软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 阅读《构建之法》、熟练使用GitHub等工具、独立完成WordCount项目(包含词频统计等需求) |
| 作业正文 | 作业正文 |
| 其他参考文献 | CSDN、简书、博客园等 |
GitHub链接:https://github.com/XydfLi
项目链接:https://github.com/XydfLi/PersonalProject-Java
作业描述:作业主要包含两个部分,一个是阅读《构建之法》并提问、一个是熟悉GitHub并完成WordCount项目。
part1:阅读《构建之法》并提问
问题1
25-26页,关于单元测试的部分,文中有提到好几个单元测试的标准,标准大多注重的是测试代码的正确性等等,其中还有一个标准又说到单元测试要快。对于这一部分我有一个疑问是:我们是否应该在单元测试中测试代码是否达到了性能上的要求(尤其是时间性能)。
提出这个问题的原因是,我在实际的开发过程中,使用过一些单元测试的工具,他们大多都具有测试程序时间性能是否达标的功能,而我们实际开发过程中有时候也必须关注程序的性能是否达标,我使用的方法是在单元测试中来测试性能,比如可以在测试函数中设置该函数的超时时间,如果超时则测试失败,这一点似乎和单元测试要快的标准有一些矛盾?
我个人的观点是,一些单元测试不一定要快,应该在单元测试中测试程序的性能。比如我可以在一些测试函数中测试性能,如果发现某部分程序性能不达标,这时候再使用性能分析工具,具体分析该部分程序该如何优化。我这里强调的是开发人员对程序的测试,不是测试人员对程序的测试,毕竟开发者也是要保证性能达标了再交给测试者测试。
问题2
关于测试的部分,我一直都有一个疑问,我们测试的时候应不应该使用真实的用户数据(不敏感数据)来进行测试?
这一点在文中没有提到,使用真实的用户数据可以使得我们的程序更加贴近真实的运行环境,而且可以极大地减小我们花费在测试上的精力。比如我们写了一个统计人口各种信息的程序,测试的时候我们需要创建一些“不存在的人口数据”,这些数据极多,包含了住址、电话、姓名、政治状况等等信息,可能我们当当创建测试用的数据就要花费时间,更别提测试数据的质量如何。如果我们使用了真实数据,不能说我们不需要创建测试数据,但是我们可以只创建一些真实数据覆盖不到的地方,只创建一些边界数据等等。
但是如果我们使用了真实的数据,测试中出现bug,那么在debug的过程中就必需要查看这个真实的数据,这样的话就容易造成用户数据的泄露,而且这哪怕不是敏感数据,似乎也会侵犯用户的隐私。
市面上有很多的测试数据生成工具,比如datafaker,不过它的原理似乎也不是根据真实数据来构造数据的。
问题3
74页,文中第4章代码风格规范中提到一个观点:注释应该只用ascii字符,不要使用中文或其他特殊字符。
这一个观点我不认同,注释都使用英文等有可能反而会增加程序员理解的成本。我认为应该要根据具体情况来定。
例如我们写的某一部分代码开发者都是中国人,而且这一部分代码是公司内部程序的主要逻辑代码,不能对外公开,那么使用中文注释会极大地降低理解成本,毕竟对于大多数中国人来说,肯定是对母语汉语的理解成本更小,日常的交流也使用中文交流。如果对英文不熟悉的人,很有可能会对某些注释产生误解,增加理解成本。
而如果我们维护的是一个开源代码库,参与开源的开发者来自世界各个国家,我们代码的读者和使用者也来自世界各国,那么使用英文注释是最佳选择。
我不知道现在主流开发者是否有使用英文注释的一些规约,这里引用一下阿里巴巴《java开发手册》2020嵩山版中的观点:24页第6点:【推荐】与其“半吊子”英文来注释,不如用中文注释把问题说清楚。专有名词与关键字保持英文原文即可。
问题4
关于第4章的结对编程部分,首先谈一谈我的理解,我认为这种方式处在单人编程和团队编程的中间地带,其兼具了两者的一些优点,同时也多了一些缺点。优点很明显,因为人数少,沟通成本较低,不需要考虑团队编程中沟通的问题(关于这一点文中也做了详细的说明)。而人数少不代表效率低,相较于单人编程,结对编程可以分工合作,产生1+1>2的效果。
我的问题来自于文中的观点:结对编程是一个渐进的过程,一开始可能不比单独编程效率高,但是度过学习阶段后会有明显改善。那么我可以认为结对编程的一个关键是如何快速地度过有效阶段?
关于这个问题文中也说了很多技巧(4.6节),但是这些技巧都是注重花费时间来培养两个人的默契,帮助更好地合作的。这就带来了结对编程的一个缺点:找到一个适合自己的伙伴不容易,相互之间培养默契度过学习阶段也需要时间,在这之前,可能效率不如单人分开编程。人数少的一个缺点是如果有人中途离开,那么很难在短时间内找到一个合适的替代者,毕竟他可能承担了50%的任务!
我想知道有没有一些较为有效的方法能够快速度过学习阶段?如果结对的伙伴中途离开,或者中途换人,有没有有效的解决方法?现在的编程很难有两个人一直长期合作,培养默契需要时间,经常变换不利影响大,换人带来的后果比团队编程严重得多,我想知道现在开发者结对编程的多吗?
问题5
关于第9章项目经理的部分,提到微软PM负责开发和测试之外的所有事情,其中包括了产品市场定位、优化方向、和各方面沟通等等职责。关于这一部分,我有一个很大的疑问是他们是否也是一个多人组成的团体?他们是否也应该要有一个精细的分工?
