python进阶一-数据结构与算法
1.关于序列转为固定变量的问题
假设存在如下一个序列,需要将对应的值赋值给相应的变量a, b, c, d
sep = [1, 2, 5, 8]
我们可以将序列中的元素分别对应变量(变量个数与序列个数一致)即可。
a, b, c, d = sep
print(a)
print(b)
print(c)
print(d)
1
2
5
8
如果我们的变量数量大于序列中元素时,会发生ValueError: not enough values to unpack (expected 5, got 4)错误
a, b, c, d, e = sep
ValueError: not enough values to unpack (expected 5, got 4)
如果我们的变量数量小于序列中元素时,会发生ValueError: too many values to unpack (expected 3)
a, b, c = sep
ValueError: too many values to unpack (expected 3)
当我们需要序列中的部分元素时,我么可以使用_来对不需要的元素进行占位
a, b, c, _ = sep
print(a)
print(b)
print(c)
1
2
5
2.关于可迭代对象(序列)转为不固定变量的问题
假设存在如下的序列
sep = [1, 2, 5, 8, 12, 28]
如果我们需要获取第一个和最后一个元素以及除了第一个和最后一个的元素的中间元素,我们可以使用*获取多参数,但是需要注意的是*获取的参数返回的都是列表,不管里面是否存在元素。
a, *args, b = sep
print(a, args, b)
1 [2, 5, 8, 12] 28
对于*来说,*后的参数代表的是多变量,单个变量只能代表一个参数,除此之外, *后面不仅可以跟需要获取的普通变量,也可以跟_忽略此变量,例如获取第一个和第二个元素等。
a, *_, b = sep
print(a, b)
1 28
*是为了针对于解压可迭代对象中元素个数不固定的情况下而设计的。
3.保留数据中的有限的数据(例如读取文件的最后十行)
假设我们使用faker随机生成1000条数据并存入文档
from pathlib import Path
from faker import Faker
file_path = Path(__file__).parent.joinpath("test_data.txt")
def generate_random_data(file_path: str):
faker_obj = Faker(locale="zh_CN")
with open(file_path, mode="w", encoding="utf-8") as w_f:
for i in range(1000):
w_f.write("{}{}".format(faker_obj.address(), "\n"))
generate_random_data(file_path)
我们需要取这个文件的最后十行数据,类似于tail的功能,一般我们可能会使用列表进行增删,但是相对会耗时不少,此处使用collections.deque进行处理。
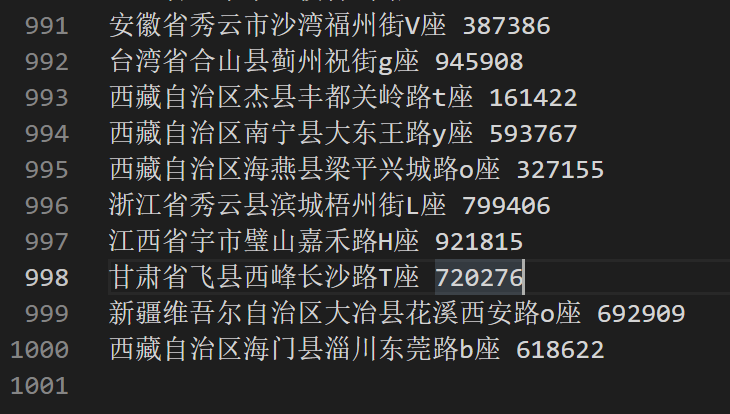
如下为文件的最后十行数据
from collections import deque
from pathlib import Path
file_path = Path(__file__).parent.joinpath("test_data.txt")
def read_file_part_data(file_path: str, line_length: int = 10):
deque_obj = deque(maxlen=line_length)
with open(file_path, mode="r", encoding="utf-8") as r_f:
for line in iter(lambda: r_f.readline(), b''):
if not line:
break
deque_obj.append(line)
return deque_obj
print(read_file_part_data(file_path))
deque(['安徽省秀云市沙湾福州街V座 387386\n', '台湾省合山县蓟州祝街g座 945908\n', '西藏自治区杰县丰都关岭路t座 161422\n', '西藏自
治区南宁县大东王路y座 593767\n', '西藏自治区海燕县梁平兴城路o座 327155\n', '浙江省秀云县滨城梧州街L座 799406\n', '江西省宇市璧山
