
生产环境 direct path read 与log file sync等待事件问题处理
1. 2018-09-26 前7天awr报告(此期间 oracle 使用率为 4,022.34/6,179.76/24=2.71%)
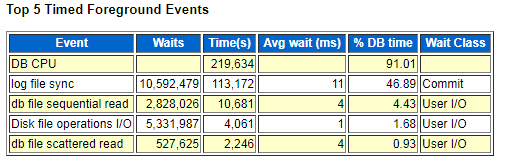
由此看出最显著问题是 log file sync 等待事件,查看后台等待事件伴随着 log file parallel write 等待事件也相对较高,初步判断此数据库操作系统I/O使用率较高,通过windows 任务管理器 查看 此时 IO 为100k/s-2M/s之间 性能监视器中 oracle 进程平均读字节为4M/s(包含网络)写字节仅10-30K/s 磁盘利用率在50%以上
2.2018-10-09 23:00 进行数据库服务器重启操作
3.2018-10-10 9:00 获取2018-10-10 00:00 2018-10-10 07:00 awr报告(此期间oracle使用率为 866.78/480.61/24=7.51%)
此时:
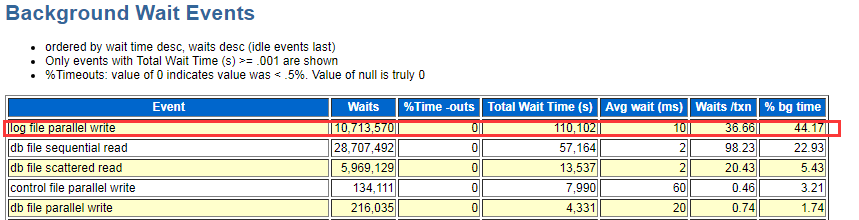
此时top5 等待事件中依然是 log file sync 占据较高,但是出现了direct path read 等待事件 通过windows 任务管理器 查看 此时 IO 为80M/s-120M/s之间 性能监视器中 oracle 进程平均读字节为4M/s(包含网络)写字节仅10-30K/s 磁盘利用率在100%
传送门:Wait Event "direct path read "
1>问题分析
1.1) 一般来说,数据块BLOCK(即ORACLE的最小存储单元)总是先由后台服务器进程缓冲至buffer cache,而后才被服务器进程获取。但对于一些大表,将其缓冲至buffer cache势必会将buffer cache中的许多其它对象挤出,即ageing out。为了避免这一情况,oracle产生了direct path read,即不需要缓冲到缓存区,而是直接由服务器进程从磁盘获取。
1.2)通过查看segment by direct physical reads获取哪些对象direct path read等待高
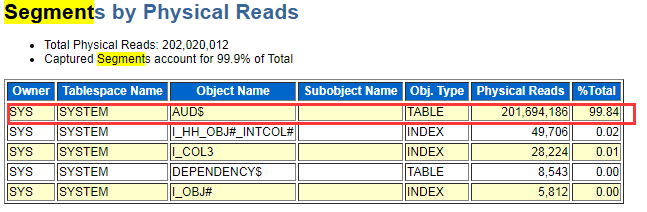
1.3)查出发现AUD$对象物理读占了整个物理I/O的98.84%的资源,我们再数据库中查看 table 对象AUD$ (查找资料发现此对象是oracle 审计功能的底层视图,记录了所有用户对oracle操作的信息)

1.4)那么我们再研究下在AUD$对象上进行了什么操作导致此严重等待(查看sql order by reads)

1.5)分析发现逻辑读与物理读占比异常的均为 d15cdr0zt3vtp 获取此sql的详细信息,不难发现此sql就是AUD$对象
SELECT TO_CHAR(current_timestamp AT TIME ZONE 'GMT',
'YYYY-MM-DD HH24:MI:SS TZD') AS curr_timestamp,
COUNT(username) AS failed_count
FROM sys.dba_audit_session
WHERE returncode != 0
AND TO_CHAR(timestamp, 'YYYY-MM-DD HH24:MI:SS') >=
TO_CHAR(current_timestamp - TO_DSINTERVAL('0 0:30:00'),
'YYYY-MM-DD HH24:MI:SS')
1.6)在此sql的wehere条件中有 “!=”、“>=”等限制条件,很可能引起全表扫描,再查询一下AUD$对象的数据量,此对象共计342812M/1024=334G (此表中有3亿+条数据)
SELECT *
FROM (SELECT SEGMENT_NAME, SUM(BYTES) / 1024 / 1024 MB
FROM DBA_SEGMENTS
GROUP BY SEGMENT_NAME
ORDER BY 2 DESC)
WHERE SEGMENT_NAME='AUD$'

