Redis入门学习笔记
0. 前期准备
0.1 安装二进制包
sudo apt install redis
0.2 redis-server的启动
# 例如: redis-server --port 7777
# redis-server的一些启动选项
Usage: ./redis-server [/path/to/redis.conf] [options]
./redis-server - (read config from stdin)
./redis-server -v or --version
./redis-server -h or --help
./redis-server --test-memory <megabytes>
Examples:
./redis-server (run the server with default conf)
./redis-server /etc/redis/6379.conf
./redis-server --port 7777
./redis-server --port 7777 --replicaof 127.0.0.1 8888
./redis-server /etc/myredis.conf --loglevel verbose
Sentinel mode:
./redis-server /etc/sentinel.conf --sentinel
# redis.conf, 常用配置项说明
1、redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程:
daemonize no
2、当redis以守护进程方式运行时,redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定:
pidfile /var/run/redis.pid
3、指定redis监听端口,默认端口号为6379,作者在自己的一篇博文中解析了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利女歌手Alessia Merz的名字:
port 6379
4、设置tcp的backlog,backlog是一个连接队列,backlog队列总和=未完成三次握手队列+已完成三次握手队列。在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn 的值,所以需要确认增大somaxconn和tcp_max_syn_backlog两个值来达到想要的
效果:
tcp-backlog 511
5、绑定的主机地址:
bind 127.0.0.1
6、当客户端闲置多长时间后关闭连接,如果指定为0,表示永不关闭:
timeout 300
7、设置检测客户端网络中断时间间隔,单位为秒,如果设置为0,则不检测,建议设置为60:
tcp-keepalive 0
8、指定日志记录级别,redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose:
loglevel verbose
9、日志记录方式,默认为标准输出,如果配置redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null:
logfile stdout
10、设置数据库数量,默认值为16,默认当前数据库为0,可以使用select<dbid>命令在连接上指定数据库id:
databases 16
11、指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合:
save <seconds><changes>
# 例如: save 300 10, 表示300秒内有10个key发生变化就将数据同步到数据文件
12、指定存储至本地数据库时是否压缩数据,默认为yes,redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变得巨大:
rdbcompssion yes
13、指定本地数据库文件名,默认值为dump.rdb:
dbfilename dump.rdb
14、指定本地数据库存放目录:
dir ./
15、设置当本机为slave服务时,设置master服务的IP地址及端口,在redis启动时,它会自动从master进行数据同步:
slaveof <masterip><masterport>
16、当master服务设置了密码保护时,slave服务连接master的密码:
masterauth <master-password>
17、设置redis连接密码,如果配置了连接密码,客户端在连接redis时需要通过auth <password>命令提供密码,默认关闭:
requirepass foobared
18、设置同一时间最大客户端连接数,默认无限制,redis可以同时打开的客户端连接数为redis进程可以打开的最大文件描述符数,如果设置maxclients 0,表示不作限制。当客 户端连接数到达限制时,redis会关闭新的连接并向客户端返回 max number of clients reached错误消息:
maxclients 128
19、指定redis最大内存限制,redis在启动时会把数据加载到内存中,达到最大内存后,redis会先尝试清除已到期或即将到期的key,当次方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制, 会把key存放内存,value会存放在swap区:
maxmemory <bytes>
20、设置缓存过期策略,有6种选择:
volatile-lru:使用LRU算法移除key,只针对设置了过期时间的key;
allkeys-lru:使用LRU算法移除key,作用对象所有key;
volatile-random:在过期集合key中随机移除key,只对设置了过期时间的key;
allkeys-random:随机移除key,作用对象为所有key;
volarile-ttl:移除哪些ttl值最小即最近要过期的key;
noeviction:永不过期,针对写操作,会返回错误信息。
maxmemory-policy noeviction
21、指定是否在每次更新操作后进行日志记录,redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内数据丢失。因为redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内置存在于内存中。默认为no:
appendonly no
22、指定更新日志文件名,默认为appendonly.aof:
appendfilename appendonly.aof
23、指定更新日志条件,共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快);
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全);
everysec:表示每秒同步一次(折中,默认值)
appendfsync everysec
24、指定是否启用虚拟内存机制,默认值为no,简单介绍一下,VM机制将数据分页存放,由redis将访问量较小的页即冷数据 swap到磁盘上,访问多的页面由磁盘自动换出到内存中:
vm-enabled no
25、虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个redis实例共享:
vm-swap-file /tmp/redis.swap
26、将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(redis的索引数据就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为 0:
vm-max-memory 0
