


典型分布式系统分析:Bigtable
正文
本文是典型分布式系统分析的第三篇,分析的是Bigtable,一个结构化的分布式存储系统。
Bigtable作为一个分布式存储系统,和其他分布式系统一样,需要保证可扩展、高可用与高性能。与此同时,Bigtable还有应用广泛的特点(wide applicability),既能满足对延时敏感的、面向终端用户的应用需求,又能hold住高吞吐需求的批处理程序。
不过,通读完整篇论文,会发现,Bigtable这个系统是建立在很多其他google的产品上的,如GFS、Chubby。GFS为Bigtable提供了可伸缩、高可靠、高可用的数据存储服务;而Chubby保证了Bigtable中元数据的高可用、强一致。这种设计思想,跟之前分析过的GFS,以及本人平常使用到的MongoDB不太一样,在GFS、MongoDB中,元数据服务器一般有两重功能:维护元数据、集中调度;而Bigtable中的master只负责调度。
本文地址:https://www.cnblogs.com/xybaby/p/9096748.html
Bigtable的定义
Bigtable是06年的论文,当时还是关系型数据库一统江湖。因此,网上有人说,Bigtable较难以理解,因为Bigtable有一些术语与关系型数据路类似,如row、column、table,但是内部实现、使用方式又与传统关系型数据库差异非常之大。不过现在是2018年了,NoSQL已经应用非常广泛,因此至少现在看起来还是比较容易读懂的。
A Bigtable is a sparse, distributed, persistent multidimensional sorted map.
上面是Bigtable的定义,特点是sparse、distributed、multidimensional、sorted map,此外,还要加上一个关键字:structured。
在文章understanding-hbase-and-bigtable中有对这几个关键字的详细解释与举例。下面结合论文中的例子来分析一下这几个术语:
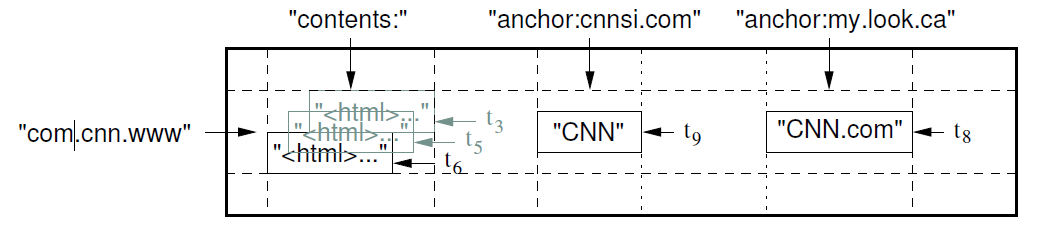
图中,是一个存储网页的例子,Bigtable是一个有序的字典(key value pair),key是 (row:string, column:string, time:int64), value则是任意的string。
在网页存储这个例子中,row是URL(倒过来的URL,为了让同一个网站的网页尽量存放在一起)。column则是由colune family:qualifier组成,上图中,contens、anchor都是colume family,一个colume family下面可以包含一个到多个colume。time则是不同时刻的版本,基于time,bigtable提供了不同的垃圾回收策略:only last n、only new enough。
Bigtable是结构化(Structured)数据,colume family在定义表(table)的时候就需要创建,类似关系型数据库。colume family一般数量较少,但colume family下面的colume是动态添加的,数量可以很多。针对上面的例子,有的文章可能只有一个作者,有的文章可能好几个作者,虽然都有anchor这colume family,但是所包含的colume数量是不一样的,这也是称之为Sparse的原因。
Bigtable存储
Bigtable是一个分布式存储,可伸缩性(scalability)是首先需要解决的问题,那么Bigtable是如何分片(partition)的呢。
tablet是Bigtable中数据分片和负载均衡的基本单位(the unit of distribution and load balancing.),大小约为100M到200M,其概念等价于GFS、MongoDB中的chunk。简单来说,就是由连续的若干个row组成的一个区块,BIgtable维护的是tablet到tablet server的映射关系,当需要迁移数据的时候,也是与tablet为单位。
tablet采用的是range-based的分片方式,相近的row会被划分在同一个tablet里面,range based对于范围查询是非常友好的,比如上面网页存储的例子,同一个网站的网页会被尽量放在一起。但是range based容易在写入的时候流量导入到同一个tablet,需要额外的split来达到均衡。
tablet内部采用了类似LSM(log-Structured merge)Tree的存储方式,有一个memtable与多个sstable(sorted string table)组成,如下入所示:
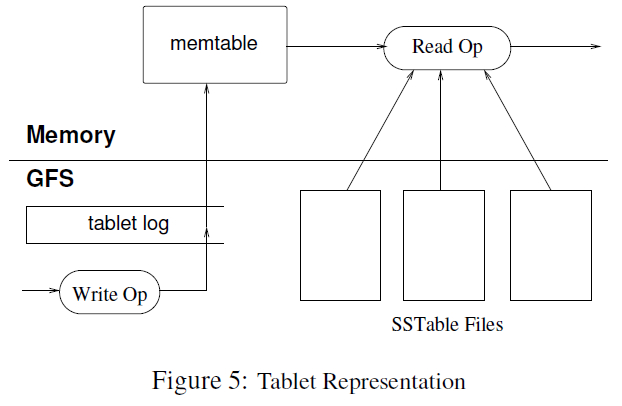
上图分解出了哪些数据是维护在内存中,哪些是持久化到GFS。可以看到memtable是内存中的数据结构,而write ahead log、sstable则会持久化到GFS。
对于memtable,理解比较简单,就是一个有序的dict,memtable的数据量到达一定情况下的时候就会以sstable的形式写入到GFS。
sstable定义如下:
a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings
因此也是顺序存储的,sstable是bigtable数据物理存储的基本单位。在sstable内部,一个sstable包含多个block(64kb为单位),block index放在sstable末尾,open sstable的时候block index会被加载到内存,二分查找block index就能找到需要的block,加速磁盘读取。在特殊情况下,sstable也是可以强制放在内存的。
写操作较为简单,写到memtable就可以了。而对于读操作,则需要merge memtable与SSTable中的数据:
A valid read operation is executed on a merged view of the sequence of SSTables and the memtable.Since the SSTables and the memtable are lexicographically sorted data structures, the merged view can beformed efciently.
