访问
劣势
- 碎片!
- 文件增长问题
- 预分配?
- 按需分配?
文件以数据块链表方式存储
文件头包含了到第一块和最后一块的指针
优点
- 创建、增大、缩小很容易
- 没有碎片
缺点
- 不可能进行真正的随机访问
- 可靠性
- 破坏一个链然后…
为每个文件创建一个名为索引数据块的非数据数据块
- 到文件数据块的指针列表
文件头包含了索引数据块
优点
- 创建、增大、缩小很容易
- 没有碎片
- 支持直接访问
缺点
- 当文件很小时,存储索引的开销
- 如何处理大文件?
-
- 链式索引块
- 多级索引块

文件头包含13个指针
- 10个指针指向数据块;
- 第11个指针指向间接数据块;
- 第12个指针指向二重间接数据块;
- 第13个指针指向三重间接数据块
影响
- 提高了文件大小限制阀值
- 动态分配数据块,文件扩展很容易
- 小文件开销小
- 只为大文件分配间接数据块,大文件在访问间接数据块是需要大量的查询
空闲空间列表
- 跟踪在存储中的所有未分配的数据块
- 空闲空间列表存储在哪里?
- 空闲空间列表的最佳数据结构是什么样的?
-
用位图代表空闲数据块列表:
-
111111111111111001110101011101111...
-
如果i =О表明数据块i是空闲,反之则已分配
-
- 使用简单但是可能会是一个big vector:
- 160GB disk ->40M blocks ->5MB worth of bits
- 然而,如果空闲空间在磁盘中均匀分布,那么在找到“0”之前需要扫描n/r
-
n=磁盘上数据块的总数
-
r =空闲块的数目
-
需要保护:
- 指向空闲列表的指针
- 位图解决:
-
必须保存在磁盘上
-
在内存和磁盘拷贝可能有所不同
-
不允许block[i]在内存中的状态为bit[i] =1而在磁盘中bit[i]= 0
-
- 在磁盘上设置bit[i] = 1
- 分配block[i]
-
在内存中设置bit[i]= 1 ?
- 链式列表
- 分组列表
多磁盘管理——RAID
通常磁盘通过分区来最大限度减小寻道时间
- 一个分区是一个柱面的集合
- 每个分区都是逻辑上独立的磁盘
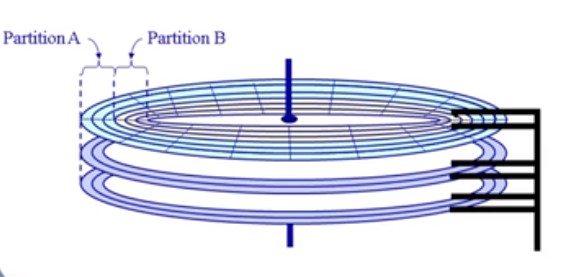
分区:硬件磁盘的一种适合操作系统指定格式的划分
卷:一个拥有一个文件系统实例的可访问的存储空间
- 通常常驻在磁盘的单个分区上
使用多个并行磁盘来增加
- 吞吐量(通过并行)
- 可靠性和可用性(通过冗余)
RAID -冗余磁盘阵列
- 各种磁盘管理技术
- RAID levels:不同RAID分类(如,RAID-0,RAID-1,RAID-5)
实现
- 在操作系统内核:存储/卷管理
- RAID硬件控制器(I/O)
数据块分成多个子块,存储在独立的磁盘中
- 和内存交叉相似
通过更大的有效块大小来提供更大的磁盘带宽
可靠性成倍增长
读取性能线性增加
- 向两个磁盘写入,从任何一个读取
数据块级磁带配有专用奇偶校验磁盘