27、redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是根据存储的数据大小来设定的,作者建议如果储存很多小对象,page大小最好设置为32或者64bytes;如果存储很多大对象,则可以使用更大的page,如果不确定,就使用默认值:
vm-page-size 32
28、设置swap文件中page数量,由于页表(一种表示页面空闲或使用的bitmap)是放在内存中的,在磁盘上每8个pages将消耗1byte的内存:
vm-pages 134217728
29、设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成长时间的延迟。默认值为4:
vm-max-threads 4
30、设置在客户端应答时,是否把较小的包含并为一个包发送,默认为开启:
glueoutputbuf yes
31、指定在超过一定数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法:
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
32、指定是否激活重置hash,默认开启:
activerehashing yes
33、指定包含其他配置文件,可以在同一主机上多个redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件:
include /path/to/local.conf
0.3 redis-cli的启动
# 例如: redis-cli -h 127.0.0.1 -p 7777 -a pass
# redis-cli的一些启动选项
Usage: redis-cli [OPTIONS] [cmd [arg [arg ...]]]
-h <hostname> Server hostname (default: 127.0.0.1).
-p <port> Server port (default: 6379).
-s <socket> Server socket (overrides hostname and port).
-a <password> Password to use when connecting to the server.
You can also use the REDISCLI_AUTH environment
variable to pass this password more safely
(if both are used, this argument takes predecence).
-u <uri> Server URI.
-r <repeat> Execute specified command N times.
-i <interval> When -r is used, waits <interval> seconds per command.
It is possible to specify sub-second times like -i 0.1.
-n <db> Database number.
-x Read last argument from STDIN.
-d <delimiter> Multi-bulk delimiter in for raw formatting (default: \n).
-c Enable cluster mode (follow -ASK and -MOVED redirections).
--raw Use raw formatting for replies (default when STDOUT is
not a tty).
--no-raw Force formatted output even when STDOUT is not a tty.
--csv Output in CSV format.
--stat Print rolling stats about server: mem, clients, ...
--latency Enter a special mode continuously sampling latency.
If you use this mode in an interactive session it runs
forever displaying real-time stats. Otherwise if --raw or
--csv is specified, or if you redirect the output to a non
TTY, it samples the latency for 1 second (you can use
-i to change the interval), then produces a single output
and exits.
--latency-history Like --latency but tracking latency changes over time.
Default time interval is 15 sec. Change it using -i.
--latency-dist Shows latency as a spectrum, requires xterm 256 colors.
Default time interval is 1 sec. Change it using -i.
--lru-test <keys> Simulate a cache workload with an 80-20 distribution.
--replica Simulate a replica showing commands received from the master.
--rdb <filename> Transfer an RDB dump from remote server to local file.
--pipe Transfer raw Redis protocol from stdin to server.
--pipe-timeout <n> In --pipe mode, abort with error if after sending all data.
no reply is received within <n> seconds.
Default timeout: 30. Use 0 to wait forever.
--bigkeys Sample Redis keys looking for keys with many elements (complexity).
--memkeys Sample Redis keys looking for keys consuming a lot of memory.
--memkeys-samples <n> Sample Redis keys looking for keys consuming a lot of memory.
And define number of key elements to sample
--hotkeys Sample Redis keys looking for hot keys.
only works when maxmemory-policy is *lfu.
--scan List all keys using the SCAN command.
--pattern <pat> Useful with --scan to specify a SCAN pattern.
--intrinsic-latency <sec> Run a test to measure intrinsic system latency.
The test will run for the specified amount of seconds.
--eval <file> Send an EVAL command using the Lua script at <file>.
--ldb Used with --eval enable the Redis Lua debugger.