由于写入是在内存中,那么查询的时候,对于某个key,有可能在memtable中,也有可能在sstable中,而且在哪一个sstable中还是不一定的。举个简单的例子,假设一个tablet包含memtable和两个sstable(第一个sstable比第二个sstable先生成)
第一个sstable
a
k
z
第二个sstable
b
g
y
memtable
c
k
w
查找任何一个key时,需要以(memtable、第二个stable、第一个sstable)的顺序查找。比如对于key k,在memtable中找到就可以返回了(虽然第一个sstable也有一个k);对于key g,首先找memtable不命中,然后在第二个sstable命中;对于key m,则查找完所有sstable之后才能知道都不会命中。为了加速查找过程,采用了两种技术,compaction、bloom filter,前者减少了一次查找读取sstable的量,后者可以避免在key不存在的时候,无需检查memtable与sstable。
compaction有几个层次:
minor compaction: When the memtable size reaches a threshold, the memtable is frozen, a new memtable is created, and the frozen memtable is converted to an SSTable and written to GFS.
merging compaction: reads the contents of a few SSTables and the memtable, and writes out a new SSTable.
major compaction: A merging compaction that rewrites all SSTables into exactly one SSTable
对于LSM-tree的详细介绍,可以参考DDIA(design data-intensive applications)
Bigtable系统架构
在论文的build blocks部分,提到了Bigtable使用到的其他组件(服务),其中最重要的就是GFS与Chubby,而Bigtable内部又分为三部分:Master,tablet server, client。因此整体架构如下图(来自slideshare)

Chubby vs master
在Bigtable中,Chubby提供了以下功能:
- to ensure that there is at most one active master at any time; --》任意时刻只有一个master
- to store the bootstrap location of Bigtable data (see Section5.1); --》元数据的起始位置
- to discover tablet servers and finalize tablet server deaths; --》tablet server的生命周期监控
- to store Bigtable schema information (the column family information for each table);
- and to store access control lists.
前三点,在一个独立的分布式存储系统(GFS MongoDB)中,应该都是由元数据服务器提供,但在Bigtable中,这部分功能都已到了Chubby,简化了master本身的设计。
那master的职责就主要是:
- assigning tablets to tablet servers,
- detecting the addition and expiration of tablet servers
- balancing tablet-server load
- garbage collection of files in GFS.
- In addition, it handles schema changes such as table and column family creations.
在经典论文翻译导读之《Google File System》一文中,作者总结到:
分布式文件系统常用的架构范式就是“元数据总控+分布式协调调度+分区存储”。
可以看出这个范式里的两个角色——协调组件、存储组件。协调组件负责了元数据总控+分布式协调调度,各存储组件作为一个分区,负责实际的存储结构和本地数据读写
在Bigtable中,Chubby负责了元数据总控,master负责分布式协调调度。
元数据管理 tablet location
上面提到,Chubby负载元数据总控,那所有tablets的位置信息全都放在Chubby上?显然是不现实的。
事实上,系统采用了类似B+树的三层结构来维护tablet location信息
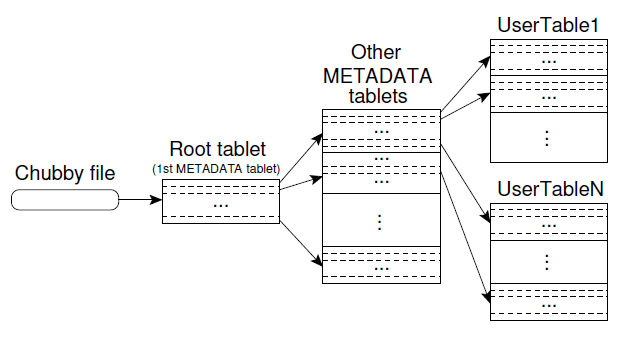
The first level is a file stored in Chubby that contains the location of the root tablet. The root tablet contain the location of all tablets in a special METADATA table.Each METADATA tablet contains the location of a set of user tablets.
