
K8s-存储_PV
K8s-存储_PV
引入:PV概念
PersistentVolume,是由管理员设置的存储,他是集群的一部分,就像节点就 是集群的资源的一样,PV也是集群中的资源,PV是Volume之类的插件,但具有 独立于使用PV的pod生命周期,此API对象包含存储实现的细节,即NFS,iSCSI 或特定于供应商的存储系统,灵活性极强;
PVC概念:持久卷申请,被pod所使用
PersistentVolumeClaim,使用户存储的请求,与pod相似,pod消耗节点资 源,pvc消耗pv资源,pod可以请求特定级别的资源(CPU和内存),声明可以请求 特定的大小和访问模式(例如,可以以读/写一次或只读多次模式挂载)
静态PV
集群管理员创建一些 PV。它们带有可供群集用户使用的实际存储的细节。它们 存在于 Kubernetes API 中,可用于消费
动态PV
动态PV 当管理员创建的静态 PV 都不匹配用户的 PersistentVolumeClaim 时,集群 可能会尝试动态地为 PVC 创建卷。此配置基于 StorageClasses:PVC 必须请求 [存储类],并且管理员必须创建并配置该类才能进行动态创建。声明该类为 "" 可 以有效地禁用其动态配置
要启用基于存储级别的动态存储配置,集群管理员需要启用 API server 上的 DefaultStorageClass [准入控制器] 。例如,通过确保 DefaultStorageClass 位 于 API server 组件的 --admission-control 标志,使用逗号分隔的有序值列表 中,可以完成此操作
绑定
master 中的控制环路监视新的 PVC,寻找匹配的 PV(如果可能),并将它们 绑定在一起。如果为新的 PVC 动态调配 PV,则该环路将始终将该 PV 绑定到 PVC。否则,用户总会得到他们所请求的存储,但是容量可能超出要求的数量。 一旦 PV 和 PVC 绑定后,PersistentVolumeClaim 绑定是排他性的,不管它们是如何绑定的。 PVC 跟 PV 绑定是一对一的映射
下图可以很好的反映
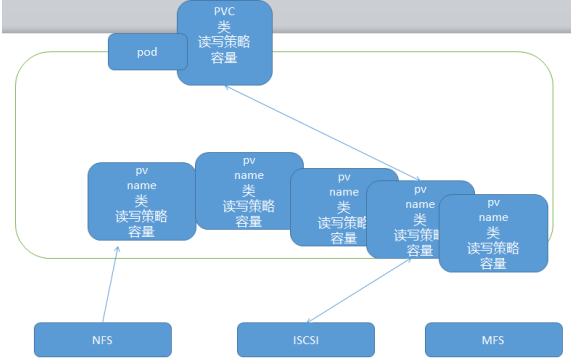
存储工程师:搭建后端存储,将存储写入到看k8s中变成pv,即映射进去
业务部门:写pod,判断种类,编写对应的pvc,最后交给集群自身去匹配
优点:有效解决各个部门之间的协调问题,灵活性强
缺点:有可能需求匹配不到,该协调还是协调
官方解决方案:
静态PV:工程师写好的
动态PV:根据需求被自动创建,交给云处理,阿里云(对象存储)
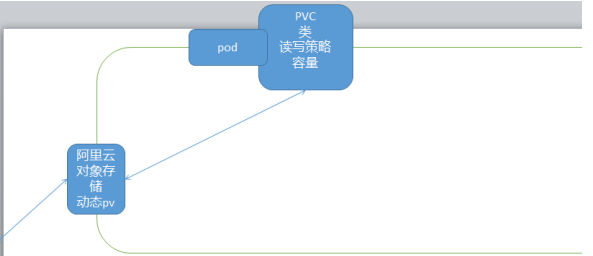
缺点:在云服务器上才能解决
持久化卷声明的保护
PVC 保护的目的是确保由 pod 正在使用的 PVC 不会从系统中移除,因为如果 被移除的话可能会导致数据丢失