--ldb-sync-mode Like --ldb but uses the synchronous Lua debugger, in
this mode the server is blocked and script changes are
not rolled back from the server memory.
--cluster <command> [args...] [opts...]
Cluster Manager command and arguments (see below).
--verbose Verbose mode.
--no-auth-warning Don't show warning message when using password on command
line interface.
--help Output this help and exit.
--version Output version and exit.
Cluster Manager Commands:
Use --cluster help to list all available cluster manager commands.
Examples:
cat /etc/passwd | redis-cli -x set mypasswd
redis-cli get mypasswd
redis-cli -r 100 lpush mylist x
redis-cli -r 100 -i 1 info | grep used_memory_human:
redis-cli --eval myscript.lua key1 key2 , arg1 arg2 arg3
redis-cli --scan --pattern '*:12345*'
(Note: when using --eval the comma separates KEYS[] from ARGV[] items)
When no command is given, redis-cli starts in interactive mode.
Type "help" in interactive mode for information on available commands
and settings.
1. Redis的数据类型
Redis作为一种KV型的内存数据库,支持五种数据类型:String,Hash(相当于Map),List,Set,Zset(有序集合)
1.1 String操作
| 命令 | 说明 | 案例 |
|---|---|---|
| set | 添加key-value | set username admin |
| get | 根据key获取数据 | get username |
| strlen | 获取key的长度 | strlen key |
| exists | 判断key是否存在 | exists name返回1存在 0不存在 |
| del | 删除redis中的key | del key |
| Keys | 用于查询符合条件的key | keys * 查询redis中全部的keykeys n?me 使用占位符获取数据keys nam* 获取nam开头的数据 |
| mset | 赋值多个key-value | mset key1 value1 key2 value2 key3 value3 |
| mget | 获取多个key的值 | mget key1 key2 |
| append | 对某个key的值进行追加 | append key value |
| type | 检查某个key的类型 | type key |
| select | 切换redis数据库 | select 0-15 redis中共有16个数据库 |
| flushdb | 清空单个数据库 | flushdb |
| flushall | 清空全部数据库 | flushall |
| incr | 自动加1 | incr key |
| decr | 自动减1 | decr key |
| incrby | 指定数值添加 | incrby 10 |
| decrby | 指定数值减 | decrby 10 |
| expire | 指定key的生效时间 单位秒 | expire key 20key20秒后失效 |
| pexpire | 指定key的失效时间 单位毫秒 | pexpire key 2000key 2000毫秒后失效 |
| ttl | 检查key的剩余存活时间 | ttl key |
| persist | 撤销key的失效时间 | persist key |
1.2 Hash操作
| 命令 | 说明 | 案例 |
|---|---|---|
| hset | 为对象添加数据 | hset key field value |
