
python爬爱奇艺电视剧及剧集链接
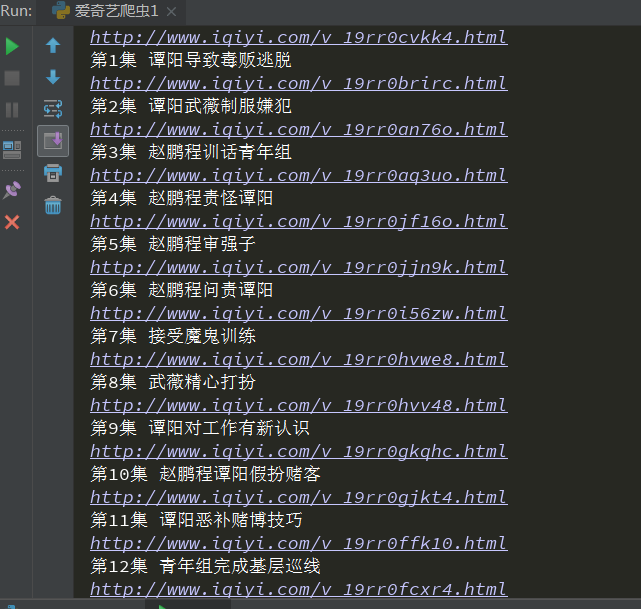
爬取的显示结果如下:
话不多说,下面是python代码。。。。。。。。。。。。。。。
1 import requests 2 import re 3 from bs4 import BeautifulSoup 4 import json 5 6 if __name__ == '__main__': 7 8 for i in range(1,10):#翻页数可自行选择 9 #获取URL,并自动翻页 10 url = 'http://list.iqiyi.com/www/2/-------------11-'+str(i)+'-1-iqiyi--.html' 11 12 headers = { 13 'Access-Control-Allow-Credentials': 'true', 14 'Cache-Control': 'max-age=900', 15 'Content-Encoding': 'gzip', 16 'Content-Language': 'zh-CN', 17 'Content-Type': 'text/html; charset=UTF-8', 18 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36', 19 'Referer': 'http://list.iqiyi.com/www/2/-------------11-4-1-iqiyi--.html', 20 'Upgrade-Insecure-Requests': '1' 21 } 22 target = requests.get(url=url,headers=headers).text 23 #爬取爱奇艺电视剧总网页,解析HTML网页 24 soup = BeautifulSoup(target,'html.parser') #html.parser解析HTML网页 25 returnSoup = soup.find_all("div", attrs={"class": "wrapper-piclist"})[0] 26 returnSoup1= str(returnSoup).replace('\r\n','').replace('\n','').replace(' ','').replace('"rseat="bigTitle','') 27 href_title = re.findall('"data-widget-qidanadd="qidanadd"href="(.*?)"target="_blank"title=".*?"><imgalt="(.*?)"height="236"rseat="dsjp7"src=',str(returnSoup1)) 28 29 30 for i in href_title: 31 href=i[0] 32 title=i[1] 33 34 #转到某个电视剧链接网页,并解析 35 href1=str(href).split('#')[0] 36 url2=href1 37 target2 = requests.get(url=url2).text 38 soup2 = BeautifulSoup(target2,'html.parser') 39 returnsoup2 = soup2.find_all('div',attrs={'class':'site-piclist_pic'}) 40 41 #用正则表达式获取剧集链接 42 result2 = re.findall('(?<=href=\").*?(?=\")',str(returnsoup2)) 43 #用正则表达式获取剧集名称 44 title2 = re.findall('(?<=title=\").*?(?=\">)',str(returnsoup2)) 45 j=len(title2) 46 #输出爬取结果 47 for i in range(1,j-2): 48 str1='第'+str(i)+'集' 49 print(result2[i]) 50 print(str1,title2[i])

