结对作业二
结对作业二
作业摘要
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对作业二 |
| 结对学号 | 周美婷 221801339 谢语涵 221801104 |
| 这个作业的目标 | 1. 通过github协作 2.规范代码 3.学会爬虫的使用 |
| 作业正文 | 作业正文 |
| 其他参考文献 | CSDN、简书、github |
目录:
作业摘要
PSP表格
GitHub仓库地址
代码规范地址
作品展示
结对讨论
实现过程
代码说明
总结
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 10 | 8 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 20 | 15 |
| • Learning tools | • 学习原型设计工具 | 60 | 120 |
| • Discussion | • 讨论 | 30 | 60 |
| • Design | • 具体设计 | 360 | 420 |
| • Coding | • 具体编码 | 1000 | 1200 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| • Code Review | • 代码复审 | 90 | 180 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 360 | 420 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 180 | 120 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 2160 | 2613 |
GitHub仓库地址
点击进入仓库地址
代码规范地址
点击进入代码规范
作品展示
管理员页面对论文搜索
- 管理员界面支持对标题进行模糊搜索
- 管理员界面搜索时可以选择推荐(即热度较高)的文章
-
- 推荐的文章由管理员定义,有一定使用量后用浏览数代替
- 管理员界面搜索时可以选择论文所属的顶会
- 管理员界面搜索记录可以保存
- 管理员界面可以用clear键一键清除所有内容

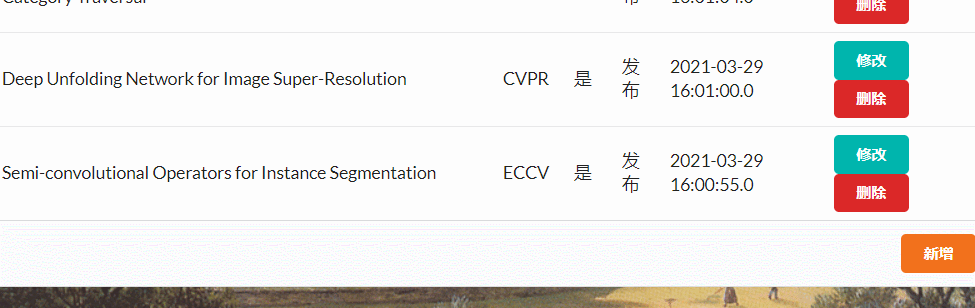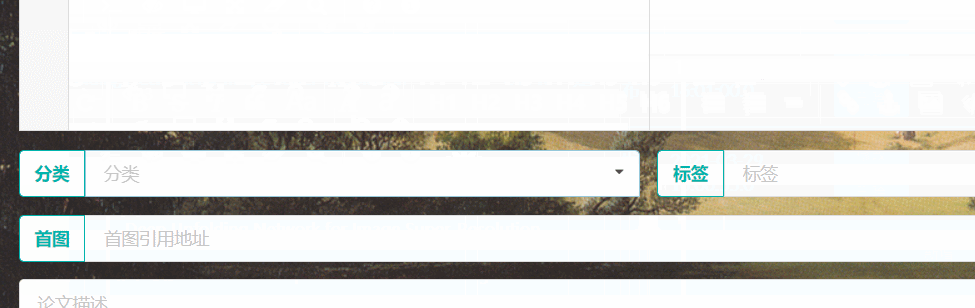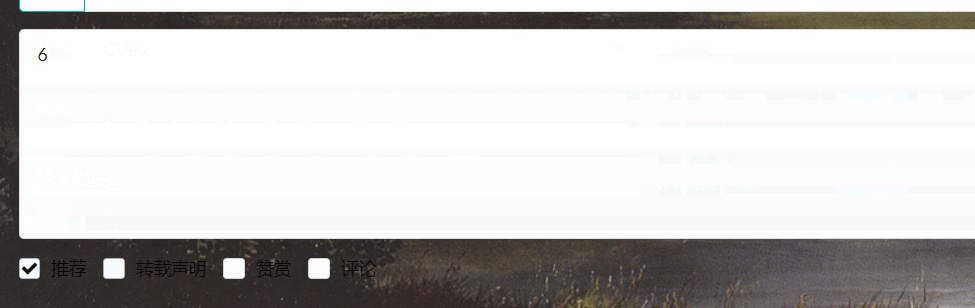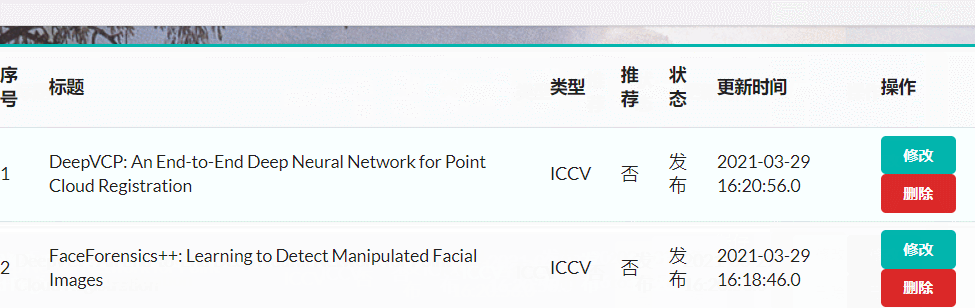