嘉禾路H座 921815\n', '甘肃省飞县西峰长沙路T座 720276\n', '新疆维吾尔自治区大冶县花溪西安路o座 692909\n', '西藏自治区海门县淄川东
莞路b座 618622\n'], maxlen=10)
总结:
collections.deque适用于保留有限的数据,因为它当插入数据大于长度时,会自动舍弃旧的数据,因此不会出现溢出的情况。- 在队列两端插入或删除元素时间复杂度都是 O(1) ,区别于列表,在列表的开头插入或删除元素的时间复杂度为 O(N) 。
4.查找最大或最小的元素
假设存在如下数据,需要查找最大的元素和最小的元素
data = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
这里我们可以使用先排序后再切片
data = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
def get_max_or_min_data(data, max_length, min_length):
data = sorted(data)
max_data = data[-1 : -max_length - 1 : -1]
min_data = data[:min_length:1]
return max_data, min_data
print(get_max_or_min_data(data, 3, 3))
([42, 37, 23], [-4, 1, 2])
除此之外,也可以使用heapq堆中的nlargest获取最大的元素,nsmallest获取最小的元素
from heapq import nlargest, nsmallest
data = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
def get_max_or_min_data(data, max_length, min_length):
return nlargest(max_length, data), nsmallest(min_length, data)
print(get_max_or_min_data(data, 3, 3))
如果出现较为复杂的比较大小的规则呢,例如下面的字典, 依据字典中的prices关键字进行大小的比较。
data = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65},
]
只需要对比较时候的规则进行匹配就可以了
def get_max_or_min_data(data, max_length, min_length):
data = sorted(data, key=lambda n: n['price'])
max_data = data[-1 : -max_length - 1 : -1]
min_data = data[:min_length:1]
return max_data, min_data
print(get_max_or_min_data(data, 3, 3))
([{'name': 'AAPL', 'shares': 50, 'price': 543.22}, {'name': 'ACME', 'shares': 75, 'price': 115.65}, {'name': 'IBM', 'shares': 100, 'price': 91.1}], [{'name': 'YHOO', 'shares': 45, 'price': 16.35}, {'name': 'FB', 'shares': 200, 'price': 21.09}, {'name': 'HPQ', 'shares': 35, 'price': 31.75}])
当然使用堆亦是如此
from heapq import nlargest, nsmallest
def get_max_or_min_data(data, max_length, min_length):
return nlargest(max_length, data, key=lambda n: n['price']), nsmallest(
min_length, data, key=lambda n: n['price']
)
print(get_max_or_min_data(data, 3, 3))
比较大小其实还有两个内置方法max和min,不过,它们只能获取一个最大或者最小的元素,比较局限。
那么这两种方法分别适用于什么场景,或者说在哪些情况下性能会更好呢?