- 允许从任意一个故障磁盘中恢复
- 例如:存储8,9,10,11,12,13,14,15,0,1,2,3
RAID-5

条带化和奇偶校验按byte-by-byte或者bit-by-bit
- RAID-O/4/5: block-wise
- RAID-3: bit-wise
例如:在RAID-3系统中存储bit-string 101
RAID-5:每个条带块有一个奇偶校验块允许一个磁盘错误
RAID-6:两个冗余块>有一种特殊的编码方式允许两个磁盘错误
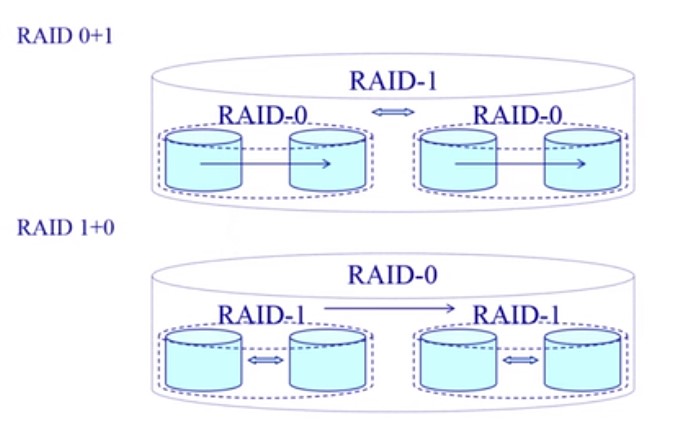
组合方式
磁盘调度
磁盘结构
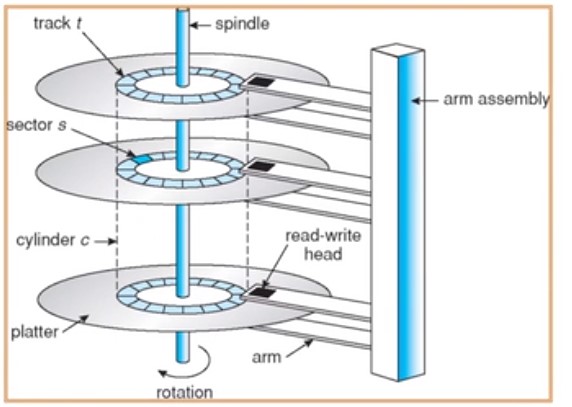
读取或写入时,磁头必须被定位在期望的磁道,并从所期望的扇区的开始
寻道时间
- 定位到期望的磁道所花费的时间
旋转延迟
- 从扇区的开始处到到达目的处花费的时间
平均旋转延迟时间=磁盘旋转一周时间的一半
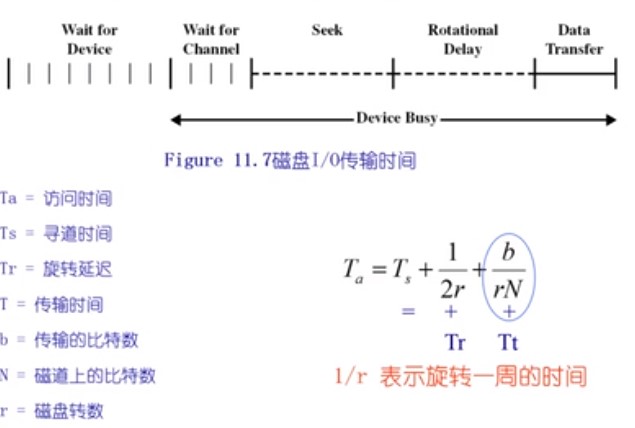
寻道时间是性能上区别的原因
对单个磁盘,会有一个I/O请求数目
如果请求是随机的,那么会表现很差
处理方式
- 按顺序处理请求(FIFO)
- 公平对待所有进程
- 在有很多进程的情况下,接近随机调度的性能
- 最短服务有限(SSTF)
-
选择从磁臂当前位置需要移动最少的I/0请求总是选择最短寻道时间 选择从磁臂当前位置需要移动最少的I/O请求
-
总是选择最短寻道时间
- SCAN
- 磁臂在一个方向上移动,满足所有为完成的请求,直到磁臂到达该方向上最后的磁道
- 调换方向
- 有时被称为elevator algorithm
- CSCAN
- 限制了仅在一个方向上扫描
-
当最后一个磁道也被访问过了后,磁臂返回到磁盘的另外一端再次进行扫描
- CLOOK
- CSCAN的改进版本
-
磁臂先到达该方向上最后最后一个请求处,然后立即反转
在SSTF、SCAN及CSCAN几种调度算法中,都可能出现磁臂停留在某处不动的情况,例如进程反复请求对某一磁道的I/0操作。我们把这一现象称为“磁臂粘着”(arm stickiness)。
N-Step-SCAN算法是将磁盘请求队列分成若干个长度为N的子队列,磁盘调度将按FCFS算法依次处理这些子队列。而每处理一个队列时又是按SCAN算法,对一个队列处理完后,再处理其他队列。
当正在处理某子队列时,如果又出现新的磁盘I/0请求,便将新请求进程放入其他队列,这样就可避免出现粘着现象。
FSCAN算法实质上是N步SCAN算法的简化,即FSCAN只将磁盘请求队列分成两个子队列。
一个是由当前所有请求磁盘I/0的进程形成的队列,由磁盘调度按SCAN算法进行处理。在处理某队列期间,将新出现的所有请求磁盘I/0的进程,放入另一个等待处理的请求队列。这样,所有的新请求都将被推迟到下一次扫描时处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号