管理员对论文进行添加删除
- 管理员可以对论文进行一键删除
- 管理员可以对论文进行添加
-
- 添加标题
- 添加文章内容(文章内容使用了markdown插件,可以添加图片等等)
- 选择分类标题
- 可添加封面图
- 对论文进行简要描述
- 对论文功能进行勾选(可勾选推荐、转载说明等等)
- 可以保存草稿下次可继续编写
管理员对分类进行添加删除
- 手动输入类别名进行添加分类
- 一篇文章只能隶属于一个顶会分类
- 可以对已有分类进行修改
- 管理员可以对文章分类进行删除
-
- 删除成功显示提示框“删除成功”

管理员对标签进行添加删除
- 手动输入类别名进行添加标签
- 一篇文章可以有多个标签
- 可以对已有标签进行修改
- 管理员可以对文章标签进行删除
-
- 删除成功显示提示框“删除成功”

首页点击分类和标签进入相应类别的论文列表
- 每个分类和标签都可以打开对应的论文列表
-
- 用户可以自选感兴趣的领域的论文
- 最新更新的论文实时展示
-
- 右上角显示论文总数

首页进入归档按年份查看论文
- 论文按照时间进行归档
-
- 用户可以查找自己感兴趣的年份

论文一
- 按权重统计论文的热度Top10关键字
-
- 与之前的wordcount作业一样,利用map对单词出现次数进行权重统计
-
- 权重统计方法:属于Title的单词权重为10,属于Abstract 单词权重为1
- 将鼠标放在相应模块上
-
- 圆圈中间展示热词名称
- 图标上展示热词热度数
- 可以自己选择关键词对比的数量
三大顶会热词TOP10
- 热词热度从大到小排列
- 鼠标历经可以放大标题
- 鼠标历经可以查看热词比例和名称
- 可以自己选择关键词对比的数量
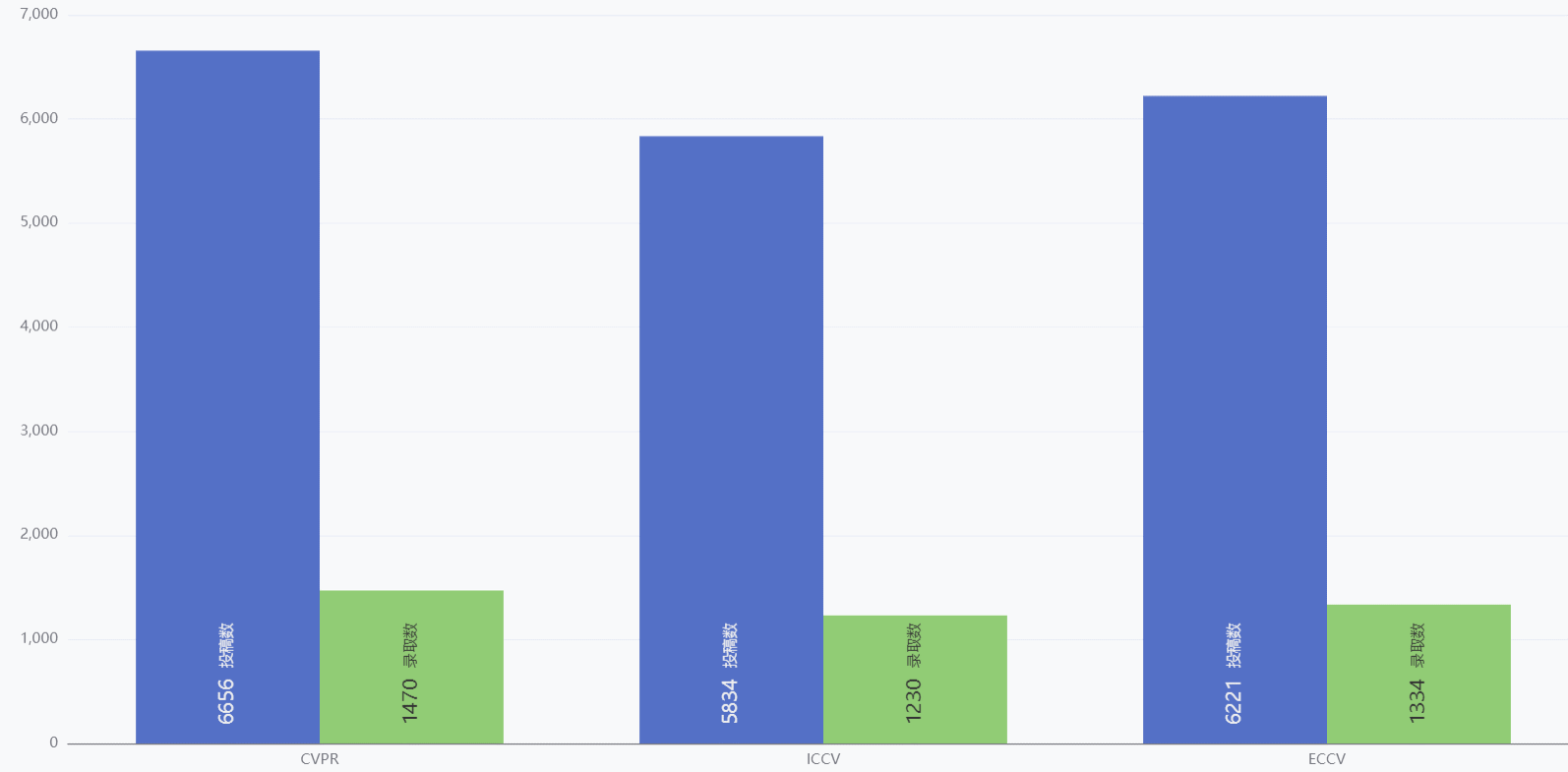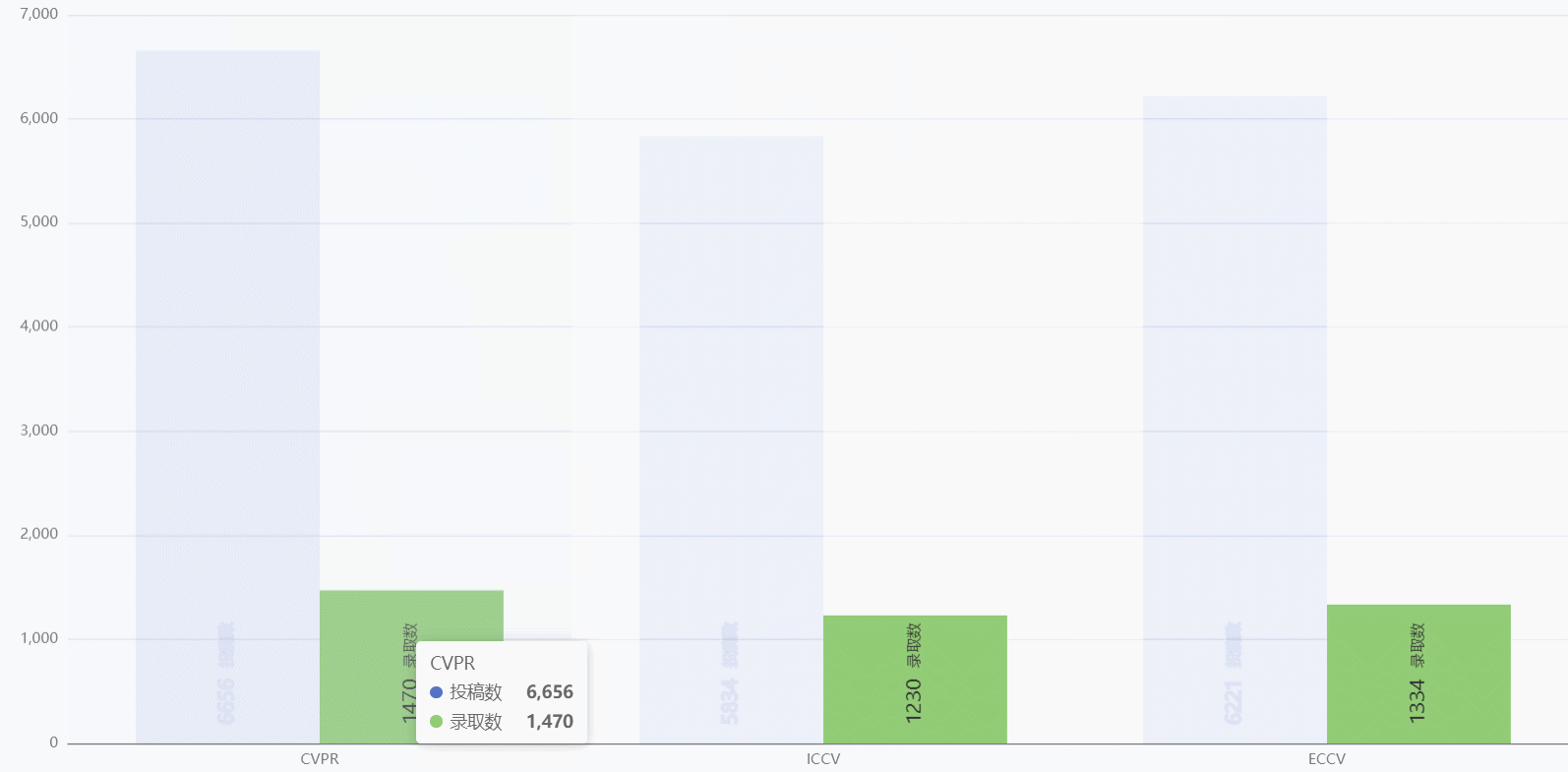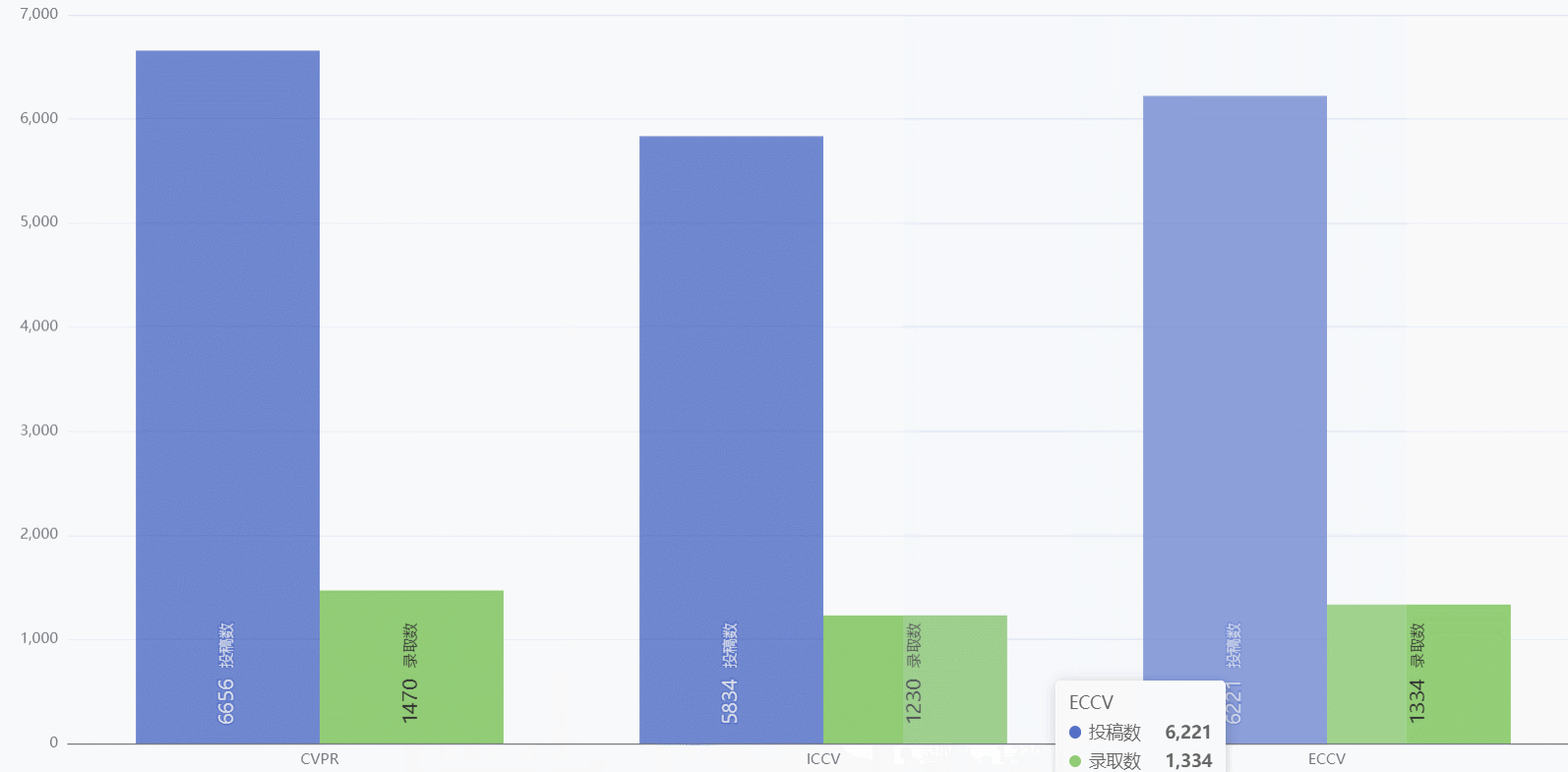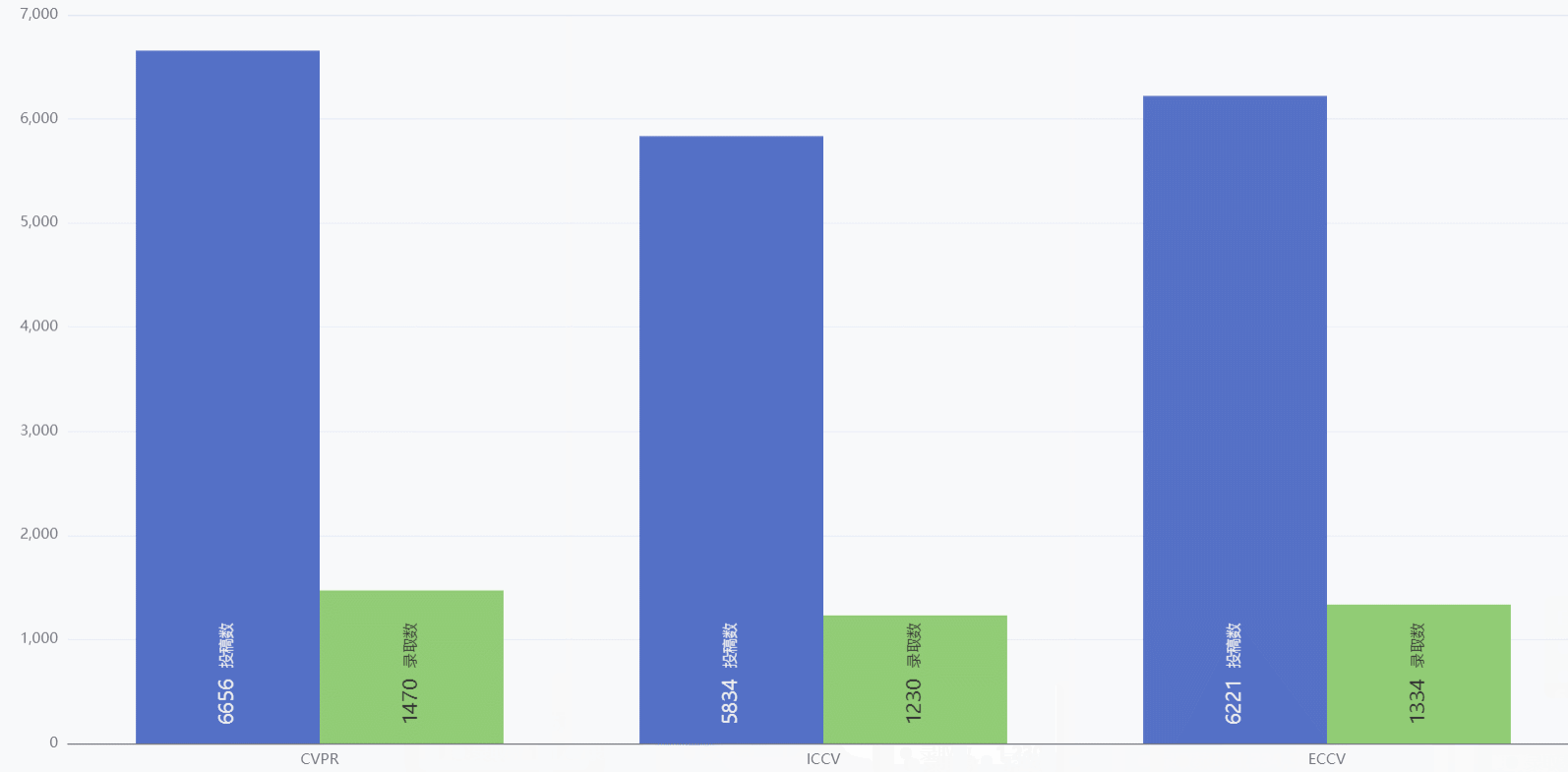
三大顶会投稿量和录取量对比
- 既可以对比三大顶会之间的投稿量和录取量,也可以对比同一个顶会的录取比
-
- 鼠标历经可以只显示投稿数或者录取数,方便用户对比
- 鼠标历经也可以展示详细数据