一般而言对于获取最大的元素较多时或者说数量快要接近集合的数量时,一般建议使用先排序后切片的方式, 其实选择哪种方式还需要取决于元素的排序是否正常。
5.实现优先级队列
优先级队列,顾名思义,就是依据优先级进行任务的调度,优先级可以是从小到大,也可以是从大到小,依据python中的heapq堆模块的最小堆特性,可以将队列变为堆,然后使用heappop进行最小元素的获取,默认是元素越小,优先级越高,当然如果想要反过来,只需要添加一个负号即可,需要注意的是对于相同优先级的元素,除了设置优先级的大小,最好再设置一个插入顺序作为第二比较项,目前发现在python3.10以后,会自动依据插入顺序进行排序。
from heapq import heappush, heappop
class PriorityQueue(object):
def __init__(self) -> None:
self._queue = []
self._index = 0
def push(self, priority, item):
# heappush(self._queue, (priority, self._index, item))
heappush(self._queue, (priority, item))
print(f"queue:{self._queue}")
def pop(self):
return heappop(self._queue)
p_queue = PriorityQueue()
p_queue.push(1, "func1")
p_queue.push(2, "func2")
p_queue.push(3, "func3")
p_queue.push(1, "func4")
p_queue.push(1, "func5")
print(p_queue.pop())
print(p_queue.pop())
print(p_queue.pop())
print(p_queue.pop())
print(p_queue.pop())
6.字典中的键对应多个值
从这个题目来看,如果是一个键对应多个普通的值看起来是不可能的,这就需要使用到列表、集合、元组了,不过使用元组的话,就无法进行值的增加删除了,对于选择列表还是集合,分两种情况。
- 1.当需要保持原有的顺序时,建议使用列表
- 2.当需要进行去重时,建议选择集合
d = {"a": [1, 2, 3], "b": {1, 2, 3}}
当然,除了上述的固定的方法,我们也可以动态的去构建字典映射多个值,这里我们使用collections.defaultdict去实现,defaultdict会自动创建对应的key映射的值的类似,这样就可以只关注插入的元素。
from collections import defaultdict
data = [("a", 1), ("b", 2), ("c", 3), ("a", 2), ("c", 2)]
d = defaultdict(list)
for key, val in data:
d[key].append(val)
print(d)
defaultdict(<class 'list'>, {'a': [1, 2], 'b': [2], 'c': [3, 2]})
由此可见,defaultdict将对应的key中元素组成了列表,当然除了这个方法,还可以使用字典自带的setdefault方法, 需要初始化一个新的字典,默认将所有字典的值设置为列表。
data = [("a", 1), ("b", 2), ("c", 3), ("a", 2), ("c", 2)]
d = {}
for key, val in data:
d.setdefault(key, []).append(val)
print(d)
7.字典排序
当我们想要控制字典的顺序时,一般会使用到collections.OrderedDict:有序字典,它可以记录字典值插入的时候的顺序,但是在python3.7之后,默认的dict默认就是支持记录插入顺序的。
from collections import OrderedDict
d = OrderedDict()
d["a"] = 1
d["b"] = 2
d["c"] = 3
d["d"] = 4
for k, v in d.items():
print(k, v)
d = {}
d["a"] = 1
d["b"] = 2
d["c"] = 3
d["d"] = 4
for k, v in d.items():
print(k, v)
上述两个结果是一致的,OrderedDict内部维护着一个根据键插入顺序排序的双向链表, 由于这一特性,内存占用是普通字典的两倍,因此需要考虑内存消耗,但是如果是较为新的python版本,此方法不建议使用。
8.字典的运算
有时候可能需要根据字典的值进行排序,取最大最小值等操作,这时候就需要使用到字典的运算,那么字典如何运算呢,正常情况下对字典的操作默认是对键的操作,需要对值操作,可以使用values方法,但是此方法没有键,可以使用items方法,但默认还是以键操作,那么我们可以将keys和values中的值进行一一对应并反转不就可以了吗?