| hget | 获取对象的属性值 | hget key field |
| hexists | 判断对象的属性是否存在 | HEXISTS key field1表示存在 0表示不存在 |
| hdel | 删除hash中的属性 | hdel user field [field ...] |
| hgetall | 获取hash全部元素和值 | HGETALL key |
| hkyes | 获取hash中的所有字段 | HKEYS key |
| hlen | 获取hash中所有属性的数量 | hlen key |
| hmget | 获取hash里面指定字段的值 | hmget key field [field ...] |
| hmset | 为hash的多个字段设定值 | hmset key field value [field value ...] |
| hsetnx | 设置hash的一个字段,只有当这个字段不存在时有效 | HSETNX key field value |
| hstrlen | 获取hash中指定key的长度 | HSTRLEN key field |
| hvals | 获取hash的所有值 | HVALS user |
1.3 List操作
| 命令 | 说明 | 案例 |
|---|---|---|
| lpush | 从队列的左边入队一个或多个元素 | LPUSH key value [value ...] |
| rpush | 从队列的右边入队一个或多个元素 | RPUSH key value [value ...] |
| lpop | 从队列的左端出队一个元素 | LPOP key |
| rpop | 从队列的右端出队一个元素 | RPOP key |
| lpushx | 当队列存在时从队列的左侧入队一个元素 | LPUSHX key value |
| rpushx | 当队列存在时从队列的右侧入队一个元素 | RPUSHx key value |
| lrange | 从列表中获取指定返回的元素 | LRANGE key start stop Lrange key 0 -1 获取全部队列的数据 |
| lrem | 从存于 key 的列表里移除前 count 次出现的值为 value 的元素。 这个 count 参数通过下面几种方式影响这个操作:count > 0: 从头往尾移除值为 value 的元素。count < 0: 从尾往头移除值为 value 的元素。count = 0: 移除所有值为 value 的元素。 | LREM list -2 “hello” 会从存于 list 的列表里移除最后两个出现的 “hello”。需要注意的是,如果list里没有存在key就会被当作空list处理,所以当 key 不存在的时候,这个命令会返回 0。 |
| Lset | 设置 index 位置的list元素的值为 value | LSET key index value |
1.4 Set操作
| 命令 | 说明 | 案例 |
|---|---|---|
| sadd | 往集合里面添加元素 | sadd key value1 value2 |
| smembers | 获取集合所有的元素 | smembers key |
| srem | 删除集合某个元素 | srem key value |
| spop | 返回并删除集合中1个随机元素(可以用来抽奖,不会重复抽到某人) | spop key |
| srandmember | 随机取一个元素 | srandmember key |
| sismember | 判断集合是否有某个值 | sismember key value |
| scard | 返回集合元素的个数 | scard key |
| smove | 移动集合元素 | smove source dest value:把source的value移动到dest集合中 |
| sinter | 求交集 | sinter key1 key2 key3:求key1,key2,key3的交集 |
| sunion | 求并集 | sunion key1 key2:求key1 key2 的并集 |
| sdiff | 求差集 | sdiff key1 key2:求key1 key2的差集 |
| sinterstore | 求交集 | sinterstore res key1 key2:求key1 key2的交集并存在res里 |
1.5 Zset操作
| 命令 | 说明 | 案例 |
|---|---|---|
| zadd | 添加元素 | zadd key score1 value1:添加元素 |
| zrange | 把集合排序后,返回名次[start,stop]的元素 默认是升续排列 withscores 是把score也打印出来 | zrange key start stop [withscore]:把集合排序后,返回名次[start,stop]的元素 默认是升续排列 withscores 是把score也打印出来 |
