C++面向对象总结——继承
引言
类是对现实中事物的抽象,类的继承和派生的层次结构则是对自然界中事物分类、分析的过程在程序设计中的体现。
一,继承的概念及语法
继承是类与类之间的关系,是一个很简单很直观的概念,与现实世界中的继承类似,例如儿子继承父亲的财产。
继承(Inheritance)可以理解为一个类从另一个类获取成员变量和成员函数的过程。例如类 B 继承于类 A,那么 B 就拥有 A 的成员变量和成员函数。被继承的类称为父类或基类,继承的类称为子类或派生类。
派生类除了拥有基类的成员,还可以定义自己的新成员,以增强类的功能。
以下是两种典型的使用继承的场景:
- 当你创建的新类与现有的类相似,只是多出若干成员变量或成员函数时,可以使用继承,这样不但会减少代码量,而且新类会拥有基类的所有功能。
- 当你需要创建多个类,它们拥有很多相似的成员变量或成员函数时,也可以使用继承。可以将这些类的共同成员提取出来,定义为基类,然后从基类继承,既可以节省代码,也方便后续修改成员
// 基类 class Animal { // eat() 函数 // sleep() 函数 }; //派生类 class Dog : public Animal { // bark() 函数 };
💙继承权限和继承方式
C++继承的一般语法为:
class 派生类名:[继承方式] 基类名{ 派生类新增加的成员 };
继承方式限定了基类成员在派生类中的访问权限,包括 public(公有的)、private(私有的)和 protected(受保护的)。此项是可选项,如果不写,默认为 private(成员变量和成员函数默认也是 private)。
现在我们知道,public、protected、private 三个关键字除了可以修饰类的成员,还可以指定继承方式。
不同的继承方式会影响基类成员在派生类中的访问权限。
- 公有继承(public):当一个类派生自公有基类时,基类的公有成员也是派生类的公有成员,基类的保护成员也是派生类的保护成员,基类的私有成员不能直接被派生类访问,但是可以通过调用基类的公有和保护成员来访问。
- 保护继承(protected): 当一个类派生自保护基类时,基类的公有和保护成员将成为派生类的保护成员。
- 私有继承(private):当一个类派生自私有基类时,基类的公有和保护成员将成为派生类的私有成员。
总的来说:继承方式代表的是父类属性在派生类的最低呈现。
派生类可以访问基类中所有的非私有成员。因此基类成员如果不想被派生类的成员函数访问,则应在基类中声明为 private。
我们可以根据访问权限总结出不同的访问类型,如下所示(访问基类的成员):

一个派生类继承了所有的基类方法,但下列情况除外:
- 基类的构造函数、析构函数和拷贝构造函数。
- 基类的重载运算符。
- 基类的友元函数。
二,派生类的构造函数
上面我们说基类的成员函数可以被继承,可以通过派生类的对象访问,但这仅仅指的是普通的成员函数,基类的构造函数不能被继承。构造函数不能被继承是有道理的,因为即使继承了,它的名字和派生类的名字也不一样,不能成为派生类的构造函数。
在设计派生类时,对继承过来的成员变量的初始化工作也要由派生类的构造函数完成,但是大部分基类都有 private 属性的成员变量,它们在派生类中无法访问,更不能使用派生类的构造函数来初始化。
这种矛盾在C++继承中是普遍存在的,解决这个问题的思路是:在派生类的构造函数中调用基类的构造函数。
下面的例子展示了如何在派生类的构造函数中调用基类的构造函数:
#include<iostream> using namespace std; class shape//定义形状基类 { public://公有成员函数 //初始化基类参数列表 shape(float w,float h):width(w),height(h){} protected://保护成员变量 float width; float height; }; class cuboid :public shape//定义长方体派生类 { public : //派生类构造函数指明基类构造函数shape cuboid(float w,float l,float h):shape(w,h),length(l){} float getarea() { return width * height*length; } private: float length; }; int main() { cuboid Cuboid(20,30,40); //实例化cuboid类的对象 float area = Cuboid.getarea(); cout << "面积:" << area << endl; return 0; }
运行结果为:
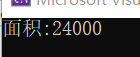
需要注意的是:
cuboid(float w,float l,float h):shape(w,h),length(l){}
shape(w,h)就是基类的构造函数,并将w和h作为实参传递给它,length(l)是派生类的参数初始化列表,用逗号隔开。
也可以将基类构造函数的调用放在参数初始化表后面:
cuboid(float w,float l,float h):length(l),shape(w,h){}
但是不管它们的顺序如何,派生类构造函数总是先调用基类构造函数再执行其他代码(包括参数初始化表以及函数体中的代码)。
另外,函数头部是对基类构造函数的调用,而不是声明,所以括号里的参数是实参,它们不但可以是派生类构造函数参数列表中的参数,还可以是局部变量、常量等,例如:
cuboid(float w,float l,float h):shape(20,10),length(l){}
💙构造函数的调用顺序
从上面的分析中可以看出,基类构造函数总是被优先调用,这说明创建派生类对象时,会先调用基类构造函数,再调用派生类构造函数,如果继承关系有好几层的话,例如:
A --> B --> C
那么创建 C 类对象时构造函数的执行顺序为:
A类构造函数 --> B类构造函数 --> C类构造函数
还有一点要注意:派生类构造函数中只能调用直接基类的构造函数,不能调用间接基类的。
🧡基类构造函数调用规则