在我的认知中,产品定位、市场发展的重要性远远高于软件的开发和测试,毕竟一个不符合主流、不符合需求的软件项目是不会被市场接受的,一旦因为产品定位的问题导致整个团队多个月的成果白费,责任在谁?
在一个10人以下的小团队中,PM负责了客户、开发者之间的沟通交流,还负责了项目开发流程的管理,总之是开发和测试之外的所有事情,如果因为某些原因,该PM中途离开,那么可能直接导致这个项目失败,毕竟PM可能就他一个人!相较而言,开发者的离开可以很快地找到下一位替代者,或者由其他开发者代劳,而PM的离开,导致短时间内开发者需要直面客户,可能之前所有沟通的成果都没有了,新来的PM并不能短时间内接上上一位PM的工作,而且新来的PM可能要更改工期的安排,又会打乱各方面的工作进度。
我想知道,有没有比较好的办法可以降低更换PM所带来的坏处?比如更换了一个开发者,新的开发者只需要看懂需求文档等各种文档就能很好地上手工作,而更换了PM,可能会出现更严重的后果,比如新的PM可能认为之前做的工作不符合市场定位,要重做等等情况。
附加题:Lenna图的故事

我在进行图像处理的时候经常会看到以上这张图,可以说这张图在计算机视觉领域算是鼎鼎大名了。
这张图是刊于1972年11月号《Playboy》杂志上的一张裸体插图照片的一部分。为什么这么多人喜欢在图像处理中使用这张图片呢?首先,该图片很好的包含了平坦区域,阴影,纹理等细节,这些都有益于测试各种不同的图像处理算法。它是一幅很好的测试照片!其次,由于这是一个非常有魅力的女人的照片,因此图像处理研究行业(多数由男性组成)倾向于使用一幅他们认为很有吸引力的图片也并不令人惊奇。
Alexander Sawchuk估计大概是在1973年6月或7月间,那时他还是南加州大学信号与图像处理研究所(SIPI)的一名助教,当时他正在与一名研究生以及SIPI研究室的经理正在匆忙地寻找一副高质量的图片用于大学的会议论文。他们不喜欢1960年代早期所使用的电视标准所用的普通检验图,他们希望找到一幅能够得到很好动态范围的有光泽的图像,并且希望能有一幅人脸图像。正在那时,碰巧有人走了进来并且带着一幅最近出版的《花花公子》,这张图片就被他们看上了。
后来在1997年,图像科学和技术协会(英语:Society for Imaging Science and Technology)的第50届会议上,这张图片的女主人莱娜·瑟德贝里被邀为贵宾出席会议,直到这时,莱娜才发现,她在图像领域有很大的名气。
相关资料:https://blog.csdn.net/huapenguag/article/details/51077495
part2:WordCount编程
Github项目地址
GitHub链接:https://github.com/XydfLi
项目链接:https://github.com/XydfLi/PersonalProject-Java
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 60 |
| • Estimate | • 估计这个任务需要多少时间 | 45 | 60 |
| Development | 开发 | 1360 | 1375 |
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 200 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 30 | 35 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| • Design | • 具体设计 | 150 | 125 |
| • Coding | • 具体编码 | 700 | 670 |
| • Code Review | • 代码复审 | 60 | 45 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 180 | 250 |
| Reporting | 报告 | 70 | 120 |
| • Test Repor | • 测试报告 | 20 | 30 |
| • Size Measurement | • 计算工作量 | 20 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 1475 | 1555 |