注意:当 pod 状态为 Pending 并且 pod 已经分配给节点或 pod 为 Running 状态时,PVC 处于活动状态
当启用PVC 保护 alpha 功能时,如果用户删除了一个 pod 正在使用的 PVC, 则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 pod 使用
建议删除过程
先 pod-->pvc-->pv-->对应的存储该保存保存改清空清空
持久化卷类型
PersistentVolume 类型以插件形式实现。Kubernetes 目前支持以下插件类型:
GCEPersistentDisk AWSElasticBlockStore AzureFile AzureDisk FC (Fibre Channel)
FlexVolume Flocker NFS iSCSI RBD (Ceph Block Device) CephFS
Cinder (OpenStack block storage) Glusterfs VsphereVolume Quobyte Volumes
HostPath VMware Photon Portworx Volumes ScaleIO Volumes StorageOS
持久卷演示代码
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
# storageClassName: slow:存储类名字一般不具备任何意义
PV访问模式
PersistentVolume 可以以资源提供者支持的任何方式挂载到主机上。如下表 所示,供应商具有不同的功能,每个 PV 的访问模式都将被设置为该卷支持的特 定模式。例如,NFS 可以支持多个读/写客户端,但特定的 NFS PV 可能以只读方 式导出到服务器上。每个 PV 都有一套自己的用来描述特定功能的访问模式
分类:模式间不具备兼容关系,即互不兼容,100%匹配
RWO--ReadWriteOnce——该卷可以被单个节点以读/写模式挂载
ROX--ReadOnlyMany——该卷可以被多个节点以只读模式挂载
RWX--ReadWriteMany——该卷可以被多个节点以读/写模式挂载
注意
一个卷一次只能使用一种访问模式挂载,即使它支持很多访问模式。例如, GCEPersistentDisk 可以由单个节点作为 ReadWriteOnce 模式挂载,或由多个 节点以 ReadOnlyMany 模式挂载,但不能同时挂载
类型支持的挂载模式
| Volume 插件 | ReadWriteOnce | ReadOnlyMany | ReadWriteMany |
|---|---|---|---|
| AWSElasticBlockStoreAWSElasticBlockStore | ✓ | - | - |
| AzureFile | ✓ | ✓ | ✓ |
