hashMap的底层实现
HashMap实现原理,利用数组和链表存储元素
数组:存储区间连续,占用内存严重,寻址容易,插入删除困难
链表:存储区间离散,占用内存比较宽松,寻址困难,插入删除容易
hashmap综合应用了这两种数据结构,实现了寻址容易,插入删除也容易
HashMap结构示意图:
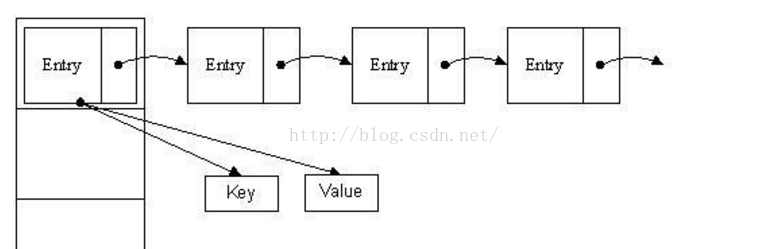
实现原理:用一个数组来存储元素,但是这个数组存储的不是基本数据类型。HashMap实现巧妙的地方就在这里,数组存储的元素是一个Entry类,这个类有三个数据域,key、value(键值对),next(指向下一个Entry)
那HashMap是怎么确定插入一个值的时候怎么确定该把这个元素插入这个数组的哪个位置呢?
实际上是通过这个算法实现的:key.hashCode()%Array[].length 位置下标由key的哈希值对数组的长度取模得到,如果两个输入串的hash函数的值一样,则称这两个串是一个碰撞(Collision),也就是哈希碰撞,当新插入数据时,HashMap会先用key的hash值检查table 位置, 如果这个位置没有值就放入(没有哈希碰撞),如果有值,就用equals() 分别比较key 如果相等就替换该value 值。如果不等就放在链表的首位并next指针指向下一个entry
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值 ,public int hashCode()返回该对象的哈希码值
说到这里,又有一个问题了,如果两个key经过计算后得到相同的数组下标怎么办?
这里用到的就是一个链表,hashmap在插入元素的时候,会首先检查这个位置上有没有元素,如果已经有了元素,那么就把这个新插入的Entry的next指向本来这个位置上的元素的地址,然后再插入这个位置,这也就是为什么插入多个相同的key的value时,这个位置的value始终是最后插入的那个元素的值。
保持对象行为的一致性。而具有相等的hashcode的两个对象equals不一定成立。你可以这样认为也行,hashcode是作为一个对象存储的参考,hash表本身是一种散列表,在数据存储这块,功效比较大,而equals是相当于两对象之间的属性(成员变量)“相等”,意即具有相同的行为(方法)。或许这样讲起来理解比较的费劲。举个例子,比如你定义class A有两个属性,int aA,aB,在定义一个class B也有两个属性,int bA,bB,然后覆写hashcode方法,A类为return aA*aB;B类为return bA*bB.现在情况已经很显然了,各自实例化一个对象:a,b,假如:a.aA=b.bA,a.aB=b.bB,相等,或者a.aA=b.bB,a.aB=b.bA两个对象a,b的hashcode一定相等,当时你能说两个对象相等吗?显然不能吧,a与b都是不同类的实例。连equals最基本的obj instance of A或是obj instance of B都不成立。如果是同一个类的不同对象,拥有相同hashcode的时候,则一定相等,或者equals成立的时候则hashcode一定为真,这也就是所谓的相等
 的对象具有行为一致性。
的对象具有行为一致性。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号