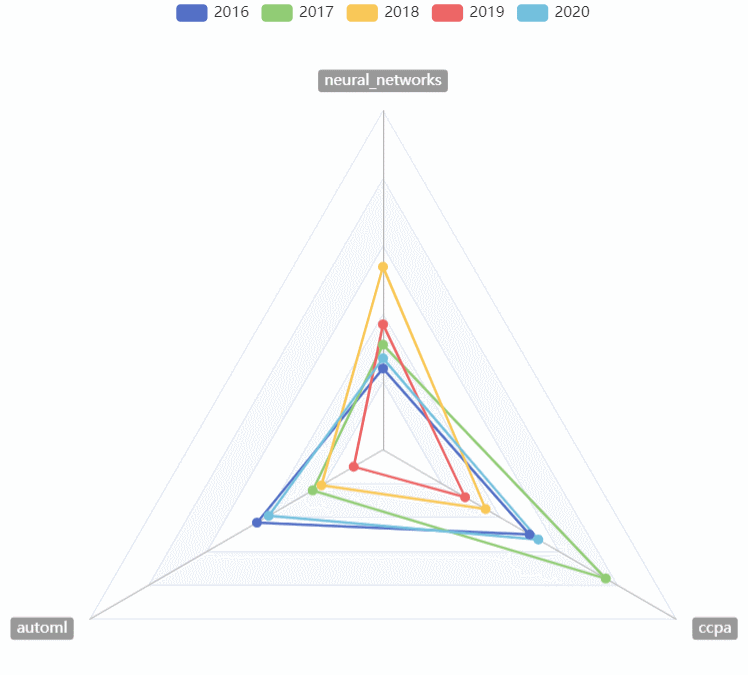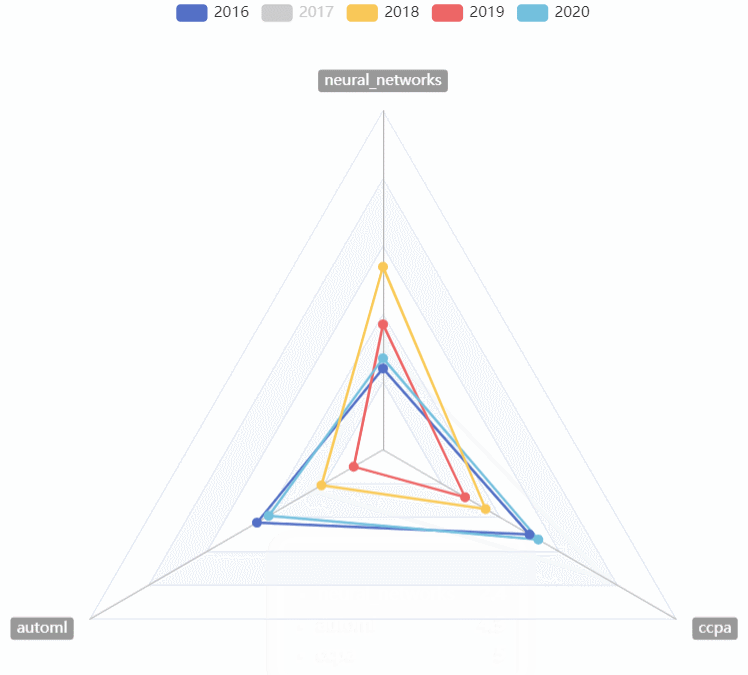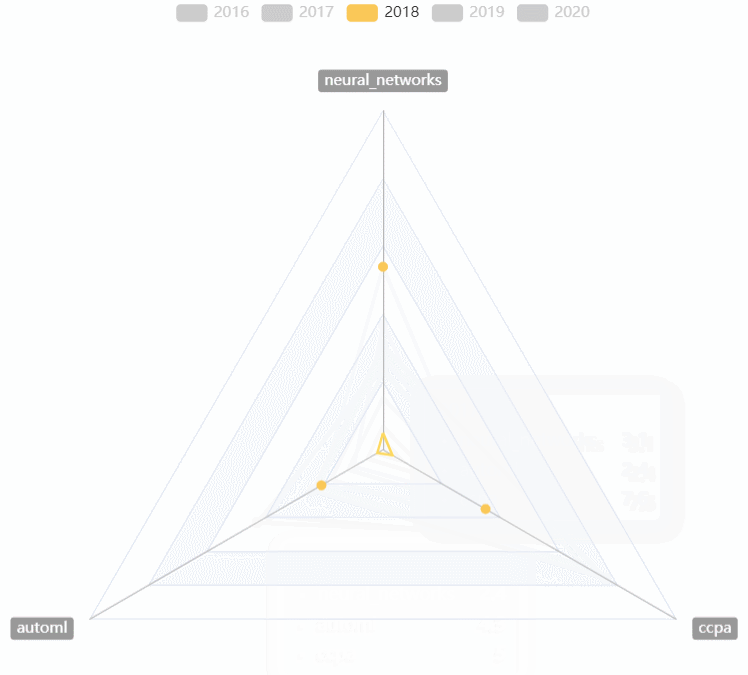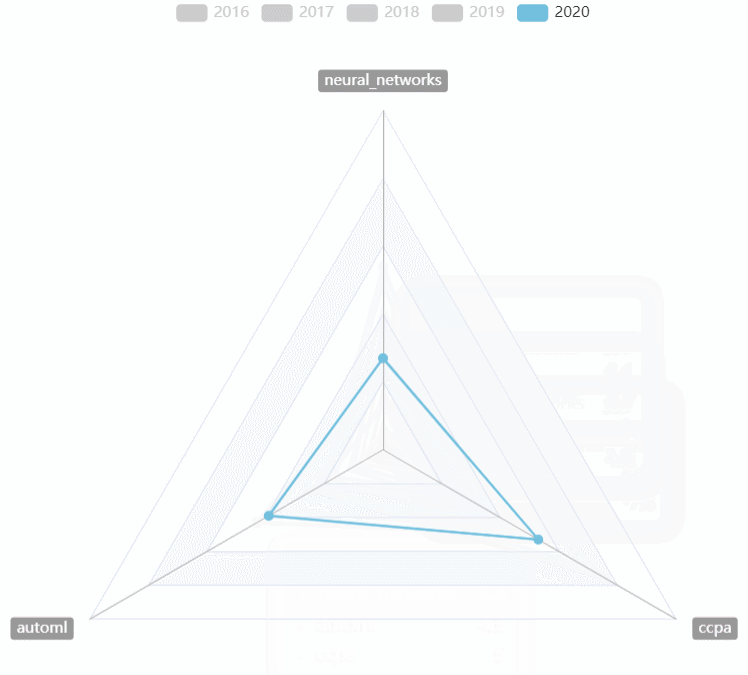
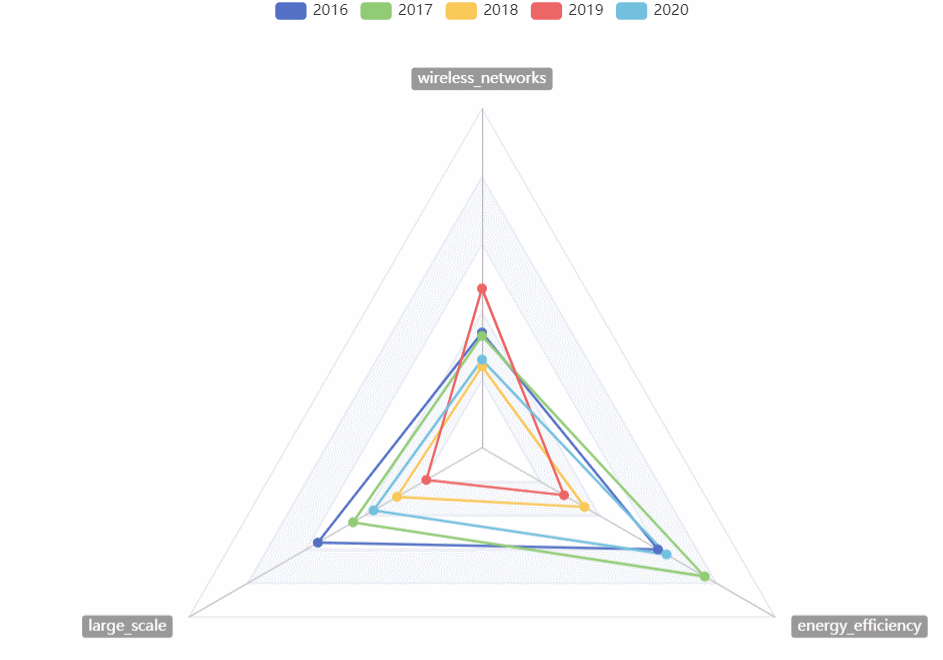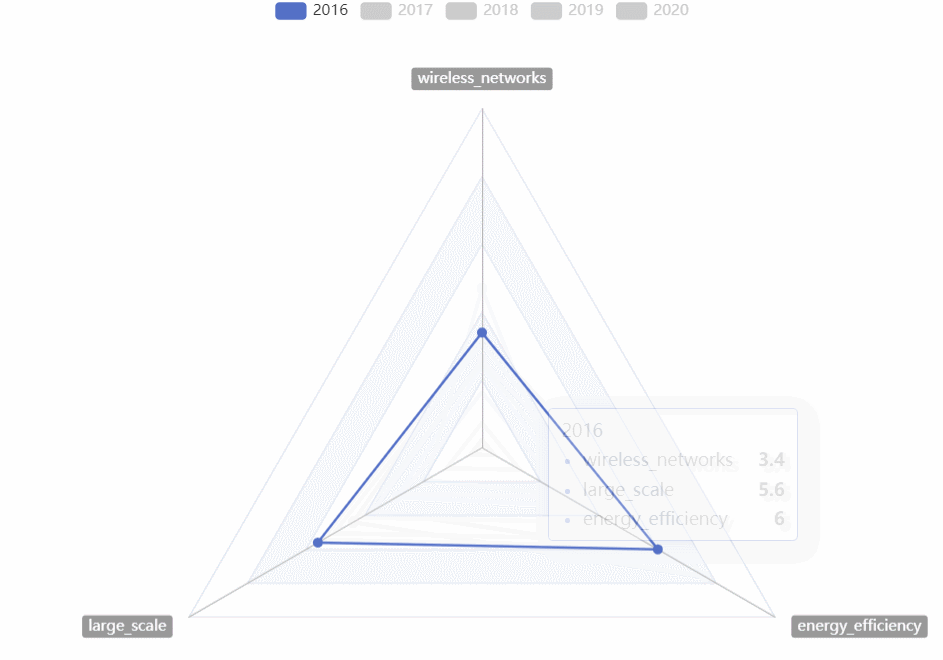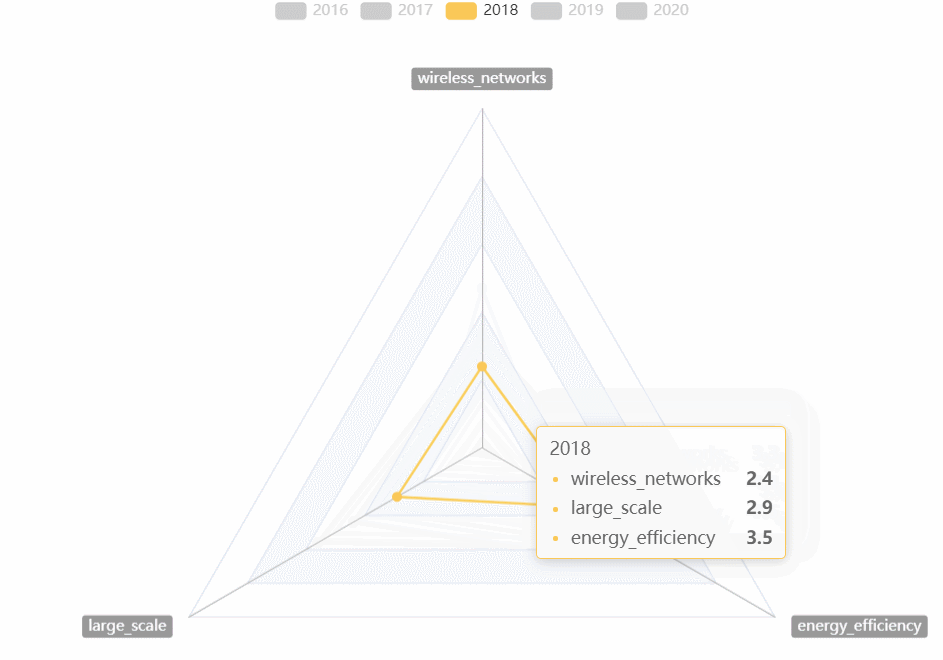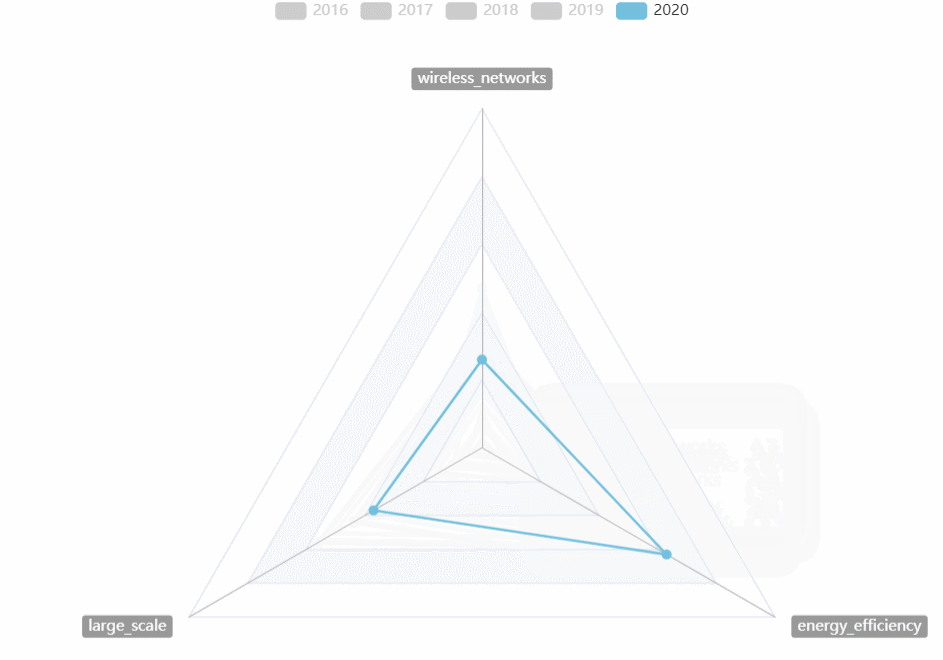
CVPR热词走势
- 用雷达图对2016~2020的CVPR热词走势进行对比
-
- 可以选择任意的年份进行比较
- 可以直观的看到某一年份最热的热词
- 可以直观的看到几年来热词走势
ECCV热词走势
- 用雷达图对2016~2020的ECCV热词走势进行对比
-
- 可以选择任意的年份进行比较
- 可以直观的看到某一年份最热的热词
- 可以直观的看到几年来热词走势

ICCV热词走势
- 用雷达图对2016~2020的ICCV热词走势进行对比
-
- 可以选择任意的年份进行比较
- 可以直观的看到某一年份最热的热词
- 可以直观的看到几年来热词走势
结对讨论
写在最前——讨论总结:讨论多以面对面和通话的形式进行,为了方便之后的开发,在讨论后我们制作了一个整体框架(因为是初步讨论的结果,所以和最终的项目会有稍微的不同)。

讨论初期:我们确定了前端和后端,因为我们都没有相关的开发经验,反倒没有纠结的认领了任务。之后我们还确定了框架,最后爬虫部分我们还是比较倾向与用python(因为可以学习新技能hh)。

一些细节处理:比如说我们打算用MD5来实现用户密码的加密,还有一些小组件,这都是一些“性价比”很高的小功能。
通话记录:
实现过程
确定涉及技术:
前端: Semantic-UI框架
后端: JDK1.8+SpringBoot+ Spring Data JPA +MySQL5.7
设计数据库:
论文表
| 名称 | 类型 | 说明 |
|---|---|---|
| appreciation | bit(1) | 推荐 |
| commentabled | bit(1) | 评论 |
| content | longtext | 文章内容 |
| create_time | datetime | 发布论文时间 |
| desctription | varchar(255) | 摘要 |
| published | bit(1) | 公开 |