假设存在如下数据:
prices = {
'ACME': 45.23,
'AAPL': 612.78,
'IBM': 205.55,
'HPQ': 37.20,
'FB': 10.75
}
反转键和值进行获取最大值
data = zip(prices.values(), prices.keys())
print(max(data))
(612.78, 'AAPL')
对字典进行排序, 以value为键进行排序
data = sorted(prices.items(), key=lambda n: n[1])
print(data)
[('FB', 10.75), ('HPQ', 37.2), ('ACME', 45.23), ('IBM', 205.55), ('AAPL', 612.78)]
9.查找字典的相同点
假设存在如下两个字典,我们需要取出字典中的相同键的元素
a = {
'x' : 1,
'y' : 2,
'z' : 3
}
b = {
'w' : 10,
'x' : 11,
'y' : 2
}
查找相同元素或者不同元素,第一点可以想到集合,集合中的交并可以获取相同或者不同元素。
a = {'x': 1, 'y': 2, 'z': 3}
b = {'w': 10, 'x': 11, 'y': 2}
set_a = set(a.items())
set_b = set(b.items())
print(set_a)
print(set_b)
print(set_a & set_b)
print(set_a | set_b)
print(set_a ^ set_b)
上述可以使用字典的items()获取key和val,默认情况下是对字典的key进行操作,当然这个仅仅限于单层的字典形式,对于多层的字典形式是不适用的,需要对于字典进行递归遍历对比才可以。
10.删除序列中的相同元素并保持原有顺序(去重)
对于可哈希对象
假设存在如下的包含吃的重复元素的列表需要进行去重并保持顺序:
a = [1, 5, 2, 1, 9, 1, 5, 10]
去重,我们第一想法便是手动遍历取去重,不仅可以去重还可以保持顺序,如下:
def fun1(data):
ret = []
for item in data:
if ret.count(item) == 0:
ret.append(item)
return ret
print(fun1(a))
[1, 5, 2, 9, 10]
当然我们可能也会想到使用集合直接去重,但是集合默认去重时会进行排序,导致原有的顺序发生变化,但是可以使用如下方法进行去重, 使用集合+生成器实现。
def fun2(data):
ret = set()
for item in data:
if item not in ret:
yield item
ret.add(item)
print(list(fun2(a)))
对于不可哈希对象
假设存在如下列表嵌套字典,需要对其中的重复元素进行删减
data = [{'x': 1, 'y': 2}, {'x': 1, 'y': 3}, {'x': 1, 'y': 2}, {'x': 2, 'y': 4}]
同样这上述的第一种方法也可以实现, 然而第二种方法则会显示如下错误:
TypeError: unhashable type: 'dict'
由此可见集合中插入的元素必须是可哈希对象,字典是不可哈希对象,因此需要将字典转换为可哈希对象处理,最接近于字典的可哈希对象就是元组。
def fun2(data, key=None):
seen = set()
for item in data:
val = item if key is None else key(item)
if val not in seen:
yield item
seen.add(val)
print(list(fun2(data, key=lambda d: (d["x"], d["y"]))))
添加类似于sorted的key来做条件选择
使用场景
1.例如需要对文件中的重复行进行去除时,就需要删除相同的元素而保持顺序。
11.命名切片
在以往我们可能在进行字符串切割,文本切割的过程中会使用到切片进行截取,我们可能会直接使用对应的数字进行切片,可能一开始不会怎么样,但是到后期再回来看那段切片时可能也会比较困惑,切片切的是什么,尤其是在使用切片较多的情况下,因此我们可以将切片对象指定为某一个与之相关的对象,切片直接调用此对象即可,这样会方便后期维护与可视化。如下:
a = [12, 1, 34, 98, 102, 45]
slice_obj = slice(1, 10, 2)
print(a[slice_obj])
你也可以将切片对象映射到固定大小的序列中,会自动匹配边界,防止溢出。
data = "hello, world"
a = slice(2, 50, 2)
# 自动匹配到序列的最大范围
a_indice = a.indices(len(data))
print(a_indice)
print(type(a_indice))
# 将元组进行解包适应range中参数
for i in range(*a_indice):
print(data[i])
(2, 12, 2)
<class 'tuple'>
l
o
o
l
12.输出序列中次数出现最多的元素?
