结对第二次作业
| 这个作业属于哪个课程 | <2021春软件工程实践|S班> |
|---|---|
| 这个作业要求在哪里 | <结对作业二> |
| 结对学号 | <221801230>、<221801334> |
| 这个作业的目标 | 1.GitHub协作 2.结对编程 3.web项目 4.结对作业一原型设计的实现 |
| 其他参考文献 | CSDN、简书、博客园等 |
GitHub仓库链接和代码规范链接
GitHub仓库地址:https://github.com/XydfLi/PairProject
代码规范地址:https://github.com/XydfLi/PairProject/blob/main/221801334%26221801230/codestyle.md
项目访问链接
PaperCV访问链接:http://120.24.27.29:8080/login.html
强烈推荐Chrome浏览器!!由于使用Bootstrap4框架,部分浏览器可能无法加载。
默认登录账号:123456
默认登录密码:123456
设计实现过程
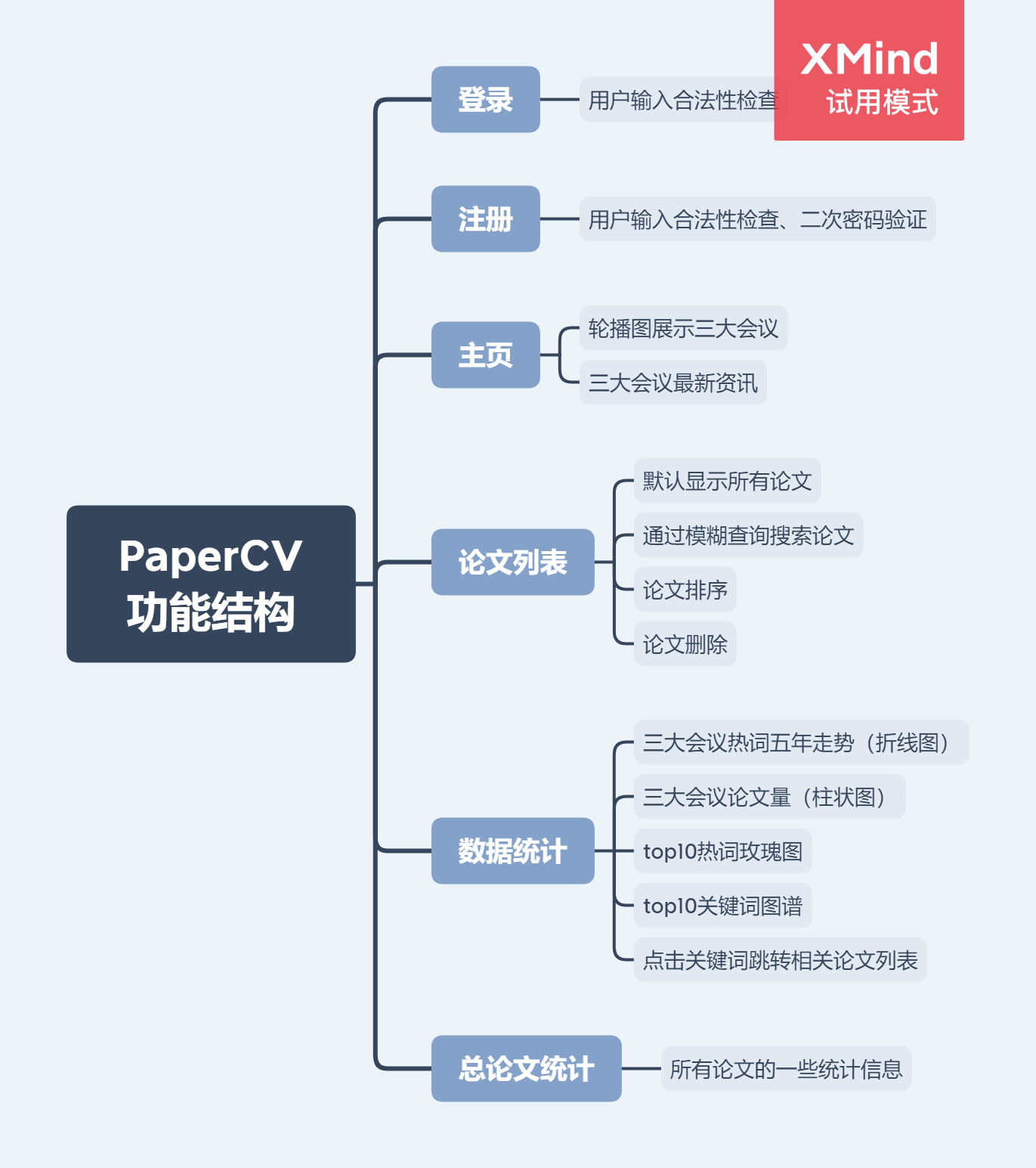
功能结构图
根据结对第二次作业要求的基本功能要求、拓展功能要求,以及结对第一次作业的原型设计,我们设计出的结构功能图如下:
Web设计规划
- 根据功能结构图,我们的程序主要划分为5个页面
- 第一个页面为登录、注册功能。该页面为用户登录的第一个页面,主要是登录、注册功能,包含用户输入的合法性检查。
- 第二个页面为主页。用户登录后跳转到主页,主页主要用于展示三大会议的信息以及三大会议的最新资讯。
- 第三个页面为论文列表。主要功能是对论文列表的操作,包括模糊查询、排序、删除等。