| title | varchar(255) | 文章标题 |
| update_time | datetime | 上一次修改时间 |
| views | int | 浏览次数 |
| type_id | bigint | 论文类型 |
| user_id | bigint | 作者id |
论文标签表
| 名称 | 类型 | 说明 |
|---|---|---|
| blogs_id | bigint | 论文id |
| tags_id | bigint | 论文标签id |
用户信息表
| 名称 | 类型 | 说明 |
|---|---|---|
| avatar | varchar(255) | 头像 |
| create_time | datetime | 创建时间 |
| nickname | varchar(255) | 名字 |
| password(MD5码) | varchar(255) | 密码 |
| type | int | 类型 |
| update_time | datetime | 修改时间 |
| username | varchar(255) | 用户名称 |
实现爬虫结果:
对词进行热度统计:
- commandline.java (实现命令行处理功能)
- infile.java (实现基础词频分析功能)
- mainbody.java (构成WordCount的主体main)

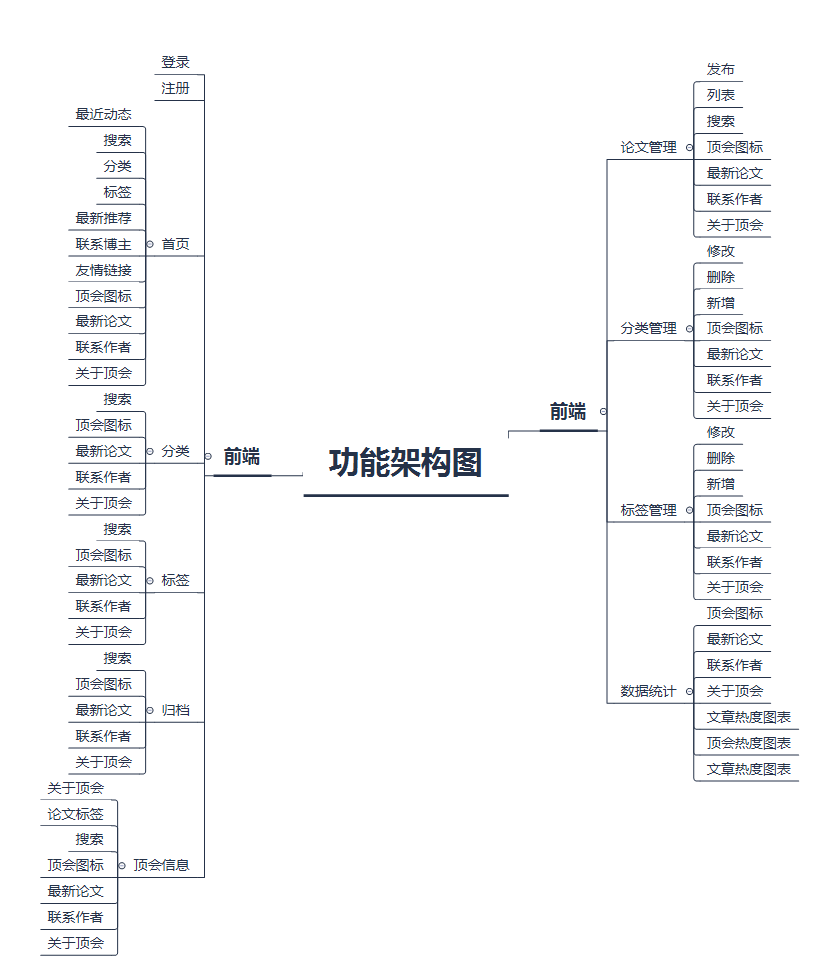
功能架构图:
代码说明
代码的概述部分给在前面,具体细节由注释指出
关键代码一:
- 密码加密采用 MD5 进行加密,使得项目安全性有所提高
- 可以进行32位的加密和16位的加密,数据库可以自动识别转换
//MD5Utils
public static String code(String str){
try {
//拿到一个MD5转换器
MessageDigest md = MessageDigest.getInstance("MD5");
//getBytes字符串转换得到的字节
md.update(str.getBytes());
// 输入的字符串转换成字节数组
byte[]byteDigest = md.digest();
int i;
StringBuffer buf = new StringBuffer("");
for (int offset = 0; offset < byteDigest.length; offset++) {
i = byteDigest[offset];