| AzureDisk | ✓ | - | - |
| CephFS | ✓ | ✓ | ✓ |
| Cinder | ✓ | - | - |
| FC | ✓ | ✓ | - |
| FlexVolume | ✓ | ✓ | - |
| Flocker | ✓ | - | - |
| GCEPersistentDisk | ✓ | ✓ | - |
| Glusterfs | ✓ | ✓ | -因没有分布式锁的存在 |
| HostPath | ✓ | - | - |
| iSCSI | ✓ | ✓ | --因没有分布式锁的存在 |
| PhotonPersistentDisk | ✓ | - | - |
| Quobyte | ✓ | ✓ | ✓ |
| NFS | ✓ | ✓ | ✓ |
| RBD | ✓ | ✓ | - |
| VsphereVolume | ✓ | - | -(当 pod 并列时 有效) |
| PortworxVolume | ✓ | - | ✓ |
| ScaleIO | ✓ | ✓ | - |
| StorageOS | ✓ | - | - |
回收策略
Retain(保留)——手动回收
Recycle(回收)——基本擦除(rm -rf /thevolume/*)--不建议使用
Delete(删除)——关联的存储资产(例如 AWS EBS、GCE PD、Azure Disk 和 OpenStack Cinder 卷)将被删除-----作用在动态PV上,像云服务器上的存 储,不用了删除,避免资源浪费
注:目前,只有 NFS 和 HostPath 支持回收策略。AWS EBS、GCE PD、Azure Disk 和 Cinder 卷支持删除策略,在新版本中NFS回收策略被移除了
状态,卷可以处在以下的某种状态
Available(可用)——一块空闲资源还没有被任何声明绑定
Bound(已绑定)——卷已经被声明绑定
Released(已释放)——声明被删除,但是资源还未被集群重新声明
Failed(失败)——该卷的自动回收失败
注:命令行会显示绑定到 PV 的 PVC 的名称
StatefulSet控制器
匹配 Pod name ( 网络标识 ) 的模式为:$(statefulset名称)-$(序号),比如下 面的示例:web-0,web-1,web-2
StatefulSet 为每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为: $(podname).(headless server name),也就意味着服务间是通过Pod域名来通 信而非 Pod IP,因为当Pod所在Node发生故障时, Pod 会被飘移到其它 Node 上,Pod IP 会发生变化,但是 Pod 域名不会有变化