| zrank | 查询member的排名(升序0名开始) | zrank key member:查询member的排名(升序0名开始) |
| zrangebyscore | 集合(升序)排序后取score在[min, max]内的元素,并跳过offset个,取出N个 | zrangebyscore key min max [withscores] limit offset N:集合(升序)排序后取score在[min, max]内的元素,并跳过offset个,取出N个 |
| zrevrank | 查询member排名(降序 0名开始) | zrevrank key member:查询member排名(降序 0名开始) |
| zremrangebyscore | 按照score来删除元素,删除score在[min, max]之间 | zremrangebyscore key min max:按照score来删除元素,删除score在[min, max]之间 |
| zrem | 删除集合中的元素 | zrem key value1 value2:删除集合中的元素 |
| zremrangebyrank | 按排名删除元素,删除名次在[start, end]之间的 | zremrangebyrank key start end:按排名删除元素,删除名次在[start, end]之间的 |
| zcard | 返回集合元素的个数 | zcard key:返回集合元素的个数 |
| zcount | 返回[min, max]区间内元素数量 | zcount key min max:返回[min, max]区间内元素数量 |
| zinterstore | 求交集 | zinterstore destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]求key...的交集,key...的权值为weight |
2. Redis的持久化机制
Redis的两种持久化机制:快照(SnapShot)与AOF(Append Only File)
2.1 快照(SnapShot)
Redis默认的持久化方式就是快照方式,在指定的时间间隔内将内存中的数据集快照写入磁盘,生成的快照文件类型是.rdb,所以也将快照方式的持久化称为RDB持久化。与快照持久化相关的几个配置如下:
11、指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合:
save <seconds> <changes>
# 例如: save 300 10, 表示300秒内有10个key发生变化就将数据同步到数据文件
12、指定存储至本地数据库时是否压缩数据,默认为yes,redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变得巨大:
rdbcompssion yes
13、指定本地数据库文件名,默认值为dump.rdb:
dbfilename dump.rdb
快照可以由服务端自动触发,也可以由客户端来手动触发,通过SAVE或BGSVAE命令来触发快照持久化,BGSAVE会是服务端fork出一个进程来执行该次持久化操作(避免阻塞主进程,后续命令操作时,可能持久化操作还未结束),而SAVE命令則会直接让服务端的主进程来执行持久化。(可能会产生阻塞,但会严格保证本次持久化完成之后才会接受其它命令)。除此之外,当客户端连接关闭时,也会触发快照持久化。
2.2 AOF
开启AOF持久化时,Redis服务端会将客户端每个写操作都记录在日志中(.aof文件),与AOF持久化相关的几个配置:
21、指定是否在每次更新操作后进行日志记录,redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内数据丢失。因为redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内置存在于内存中。默认为no:
appendonly no
22、指定更新日志文件名,默认为appendonly.aof:
appendfilename appendonly.aof
23、指定更新日志条件,共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快);
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全);
everysec:表示每秒同步一次(折中,默认值)
appendfsync everysec
2.3 RDB与AOF持久化对比
RDB 的优点:
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。RDB 的缺点:
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF 的优点:
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。AOF 的缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
小结:
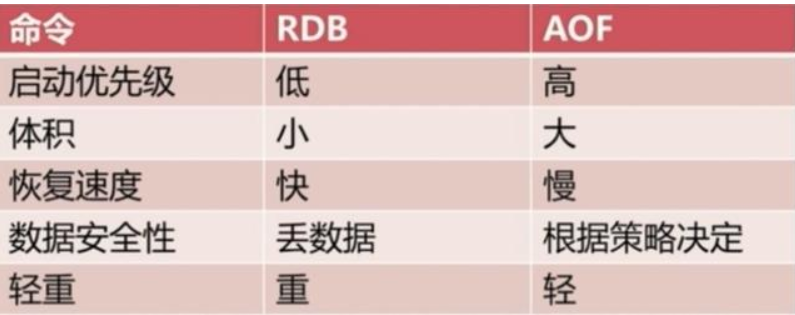
3. Redis的主从复制架构
主从复制架构主要是做数据冗余,从节点仅仅起到数据备份的作用,没有故障自动转移功能,并不像Zookeeper那样有着完整的选举机制。主节点主要负责处理写请求,从节点主要负责处理读请求,主节点写入数据后,将命令发送到从节点,使主从数据同步。
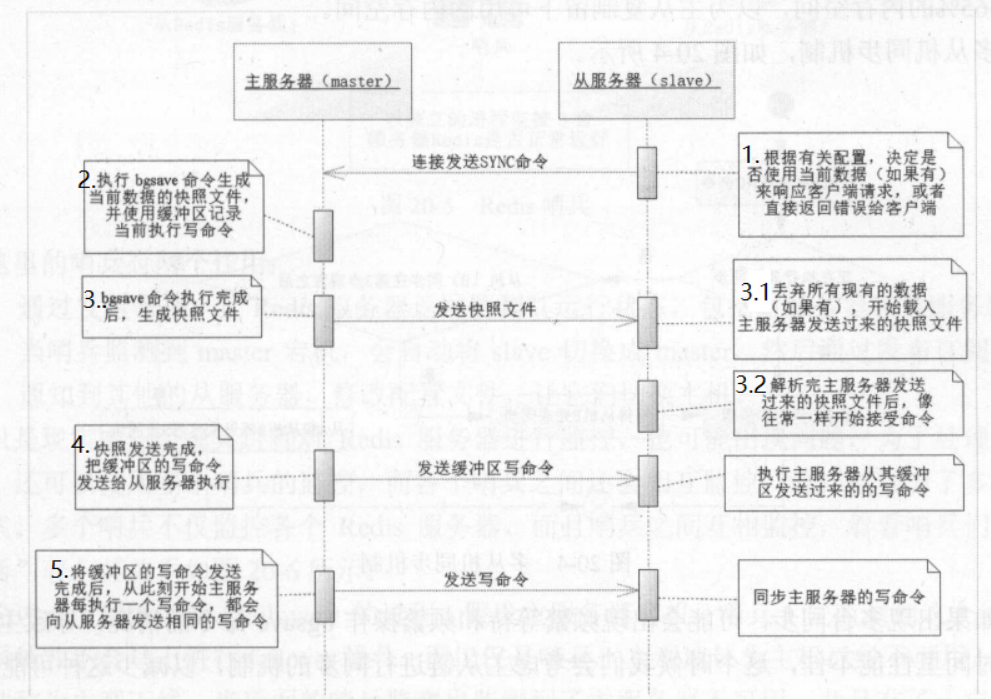
4. Redis的哨兵机制(Redis-Sentinel)
Redis-Sentinel是官方推荐的高可用解决方案,当redis在做master-slave的高可用方案时,假如master宕机了,redis本身(以及其很多客户端)都没有实现自动进行主备切换,而redis-sentinel本身也是独立运行的进程,可以部署在其他与redis集群可通讯的机器中监控redis集群。
由一个或多个Sentinel实例组成的Sentinel系统可以监视多个主服务器,以及所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求 。如下图:
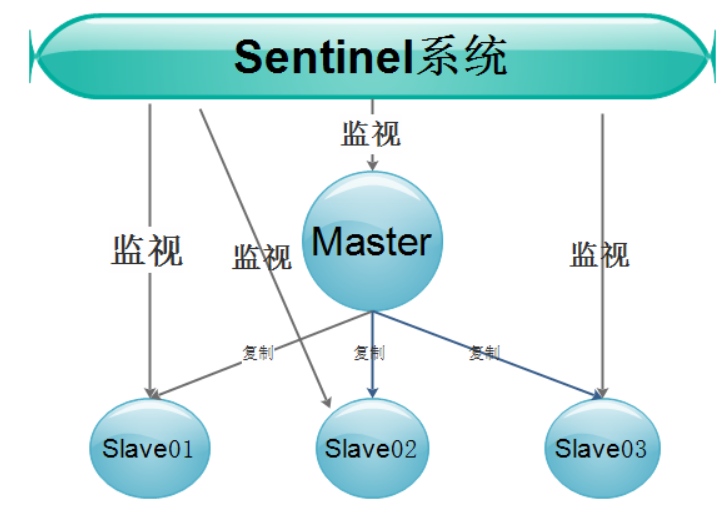
Sentinel负责监控集群中的所有主、从节点,当发现主节点故障时,Sentinel会在所有的从节点中选一个成为新的主节点。当旧的主节点恢复时,并不会恢复成为柱节点,而是成为新的从节点。Sentinel节点之间会运行选举及一致性协议(类似Zookeeper),保障系统的高可用。
相比主从复制架构,Redis的哨兵模式具备故障自动转移功能。由于主/从节点之间的关系可能会发生变化,所以客户端连接的并不是某个具体的Redis节点,而是连接到Sentinel,类似一个代理。哨兵机制可以解决高可用,但是在伸缩性方面存在问题,无法动态增加节点。
5. Redis Cluster模式
Redis最开始使用主从模式做集群,若master宕机需要手动配置slave转为master;后来为了高可用提出来哨兵模式,该模式下有一个哨兵角色监视master和slave,若master宕机可自动将slave转为master,但它也有一个问题,就是不能动态扩充;所以在3.x又提出cluster集群模式。
Redis Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
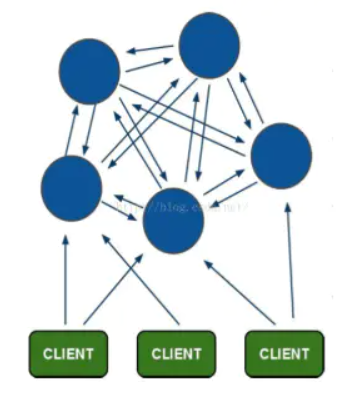
Redis Cluster特性:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 节点的fail是通过集群中超过半数的节点检测失效时才生效。
- 客户端与redis节点直连,不需要中间proxy层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
- Redis Cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),Redis Cluster 负责维护node <-> slot <-> value这三者之间的映射关系。
- Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
- 当有节点上下线时,会进行slot的重新分配,对应slot的数据也会发生迁移。
Redis Cluster为了保证数据的高可用性,加入了主从模式,上图中的每个节点相当于一个主从集群架构(包含一个主节点和若干个从节点),当主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉。
6. Redis的几种缓存问题
Redis是一个K/V型的内存数据库,理论上来说其中应该存储热点数据,减轻数据库的压力。流程如下所示:
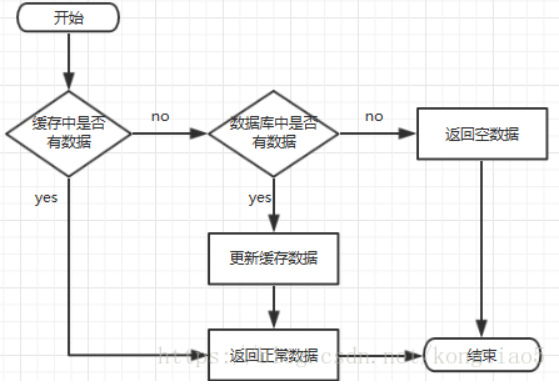
6.1 缓存穿透
如果Redis缓存的数据没有命中,导致大量的流量直接冲击到数据库,这就是所谓的缓存穿透。如发起为id=-1的数据或id为特别大不存在的数据查询,这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,并设置一个缓存有效时间,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。