if (i < 0)
i += 256;
if (i < 16)
buf.append("0");
buf.append(Integer.toHexString(i));
}
//32位加密
return buf.toString();
//16位的加密
//return buf.toString().substring(8, 24);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
return null;
}
}
关键代码二:
- 博客编辑页面采用 Markdown 放行进行书写,集成了 Markdown 编辑器插件
- 使用 MarkdownUtil 工具将 Markdown 转化成 HTML 格式
//MarkdownUtils
//markdown格式转换成HTML
public static String markdownToHtml(String markdown) {}
//增加扩展[标题锚点,表格生成]
public static String markdownToHtmlExtensions(String markdown) {
//h标题生成id
Set<Extension> headingAnchorExtensions = Collections.singleton(HeadingAnchorExtension.create());
//转换table的HTML
List<Extension> tableExtension = Arrays.asList(TablesExtension.create());
Parser parser = Parser.builder()
.extensions(tableExtension)
.build();
Node document = parser.parse(markdown);
HtmlRenderer renderer = HtmlRenderer.builder()
.extensions(headingAnchorExtensions)
.extensions(tableExtension)
.attributeProviderFactory(new AttributeProviderFactory() {
public AttributeProvider create(AttributeProviderContext context) {
return new CustomAttributeProvider();
}
})
.build();