StatefulSet 使用 Headless 服务来控制 Pod 的域名,这个域名的 FQDN 为: $(service name).$(namespace).svc.cluster.local,其中,“cluster.local” 指 的是集群的域名
根据 volumeClaimTemplates,为每个 Pod 创建一个 pvc,pvc 的命名规则 匹配模式:(volumeClaimTemplates.name)-(pod_name),比如下面的 volumeMounts.name=www, Pod name=web-[0-2],因此创建出来的 PVC 是 www-web-0、www-web-1、www-web-2
删除 Pod 不会删除其 pvc,手动删除 pvc 将自动释放 pv
StatefulSet的启停顺序
有序部署:部署StatefulSet时,如果有多个Pod副本,它们会被顺序地创建 (从0到N-1)并且,在下一个Pod运行之前所有之前的Pod必须都是Running和 Ready状态。
有序删除:当Pod被删除时,它们被终止的顺序是从N-1到0
有序扩展:当对Pod执行扩展操作时,与部署一样,它前面的Pod必须都处于 Running和Ready状态
StatefulSet使用场景
稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现
稳定的网络标识符(域名),即 Pod 重新调度后其 PodName 和 HostName 不 变,基于Headless Service服务实现
有序部署,有序扩展,基于 init containers 来实现(initC)
有序收缩
现在基于以下实验验证上诉功能
选择7-4作为nfs服务器
- 安装NFS服务器,因集群作为NFS客户端,所以顺便一起执行以下安装命令
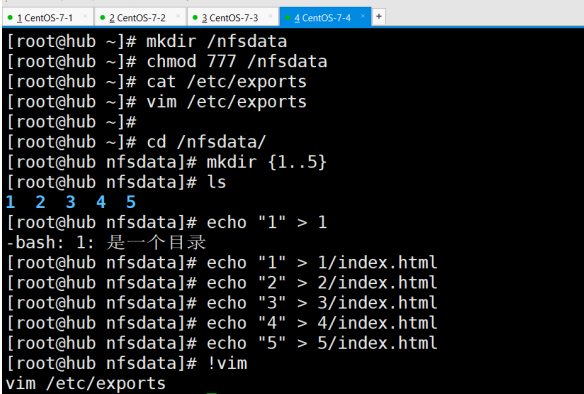
模拟5台服务器挂载点
启动服务
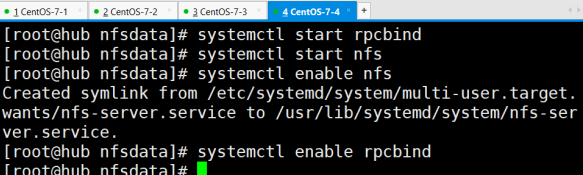
其它机器测试使用
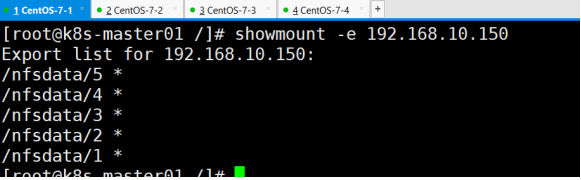
创建目录挂载使用测试
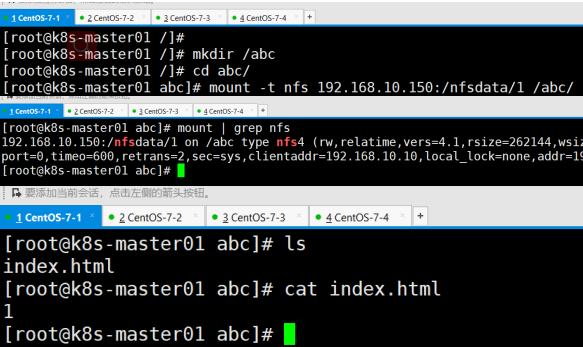
能够正常挂载
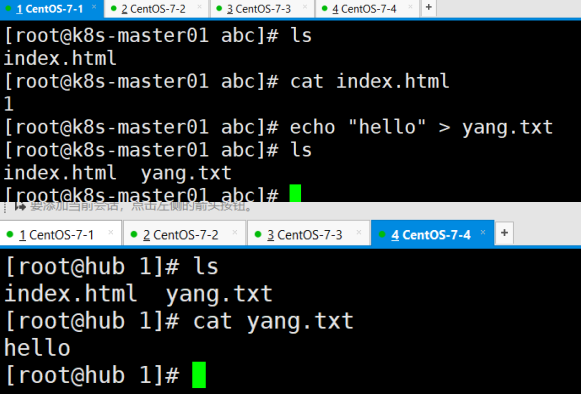
也能正常写入文件,测试完成,退出,下载nfs挂载进行下面实验
- 部署PV,基于以下模板在同一文件创建多个pvc(pod)
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: REtain
storageClassName: nfs
nfs:
path: /nfsdata/1
server: 192.168.10.150
# 创建:注意每个pvc之间的区别,为下面实验验证
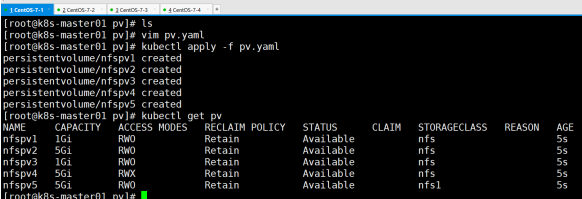