- 第四个页面为数据统计。主要统计热词、关键词、图谱、趋势信息的显示。同时,点击关键词将自动查询相关论文,并跳转显示在论文列表。
- 第五个页面为总论文统计。主要是在所有论文的基础上对论文的数据进行统计。
编码实现规划
- 本次实现主要采用前后端分离开发的模式
- 后端使用springboot+mybaties+SQLite框架,采用MVC架构
- 前端使用bootstrap框架
- 前后端交互使用ajax技术
- 数据库中的密码需要进行MD5加密(加盐)后再存储
代码架构
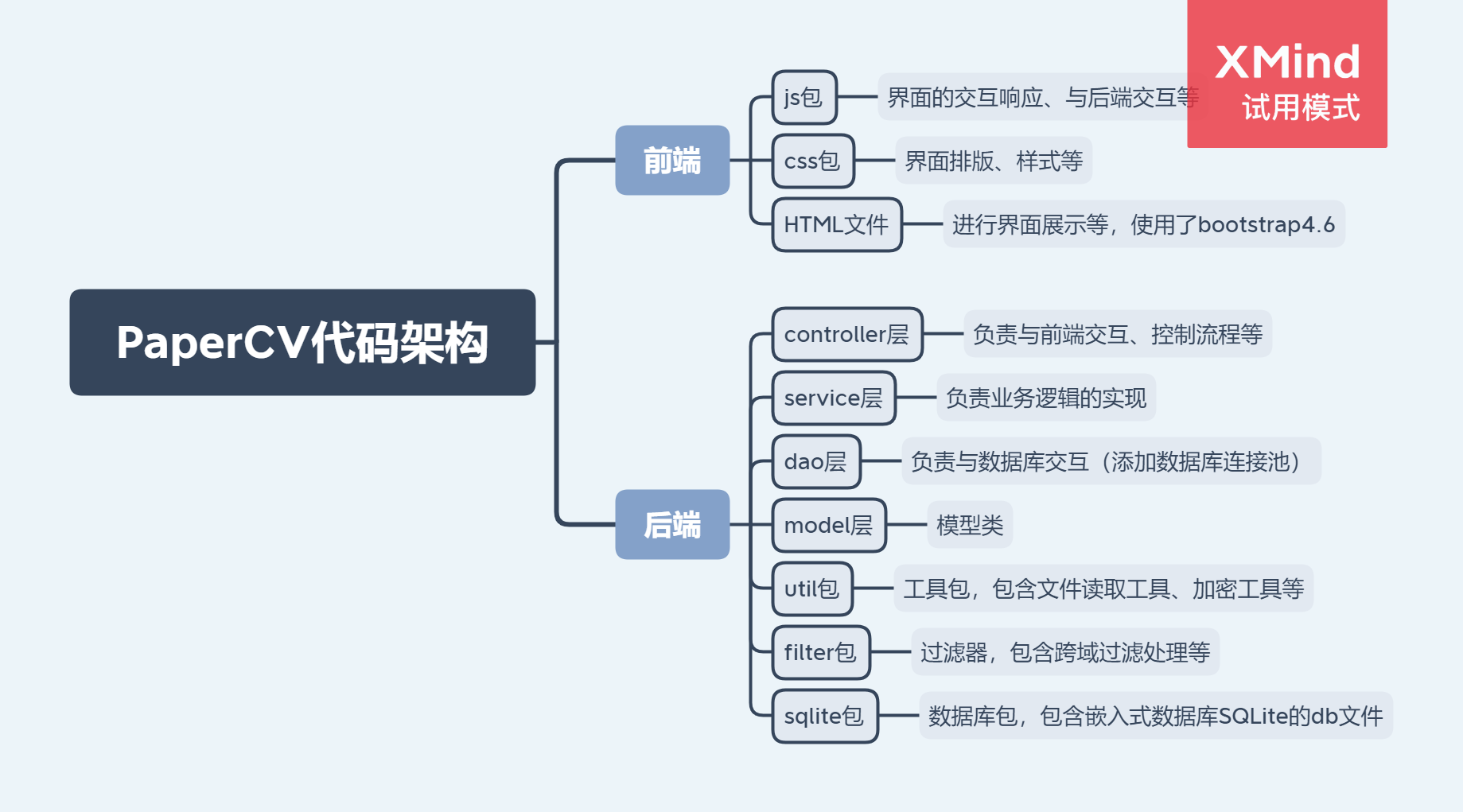
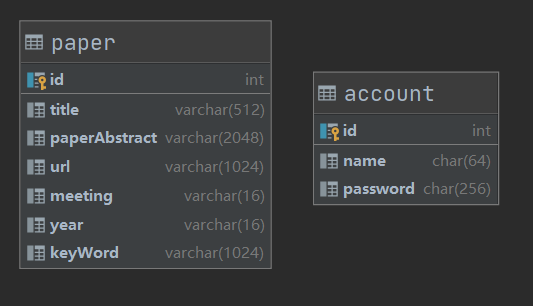
数据库表设计
论文表paper和用户表account
PSP表格
- lxy:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 60 |
| • Estimate | • 估计这个任务需要多少时间 | 45 | 60 |
| Development | 开发 | 1235 | 1200 |
| • Analysis | • 需求分析 (包括学习新技术) | 45 | 60 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 30 | 35 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| • Design | • 具体设计 | 180 | 155 |
| • Coding | • 具体编码 | 700 | 670 |
| • Code Review | • 代码复审 | 100 | 80 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 90 | 120 |