return renderer.render(document);
}
关键代码三:
- 使用 CommentUtil 工具类以及 Semantic-UI 中自带的留言组件实现评论功能,让评论显示为层级
//CommentUtil
//评论格式化工具
//循环每个顶级的评论节点
public static List<Comment> eachComment(List<Comment> comments) {}
//找出root为根节点,blog不为空的对象集合
public static void combineChildren(List<Comment> comments) {
for (Comment comment : comments) {
List<Comment> replys1 = comment.getReplyComments();
for(Comment reply1 : replys1) {
//循环迭代,找出子代,存放在tempReplys中
recursively(reply1);
}
//修改顶级节点的reply集合为迭代处理后的集合
comment.setReplyComments(tempReplys);
//清除临时存放区
tempReplys = new ArrayList<>();
}
}
//存放迭代找出的所有子代的集合
public static List<Comment> tempReplys = new ArrayList<>();
//像剥洋葱一样一层一层剥出来,用递归迭代
public static void recursively(Comment comment) {}
关键代码四:
- 与之前的wordcount作业一样,利用map对单词出现次数进行权重统计
- 权重统计方法:属于Title的单词权重为10,属于Abstract 单词权重为1
public int countwords(String str) {
List<String> wordslist = new ArrayList<String>();
//剔除文本中的非字母和数字的部分并以!作为暂时的分隔符
String regex ="[^0-9a-zA-Z]";
Pattern pat = Pattern.compile(regex);
Matcher mat = pat.matcher(str);
str = mat.replaceAll("!");
//按照分隔符划分
String [] textArray = str.split("!+");
//对单词形式进行约定