假设我们存在如下序列
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
'my', 'eyes', "you're", 'under'
]
乍一看,我们的第一想法可能就是遍历获取,首先获取所有元素的出现此处,再选择次数出现最多的元素 代码如下:
def fun(data):
max = {}
for item in data:
if max.get(item, None) is not None:
max[item] += 1
else:
max.setdefault(item, 1)
return max
ret = fun(words)
print(ret)
ret = sorted(ret.items(), key=lambda n:n[1])
print(ret.pop()[0])
{'look': 4, 'into': 3, 'my': 3, 'eyes': 8, 'the': 5, 'not': 1, 'around': 2, "don't": 1, "you're": 1, 'under': 1}
eyes
上述方法确实做到了序列中元素个数的统计并且可以找出最多或者最少的元素,但是实现较为繁琐,可以使用collections.defaultdict进行简化
from collections import defaultdict
def fun(data):
max = defaultdict(int)
for item in data:
max[item] += 1
return max
ret = fun(words)
print(ret)
ret = sorted(ret.items(), key=lambda n:n[1])
print(ret.pop()[0])
虽然已经进行了简化,但是collection模块已经内部提供了一个统计元素个数的方法,collections.Counter(),它不仅方便了统计元素,也可以方便给出前几个最大元素等
from collections import Counter
ret = Counter(words)
print(ret)
print(ret.most_common(3))
Counter({'eyes': 8, 'the': 5, 'look': 4, 'into': 3, 'my': 3, 'around': 2, 'not': 1, "don't": 1, "you're": 1, 'under': 1})
[('eyes', 8), ('the', 5), ('look', 4)]
注意事项
Counter只适用于序列中元素为可哈希对象的情况,也就是序列中的元素都是不可变对象,对于序列中的元素是不可哈希对象,例如列表、字典时则会抛异常。
13.依据字典中的关键字进行排序
假设存在如下字典
rows = [
{'fname': 'Brian', 'lname': 'Jones', 'uid': 1003},
{'fname': 'David', 'lname': 'Beazley', 'uid': 1002},
{'fname': 'John', 'lname': 'Cleese', 'uid': 1001},
{'fname': 'Big', 'lname': 'Jones', 'uid': 1004}
]
看到排序,就想到sorted方法,依据uid对字典进行排序
data = sorted(rows, key=lambda n: n["uid"])
print(data)
除此之外,lambda可以被operator.itemgetter所替代,官方说返回一个使用操作数的 __getitem__() 方法从操作数中获取 item 的可调用对象,相当于是对字典取值,也可以传入多个参数进行排序,如下:
from operator import itemgetter
data = sorted(rows, key=itemgetter("uid"))
print(data)
一般而言,itemgetter相对于lambda是快一点。
14.排序不支持原生排序的对象
一般而言,我们进行排序时需要是相同的类型,而且对于对象的类型也有所要求,一般只能按照数字或者阿斯克码的值进行排序,对于一些非常规的例如一个实例化对象,我们该怎么处理呢?