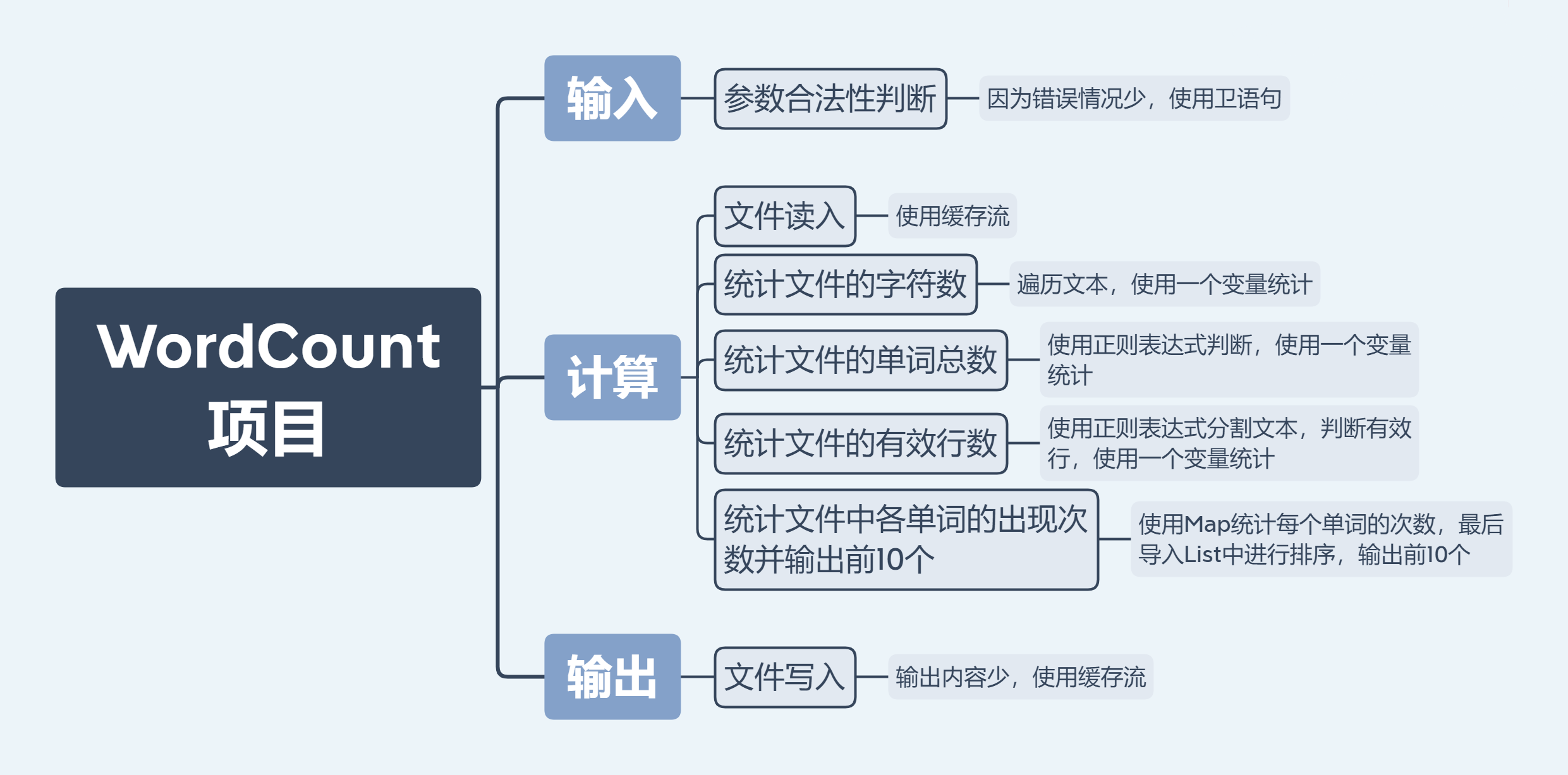
解题思路
- 思考过程
在读完需求,提出自己的问题,然后彻底搞懂需求之后我再开始思考解题思路。思考的第一步是先思考如何实现需求里的所有要求,划分出所有的功能,不考虑性能,不考虑代码延展性等,提取出需求里实际需要我们完成的功能。第二步对第一步中得到的功能划分进行进一步的分析,思考如何具体实现,如何做性能上的提升,提高整体代码的质量。
- 功能划分
- 输入部分
1、命令行指令的输入和参数的获取
2、参数的合法性判断- 计算部分
1、文件读入
2、统计文件的字符数
3、统计文件的单词总数
4、统计文件的有效行数
5、统计文件中各单词的出现次数并输出前10个- 输出部分
1、文件写入- 异常部分
1、枚举并处理所有可能的异常
- 查找资料
第一步我先学习完作业要求中提供的各方面学习资料。
第二步根据之前进行的功能划分来查找资料。查找资料时找出实现该功能的尽可能多的解法,最后再选择其中最合适的解法做标记。查找资料的途径非常多,有CSDN、简书、百度、知乎、中国知网等等。
- 初步解题思路
代码规范制定链接
代码规范:https://github.com/XydfLi/PersonalProject-Java/blob/main/221801334/codestyle.md
设计与实现过程
总体概述
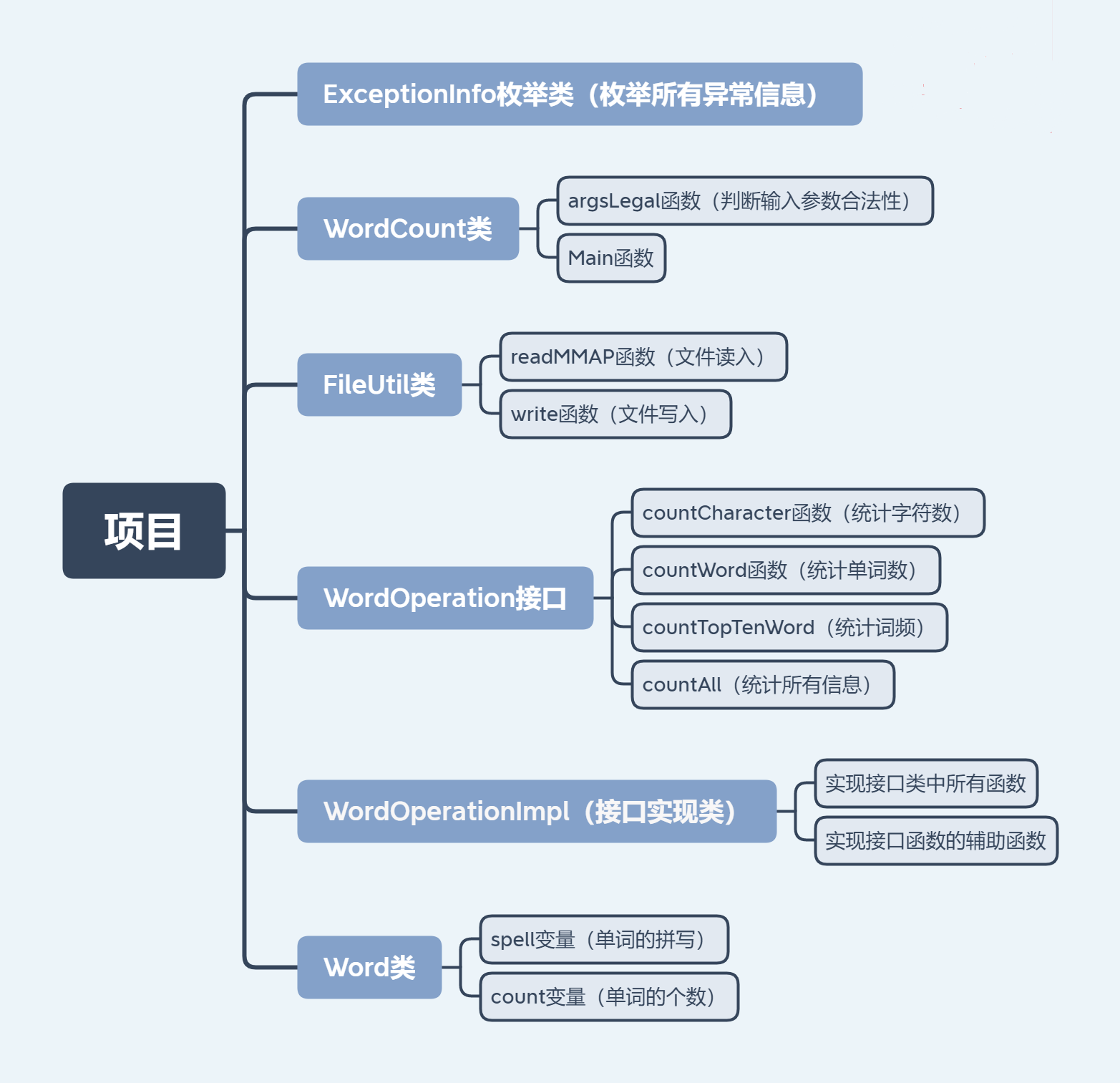
参数合法性判断
第一步,定义一个枚举类型ExceptionInfo,里面枚举了所有可能出现的异常信息,并对各种异常信息做分类。对异常信息做分类的目的是为了更好的对用户做出相应的提示,有的异常提示并退出程序,而有的异常仅需要提示,程序正常执行等等。
第二步,在WordCount中判断参数的合法性,主要使用卫语句,通过每一条if语句列举出所有可能的异常的情况加以判断和处理。
文件读入
文件读入主要使用了MMAP,选择该方法的原因有两个。
第一个是效率高,MMAP是一种内存映射文件的方法,常规的文件读取需要两次的数据拷贝过程,而MMAP技术仅一次,故效率高。
第二个是可以很好地解决java中缓存流无法读取到'\r'的问题,缓存流会将'\r'、'\n'、'\r\n'均当成换行,导致readLine函数读取不到'\r'字符。
MMAP学习资料:认真分析mmap:是什么 为什么 怎么用
/**
* 文件读入,使用mmap
*
* @param file 输入文件
* @return 文件内容,如果空则为""
*/
public static String readMMAP(File file){
RandomAccessFile raf = null;
MappedByteBuffer mbb = null;
try {
raf = new RandomAccessFile(file, "r");
mbb = raf.getChannel().map(FileChannel.MapMode.READ_ONLY, 0, file.length());
if (mbb != null){
return ENCODING.decode(mbb).toString();
} else {
return "";
}
} catch (IOException e) {
...
} finally {
...
}
return "";
}
文件写入
此次文件写入的数据量比较小,所以我没使用mmap方法,使用了缓存流的方法,即BufferedWriter。在这边我考虑到输出文件的内容大多比较少,所以直接设置了缓冲区的大小为1024字节,减少空间资源的消耗。
计算部分
统计文件的字符数
因为需求已经说明了,输入的字符均为ASCII字符,统计的也是ASCII字符,所以我们直接输出文本字符串的长度即可。
统计文件的单词总数
实现的原理很简单,主要是通过正则表达式来匹配字符串。如果匹配到一个字符串,再判断该字符串的前一个字符是不是非字母数字的字符,如果是表示找到一个单词。其中需要注意的一点是第一个匹配到的字符串需要单独处理。
/**
* 统计文本中单词个数
*
* @return 单词数
*/
@Override
public int countWord() {
