基于用户的协同过滤推荐算法
概述
计算机网络技术带给人们的最大贡献之一就是数据的共享,如何使得我们的项目更加“深入人心”是我们需要不断思考的方向。很多的项目都需要给用户提供数据(例如博客、知识等),但是海量的数据从某种程度上会降低用户获取有用信息的效率。项目如果能给用户推荐他们感兴趣的博客,做到真正的“千人千面”,那将使得我们的项目更加智能,更加具有市场竞争力。
目前常用的推荐算法有:协同过滤、矩阵分解、聚类、深度学习等等,这里我主要聊聊基于用户的系统过滤推荐算法。
原理
思想
协同过滤算法是一个大类,主要有基于用户、基于物品、两者结合等分支,这里我主要介绍的是基于用户的协同过滤算法,这也是我在软工实践中使用过的算法。
主要的思想也很简单,中国有一句俗语“物以类聚,人以群分”,我们可以有很大的把握认为一个和你很相似的用户喜欢的物品也大概率也是你喜欢的物品,这就是基于用户的协同过滤推荐算法的思想。
流程图
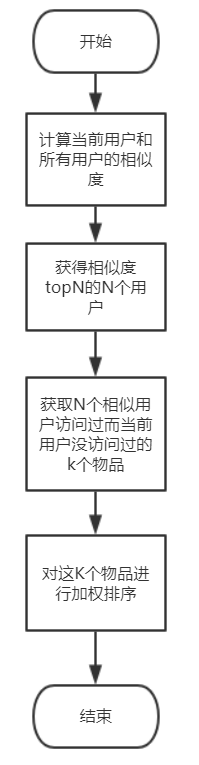
步骤一:计算用户相似度
相似度计算的方法有很多种,这里我主要采用的是余弦相似度:
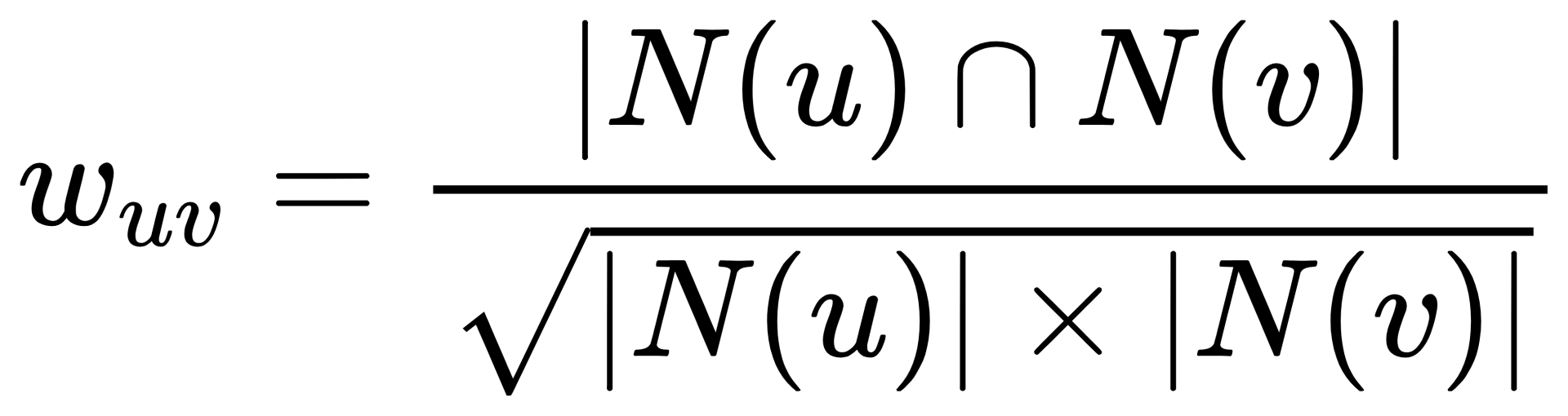
算法比较简单,主要是计算一个用户相似度矩阵,通过一个大根堆来维护topN的N个相似用户列表。
相关代码如下:
/**
* 获取用户的MAX_ACCOUNT_NUMBER个最相似的用户
*
* @param name 用户ID
* @return 优先队列,按照用户相似度从高到低排序
*/
private static Queue<SimilarAccount> getSimilarUsers(String name) {
Long blogNum = accountBlogSize.get(name);
if ((blogNum == null) || (blogNum < 1)) {
return null;
}
// 用户相似度矩阵
long[][] similarityMatrix = new long[MAX_ACCOUNT_NUMBER][MAX_ACCOUNT_NUMBER];
int temp = 0;
// 用户所对应的博客集
for (Map.Entry<String, TreeSet<BlogInterest>> entry : accountBlogCollection.entrySet()) {
nameId.put(entry.getKey(), temp);
idName.put(temp, entry.getKey());
temp = temp + 1;
}
for (Map.Entry<Long, Set<String>> longSetEntry : blogAccountCollection.entrySet()) {// 博客所对应的用户集
Set<String> as = longSetEntry.getValue();
for (String accO : as) {
for (String accT : as) {
if (accO.equals(accT)) {
continue;
}
// 更新有相同感兴趣物品的用户相似度矩阵,主要进行标记,矩阵的值代表相同物品的个数
similarityMatrix[nameId.get(accO)][nameId.get(accT)]++;
similarityMatrix[nameId.get(accT)][nameId.get(accO)]++;
}
}
}
// 进一步计算用户相似度矩阵
Queue<SimilarAccount> similar = new PriorityQueue<>((o1, o2) -> (int) (o2.getSimilar() - o1.getSimilar()));
Long accountNum = accountBlogSize.get(name);
for (int i = 0; i < similarityMatrix.length; ++i) {