假设存在如下的User类
class User(object):
def __init__(self, name, age) -> None:
self.name = name
self.age = age
def __repr__(self) -> str:
return f"(name:{self.name}, age:{self.age})"
user1 = User("tom", 19)
user2 = User("mike", 24)
user3 = User("david", 12)
users = [user1, user2, user3]
我们需要对user对象依据age属性进行排序
首先我们可以使用sorted+key进行排序
data = sorted(users, key=lambda n: n.age)
print(data)
[(name:david, age:12), (name:tom, age:19), (name:mike, age:24)]
上文我们说到operator.itemgetter,是针对于字典的,除此之外,还有一个attrgetter,它可以获取到类对象中的属性,当然和operator.itemgetter一样,也可以传入多个参数进行排序。
from operator import attrgetter
data = sorted(users, key=attrgetter("name"))
print(data)
15.根据字段对序列中的数据进行分组
假设有一个序列中有多个字典
rows = [
{'address': '5412 N CLARK', 'date': '07/01/2012'},
{'address': '5148 N CLARK', 'date': '07/04/2012'},
{'address': '5800 E 58TH', 'date': '07/02/2012'},
{'address': '2122 N CLARK', 'date': '07/03/2012'},
{'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'},
{'address': '1060 W ADDISON', 'date': '07/02/2012'},
{'address': '4801 N BROADWAY', 'date': '07/01/2012'},
{'address': '1039 W GRANVILLE', 'date': '07/04/2012'},
]
根据date进行分组输出, 使用itertools.groupby方法进行分组,它会自动依据其中的key对元素进行分组
from itertools import groupby
from typing import Iterator
data = groupby(rows, key=lambda n: n["date"])
print(data)
print(isinstance(data, Iterator))
for k, v in data:
print(k)
for i in v:
print(i)
<itertools.groupby object at 0x00000256968B2F70>
True
07/01/2012
{'address': '5412 N CLARK', 'date': '07/01/2012'}
07/04/2012
{'address': '5148 N CLARK', 'date': '07/04/2012'}
07/02/2012
{'address': '5800 E 58TH', 'date': '07/02/2012'}
07/03/2012
{'address': '2122 N CLARK', 'date': '07/03/2012'}
07/02/2012
{'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'}
{'address': '1060 W ADDISON', 'date': '07/02/2012'}
07/01/2012
{'address': '4801 N BROADWAY', 'date': '07/01/2012'}
07/04/2012
{'address': '1039 W GRANVILLE', 'date': '07/04/2012'}
由此可见,它将数据依据date进行分组,上述我们了解到字典可以使用operator.itemgetter来获取字典的值,来代替lambda表达式,只需要将上述的lambda n: n["date"]改为itemgetter("date")即可
注意事项
- groupby会扫描整个序列并查找key值符合要求的
连续相同的值,返回一个key值和一个可迭代对象 - 由于groupby查找的是连续的值,因此需要事先进行排序后处理
如果仅仅是想要将对于date的值进行分块到对应的value值中,可以使用上述的collections.defaultdict进行归类分组,实现如下:
from collections import defaultdict
d = defaultdict(list)
for item in rows:
d[item["date"]].append(item)
print(d)
defaultdict(<class 'list'>, {'07/01/2012': [{'address': '5412 N CLARK', 'date': '07/01/2012'}, {'address': '4801 N BROADWAY', 'date': '07/01/2012'}], '07/04/2012': [{'address': '5148 N CLARK', 'date': '07/04/2012'}, {'address': '1039 W GRANVILLE', 'date':
'07/04/2012'}], '07/02/2012': [{'address': '5800 E 58TH', 'date': '07/02/2012'}, {'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'}, {'address': '1060 W ADDISON', 'date': '07/02/2012'}], '07/03/2012': [{'address': '2122 N CLARK', 'date': '07/03/2012'}]})
groupby需要先排序再分组,返回的是迭代器,内存占用较小,但耗时相对较多,defaultdict则可以直接分组,内存占用较高,但耗时相对较少。