// 正则表达式为:[a-z]{4}[a-z0-9]*
Matcher wordMatcher = wordPattern.matcher(content);
int wordNum = 0;
if (wordMatcher.find()){ // 第一个匹配到的字符串单独处理
int start = wordMatcher.start() - 1;
if (start >= 0){ // 可以判断前一个字符
if (wordLegal(content.charAt(start))){
++wordNum;
}
} else {
++wordNum;
}
}
while (wordMatcher.find()){
if (wordLegal(content.charAt(wordMatcher.start() - 1))){
++wordNum;
}
}
return wordNum;
}
统计文件的有效行数
这一部分也可以使用正则表达式很方便地解决,但是为了效率我使用了遍历字符串的方法。
首先我先找到一个子字符串,该字符串以'\n'结尾,就是代码中startIndex,endIndex之间的字符串。然后从startIndex开始遍历这个子串,一旦找到一个非空白字符就退出循环,表示找到了一个有效行。
/**
* 计算行数
*
* @param start 开始位置
* @param end 结束位置
*/
private void countLine(int start, int end){
String temp = content.substring(start, end);
int tempLen = temp.length();
// 一行的开始位置
int startIndex = 0;
// 一行的结束位置
int endIndex;
int i;
int count = 0;
char c;
while (startIndex < tempLen) {
// 找到一个以'\n'结尾的字符串
for (endIndex = startIndex;endIndex < tempLen;endIndex++){
if (temp.charAt(endIndex) == '\n'){
break;
}
}
if ((endIndex - startIndex) > 0){
for (i = startIndex;i < endIndex;++i){
c = temp.charAt(i);
if ((c >= 33) && (c <= 126)){// 找到一个非空白字符
break;
}
}
if (i < endIndex){
++count;
}
}
startIndex = endIndex + 1;
}
lineNum.getAndAdd(count);
}
统计文件中各单词的出现次数并输出top10
第一步,我通过map来记录每一个单词的个数,和统计单词数的原理一样,通过正则表达式得到每一个单词,然后更新Map。
第二步,通过Map中的数据来获取top10单词。原理是构建一个优先队列,然后遍历map,维护这个队列。如果队列大小小于10,则该元素入队,如果大于等于10,那么判断该元素是否比队头元素大,大则队头元素出队,将更大的元素入队。最后逆向输出队列即可。
值得一提的是,这种方法的时间复杂度比把map进行排序然后输出前10个的方法更加小,性能更高。
/**
* 获取top10的单词
*
* @param wordIntegerMap Map类,各个单词的个数
* @return top10单词列表
*/
private List<Map.Entry<String, Integer>> getTopTen(Map<String, Integer> wordIntegerMap){
// 构建优先队列
Queue<Map.Entry<String, Integer>> wordQueue = new PriorityQueue<>(16, (o1, o2) -> {
if (o1.getValue().intValue() != o2.getValue().intValue()){
return o1.getValue() - o2.getValue();
}
return o2.getKey().compareTo(o1.getKey());