String v_regex = "^[a-z]{4}[a-z0-9]*$";
for(String i:textArray){
Pattern v_pat = Pattern.compile(v_regex);
Matcher v_mat = v_pat.matcher(i);
if(v_mat.matches()) {
wordslist.add(i);
}
}
return wordslist.size();
}
public void createmap(List<String> list,int weight) {
for(String i:list){
if(!ver.containsKey(i))
ver.put(i, weight);
else {
int num = ver.get(i);
ver.put(i, num+weight);
}
}
List<Map.Entry<String,Integer>> verlist = new ArrayList<Map.Entry<String,Integer>>(ver.entrySet());
Collections.sort(verlist,new Comparator<Map.Entry<String, Integer>>(){
//用Map实现统计,参照之前的作业
public int compare(Map.Entry<String, Integer> o1,Map.Entry<String, Integer> o2) {
if(o1.getValue()==o2.getValue())
return (o1.getKey()).compareTo(o2.getKey());
return o2.getValue()-o1.getValue();
}
});
wordsmap = verlist;
}
关键代码五:
- 用urllib.request抓取顶会论文列表网址得到源代码,beautifulsoup配合正则(附加功能爬虫使用到)即可得到论文列表的基本信息
f = open("result.txt", 'a', encoding='utf-8')
html1 = urllib.request.urlopen("http://openaccess.thecvf.com/CVPR2018.py").read()
bf1 = BeautifulSoup(html1)
texts1 = bf1.select('.ptitle')
a_bf = BeautifulSoup(str(texts1))