事实上,通过派生类创建对象时必须要调用基类的构造函数,这是语法规定。换句话说,定义派生类构造函数时最好指明基类构造函数;如果不指明,就调用基类的默认构造函数(不带参数的构造函数);如果没有默认构造函数,那么编译失败。请看下面的例子:
#include<iostream> using namespace std; class shape//定义形状基类 { public://公有成员函数 //初始化基类参数列表 shape(float w,float h):width(w),height(h){} //默认构造函数 shape():width(20),height(30){} protected://保护成员变量 float width; float height; }; class cuboid :public shape//定义长方体派生类 { public : //初始化派生类参数列表 cuboid(float w,float l,float h):shape(w,h),length(l){} //派生类默认构造函数 cuboid() :length(50){} // float getarea() { return width * height*length; } private: float length; }; int main() { cuboid Cuboid1(20,30,40); //实例化cuboid类的对象 cuboid Cuboid2; float area1 = Cuboid1.getarea(); float area2 = Cuboid2.getarea(); cout << "Cuboid1的面积:" << area1 << endl; cout << "Cuboid2的面积:" << area2 << endl; return 0; }
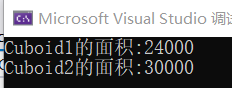
创建对象 Cuboid1时,执行派生类的构造函数 shape(float w,float h):width(w),height(h){},它指明了基类的构造函数。
创建对象 Cuboid2时,执行派生类的构造函数cuboid():length(50){}它并没有指明要调用基类的哪一个构造函数,从运行结果可以很明显地看出来,系统默认调用了不带参数的构造函数,也就是shape(){}
如果将基类 shape中不带参数的构造函数删除,那么会发生编译错误,因为创建对象 Cuboid2时需要调用 shape类的默认构造函数, 而 shape类中已经显式定义了构造函数,编译器不会再生成默认的构造函数。
三,派生类的析构函数
和构造函数类似,析构函数也不能被继承。与构造函数不同的是,在派生类的析构函数中不用显式地调用基类的析构函数,因为每个类只有一个析构函数,编译器知道如何选择,无需程序员干涉。
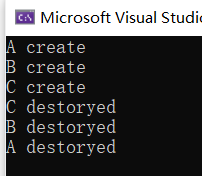
另外析构函数的执行顺序和构造函数的执行顺序也刚好相反:
- 创建派生类对象时,构造函数的执行顺序和继承顺序相同,即先执行基类构造函数,再执行派生类构造函数。
- 而销毁派生类对象时,析构函数的执行顺序和继承顺序相反,即先执行派生类析构函数,再执行基类析构函数。
请看下面的例子:
#include<iostream> using namespace std; class A { public: A() { cout << "A create" << endl; } ~A() { cout << "A destoryed" << endl; } }; class B :public A { public: B() { cout << "B create" << endl; } ~B() { cout << "B destoryed" << endl; } }; class C :public B { public: C() { cout << "C create" << endl; } ~C() { cout << "C destoryed" << endl; } }; int main() { C test; return 0; }
四,向上转型(将派生类赋值给基类)
在 C/C++ 中经常会发生数据类型的转换,例如将 int 类型的数据赋值给 float 类型的变量时,编译器会先把 int 类型的数据转换为 float 类型再赋值;反过来,float 类型的数据在经过类型转换后也可以赋值给 int 类型的变量。
数据类型转换的前提是,编译器知道如何对数据进行取舍。例如:
int a = 10.9; cout << a << endl;
输出结果为 10,编译器会将小数部分直接丢掉(不是四舍五入)。如果是int 转float类型,编译器会自动添加小数(用0添加)。
类其实也是一种数据类型,也可以发生数据类型转换,不过这种转换只有在基类和派生类之间才有意义,并且只能将派生类赋值给基类,包括将派生类对象赋值给基类对象、将派生类指针赋值给基类指针、将派生类引用赋值给基类引用,这在 C++ 中称为向上转型(Upcasting)。相应地,将基类赋值给派生类称为向下转型(Downcasting)。
1️⃣将派生类对象赋值给基类对象
#include<iostream> using namespace std; class A { public: A(int a):m_a(a){} void Cout() { cout << "Class A: m_a=" << m_a << endl; } public: int m_a; }; class B:public A { public: B(int a,int b):A(a), m_b(b){} void Cout() { cout << "Class B: m_a=" << m_a << ", m_b=" << m_b << endl; } private: int m_b; }; int main() { A aa(2); B bb(3, 4); aa.Cout(); bb.Cout(); aa = bb; aa.Cout(); bb.Cout(); }