| • Test Report | • 测试报告 | 20 | 30 |
| • Size Measurement | • 计算工作量 | 20 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 50 | 60 |
| 合计 | 1370 | 1380 |
* wwh:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 60 |
| • Estimate | • 估计这个任务需要多少时间 | 45 | 60 |
| Development | 开发 | 2070 | 2190 |
| • Analysis | • 需求分析 (包括学习新技术) | 150 | 210 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 30 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| • Design | • 具体设计 | 150 | 240 |
| • Coding | • 具体编码 | 1440 | 1350 |
| • Code Review | • 代码复审 | 120 | 100 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 120 | 210 |
| • Test Report | • 测试报告 | 50 | 120 |
| • Size Measurement | • 计算工作量 | 20 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 50 | 60 |
| 合计 | 2235 | 2460 |
成品展示
登录
点击右上方登录按钮进入登录界面
对用户的输入包含合法性检查(是否为空等)
登录界面上存在一些娱乐功能,例如播放音乐,跳转到推荐网页等功能

注册
- 点击右上方注册按钮进入注册界面
- 密码设置需要两次填写密码,防止出错
- 包含用户输入的合法性检查(是否为空,邮箱格式等)

主页
- 主页部分主要包含三大会议轮播图和最新资讯两个部分
- 轮播图循环播放三大会议的宣传图,点击图片可以跳转到三大会议的主页

- 轮播图切换效果展示

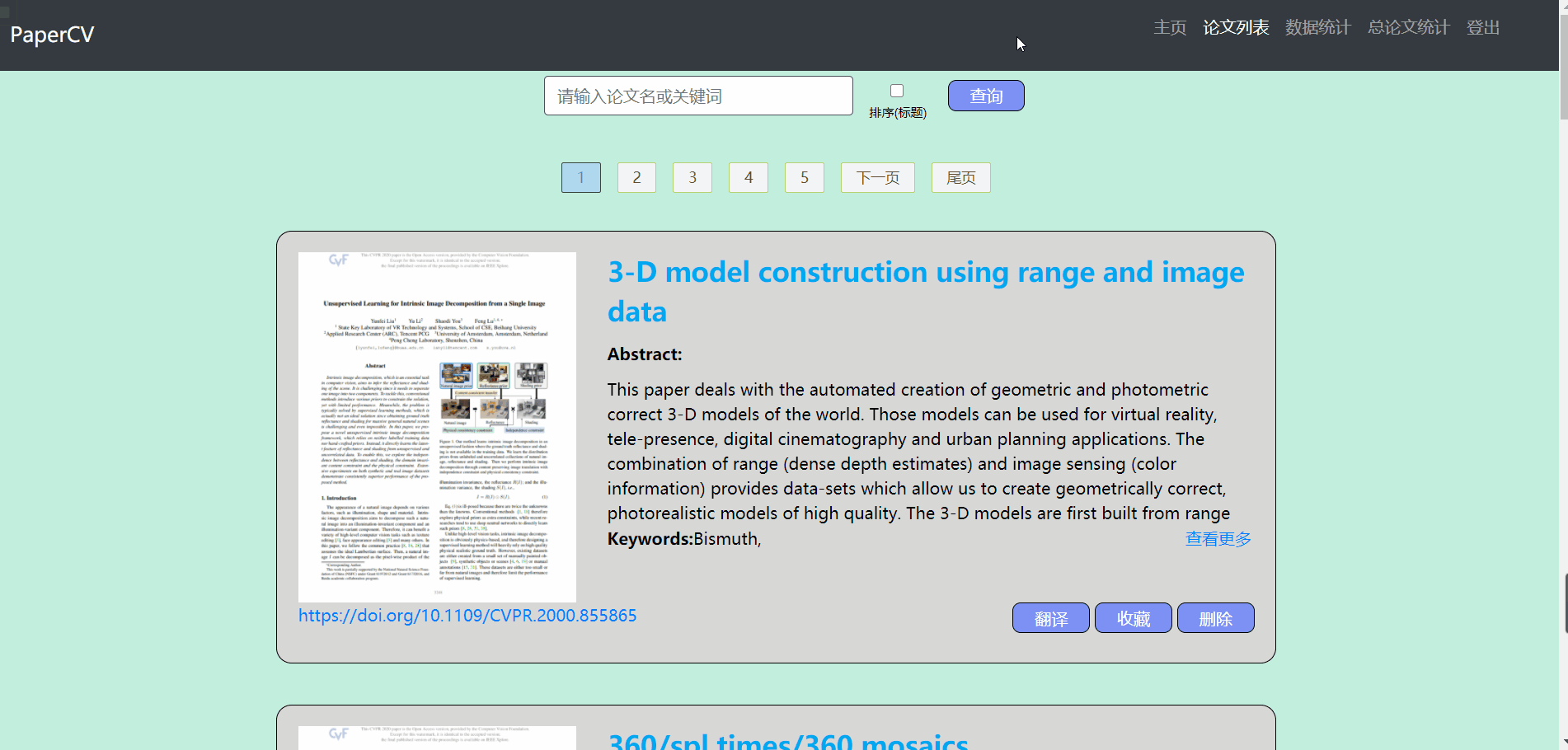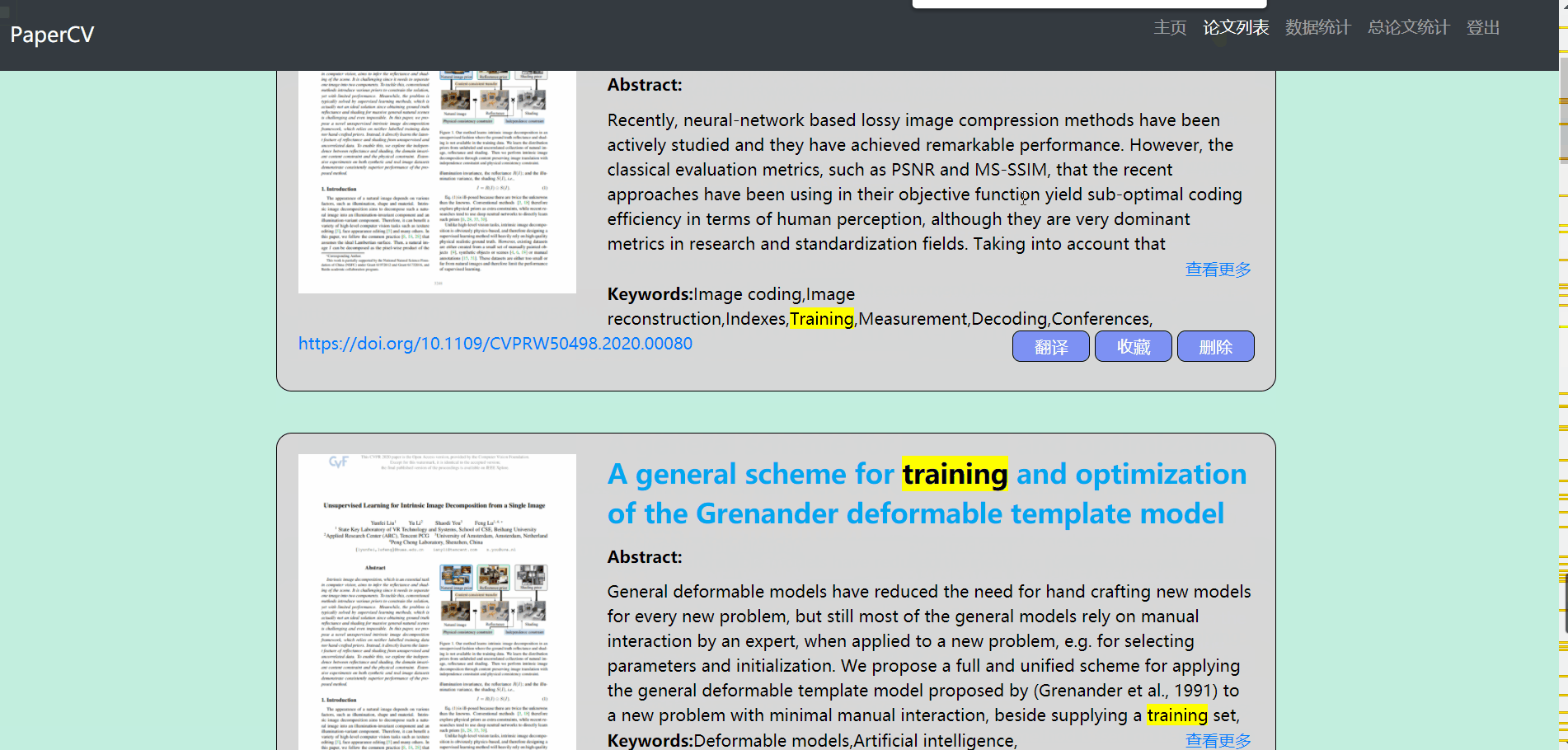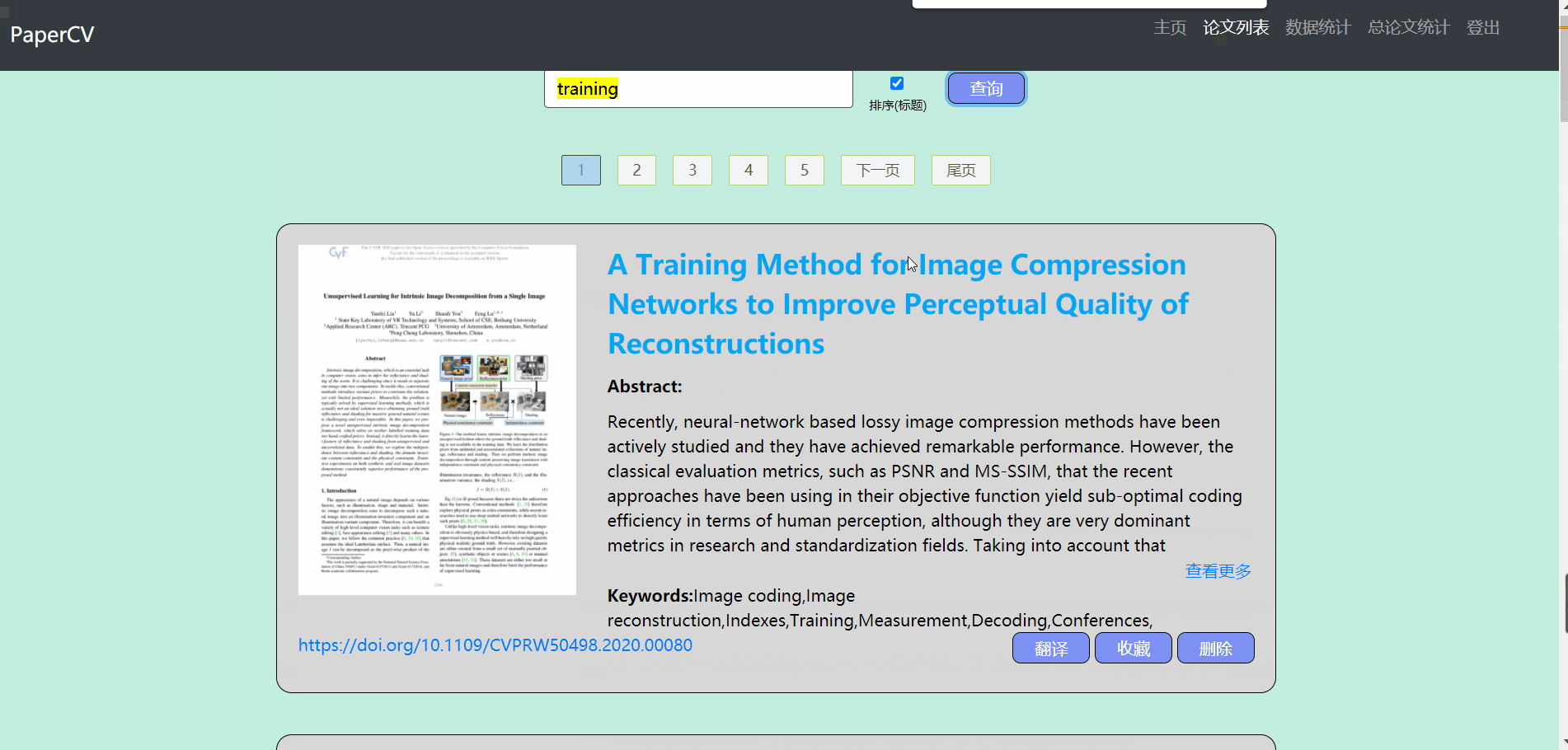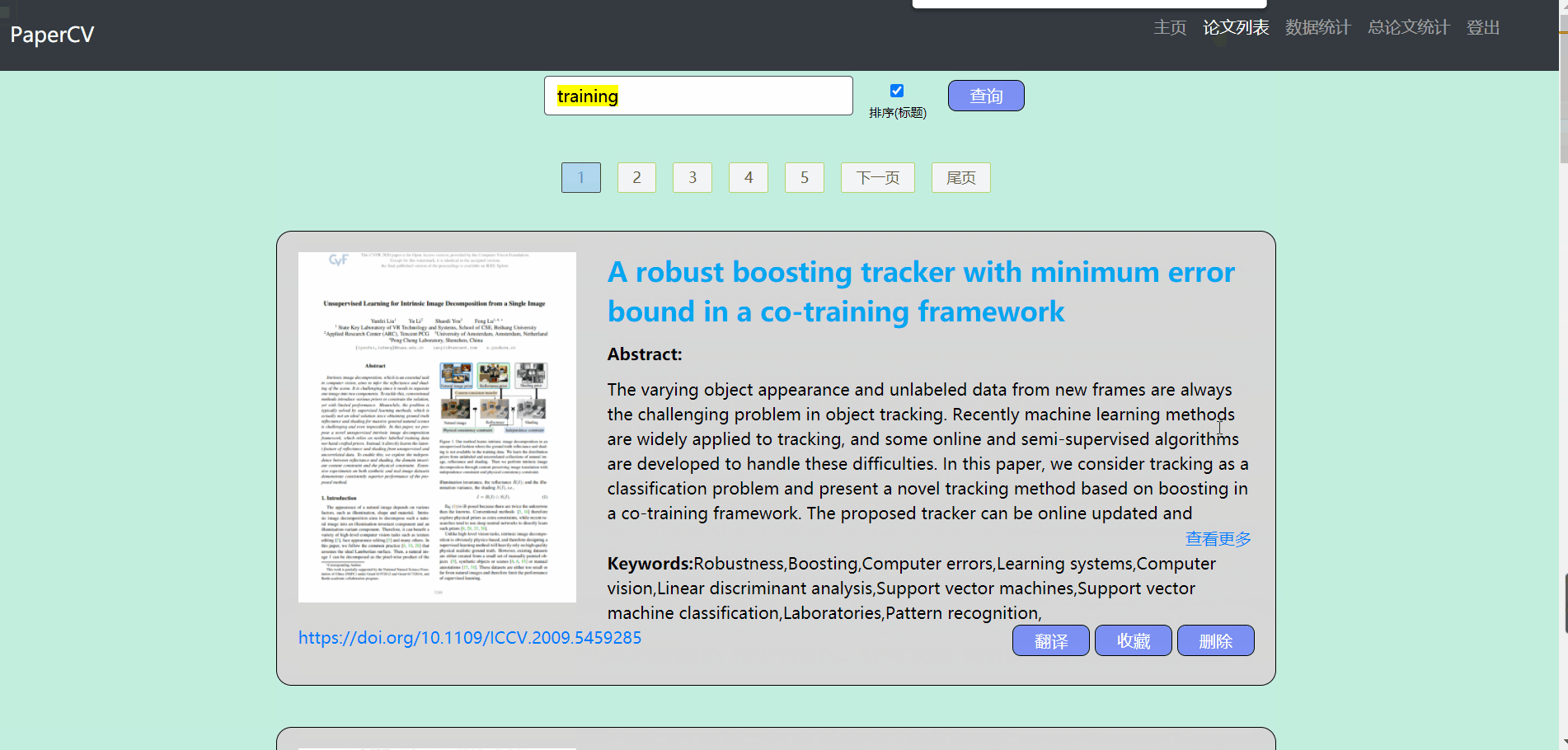
论文列表
- 论文列表主要包含对论文的操作
- 默认显示全部的论文,用户可以输入标题来查询论文(支持模糊查询),在查询的过程中可以选择是否需要排序
- 对显示的列表做了分页处理,每页显示10条数据
- 对于不需要的论文可以点击删除按钮进行删除
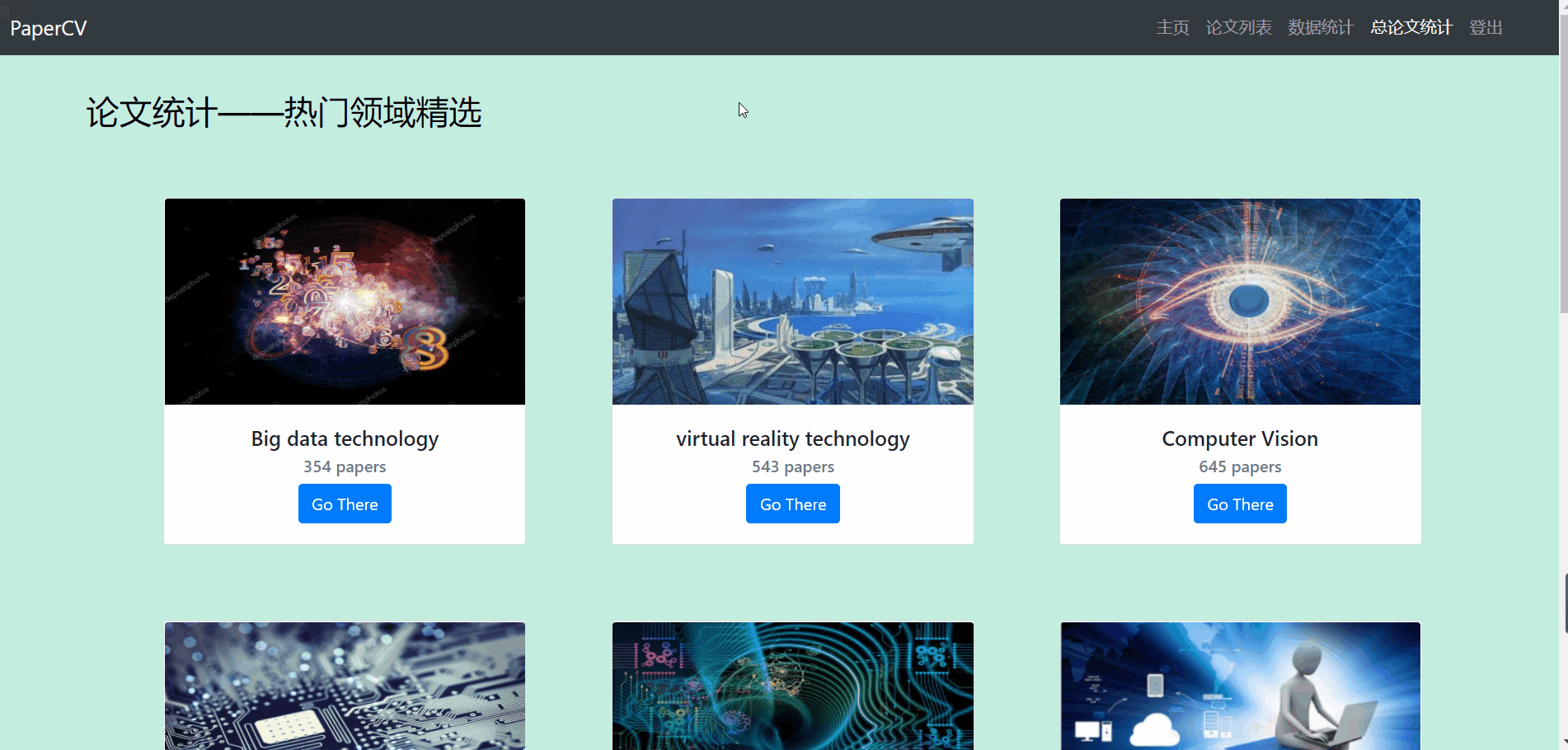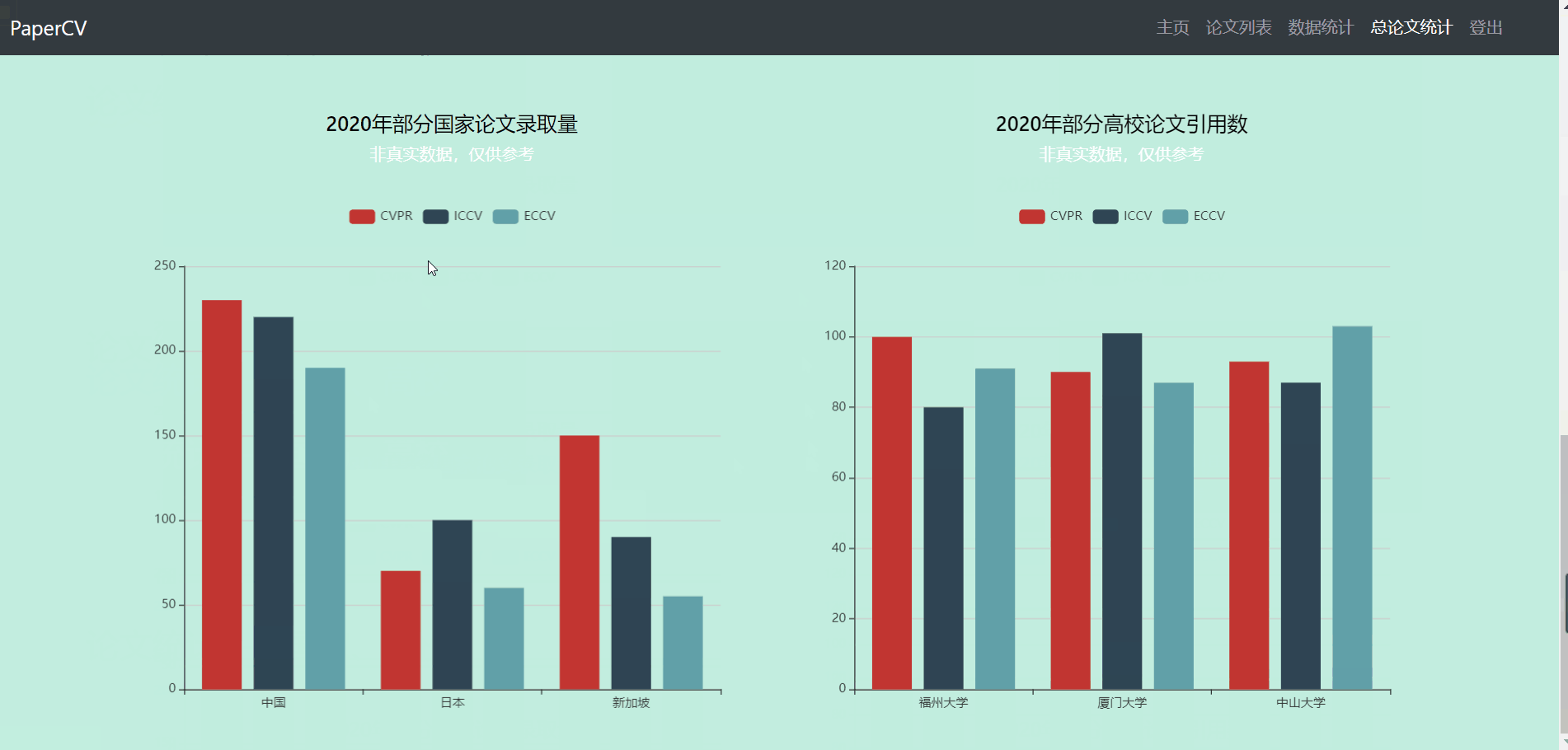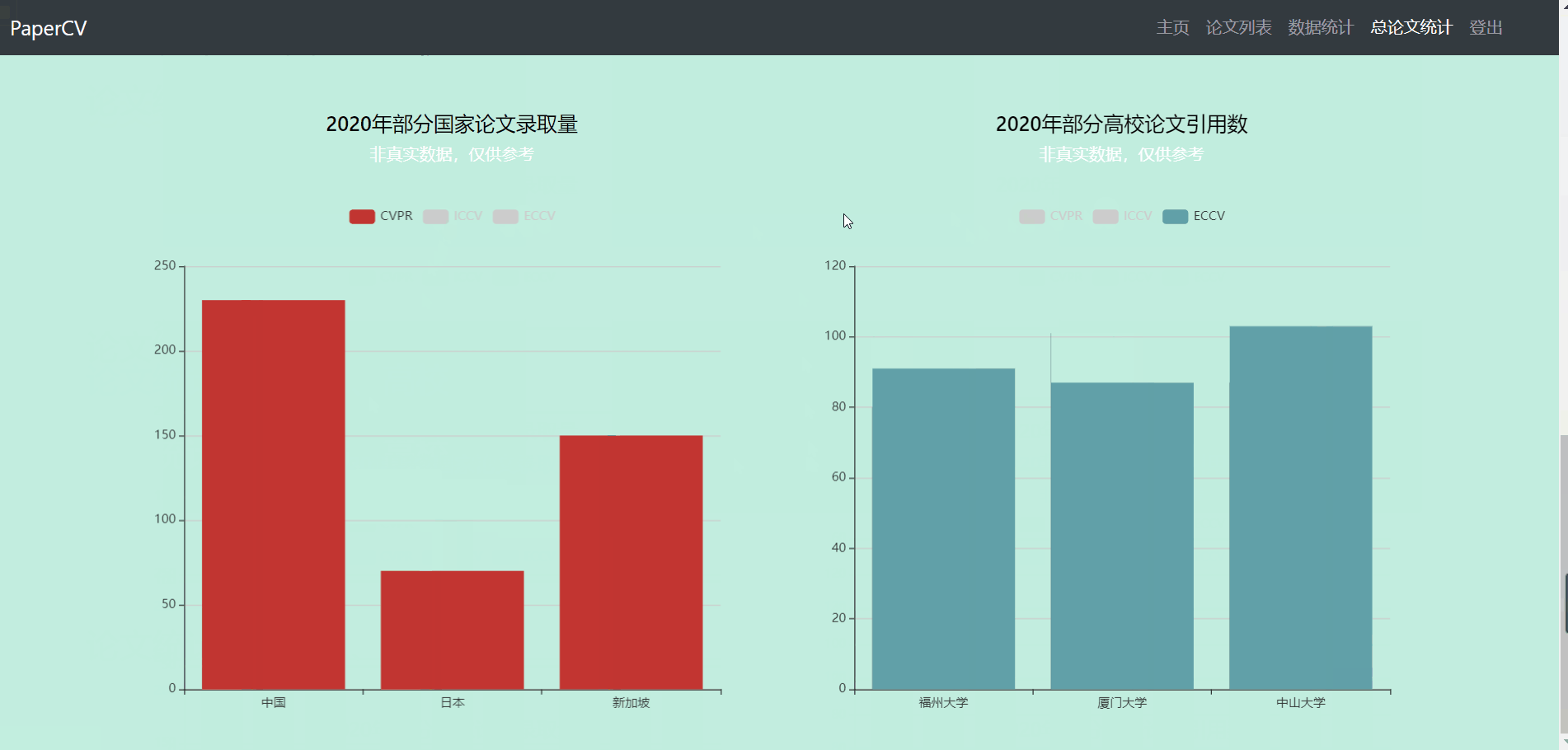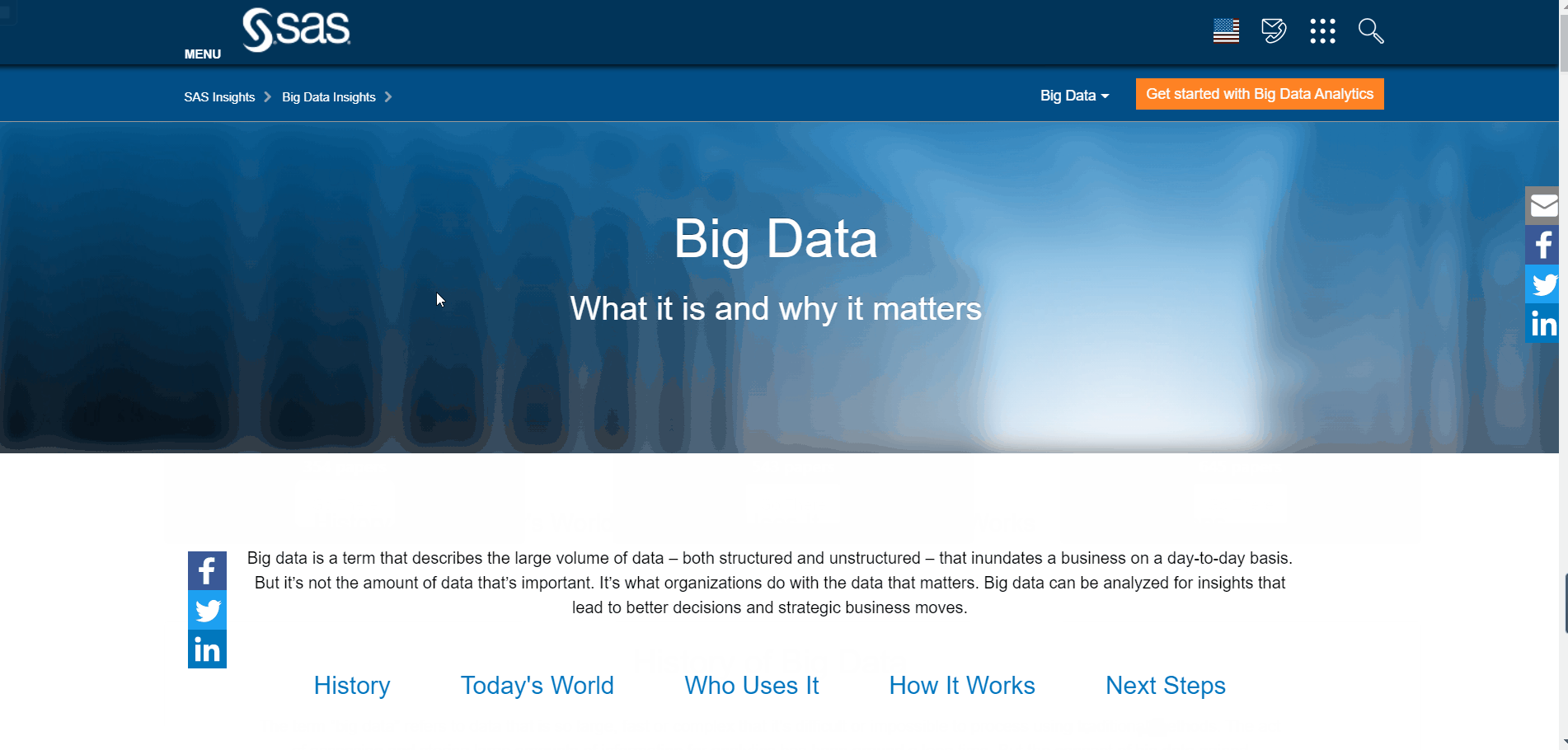
数据统计
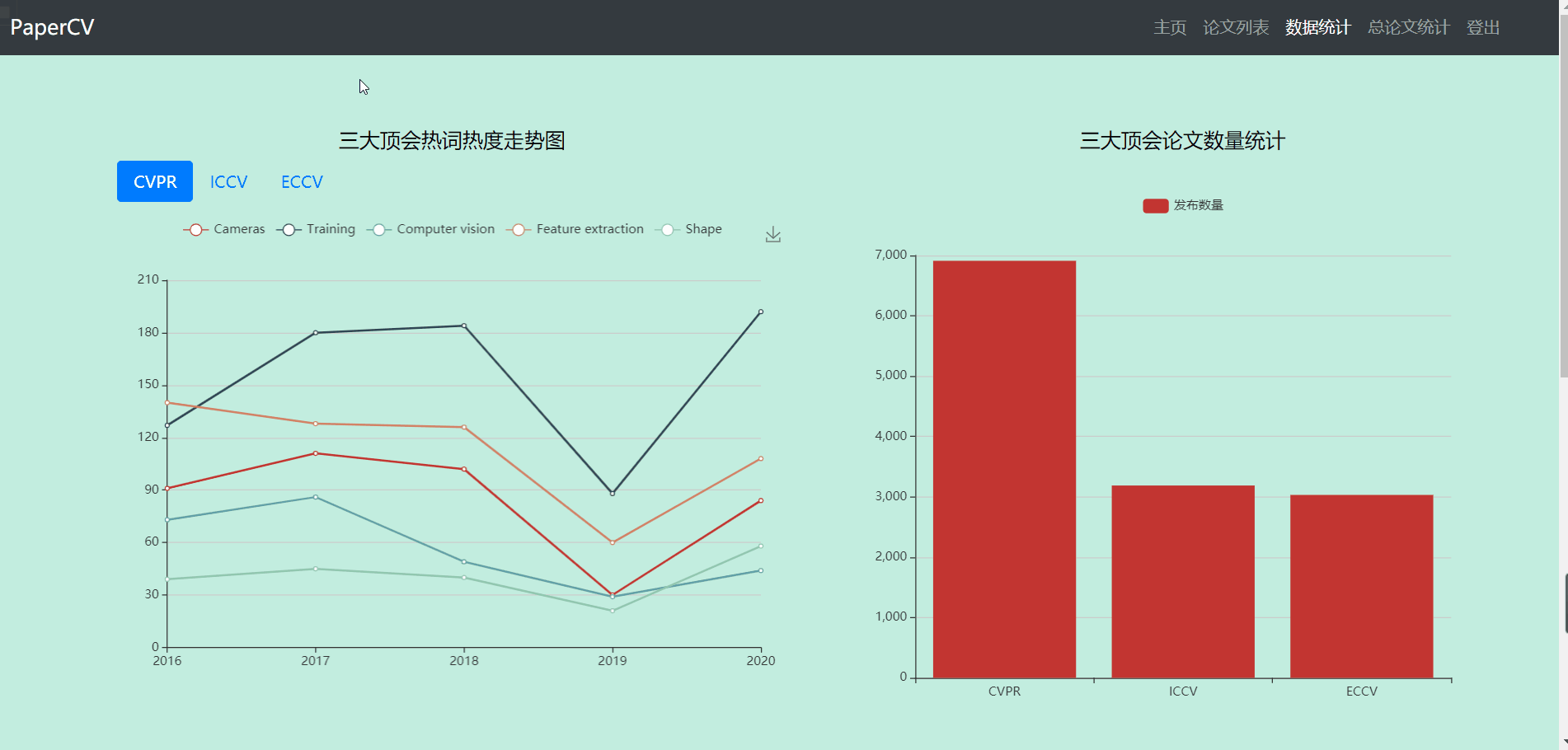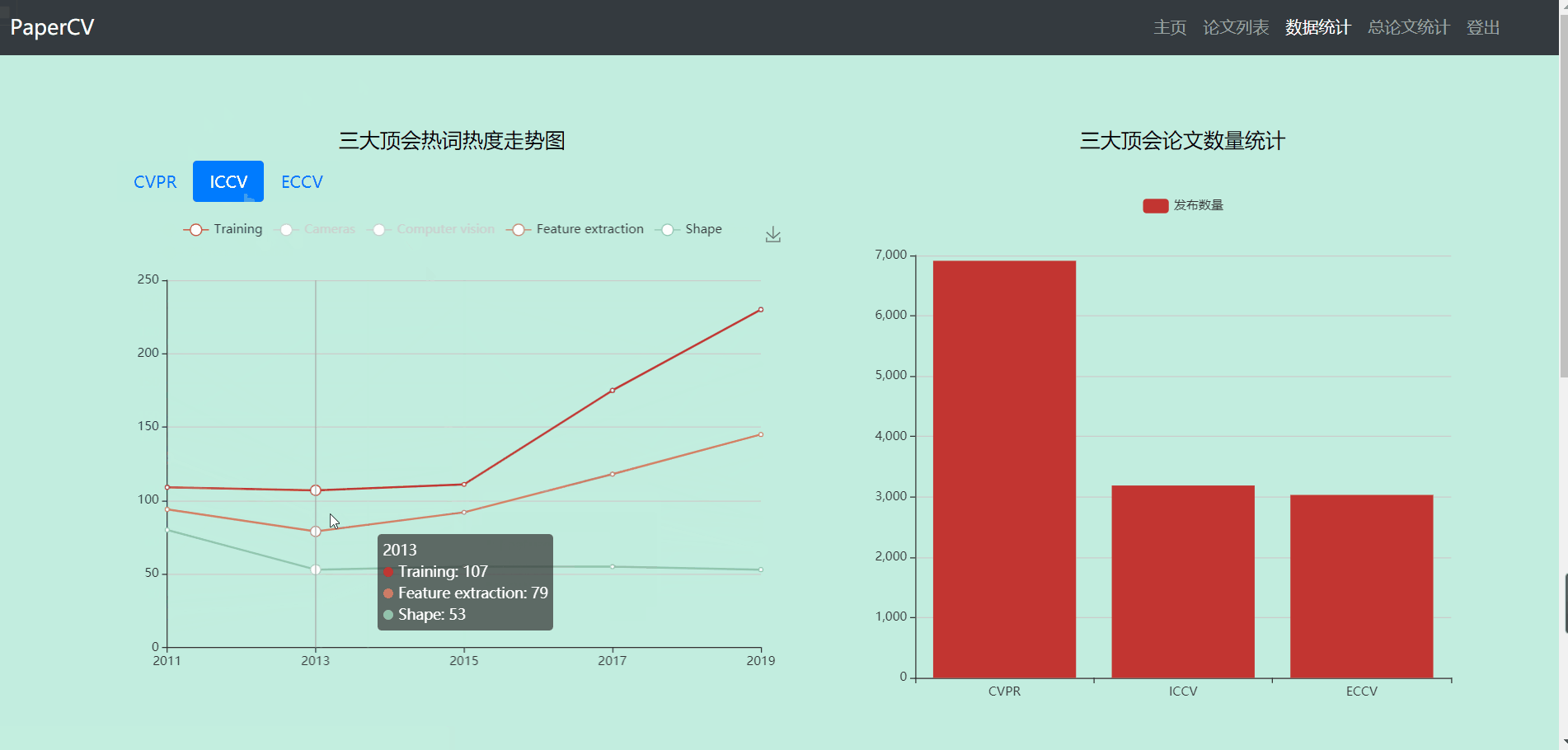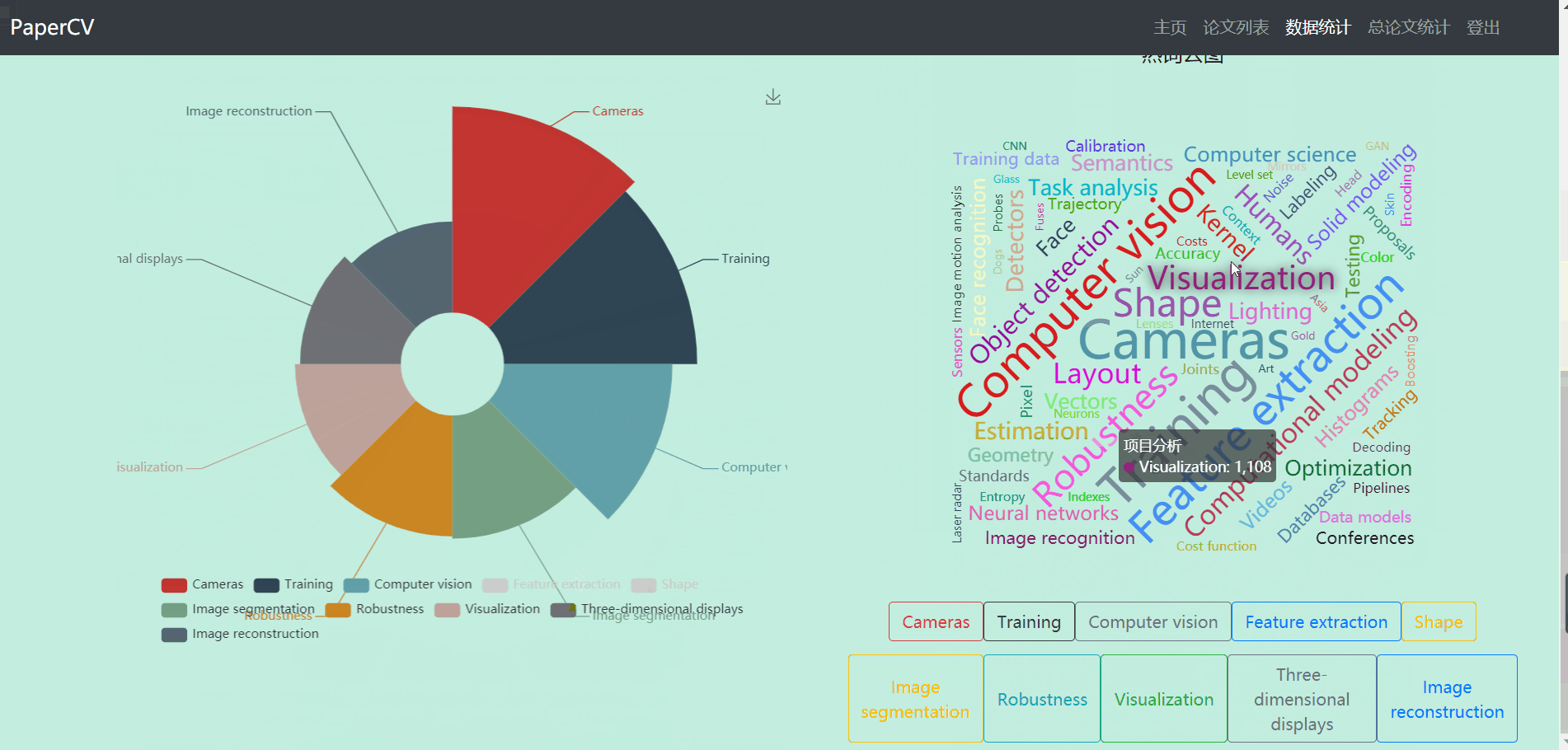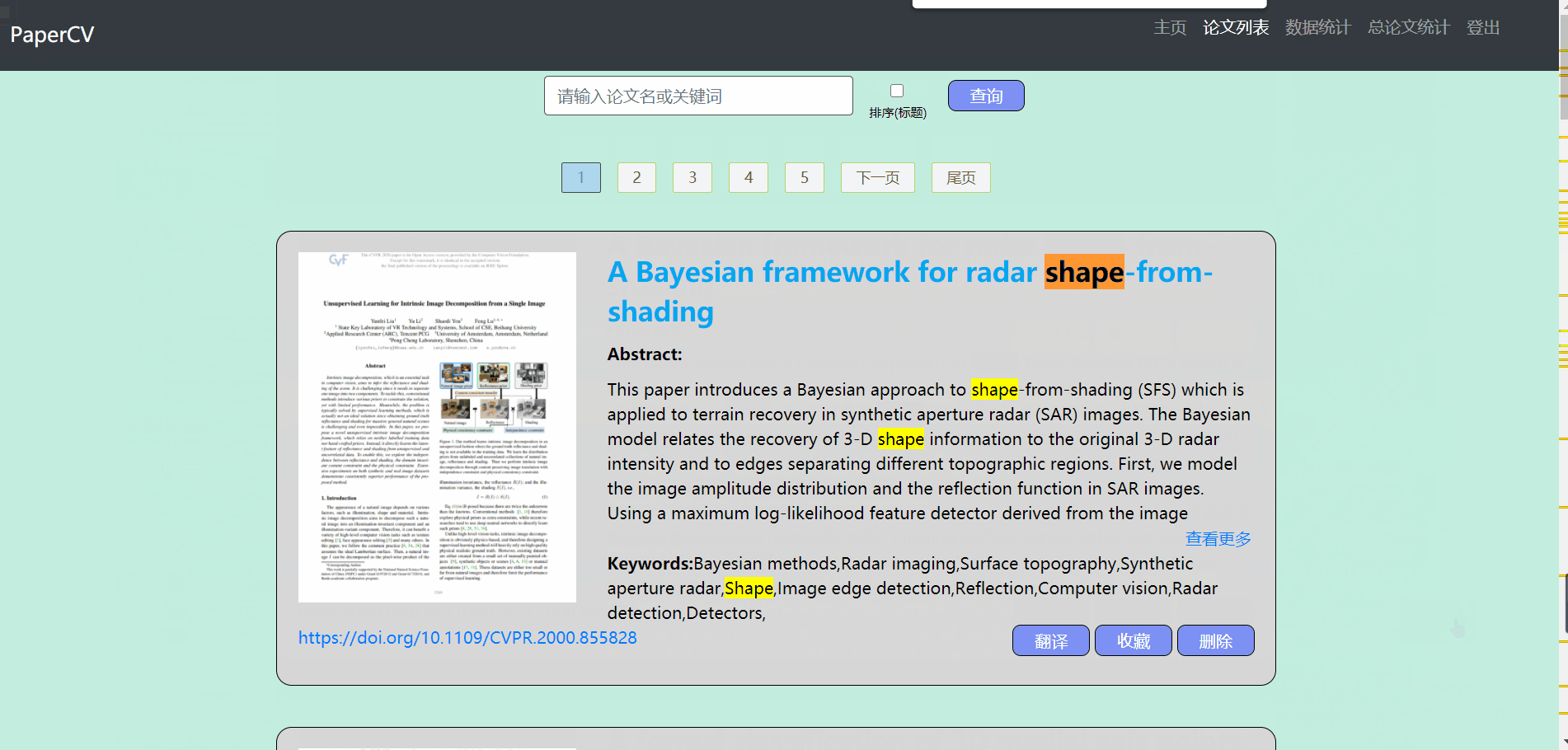