});
List<Map.Entry<String, Integer>> words = new ArrayList<>(wordIntegerMap.entrySet());
//
for (Map.Entry<String, Integer> word : words){
if (wordQueue.size() < 10){
wordQueue.add(word);
} else if (isReplace(word, wordQueue.peek())){
wordQueue.poll();
wordQueue.add(word);
}
}
List<Map.Entry<String, Integer>> wordList = new ArrayList<>(16);
while (!wordQueue.isEmpty()){
wordList.add(wordQueue.poll());
}
return wordList;
}
countAll函数的实现(精华部分)
有关于这一部分的优化过程,我已经详细地写在性能改进的部分,点击这里前往
countAll方法的实现并不是简单地调用前面几个统计的方法拼接而成的,而是经过了多线程的优化。
countAll函数的实现主要分为有效行数统计、单词及词频统计两个部分。原理是首先将文本字符串划分为几个子字符串,每个字符串都以'\n'结尾。开线程处理每一个子字符串的有效行数和单词个数,以及单词词频的统计。
/**
* 统计字符数、单词数、行数、top10单词并输出到文件
*/
@Override
public void countAll() {
...
int len = content.length();
// 字符串按照oneLen的长度来划分
int oneLen = Math.max(MIN_THREAD_LENGTH, len >> 4);
int start = 0;
int j;
for (int i = 0;i < len;i += oneLen){
if (i > start){
for (j = i;j < len;++j){
if (content.charAt(j) == '\n'){
break;
}
}
int finalStart = start;
int finalJ = j;
threadPool.execute(() -> countLine(finalStart, finalJ));
threadPool.execute(() -> countWordThread(finalStart, finalJ));
start = j + 1;
}
}
if (start < len){
int finalStart1 = start;
threadPool.execute(() -> countLine(finalStart1, len));
threadPool.execute(() -> countWordThread(finalStart1, len));
}
...
}
内容的整理和输出
这部分主要是调用文件写入函数将运算的结果写入文件中。其中因为频繁修改字符串,使用了StringBuilder,它可以极大提高频繁修改字符串的性能。同样,因为输出文件较小,提前设置了StringBuilder的大小为1024字节,减小空间消耗。
性能改进
改进一:多线程改进(精华部分)
注意:这一部分作为测试样例的文件大小均为:149mb
初始状况
当我一开始完成项目的时候,进行性能分析,149mb文件需要总时间:7497ms。观察性能分析结果,得出结论:CPU负载在大部分时间内只有20%-30%。好家伙,作为一个老板,我不能允许我的CPU大部分时间在磨洋工,解决的方法就是多线程。
具体性能分析如下:
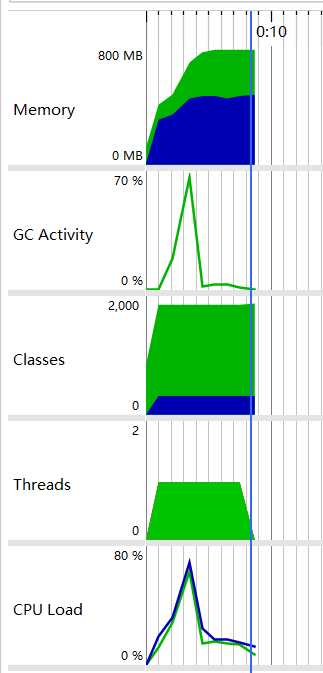
多线程优化统计有效行数
通过查阅资料,我总结出多线程优化的两个关键地方:一个是负载均衡,就是每个线程的工作量差不多。还有一个是尽可能少的加锁等,以防止线程间过多阻塞造成资源消耗。
经过细致地分析代码,我打算从有效行数的统计开始。既然用到了多线程,那么线程池也安排上。
然后将有效行数的统计任务分割好,交给线程池,分割是按照正则表达式匹配字符串,一旦匹配到一个'\n'字符就分配一个线程进行处理。