创建statefulSet,就必须创建无头服务Headless Service, 来控制 Pod 的域名 基于操作文档模板创建即可
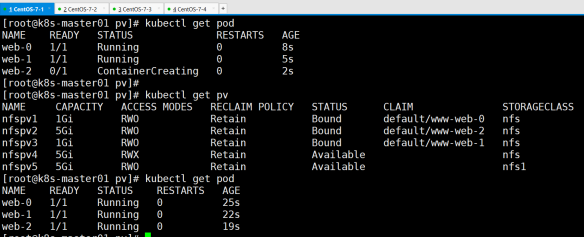
因为主页内容是挂载点,所以使用了pv的内容
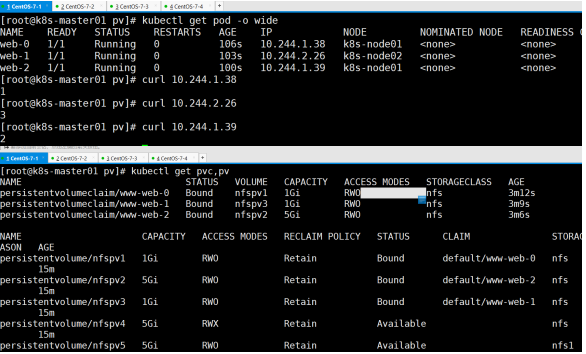
pv的组成
由statefulset名字+pod名字+起来的顺序号,从0开始
配顺序,先优先匹配最优的,再次优匹配
测试:扩容验证是否只有容量可以不同,其余是否可以运行不同(存储种类,回收策略) 将副本数量由3改为5
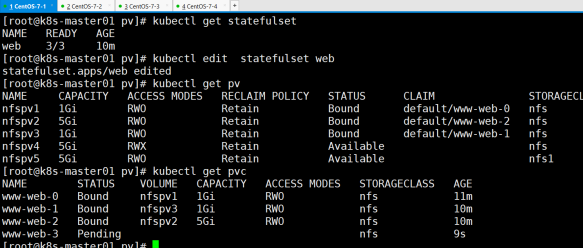
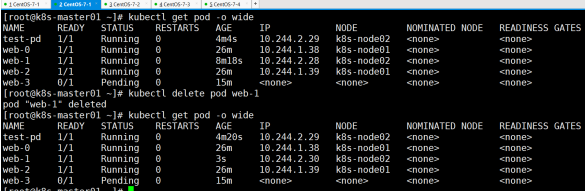
首先先创建web-3----验证有序部署
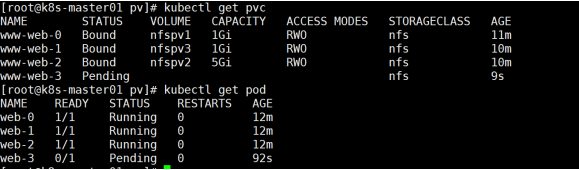
结论: web-3一直处于绑定状态,即不能正常绑定,
验证statefulset的稳定持久卷特性
删除pod,再看是否创建,查看挂载的内容是否还在
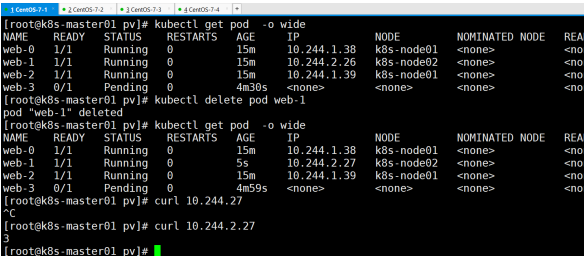
还能正常查看,再次验证,进入容器闯进后删除pod,看新建的pod是否还有内容
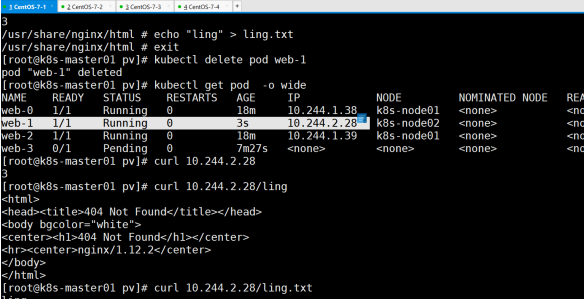
结论:验证成功
验证statefulset的稳定的网络标识
先进入之前volume里下载web-1的文件内容并查看
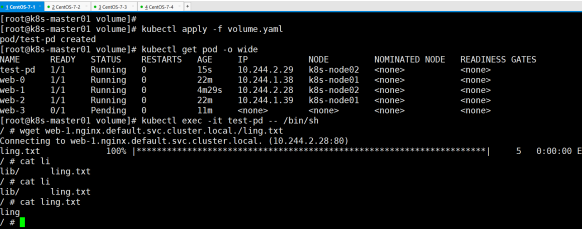
开另一终端,删除web-1pod,test-pd先删除ling.txt文件,再次下载,看是否成 功下载,文件内容是否改变
结论:域名不改,再次下载还能成功,即验证成功
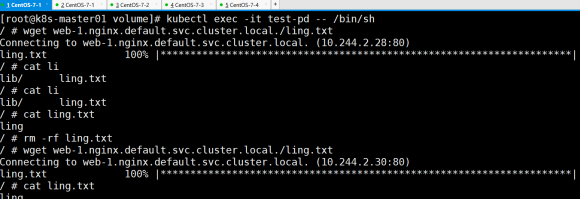
测试回收
将statefulset控制器删除,再删除pvc,看pv状态,测试保留性Retain
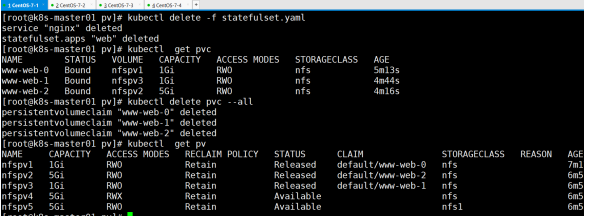
此时可看到nfspv1,nfspv2,nfspv3已经变成已释放状态Released 怎样将其变成可用,最简单方法,删除pv,重新新建pv
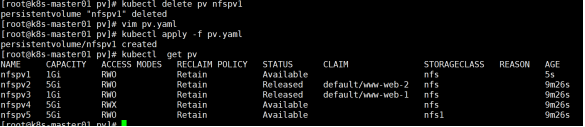
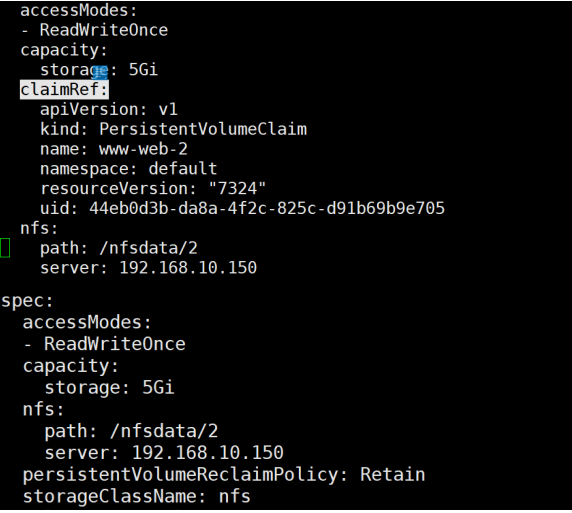
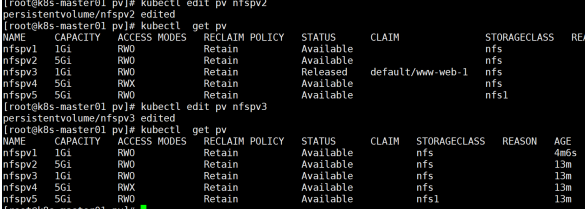
但此种方法较为麻烦,最简易方法如下,edit修改关键字信息 将claimRef:和所属的子选项删除即可
结论:删除后状态回到可用状态

 浙公网安备 33010602011771号
浙公网安备 33010602011771号