可见,Chubby中存储的只是root tablet的位置信息,数据量很少。在Root tablet里面,维护的是METADATA tablets的位置信息;METADATA tablet存储的则是应用的tablet的位置信息。
系统也做了一些工作,来减轻存储METADATA tablets 的 tablet server的负担,首先METADATA tablet对应的sstable存储在内存中,无需磁盘操作。其次,bigtable client会缓存元数据信息,而且会prefetch元数据信息,减少交互。
The client library caches tablet locations.
further reduce this cost in the common case by having the client library prefetch tablet locations
单点master
在上图中可以看出,Bigtable中,master是无状态的单点,无状态是指master本身没有需要持久化的数据。而单点需要面对的问题是单点故障(single point of failure)
首先,master的负载并不高,最重要的原因是,Bigtable client并不与master直接交互(这归功于master并不维护系统元数据)。而tablets的管理,如创建、迁移,本身就不是高频操作。
其次,即使master fail(由于crash或者network partition),系统会创建新的master,并在内存中恢复元数据(tablets到tablet server的映射、尚未分配的tablets)。步骤如下:
- The master grabs a unique master lock in Chubby, which prevents concurrent master instantiations.
- The master scans the servers directory in Chubby to find the live servers.
- The master communicates with every live tablet server to discover what tablets are already assigned to each server.
- The master scans the METADATA table to learn the set of tablets. Whenever this scan encounters a tablet that is not already assigned, the master adds the tablet to the set of unassigned tablets, which makes the tablet eligible for tablet assignment.
注意第三 四步,元数据既来自tablet server,又来自METADATA table。一方面是存在有一些尚未分配的tablets(如迁移产生的、talets server故障导致的),这部分只存在于METADATA table;另一方面,tablet server中一定是当前时刻的准确信息。
Bigtable lessons
作为一个划时代的、开创性的、应用广泛的分布式系统,Bigtable无论在设计、实现、应用中都会遇到很多问题,有很多指的思考、借鉴的地方,他山之石可以攻玉。Bigtable自己总结如下:
(1)万万没想到的失败和异常
除了大家耳熟能详的网络分割(network partition)和节点故障(fail stop)模型,Bigtable还遇到了:
- memory and network corruption,
- large clock skew,
- hung machines,
- extended and asymmetric network partitions,
- bugs in other systems that we are using (Chubby for example),
- oveflow of GFS quotas
- and planned and unplanned hardware maintenance.
(2)三思而后行,不要过度设计
Another lesson we learned is that it is important to delay adding new features until it is clear how the new features will be used.
先搞懂需求背后用户希望解决的真正问题,有时候需求是假象,需要先挖掘本质
(3)监控的重要性
the importance of proper system-level monitoring(i.e., monitoring both Bigtable itself, as well as the client processes using Bigtable).
不能同意更多,特别是现在服务化、微服务甚嚣尘上,没有完善的监控让系统的运维苦不堪言。特别是作为各种框架、引擎,完善的监控更是不可或缺。
(4)简化设计
The most important lesson we learned is the value of simple designs.
在Google三大件(MapReduce、GFS、Bigtable)都提到了这一点,simple design意味着更好的维护性,更少的边界条件。不过坦白的说,没有涉及过复杂的系统,是很难体会到"Simple is Better Than Complex"。
杂项
事务支持
分布式系统中,分布式事务会影响到性能、可用性,因此大多只提供单行原子性操作,bigtable中也是如此
Every read or write of data under a single row key is atomic (regardless of the number of different columns being read or written in the row)
locality group
client指定多个colume family形成一个group,locality group单独存成一个sstable,而且locality group还可以强制保存在内存中,如前面提到的METADATA tablets。
group使用单独的sstable存储就使得Bigtable事实上使用了colume based storage,这对于批处理程序或者OLAP非常有用。
Bigtable locality groups realize similar compression and disk read performance benefits observed for other systems that organize data on disk using column-based rather than row-based storage
Merged commit log
为了减轻GFS的负担,加快commit log 写入的速度,tablet server并不是为每一个tablets维护一个commit log,而是一个tablet server上的所有tablets公用一个commit file。
但公用的commit log在tablets recover的时候就不又好了,假设某个Tablet server故障,其上维护的诸多tablets会被迁移到其他tablet server上,多个目标tablet server都需要读取这个commit log文件来恢复tablets的状态。显然,都来读取这个文件是不切实际的,bigtable采取了先对commit log并行归并排序的算法,让关联的数据集中。
We avoid duplicating log reads by first sorting the commit log entries in order of the keys <table; row name; log sequence number>.
In the sorted output, all mutations for a particular tablet are contiguous and can therefore be read efficiently with one disk seek followed by a sequential read.
references
Bigtable: A Distributed Storage System for Structured Data
understanding-hbase-and-bigtable
undestand-google-bigtable-is-as-easy-as-playing-lego-bricks-lecture-by-romain-jacotin
design data-intensive applications


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)