- 数据统计部分主要包含4个图
- 第一个图显示的是三大会议热词近几年的走势变化图(可切换会议)
- 第二个图显示的是三大会议的总论文数量
- 第三个图显示的是三大会议top10关键词的论文数
- 第四个图谱显示的是三大会议top500关键词的云图
- 点击第四个图谱下方的10个关键词可以跳转到论文列表界面,显示对应关键词的论文列表
总论文统计
- 总论文统计界面主要分为热门领域、各高校论文统计两个部分。因为缺乏数据,该部分使用的是测试数据。
- 第一部分显示了热门领域的图片、论文量等信息,点击可跳转。
- 第二部分显示了部分高校或部分国家的论文量等信息(非真实数据)。
代码说明
代码的总体架构和实现技术请点击这里查看。
前端部分
前端采用HTML+CSS+JavaScript编写,并利用了一些bootstrap含有的组件
部分页面代码
通用头部导航栏
<nav class="navbar navbar-expand-md navbar-dark bg-dark mb-4 fixed-top">
<a class="navbar-brand" href="home.html">PaperCV</a>
<div class="collapse navbar-collapse" id="navbarCollapse">
<ul class="navbar-nav ml-auto">
<li class="nav-item active"><a class="nav-link" href="home.html">主页</a></li>
<li class="nav-item"> <a class="nav-link" href="paper-list.html">论文列表</a> </li>