- 在Redis与应用之间加一层布隆过滤器(部署在应用上),将大量不存在的数据查询拦截掉。不过考虑到分布式应用,可以利用Redis的BitMap来实现布隆过滤器。
6.2 缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期导致的),这时如果并发用户特别多,读缓存没读到数据,最终都去数据库去请求数据,导致数据库压力瞬间增大,造成过大压力。
解决方案:
- 设置热点数据永远不过期。(适用于少量数据)
- 分布式锁,代码如下所示:
package com.xycode.distributed;
import lombok.extern.slf4j.Slf4j;
import redis.clients.jedis.Jedis;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
/**
* @author xycode
*/
@Slf4j
public class RedisDistributedLock implements Lock {
private String lockName;
private Jedis cli;
public RedisDistributedLock(String lockName) {
this.lockName = lockName;
cli = new Jedis("121.48.165.121", 7777);
cli.auth("pass");
}
@Override
public void lock() {
while (true) {
if (tryLock()) {
break;
} else {
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("{} waiting for redis lock", Thread.currentThread().getName());
}
}
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock() {
if (cli.setnx(lockName, "lock") == 1) {
return true;
}
return false;
}
public boolean isLock() {
if (cli.exists(lockName)) {
return true;
}
return false;
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return false;
}
@Override
public void unlock() {
cli.del(lockName);
log.info("{} released redis lock", Thread.currentThread().getName());
}
@Override
public Condition newCondition() {
return null;
}
}
public static String getData(String key) throws Exception{
//从缓存读取数据
String result=getDataFromRedis(key);
//缓存中不存在数据
if(result==null){
RedisDistributedLock distributedLock=new RedisDistributedLock(key);
try{
//尝试去获取锁
if(distributedLock.tryLock()){
//获锁成功,从数据库获取数据
result=getDatafromMysql(key);
//更新缓存数据
if(result!=null){
setDataToCache(key,result);
}
}else{
//获锁失败,暂停100ms再重新尝试获取数据
Thread.sleep(100);
result=getData(key);
}
}catch(Exception e){
//异常处理
}finally{
//释放锁
if(distributedLock.isLock()){
distributedLock.unlock();
}
}
}
return result;
}
通过以上的处理,当第一个用户请求成功从数据库获取数据并设置好缓存之前,其它用户都会被阻塞住,上述代码是针对指定的key来设置分布式锁,更为高效。(以上是主动轮询式的,也可以基于Zookeeper实现异步回调式的)
6.3 缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
- 使用分布式锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号