结果为:149mb文件需要总时间:8402ms,性能分析如下:
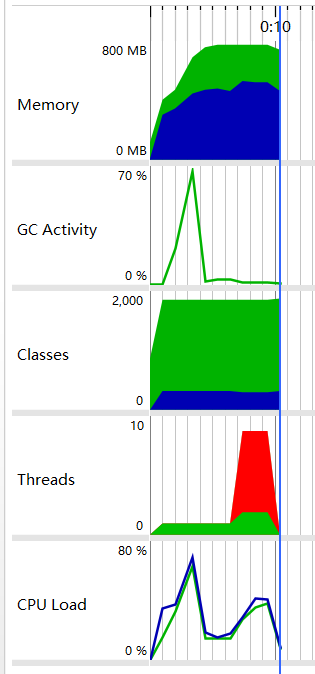
分析结果可知:当线程多的时候,CPU负载确实上升了,当时线程那部分一片红意味着一堆的线程阻塞。总的时间反而增加了。
多线程优化单词统计
线程阻塞的问题我们先放着,先把单词统计的部分也加入线程池,将单词统计部分划分好交给线程池。这边需要注意的一点是,Map我改为使用线程安全的ConcurrentHashMap,同时map更新部分的代码也要修改:
/**
* 往map中修改数据
*
* @param key 单词
*/
private void dealMap(String key){
Integer oldValue;
while (true) {
oldValue = wordIntegerMap.get(key);
if (oldValue == null) {
if (wordIntegerMap.putIfAbsent(key, 1) == null) { // 表示数据添加成功
break;
}
} else {
if (wordIntegerMap.replace(key, oldValue, oldValue + 1)) { // 表示数据更新成功
break;
}
}
}
}
结果为:149mb文件需要总时间:6218ms,性能分析如下:
线程情况如下:
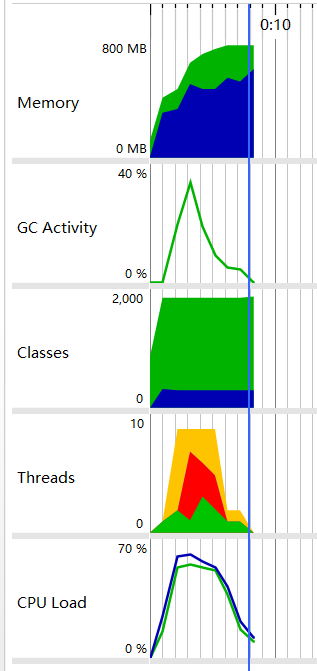
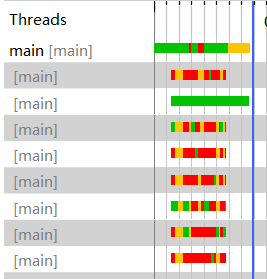
分析结果可知:CPU负载大部分在40%以上了,不错,CPU更加努力工作带来的结果是总体时间的下降。但是还不够,目前仍然存在两个问题:一个是CPU负载还是不够高,另一个是阻塞的线程太多了,这就像是员工之间有很多的地方需要互相配合,但是他们之间的默契又不好。
多线程任务划分
经过对代码分析,线程阻塞的原因是他们要访问同一个数据,为了线程安全,他们不能同时修改访问,造成了阻塞。而我给每一个线程分配的任务太少,这就导致了每一个线程频繁地访问这个数据,也就频繁地造成阻塞。
我的解决办法是,增加分配给线程的任务量,降低分配的线程数。任务量划分的原理是将文本字符串分割为几段,每个线程工作一段,每一段字符串都以'\n'字符结尾,为了防止每段字符串太小,这里设置了一个最短字符串的长度。同时,把有效行数和单词统计的线程工作量都划分了。代码请看这里
结果为:149mb文件需要总时间:3598ms,性能分析如下:
线程情况如下:
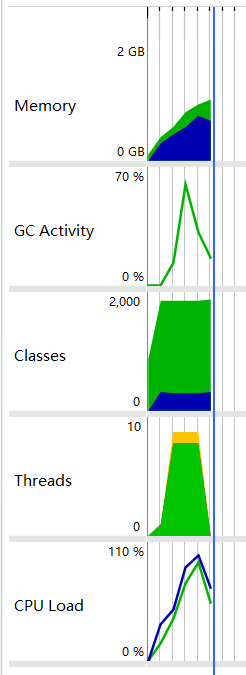

分析结果:CPU负载一半的时间在60%以上,线程也基本都处在运行状态,没出现阻塞,时间也下降了。
多线程优化总结
总结一下结果,对于149mb的文件,经过多线程优化后,时间从7497ms下降到3598ms,时间性能提升了52.03%。
多线程优化对于数据量比较大的情况下,优化的效果比较明显,而如果数据量太小,因为线程创建、销毁、切换等开销,性能有可能反而会下降。所以在这里我建议老师测试的时候既要有小数据的文件,也要有大数据的文件。
改进二:文件读入改进
文件读入部分使用了MMAP技术,对性能的提升较大,具体实现思路及代码请点击这里
经过测试,150mb的文件,使用mmap读入花费682ms,使用缓存流的方式读入花费1548ms。从结果来看,mmap确实使得文件读入的时间降低,而且文件越大,这个差距就越明显。
改进三:初始化改进
给项目中的List、Map、缓存空间预分配一个初始空间。
对于ArrayList,如果空间不足的时候,将会申请一个更大的数组空间,然后把原数组中的数据复制过去,这一操作如果经常进行,会极大影响性能。
对于Map,如果元素个数超过负载因子*容量的大小,那么会执行reHash操作,这个操作也很影响性能。经过测试,添加3750000数据,未分配空间的Map需要2388ms,预分配空间的Map仅需要741ms。
缓存空间大小的分配主要是在文件写入的部分,因为文件写入采用缓存流的方式,而输出内容的大小又比较小,分配一个合适的缓存空间大小可以减少缓存刷新的次数,增加代码性能。
单元测试
单元测试主要使用的是TestNG,以及Assert断言。