1.7)确认此审计数据没用后可定期进行清理 ( truncate table sys.aud$ ) (操作时间 2018-10-11 10:21) truncate 后 磁盘I/O从100M+/s 降至1M-/s
清理前后可以使用以下SQL对比表空间使用率:
select
b.tablespace_name "表空间",
b.bytes/1024/1024 "大小M",
(b.bytes-sum(nvl(a.bytes,0)))/1024/1024 "已使用M",
substr((b.bytes-sum(nvl(a.bytes,0)))/(b.bytes)*100,1,5) "利用率"
from dba_free_space a,dba_data_files b
where a.file_id=b.file_id
and b.tablespace_name='SYSTEM'
group by b.tablespace_name,b.file_name,b.bytes
order by b.tablespace_name;
注:
1. oracle 11gr2的审计功能默认是打开的,但是由于默认状况下是会审计所有账号的登入和登出的,这就使得审计日志的数据量非常大.
2.可以取消登陆与登出审计来使审计日志数据增长变慢
SQL> noaudit connect;
1.8)
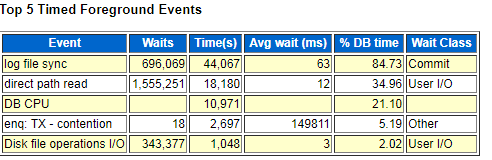
获取2018-10-11 11点到13点之间的awr报告Top 5等待事件,我们发现direct path read 等待事件已经消失了,并且 log file sync 等待事件显著下降 说明log file sync等待事件是由之前的全表扫描导致I/O紧张引起的
此图等待较高的还有 Disk file operations I/O 等待事件,那么我们来了解一下此等待事件
传送门:Wait Event "Disk file operations I/O"
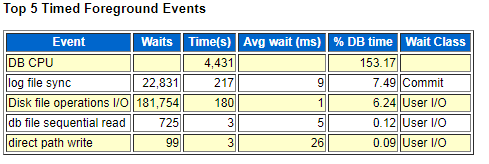
至此,log file sync 等待事件是由于硬件性能保持在9ms等待;同时再此记录该库log file sync、Disk file operations I/O 、log file parallel write等待事件时间分布表,便于后期对比观察性能是否提升
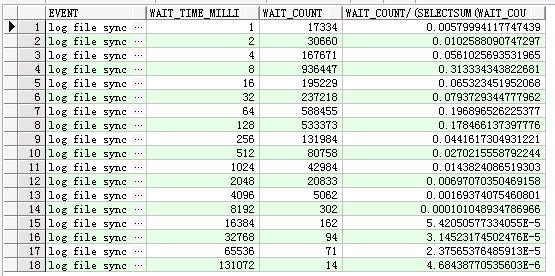
log file sync
select event, wait_time_milli,wait_count, wait_count/(select sum (wait_count) from v$event_histogram where event = 'log file sync' ) from v$event_histogram where event = 'log file sync';
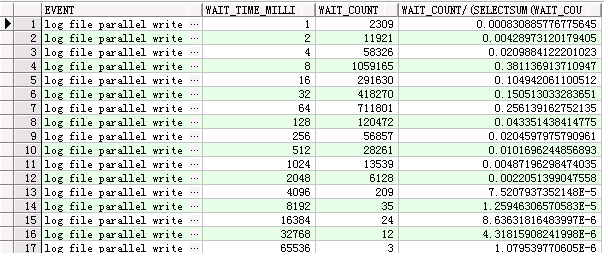
log file parallel write
select event, wait_time_milli,wait_count, wait_count/(select sum (wait_count) from v$event_histogram where event = 'log file parallel write' ) from v$event_histogram where event = 'log file parallel write';
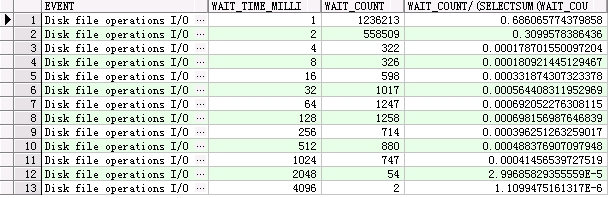
Disk file operations I/O
select event, wait_time_milli,wait_count, wait_count/(select sum (wait_count) from v$event_histogram where event = 'Disk file operations I/O' ) from v$event_histogram where event = 'Disk file operations I/O';
Direct Path Read
select event, wait_time_milli,wait_count, wait_count/(select sum (wait_count) from v$event_histogram where event = 'direct path read' ) from v$event_histogram where event = 'direct path read';
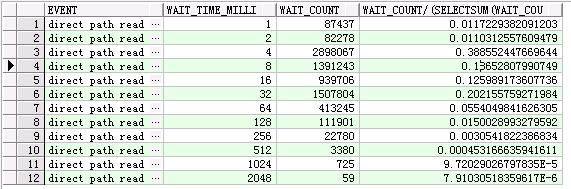
via:
https://blog.csdn.net/haojiubujian920416/article/details/81222523
https://blog.csdn.net/mjj291268154/article/details/49935205
https://www.linuxidc.com/Linux/2015-09/122732.htm
https://www.cnblogs.com/6yuhang/p/5923914.html
https://blog.csdn.net/ljunjie82/article/details/52051066

 浙公网安备 33010602011771号
浙公网安备 33010602011771号