本例中 A 是基类, B 是派生类,aa、bb 分别是它们的对象,由于派生类 B 包含了从基类 A 继承来的成员,因此可以将派生类对象 bb 赋值给基类对象 aa。通过运行结果也可以发现,赋值后 aa 所包含的成员变量的值已经发生了变化。
赋值的本质是将现有的数据写入已分配好的内存中,对象的内存只包含了成员变量,所以对象之间的赋值是成员变量的赋值,成员函数不存在赋值问题。对象之间的赋值不会影响成员函数,也不会影响 this 指针。
将派生类对象赋值给基类对象时,会舍弃派生类新增的成员,也就是“大材小用”,如下图所示:
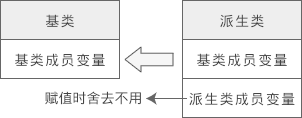
可以发现,即使将派生类对象赋值给基类对象,基类对象也不会包含派生类的成员,所以依然不同通过基类对象来访问派生类的成员。
2️⃣将派生类指针赋值给基类指针
除了可以将派生类对象赋值给基类对象(对象变量之间的赋值),还可以将派生类指针赋值给基类指针(对象指针之间的赋值)。我们先来看一个多继承的例子,继承关系为:
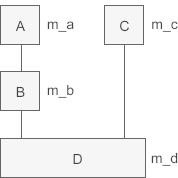
#include <iostream> using namespace std; //基类A class A{ public: A(int a); public: void display(); protected: int m_a; }; A::A(int a): m_a(a){ } void A::display(){ cout<<"Class A: m_a="<<m_a<<endl; } //中间派生类B class B: public A{ public: B(int a, int b); public: void display(); protected: int m_b; }; B::B(int a, int b): A(a), m_b(b){ } void B::display(){ cout<<"Class B: m_a="<<m_a<<", m_b="<<m_b<<endl; } //基类C class C{ public: C(int c); public: void display(); protected: int m_c; }; C::C(int c): m_c(c){ } void C::display(){ cout<<"Class C: m_c="<<m_c<<endl; } //最终派生类D class D: public B, public C{ public: D(int a, int b, int c, int d); public: void display(); private: int m_d; }; D::D(int a, int b, int c, int d): B(a, b), C(c), m_d(d){ } void D::display(){ cout<<"Class D: m_a="<<m_a<<", m_b="<<m_b<<", m_c="<<m_c<<", m_d="<<m_d<<endl; } int main(){ A *pa = new A(1); B *pb = new B(2, 20); C *pc = new C(3); D *pd = new D(4, 40, 400, 4000); pa = pd; pa -> display(); pb = pd; pb -> display(); pc = pd; pc -> display(); cout<<"-----------------------"<<endl; cout<<"pa="<<pa<<endl; cout<<"pb="<<pb<<endl; cout<<"pc="<<pc<<endl; cout<<"pd="<<pd<<endl; return 0; }
运行结果:
Class A: m_a=4 Class B: m_a=4, m_b=40 Class C: m_c=400 ----------------------- pa=0x9b17f8 pb=0x9b17f8 pc=0x9b1800 pd=0x9b17f8
本例中定义了多个对象指针,并尝试将派生类指针赋值给基类指针。与对象变量之间的赋值不同的是,对象指针之间的赋值并没有拷贝对象的成员,也没有修改对象本身的数据,仅仅是改变了指针的指向。
我们将派生类指针 pd 赋值给了基类指针 pa,从运行结果可以看出,调用 display() 函数时虽然使用了派生类的成员变量,但是 display() 函数本身却是基类的。也就是说,将派生类指针赋值给基类指针时,通过基类指针只能使用派生类的成员变量,但不能使用派生类的成员函数。pa 本来是基类 A 的指针,现在指向了派生类 D 的对象,这使得隐式指针 this 发生了变化,也指向了 D 类的对象,所以最终在 display() 内部使用的是 D 类对象的成员变量,相信这一点不难理解。
概括起来说就是:编译器通过指针来访问成员变量,指针指向哪个对象就使用哪个对象的数据;编译器通过指针的类型来访问成员函数,指针属于哪个类的类型就使用哪个类的函数。
3️⃣将派生类引用赋值给基类引用
引用在本质上是通过指针的方式实现的,既然基类的指针可以指向派生类的对象,那么我们就有理由推断:基类的引用也可以指向派生类的对象,并且它的表现和指针是类似的。
修改上例中 main() 函数内部的代码,用引用取代指针:
int main(){ D d(4, 40, 400, 4000); A &ra = d; B &rb = d; C &rc = d; ra.display(); rb.display(); rc.display(); return 0; }
运行结果:
Class A: m_a=4 Class B: m_a=4, m_b=40 Class C: m_c=400
ra、rb、rc 是基类的引用,它们都引用了派生类对象 d,并调用了 display() 函数,从运行结果可以发现,虽然使用了派生类对象的成员变量,但是却没有使用派生类的成员函数,这和指针的表现是一样的。
小结:
向上转型后通过基类的对象、指针、引用只能访问从基类继承过去的成员(包括成员变量和成员函数),不能访问派生类新增的成员。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号