<li class="nav-item"> <a class="nav-link" href="data-statistics.html">数据统计</a> </li>
<li class="nav-item"> <a class="nav-link" href="paper-statistics.html">总论文统计</a></li>
<li class="nav-item"> <a class="nav-link" href="login.html">登出 </a></li>
</ul>
</div>
</nav>
对于图表部分,引用echarts图表,从后端获取数据,用ajax技术展示在图表上,以下只展示一段代码
option = {
title: {
text: ''
},
tooltip: {
trigger: 'axis'
},
legend: {
data: iccvValues
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
toolbox: {
feature: {
saveAsImage: {}
}
},
xAxis: {
type: 'category',
boundaryGap: false,
data: iccvYears
},
yAxis: {
type: 'value'
},
series: [
{
name: iccvValues[0],
type: 'line',
stack: 'num1',
data: iccvCounts[0]
},
{
name: iccvValues[1],
type: 'line',
stack: 'num2',
data: iccvCounts[1]
},
{
name: iccvValues[2],
type: 'line',
stack: 'num3',
data: iccvCounts[2]
},
{
name: iccvValues[3],
type: 'line',
stack: 'num4',
data: iccvCounts[3]
},
{
name: iccvValues[4],
type: 'line',
stack: 'num5',
data: iccvCounts[4]
},
]
};
echartBar = echarts.init(document.getElementById("pills-profile"));
echartBar.setOption(option);
分页显示使用jQuery的pagination插件,加快加载速度
function showOne(URL, nowPage, back) {
selectOne(URL + "/" + nowPage + back);// 获取数据
// 添加分页
$("#item-list").pagination({
currentPage: nowPage,
totalPage: Math.ceil(totalCount/PAGE_COUNT),
isShow:true,
count:5,// 显示个数
homePageText:'首页',
endPageText:'尾页',
prevPageText:'上一页',
nextPageText:'下一页',
callback: function (index) {// 回调函数
showOne(URL, index, back);
}
});
// 使用jQuery动态添加论文
for (var i = 0;i < items.length;i++) {
var new_item = "<div>
...