构造思路
构造单元测试的思路主要是从两个方面来测试。一个是从用户的角度,测试是否符合用户需求,测试在所有用户输入的可能性下程序的响应。还有一个是开发者的角度,把程序分块进行测试,尽可能提高代码覆盖率,边界测试(大数据测试),特殊情况测试。
测试覆盖率
我设计的测试基本覆盖了所有的代码,只剩下一些比较难出现的异常处理测试不到(例如多线程InterruptedException异常等)。
关于如何优化覆盖率,这里我使用的编译器是IDEA,测试的时候可以显示覆盖率等情况,同时编译器也标记出了覆盖到的地方和没覆盖到的地方。我们测试的时候可以观察有哪些地方没有覆盖到,然后设计测试样例覆盖过去。
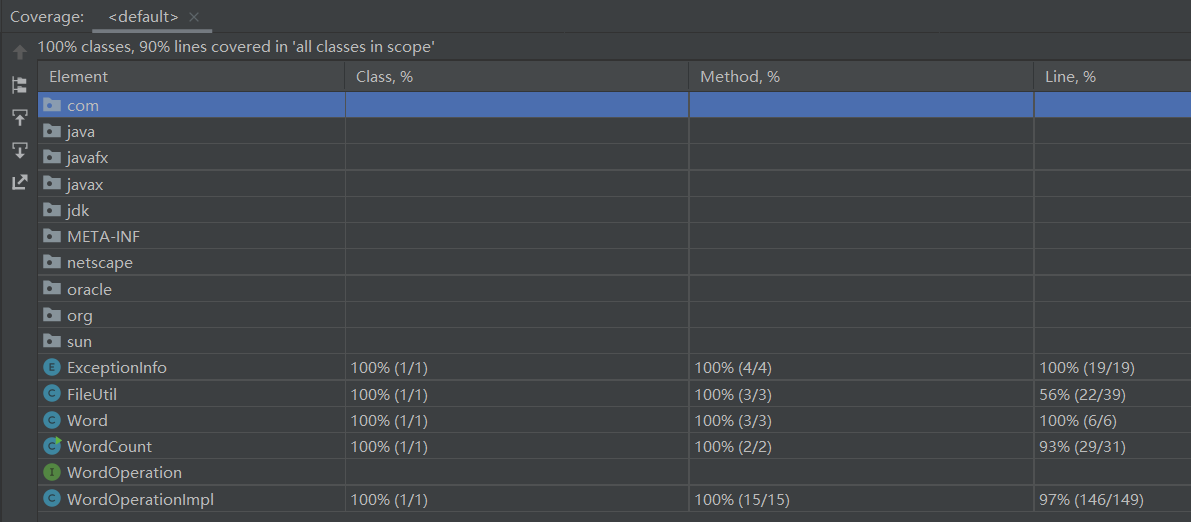
最终我的测试覆盖率情况是:类的覆盖率100%,方法覆盖率100%,代码行覆盖率90%。
测试覆盖率情况截图如下:
输入参数测试
这一部分的单元测试主要模拟在各种用户输入下,程序的响应。以下函数主要测试的是WordCount中的Main函数和argsLegal函数。
因为这个接口由用户调用,所以测试需要包含所有的情况,在测试中包含了:参数为null、无参、只有一个参数、输入文件不存在、输入文件是一个图片、输出文件不存在、输出文件是一个图片、输出文件已经有内容、输入输出正常、输出文件所在的文件夹不存在等等情况。
统计字符数测试
主要测试的是接口中的countCharacter函数,该函数的作用是统计字符数。
/**
* 测试字符数
*
*/
@Test
public void testCountCharacter() {
Assert.assertEquals(wordOperation.countCharacter(),47853);
}
统计单词数测试
主要测试的是接口中的countWord函数,该函数的作用是统计单词数
/**
* 测试单词数
*
*/
@Test
public void testCountWord() {
...
File input = new File(INPUT_ROOT + "test11.txt");
File out = new File(OUTPUT_FILE + "test11_output.txt");
WordOperation wordOperation2 = new WordOperationImpl(input, out);
Assert.assertEquals(wordOperation2.countWord(),1);
}
统计top10单词测试
主要测试的是接口中的countTopTenWord函数,该函数的作用主要是统计top10单词
/**
* 测试统计top10单词
*
*/
@Test
public void testCountTopTenWord() {
List<Word> answer = new ArrayList<>();
answer.add(new Word("error", 153));
answer.add(new Word("state", 87));
answer.add(new Word("quantum", 85));
answer.add(new Word("logical", 83));
answer.add(new Word("code", 74));
answer.add(new Word("qubit", 67));
answer.add(new Word("correction", 66));
answer.add(new Word("with", 56));
answer.add(new Word("that", 53));
answer.add(new Word("fault", 47));
List<Word> topTen = wordOperation.countTopTenWord();
for (int i = 0;i < topTen.size();i++){
Assert.assertEquals(topTen.get(i).getSpell(), answer.get(i).getSpell());
Assert.assertEquals(topTen.get(i).getCount(), answer.get(i).getCount());
}
...
