
Hadoop学习6--里程碑式的开始之执行第一个程序wordcount
一、先在HDFS文件系统创建对应的目录,具体如下:
1、待处理文件存放目录
/data/wordcount(之所以创建wordcount,是为了对文件分类,对应本次任务名)
命令:hadoop fs -mkdir -p /data/wordcount (-p是同时创建子目录)
2、存放输出文件目录
/output
命令:hadoop fs -mkdir /output
tip:也可以在已连接了集群的eclipse里建立,即:Map/Reduce Location里
不过这种方式建立的文件,所有者是本机,不是我安装hadoop的用户,是否可用,需要验证下。
3、验证以上的成果:
命令:hadoop fs -ls /
二、自己在本地文件系统(也就是某一个目录下)手动创建一个文件,用于测试
1、创建文件
命令:vi ~/test/inputword(vi命令有意思,如果文件不存在,会自动创建一个空文件)
2、打开文件、手动写入一些测试内容:
hello my
hello master
what slave
hello slave
保存。
3、将该文件上传到hdfs文件系统:
命令:hadoop fs -put ~/test/inputword /data/wordcount/
验证方式:
命令:hadoop fs -text /data/wordcount/inputword
三、运行吧
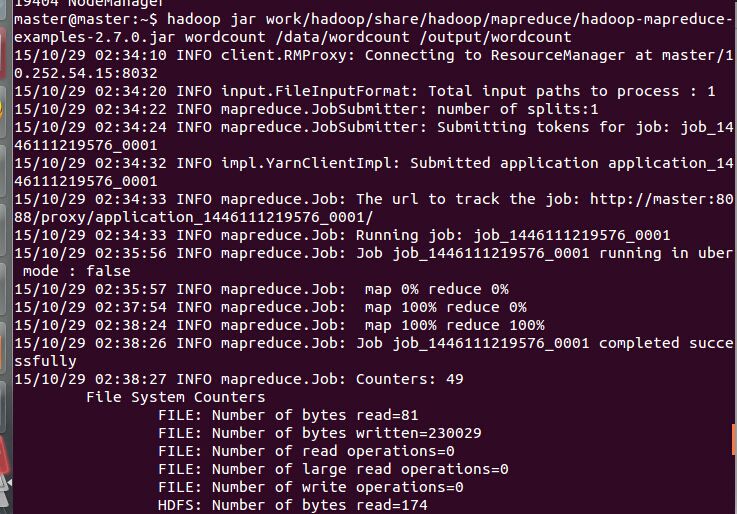
命令:hadoop jar /work/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount /data/wordcount /output/wordcount
tip:
1、注意jar包的路径一定要写对,否则会提示找不到jar包
2、遇到个问题,一直提示重试连接服务器master:
15/10/29 02:26:38 INFO ipc.Client: Retrying connect to server: master/xx.xx.xx.xx:8032. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
网上查了下,说是端口还是什么的,这个8032并不是我配置的,和他有关系的可能性不大。
不过其中一句话引起了我的联想,他提到了连接不上JobTacker云云
突然想起来,由于在启动hadoop集群的时候,提示start-all.sh已过时,于是使用的start-dfs.sh
这样在启动后,使用jps验证服务,是少几个的,只有两个namenode,一个datanode和一个默认的jps
于是重新执行了一次 start-all.sh
然后重新运行,成功。
Nice!
把结果截图放上来吧!
四、验证:
命令:-text /output/wordcount/part-r-00000
结果就是对单词出现个数的统计,略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号