if (!accountBlogSize.containsKey(idName.get(i))) {
continue;
}
Long num = accountBlogSize.get(idName.get(i));
if (!idName.get(i).equals(name)) {
similar.add(new SimilarAccount(idName.get(i),
similarityMatrix[nameId.get(name)][i] / Math.sqrt(num * accountNum)));
}
}
return similar;
}
步骤二:获取需要推荐给用户的物品
这一个步骤主要是遍历相似用户列表,获取到相似用户访问过而当前用户未访问过的物品,这些物品就是我们要推荐给用户的物品。
在这里我们还可以进一步计算一下当前用户可能对该物品的兴趣度,兴趣度的计算有很多方法,这里主要采用的是将相似用户的相似度*相似用户对该物品的兴趣度,然后进行所有的用户累加。最后按照兴趣度进行排序后再推荐给用户。
相关代码如下:
// 获取相似用户访问过,而当前用户未访问过的物品
while (!similarAccountQueue.isEmpty()) {
String similarID = similarAccountQueue.poll().getName();
Set<BlogInterest> siat = accountBlogCollection.get(similarID);
for (BlogInterest ai : siat) {
flag = false;
for (BlogInterest bi : ait) {
if (bi.getBlogID().intValue() == ai.getBlogID().intValue()) {
flag = true;// 表示该物品两个用户都访问过,跳过
break;
}
}
if (flag) {
continue;
}
ans.add(IDBlog.get(ai.getBlogID()));// 添加需要推荐的物品
}
}
问题
问题一:冷启动问题
这个问题主要来自于,网站刚开始运行的时候,用户数、用户访问量、用户兴趣度等数据较少,那么会导致推荐效果不好、推荐数据少等问题。
解决方法也很简单,我们可以人为在推荐的算法里面设置一个最小的“阈值列表”,即如果在前期推荐结果不好的情况下默认使用该列表进行填充。
还有一种解决方法是和别的多种推荐算法进行结合,最终的结果进行加权后得出。比如我们可以默认把一些访问量topN的而用户没访问过的物品推荐给用户。
// 解决部分冷启动问题(最初物品数太少,导致推荐的物品太少)
for (Blog blog : baseBlog) {
if (ans.size() > 500) {
break;
}
flag = false;
for (Blog blog1 : ans) {
if (blog1.getId().intValue() == blog.getId().intValue()) {
flag = true;
break;
}
}
if (!flag) {
ans.add(blog);
}
}
问题二:数据稀疏问题
从代码中我们很容易可以看出,计算相似度的复杂度较高,是O(n^2)级别,然而当我们仅对数据库中的一小部分进行操作时,就会导致数据变稀疏,这样可能会带来推荐效果、性能的下降。
这个问题是算法本身的缺陷,需要对算法进行改进,或者结合多种算法。
总结
协同过滤算法是较为传统的算法,算法的实现原理较为简单,有着各种各样的问题,但是算法本身的思路是值得借鉴的。目前比较新的算法有搭建深度神经网络进行学习的算法,这种算法的推荐效果较好,但是这种算法仍然需要大量的数据用于训练。我认为基于用户的协同过滤算法其实可以和传统的一些机器学习算法进行结合。比如在相似用户查找那,可以采用聚类算法,推荐的过程可以考虑对数据进行降维处理,仅保留有价值的数据等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号