}
统计所有数据测试
这一部分主要测试的是接口中的countAll函数,该函数使用多线程优化了各方面的计算。测试中我自己构造了14个文件,基本包含了所有的情况。
14个文件包括了:149mb大数据文件1、149mb大数据文件2、自定义空白字符开头文件、空文件、随机生成60000000个字符(范围0-127)、一篇英文论文、随机生成60000000个空白字符、随机生成60000000个非空白字符、测试类似"\r\n\r\n\r\n"等情况下的空行、7500000个以制表符隔开的"apple123"单词、以"abcd"开头的60000004个字母数字、第二篇英文论文、第三篇英文论文(全大写)
/**
* 测试计算部分
*
* @param fileName 文件名
*/
private void test(String fileName){
String input = INPUT_ROOT + fileName;
String output = OUTPUT_ROOT + fileName.substring(0, fileName.lastIndexOf(".")) + "_output.txt";
String answer = ANSWER + fileName.substring(0, fileName.lastIndexOf(".")) + "_answer.txt";
WordCount.main(new String[]{input, output});
Assert.assertEquals(FileUtil.readMMAP(new File(answer)), FileUtil.readMMAP(new File(output)));
}
这里就不展示测试文件了,太多了。
计算部分异常
关于异常这个方面,本次项目中主要异常是用户输入方面的异常和文件操作方面的异常。
用户方面的异常的测试和说明我已经写在单元测试部分了,点击这里查看。
文件操作部分的异常我这里补充一下。有关于IOException异常的,该异常已被捕获并做了相应的处理,出现该异常的情况是输入文件不存在,而这个我在用户输入参数部分就做了处理,所以该情况不可能出现在这里。
心路历程
- 这次的作业我刚看到的第一眼感觉不难,需求清晰明了,要求我们实现的一些功能也不难。大多数作业的内容都是以前学过的,需要去复习一下重新捡起来,这次项目上我花费时间最多的还是在改进代码上。
- 此次的项目开发虽然功能看上去不难,但是我真正开始编码了才发现,需要我们注意的点,需要我们注意的一些细节还是非常多的。这些细节往往就意味着一个bug,为了解决这些问题,我和很多朋友一起讨论过,这里感谢和我讨论,一起分享想法的朋友们( ̄▽ ̄)~*。
- 开发项目的过程中,我开发第一个版本的代码花费的时间比较少。第一个版本的代码主要考虑的是先把功能都实现了,性能方面不怎么考虑。
- 此次开发中我遇到的第一个问题就是文件读取上的问题,缓存流的方法无法读取到'\r'字符,我当初第一个想法是既然传统IO不行,那我试试通道的方法。可是通道的方法我又不熟悉,嗯。。。又进入了查资料的状态。后来发现java这边也可以用mmap,这让我很高兴,虽然我之前只在C++上用过mmap,不过原理是一样的。不过上手以后又发现java的mmap没有ummap类似的方法,嗯。。。我又开始犹豫了。不过后来经过不断查资料,找到了解决的方法,而且在性能测试中149mb的数据需要的内存不超过2g,我就放心了。
- 发布了baseline以后,紧接着又开始进行v2代码的开发。这一部分耗费了我大部分的时间,我开始思考如何优化我的算法。最开始的想法是用字典树替换掉Map,字典树在匹配字符串上有优势,时间复杂度也是O(1),所以我实现了字典树的代码(v2中移除了,可以在v1中查看)。经过多次测试,发现性能还更低!嗯。。。我似乎做了无用功 (`皿´)ノ ,算了,这就是性能优化的常态。
- 字典树优化失败以后,我又开始了多线程的优化,优化过程这里我不多说了,前面我已经详细写下了过程,点击这里前往,还好,多线程优化给我带来了好消息。
收获与不足
- 这次的项目让我重新复习了一遍java,捡起了很多java的知识。在编码的过程中我经常要去看jdk的源码,这也让我意识到了我的java基础并不牢固,我也在java中尝试了许多我之前没用过,不会用的一些东西。
- 这次的项目中和朋友们一起讨论给了我很多的思路,项目里很多的想法也是在讨论中出现的,希望大家以后也能更经常在一起互相讨论(▽),有时候和别人的讨论比自己独自研究进步更快。这边特别感谢一下陪我度过大半时间的李宇琨同学,给我带来很多想法和思路。
- 之前参加的华为软件精英挑战赛学到的一些知识没想到竟然在这次作业中用上了,两者都是要求我们对程序的性能尽可能地优化,都需要我们进行性能分析,mmap的知识也是那时候学的。
- 这里还要特别感谢一下我们的助教徐明盛学长,这次的作业中我经常找徐学长提问题,每次学长都耐心回答我的问题,非常感谢,希望学长不要嫌我烦( • ̀ω•́ )✧。
- 这次作业还有一个收获是让我熟悉了一些常用工具的做法,像是TestNG、JProfiler等等。
- 希望后面的作业有性能优化要求的话,可以给出测试计算机的一些信息,例如操作系统、CPU核数、内存等等,这对于代码的性能优化有很大的帮助。也对于编程语言的选择有很大帮助,例如C++在不同操作系统下自带的包不同。也希望在测试的过程中能够多次测试或增大数据集,以减小时间的抖动。
- 关于代码还有一个不足之处是top10单词的统计我还没开始尝试优化,这里标记一下,以后有机会优化,优化思路参考的论文是:张军,杨家海,王继龙.基于多次过滤的TopN统计算法[J].清华大学学报(自然科学版),2006(04):604-608.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号