16.过滤序列元素
假设存在如下序列
mylist = [1, 4, -5, 10, -7, 2, 3, -1]
一看到这,我们第一时间会想到列表推导式,需要将序列中的大于0的数输出,例如
data = [item for item in mylist if item > 0]
print(data)
[1, 4, 10, 2, 3]
确实,结果也已经输出,但是内存占用较高,我们只需要将[]改为()换成生成器,就可以大大的减小内存占用,这两种方式都是针对于过滤条件相对简单的情况下,如果对于较为复杂的情况,我们可以使用内置的filter方法,并且返回的也是迭代器对象,内存占用小,如下
data = filter(lambda n: n > 0, mylist)
print(list(data))
除此之外,itertools模块中也提供了filterfalse进行过滤,不过与filter不一样的是,当前面条件为True时会舍弃元素,为False才会保留元素,相当于filter与filterfalse是一对反义词。
from itertools import filterfalse
data = filterfalse(lambda n: n < 0, mylist)
print(list(data))
可能还存在一种情况,序列中的元素过滤条件为另一个序列,相对于是一一对应的关系。
假设存在如下两个序列
addresses = [
'5412 N CLARK',
'5148 N CLARK',
'5800 E 58TH',
'2122 N CLARK',
'5645 N RAVENSWOOD',
'1060 W ADDISON',
'4801 N BROADWAY',
'1039 W GRANVILLE',
]
counts = [ 0, 3, 10, 4, 1, 7, 6, 1]
需要对上述的address依据counts是否大于一进行过滤, 这里我们使用compress进行一对一的匹配
from itertools import compress
data = compress(addresses, [item > 1 for item in counts])
print(list(data))
['5148 N CLARK', '5800 E 58TH', '2122 N CLARK', '1060 W ADDISON', '4801 N BROADWAY']
将作为条件的序列先进行条件筛选转为Bool值的序列,再与address进行条件过滤。
17.从字典中提取子集
假设存在如下字典
prices = {
'ACME': 45.23,
'AAPL': 612.78,
'IBM': 205.55,
'HPQ': 37.20,
'FB': 10.75
}
我们需要将prices大于200的提取出来
这里我们可以使用字典推导式
data = {(k, v) for k, v in prices.items() if v > 200}
print(data)
{('IBM', 205.55), ('AAPL', 612.78)}
当然我们也可以进行判断后直接使用dict转为字典
data = dict((k, v) for k, v in prices.items() if v > 200)
print(data)
上述都是对于字典的条件筛选,itertools中有几个方法可以直接获取一个序列中的所有子序列(是否可重复,是否有序等)有意者可以查看这篇文章itertools模块
18.映射名称到序列元素
正常情况下,我们获取序列中的元素都会使用下标的方式,但是单纯的通过数字的方式去获取对于的值,会让人感觉到不清晰,因此我们可以将序列中的元素映射到一个名称,我们可以通过名称去访问对应的元素,这就需要使用到collections.nametuple(命名元组),如下:
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "gender"], defaults=["man"])
p1 = Person("tom", 18)
print(p1.name)
print(p1.age)
print(p1.gender)
p2 = Person("mike", 19, gender="woman")
print(p2.name)
print(p2.age)
print(p2.gender)
tom
18
man
mike
19
woman
由此可见,命名元组类似于创建了一个类,类中设置了属性,我们可以通过对应名称去访问
除此之外,命名元组还可以代替字典,尤其是在数据较多的时候,字典创建会消耗更多的内存空间,因此我们可以使用命名元组。我们可以再使用命名元组的_asdict()返回字典形式,需要注意的是命名元组是不可修改的(属性名称是无法修改)的,但是可以修改属性的值,通过_replace方法进行修改:
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "gender"], defaults=["man"])
p2 = Person("mike", 19, gender="woman")
print(p2._asdict())
print(p2._replace(age=22))
{'name': 'mike', 'age': 19, 'gender': 'woman'}
Person(name='mike', age=22, gender='woman')
当然,作为属性传递,命名元组也可以设置默认值,上述有所体现,后期如果需要修改则可以使用_replace进行修改即可,需要注意的是当默认值少于实际属性时则默认值向靠右的属性靠齐
使用场景
1、数据库查询过程,可以使用命名元组代替下标更清晰
2.需要创建较大的字典数据结构时
19.数据处理时并计算
看题目可能并不是很清楚说的是啥,下面举个例子
print(sum(range(10)))
# 45
计算0-9的和,首先range()会生成0-9的数字并通过sum进行求和,其实这就是将两个步骤一起做,range返回的是一个生成器,其实一般而言我们推荐在数据计算过程中处理生成器数据,()包裹即可,当然也可以使用列表表达式,但会消耗一部分内存和性能。
20.合并多个字典及映射
详细可见collections.ChainMap(*maps)
参考
本文内容均来自于python3-cookbook书中的数据结构与算法,如有兴趣的小伙伴可以访问python3-cookbook进行学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号