算法提高课
给定 nn 个长度不超过 5050 的由小写英文字母组成的单词,以及一篇长为 mm 的文章。
请问,其中有多少个单词在文章中出现了。
注意:每个单词不论在文章中出现多少次,仅累计 11 次。
1|0输入格式
第一行包含整数 TT,表示共有 TT 组测试数据。
对于每组数据,第一行一个整数 nn,接下去 nn 行表示 nn 个单词,最后一行输入一个字符串,表示文章。
2|0输出格式
对于每组数据,输出一个占一行的整数,表示有多少个单词在文章中出现。
3|0数据范围
1≤n≤1041≤n≤104,
1≤m≤1061≤m≤1064|0输入样例:
5|0输出样例:
难度:中等 时/空限制:1s / 64MB 总通过数:7347 总尝试数:13048 来源:《信息学奥赛一本通》 , HDU2222 , kuangbin专题 算法标签
挑战模式
核心思路:首先我们可以联想KMP,但是我们会发现这里有多组数据匹配,所以使用kmp最后是一定会超时的。所以我们可以选择建树来进行优化,也就是建立一颗字典树,然后在这个上面使用kmp。然后我们回想一下kmp,我们会发现这个的主要思路还是求ne数组,也就是我们的回退数组。然后在这个树上怎么将我们的ne数组进行映射呢,其实我们可以发现其实就是将代码由一维的形式转变为二维的形式。其实最重要的一个点就是我们可以=通过这样的一个方式把我们的后缀字符串一网打尽,比如我们求she,就可以把he,e这列后缀字符串给找出来。为什么可以这样呢,因为我们的kmp就是的ne数组的定义就是最长的前后缀的下标
这里我们首先需要回顾一下
下面先看代码:
所以这整个过程其实就是相当于在树上完成了转移,也就是字符串的回退.这也就是董晓算法中的回退边的由来。那董晓算法中的转移边是怎么来的呢,于是我们看这个代码可不可以进一步进行优化。
我们可以看到这段代码:
我们发现这个j只要没有匹配那么他就会一直往会跳,所以我们怎么可以使得他他少跳几步呢。这里就可以假设循环到i层的时候,前i-1层都求对了。那么ne[t]就是那个ne指针最终需要跳到的位置.
这里其实会发现优化之后的代码还是比较难理解,这里可以参照董晓算法。他那里引入了转移边和回退边的定义。回退边就是我们的ne数组,转移边的作用是让我们每次没必要退回根节点,而是可以通过转移边进行转移。就是可以帮助我们更快的找到找到那个字符串的最长后缀字符串所对应的前缀字符串,比如:her er.
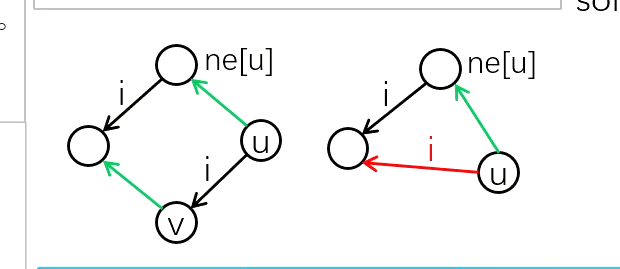
左边是回跳边,符合四边形法则。右边是转移边,符合三角形法则.
__EOF__

本文链接:https://www.cnblogs.com/xyh-hnust666/p/16980552.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具