</div>"
$("#item-list").append(new_item);
}
// 为每一个论文注册删除监听事件
$(".delete-item").click(function () {
var id = $(this).attr("name")
$("#"+id).remove();
});
}
前后端交互代码
前后端交互主要使用jQuery框架中的ajax技术,下面展示登录的交互
$.ajax({
url:httpRoot + "/account/login",
type:"POST",
cache:false,
data:JSON.stringify(account),
async:false,
contentType:"application/json",
success:function(result){
if(result == "登录成功"){
window.location.href = "home.html";
} else {
alert(result);
}
}
});
后端部分
这里主要展示业务逻辑,以及跨域、加密等功能的关键代码
跨域部分
这一部分主要是为了解决前后端跨域的问题。主要是通过实现springboot的过滤器接口来实现的,在过滤器中设置允许请求头、请求方法、请求域名等。
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain)
throws IOException, ServletException {
HttpServletResponse response = (HttpServletResponse) servletResponse;
HttpServletRequest request = (HttpServletRequest) servletRequest;
response.addHeader("Access-Control-Allow-Origin", request.getHeader("origin"));
response.setHeader("Access-Control-Allow-Headers", "x-requested-with,Cache-Control,Pragma," +
"Content-Type,Token, Content-Type");
response.setHeader("Access-Control-Allow-Methods", "POST, GET, OPTIONS, DELETE");
response.setHeader("Access-Control-Max-Age", "3600");
response.setHeader("Access-Control-Allow-Credentials", "true");
String method = request.getMethod();
if (method.equalsIgnoreCase("OPTIONS")) {
servletResponse.getOutputStream().write("Success".getBytes("utf-8"));
} else {
filterChain.doFilter(servletRequest, servletResponse);
}
}
MD5加密实现
MD5加密主要是为了实现数据库密码加密后存储的功能,防止密码明文存储。
加盐的规则为:将密码反转->将所有a替换为#->将密码字符串复制连接
public static String md5Password(String password) {
try {
// 加盐
password = new StringBuilder(password).reverse().toString().replace('a', '#');
password = password + password;
// 得到一个信息摘要器
MessageDigest digest=MessageDigest.getInstance("md5");
byte[] result=digest.digest(password.getBytes());
StringBuilder buffer=new StringBuilder();
// 把每一个byte 做一个与运算 0xff;
for (byte b:result) {
// 与运算
int number=b&0xff;
String str=Integer.toHexString(number);
if (str.length()==1) {
buffer.append("0");
}
buffer.append(str);
}
// 标准的md5加密后的结果
return buffer.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
获取top500关键词
算法为遍历所有论文,获取
public List<Map.Entry<String, Integer>> getTop500() {
List<Paper> papers = paperMapper.selectAll();
Map<String, Integer> wordMap = new HashMap<>();
// 存储关键词个数
for (Paper paper : papers){
for (String word : paper.getKeyWord().split(",")){
if (word.length() < 3) {// 过滤长度小于3的关键词
continue;
}
if (wordMap.containsKey(word)){
wordMap.put(word, wordMap.get(word) + 1);
} else {
wordMap.put(word, 1);
}
}
}
List<Map.Entry<String, Integer>> words = new ArrayList<>(wordMap.entrySet());
words.sort((o1, o2) -> o2.getValue() - o1.getValue());
return words.subList(0, 500);
}
获取某个会议top5关键词的个数在近5年的趋势变化
算法分为两个部分,第一个部分获取top5关键词,第二个部分计算每年每个关键词的个数。
public List<Word> getTrendWord(String meeting, List<String> years) {
// 获取该会议热词的排序
List<Paper> papers = paperMapper.selectByMeeting(meeting);
Map<String, Integer> wordMap = new HashMap<>();
for (Paper paper : papers){
for (String word : paper.getKeyWord().split(",")){
if (word.length() < 3) {
continue;
}
if (wordMap.containsKey(word)){
wordMap.put(word, wordMap.get(word) + 1);
} else {
wordMap.put(word, 1);
}
}
}
List<Map.Entry<String, Integer>> words = new ArrayList<>(wordMap.entrySet());
words.sort((o1, o2) -> o2.getValue() - o1.getValue());
Map<String, Integer> hotWord = new HashMap<>();
for (Paper paper : papers) { // 遍历所有论文
for (String year : years) { // 遍历所有年限
if (year.equals(paper.getYear())) {// 年份匹配
for (String key : paper.getKeyWord().split(",")) {
for (int i = 0;i < 5;i++){
if (words.get(i).getKey().equals(key)) {// 关键词匹配
// 个数+1
String keyMap = year + "_" + key;
if (hotWord.containsKey(keyMap)) {
hotWord.put(keyMap, hotWord.get(keyMap) + 1);
} else {
hotWord.put(keyMap, 1);
}
}
}
}
break;
}
}
}
// 初始化结果列表
List<Word> res = new ArrayList<>(8);
for (int i = 0;i < 5;i++){
res.add(new Word(words.get(i).getKey(), years, new ArrayList<>()));
}
// 填入每个年份每个关键词的个数
for (String year : years) {
for (int j = 0; j < 5; j++) {
String keyMap = year + "_" + words.get(j).getKey();
res.get(j).getCounts().add(hotWord.getOrDefault(keyMap, 0));
}
}
return res;
}
结对讨论过程描述
结对模式描述
在结对编程一种我们已经形成了一种默契,每一次的协作都按照一定的模式进行,这次的结对编程二也沿用了,并在结对编程一的基础上做了一些改进。具体模式如下:
- 每天进行一次线下讨论。这次的作业我们已经返校了,所以我们之间的合作尽可能面对面进行,可以极大提升效率,且每天的线下讨论也是对我们完成每天任务的一种催促。
- 每天讨论的第一部分是分别对自己今天做的任务的说明。主要是互相说明今天所做的工作,以及互相讨论在工作中遇到的一些问题,作为听的一方需要提出自己的一些建议。
- 每天讨论的第二部分是对第二天工作的安排。大体的工作安排会在第一天安排好,之后每天都需要说明第二天的安排,针对具体的情况进行具体的安排。安排内容合理,编程内容上尽量减少代码的冲突,根据两个人第二天课程的多少来安排任务。
- 任务的安排优先级为:基本功能>拓展功能>原型设计的需求
- 对我们都不懂的知识,我们分工学习,然后讨论的时候互相给对方讲解。
- 熟练使用github上的各种工具,例如issue,release等
主体分工
此次作业采用前后端分离开发的模式,我们两人一人负责后端,一人负责前端。
部分讨论照片分享
1、第一次在玫瑰园讨论,主要内容是分析题目、环境搭建以及主体任务安排。

2、这一次是在宿舍,我们在讨论如何解决bug。

3、有一部分讨论是在QQ上进行,及时讨论遇到的问题
心路历程和收获
lxy:
在这次作业实现过程中,我们主要碰到的问题:第一个是如何在保证实现作业基本功能、拓展功能的基础上,尽可能实现原型设计中的功能。第二个是如何快速高效的学习新的技术知识,完成此次作业。
解决问题:关于第一个功能实现的问题,我们主要是先分析实现每一个功能所需要的技术、学习的时间成本等。最后我们决定优先实现结对作业二要求的基本功能和拓展功能,对于原型设计中的其他功能放在最后。这样帮助我们抓住作业的重点,更好地完成任务。关于第二个学习的问题,我们两人都有一定的前端、后端技术基础,我们主要的安排是谁擅长哪部分就谁负责哪部分,对于我们都不懂的部分,我们分工每个人学习一块,再互相教学。
收获:能够熟练地根据需求、人员等安排任务。能够熟练解决开发过程中碰到的各种突发情况和技术难点。

wwh:
结队作业二的任务是基本实现结队作业一原型设计中的功能。由于之前的实战经验比较少,刚碰到作业时心里还是会有点紧张。完成作业的模式就是边编写代码编跟进学习,对于遗忘或者不懂的知识及时查询文档资料。在刚开始写界面的时候,怎么也写不好,后来又加深了一些界面美化上的知识,代码写起来也更得心应手。而且这次作业也与我在寒假作业一中定的学习目标相契合,在写作业的过程中也推动了我的学习进程。
结队作业的过程首先是使我对于git和github的应用更加熟练了,对于新加入功能或者修复bug都及时提交进度。再就是对于结队编程有了更深刻的理解,两个人共同完成项目能看到更多的角度,彼此的监督也有利于提高编程效率。对于我不懂的问题,而有时队友已经接触过了,解决问题也更加迅捷。结队编程确实让我提高了对已学技术的运用,也锻炼了我的学习能力。

评价结对队友
lxy:
队友nb!队友在开发过程中可以很好地完成我们共同制定的任务安排,不拖欠真是太棒了。而且wh同学在开发中对功能的细节要求高,比如界面自适应的问题、用户按回车进行登录、搜索等功能都是wh提出的。希望我们今后都能够顺利完成软工实践!
wwh:
第二次结对作业的合作依旧十分愉快,我的队友xy非常厉害,对于交互方面的知识格外丰富,常常会出现一些独特的想法,让项目功能更丰富。xy十分自律,对于布置的任务他总会超前完成,这也使项目的推动十分顺利。期待之后能有更多的合作,也愿我们之后能顺利完成软工实践。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号