a = a_bf.find_all('a')
urls = []
for each in a:
urls.append("http://openaccess.thecvf.com/" + each.get('href'))
for i in range(len(urls)):
f.write(str(i))
f.write("\n")
html2 = urllib.request.urlopen(urls[i]).read()
bf = BeautifulSoup(html2)
texts2 = bf.find_all('div', id='papertitle')
f.write("Title: " + texts2[0].text.lstrip('\n') + "\n")
texts3 = bf.find_all('div', id='abstract')
f.write("Abstract: " + texts3[0].text.lstrip('\n') + "\n\n\n")
总结
心路历程和收获
XYH: 这次的结对作业使我基本掌握了Semantic-UI框架的使用,也学会了一些python的皮毛(👉 有时间我会深入学习一下python👈 )。整个项目部署和测试阶段的调试,让我对项目开发的整体流程有了一个全面的了解,加深了我对前后端的技术栈的掌握,以及使我能够部署项目,Linux 服务器相关操作更佳熟练。同时,相比起上一次结对作业,我更加懂得如何通过团队的合作达成1+1>2的效果😇 。
ZMT:通过这次结对作业,我从零开始学习了SpringBoot相关的开发技术,根据视频的讲解一点点的动手去开发使我受益匪浅😏 。同时,我对自己的代码有了更佳严格的要求、 有了不同的代码和业务思想,巩固了后端技术栈的知识,对代程序编写有更加深刻的认识😴。这次结对编程我们的分工也更加的合理,总体的过程十分顺利,也期待之后的团队实践项目。
队友评价
XYH:这次的作业任务很重,我和MT也没有相关的开发经验,还好我们都一心一意想攻克难关,坚持了下来。在这种高压的环境下,有一个可以互相帮助的人是很难得的。🙈 🙉🙊 而且经历过第一次的结对作业,我们的沟通和任务的分配可以说是越来越顺利,因此,这次作业,我们匀出了更多的时间在改进我们的作品上😉 。
ZMT:做事认真负责,遇到不懂上网去查询相关的资料让我们一起去学习,去弄懂。😄 对时间的把握比我好,在我懒时,会督促我把进度提上来,起到了监督的作用;一些代码的编写比较熟练,一些方面会教导我;虽然不能做到完全按照原型设计编写前端界面,但是前端编写依旧美观。 ✌️
